Twitter Sentiment analysis Using Apache Spark By: Amandeep




















28 Slides4.30 MB
Twitter Sentiment analysis Using Apache Spark By: Amandeep Kaur (101060350) Deepesh Khaneja (101024610) Khushboo Vyas (101059808) Ranjit Singh Saini (101024552)
Outline Introduction Sentiment Analysis Challenges in sentiment analysis Framework Apache Spark Implementation Conclusion
What is sentiment analysis? Variety of Social Media Platforms and Blogs provide opportunities to express emotions. 1 Information has become vast and analysis can lead to several predictive results. 2 3 4 5 Sentiment Analysis is the classification of polarity of any word, sentence or document uses Natural Language Processing(NLP) to extract, identify or to characterize the sentiment content. Goal is to determine whether it is positive, negative or neutral.
Challenges in sentiment analysis Tweets Tweetsare arehighly highlyunstructured unstructuredand and non-grammatical non-grammatical 1 Has limit of Maximum of 140 characters 2 3 Extensive usage of slangs, acronyms and anti-social words Out of Vocabulary Words slangs 4 emoticons LOL G M O ROFL IMHO TBH Words like Pleaseeeee, Noooo, Damnnnn 08/24/202 3
High Level Functional and Object Oriented Programming Intellij Idea Apache Spark A lightning fast cluster computing platform to retrieve streaming data and forwarding to storage system like HDFS, Database Server Scala Technology Used Integrated Development Environment to build, run and test code
Apache Spark: Introduction Fast and general engine for large-scale data processing. Is open source, supports multiple languages and faster than on Apache Hadoop. Main Features Real Time Stream Processing: can handle real time streaming. In-memory cluster computing: increases the processing speed of an application. Advanced Analytics: It also supports SQL queries, Streaming data, Machine learning (ML), and Graph algorithms along with “map” and “reduce”. Figure: Hadoop vs apache spark By Cloudera.com
Apache Spark VS Hadoop
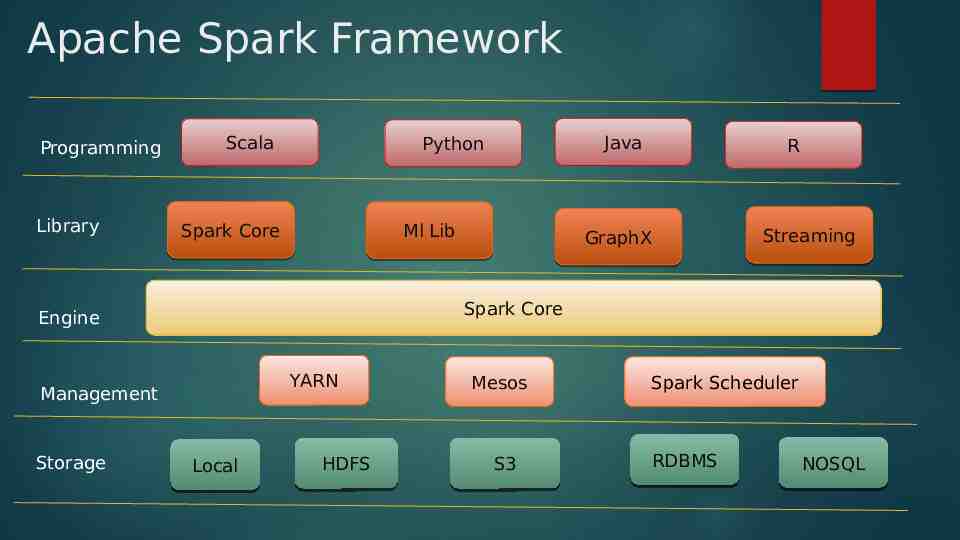
Apache Spark Framework Programming Library Scala Spark Core Ml Lib R GraphX Streaming Spark Core Engine YARN Management Storage Java Python Local HDFS Mesos S3 Spark Scheduler RDBMS NOSQL
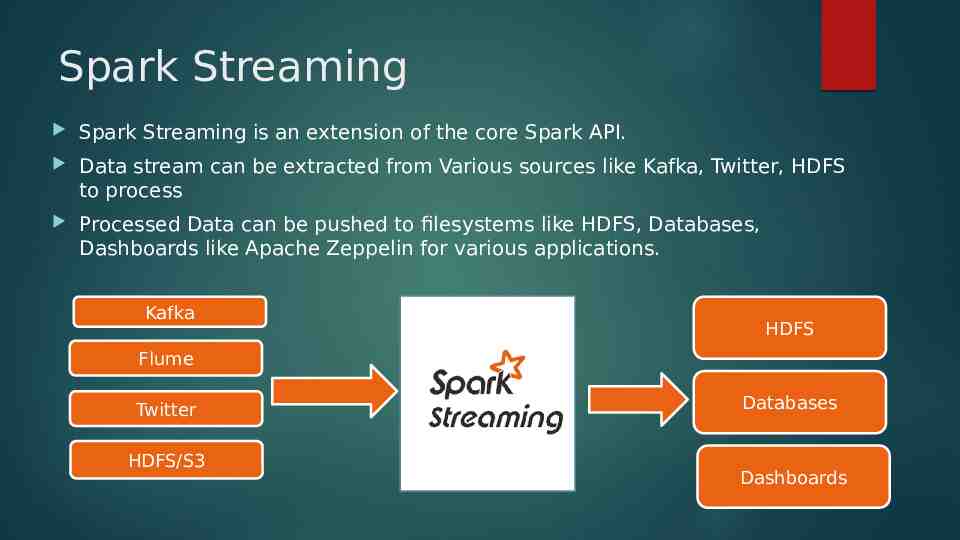
Spark Streaming Spark Streaming is an extension of the core Spark API. Data stream can be extracted from Various sources like Kafka, Twitter, HDFS to process Processed Data can be pushed to filesystems like HDFS, Databases, Dashboards like Apache Zeppelin for various applications. Kafka HDFS Flume Twitter HDFS/S3 Databases Dashboards
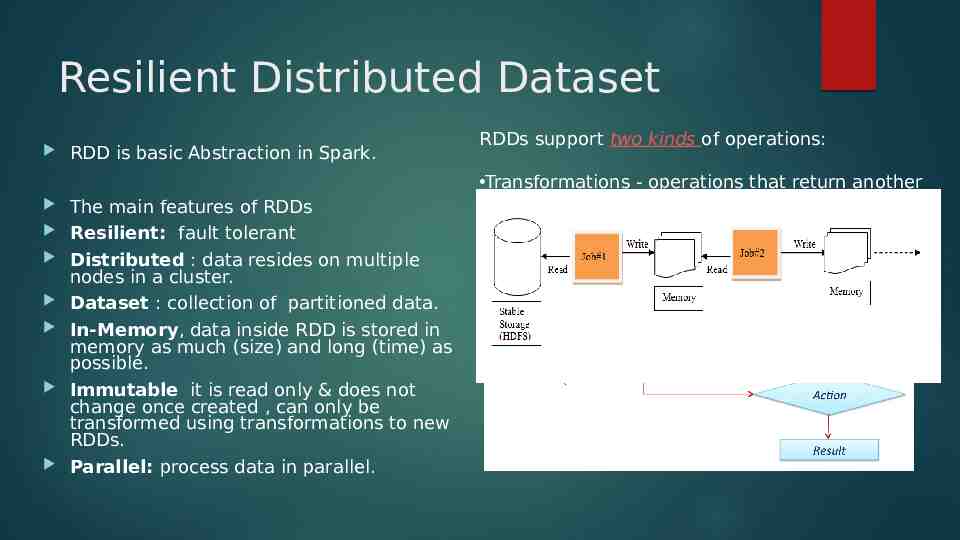
Resilient Distributed Dataset RDD is basic Abstraction in Spark. The main features of RDDs Resilient: fault tolerant Distributed : data resides on multiple nodes in a cluster. Dataset : collection of partitioned data. In-Memory, data inside RDD is stored in memory as much (size) and long (time) as possible. Immutable it is read only & does not change once created , can only be transformed using transformations to new RDDs. Parallel: process data in parallel. RDDs support two kinds of operations: Transformations - operations that return another RDD. Actions - operations that trigger computation and return values.
Interactive and Iterative operations on RDD Interactive Operations Support for persisting RDDs on disk and memory. Spark will keep the elements around on the cluster for much faster access Iterative Operations Store intermediate results in a distributed memory instead of Stable storage (Disk) Makes the system faster MR 1 Data on disk MR 2 Input from stable stage MR 3 e rit Each transformed RDD may be recomputed each time you run an action on HDFS read w Iteration 1 If different queries are run on the same set of data repeatedly, this particular data can be kept in memory for better execution times. Iteration 2 Iteration n MR 1 MR 1 ad e R Distribu ted Memory MR 2 MR 3 Distribu ted Memory MR 2 MR 3 Tuple s(on Disk)
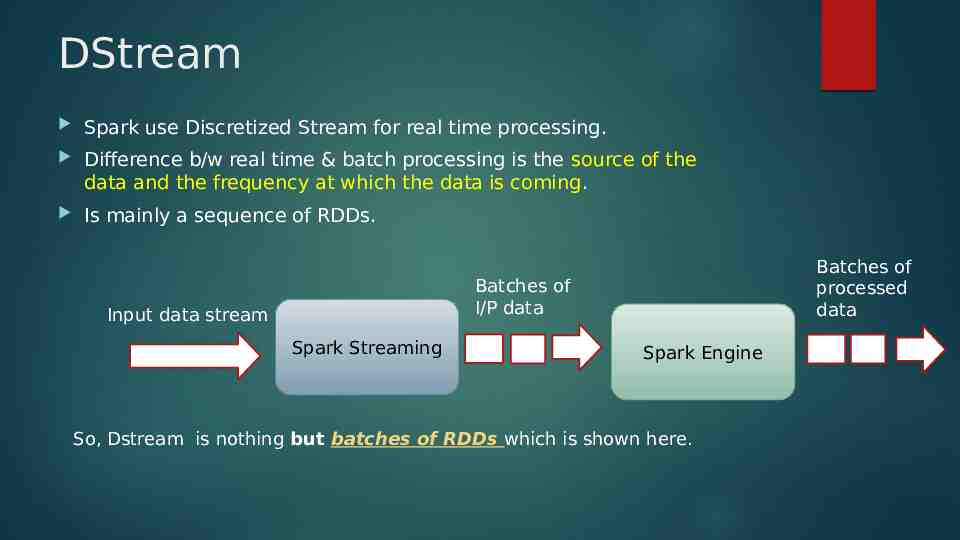
DStream Spark use Discretized Stream for real time processing. Difference b/w real time & batch processing is the source of the data and the frequency at which the data is coming. Is mainly a sequence of RDDs. Batches of processed data Batches of I/P data Input data stream Spark Streaming Spark Engine So, Dstream is nothing but batches of RDDs which is shown here.
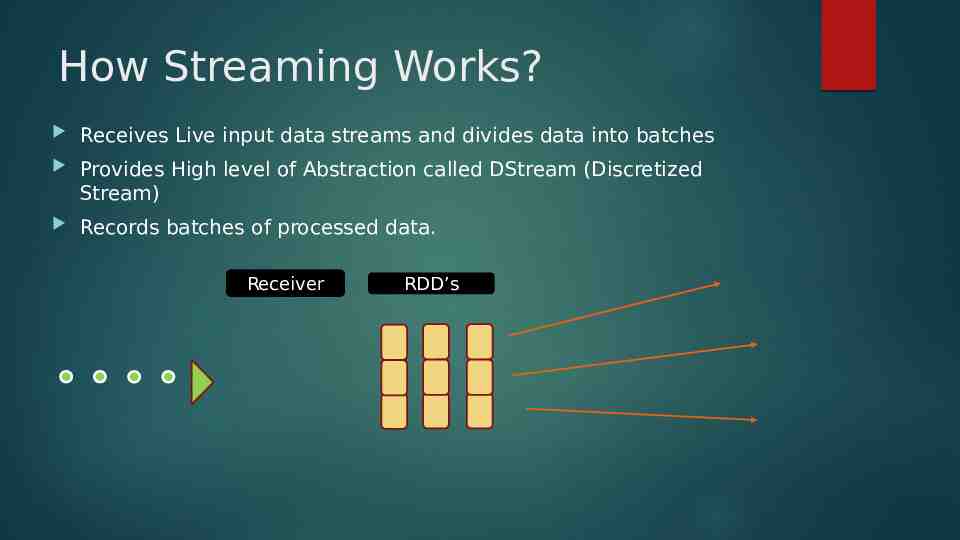
How Streaming Works? Receives Live input data streams and divides data into batches Provides High level of Abstraction called DStream (Discretized Stream) Records batches of processed data. Receiver RDD’s
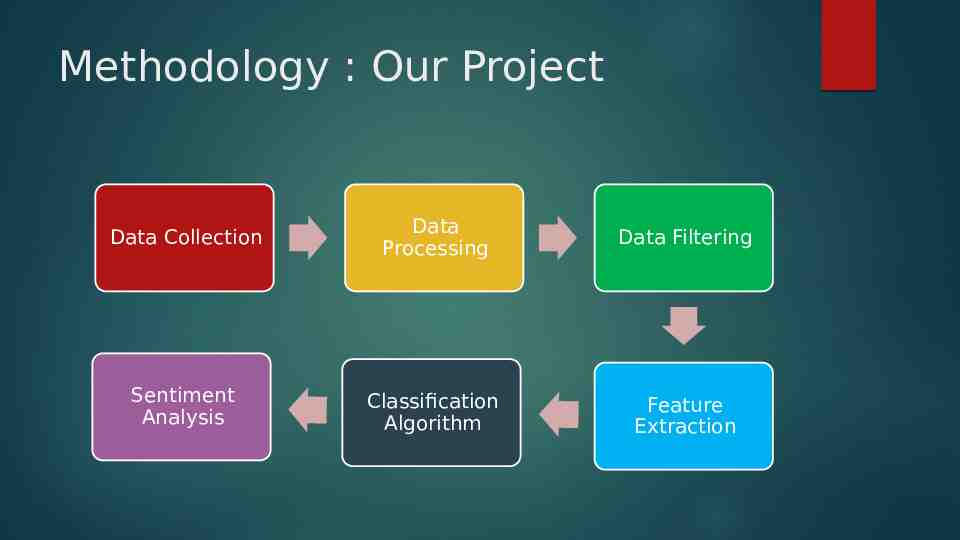
Methodology : Our Project Data Collection Data Processing Data Filtering Sentiment Analysis Classification Algorithm Feature Extraction
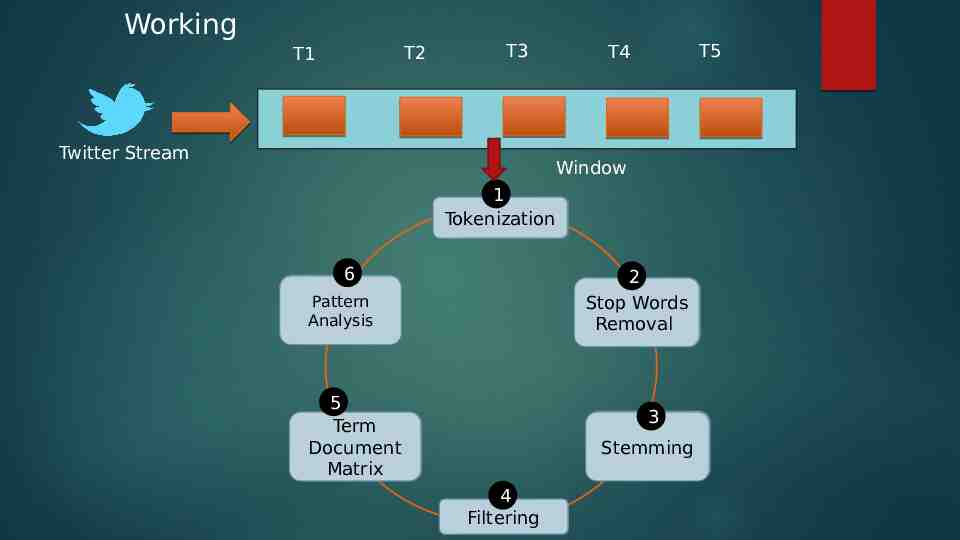
Working T2 T1 T3 Twitter Stream T5 T4 Window 1 Tokenization 6 2 Stop Words Removal Pattern Analysis 5 Term Term Document Document Matrix Matrix 3 Stemming 4 Filtering
Data Collection steps oauth.consumerKey xxxxxxxxxxxxxxxx oauth.consumerSecret x12221xxxxx oauth.accessToken x12221xxxxx oauth.accessTokenSecret x12221xxxxx 1. Twitter provides limited public API. 2. User needs to fill his API credentials. val keywords scala.io.StdIn.readLine() val filter keywords.split(",") val tweets: DStream[Status] 3. twitter4j library is used With Scala to Access Streaming Tweets. TwitterUtils.createStream(streami ngContext, None, filter) Live Tweets can be filtered according to keywords like #trump, #SRK, #life using filter argument in create stream.
Data Preprocessing: Tokenization Breaking a stream of text up into words, phrases, symbols, or other meaningful elements called tokens. In our Project, the incoming live streams of tweets are converted into list of tokens or words. Words are split after each space in the sentence. Example – In unigram format : Consider one token Tweet: What does Melania see in Donald Trump? After tokenizing : {‘What’ , ‘does’, ‘Melania’, ‘see’ , ‘in’, ‘Donald’, ‘Trump’, ‘?’} // Let's extract the words of each tweet // We'll carry the tweet along in order to print it in the end val textAndSentences: DStream[(TweetText, Sentence)] tweets. map( .getText). map(tweetText (tweetText, wordsOf(tweetText))) def wordsOf(tweet: TweetText): Sentence tweet.split(" ")
Data Filtering: Stemming Tokens are reduced to the root of word. Helps to avoid the derived words having same meanings semantically. Provided by Stanford CoreNLP library in scala. Stemming has the disadvantage of discarding linguistic information. Fish(root ) fish fishing fishes Figure: example of stemming
Feature Extraction: TF-IDF Matrix TF stands for term frequency and IDF stands for inverse Document Frequency. A feature extraction method reflecting the importance of term in a document of corpus. Computed Mathematically as TF provides all the terms with highest frequencies in the document !!! But all terms are not relevant to the desired result. T(t,D) Number of times term t appears in a document/ Total number of documents D IDF(t, D) log( ( D 1) / DF(t,D) 1)) , where DF(t, D) is the document frequency of term t in documents D
TF-IDF Continued. IDF provides the relative importance of a term in all documents D. If it appears in all documents then it provides no significant information. Based on the score of TF-IDF, set of keywords are chosen. The weights of TF-IDF results reflect the importance of keyword from a chosen hashtag.
Classification Algorithm Several Machine Learning Based Classification algorithms are available using supervised or unsupervised learning Approach. The supervised methods make use of a large number of labeled training documents. The unsupervised methods are used when it is difficult to find these labeled training documents. Machine Learning Supervised Unsupervised Classification -Naïve Bayes -Random Decision Forests Clustering K-means Regression Liner Logistic Dimensionality Reduction -Principal component -SVD
Pattern analysis Conducted to find the most important keywords using the TF-IDF statistics. The more the value of TF-IDF weight of a keyword, the more relevant it is to hashtag. Words with high TF-IDF represents the current trends on twitter.
Sentiment Analysis The other phase of the project is to analyze the sentiments in each tweet. The tweets received after processing and filtering are given score. The words in the tweets reflect the positive, negative or neutral sentiment. Neutral tweets are skipped from final output. // Compute the score of each sentence and keep only the nonneutral ones val textAndNonNeutralScore: DStream[(TweetText, Int)] textAndMeaningfulSentences. mapValues(sentence computeScore(sentence, positiveWords.value, negativeWords.value)). filter { case ( , score) score ! 0 }
Output Positive Tweet On Inputting multiple particular Keywords like ‘Canada’ , ‘Toronto’, ‘Trump’ Output is the live stream of tweets associated with these keywords with sentiment score on its left. We can see some false positives due to unsupervised learning approach. Negative Tweet
FUTURE WORK Use of TF–IDF feature extraction to find the current Trends on Twitter Classification and Prediction Model Integrating with Dashboard to better visualize results Used by major MNC’s
Conclusion Apache Spark use is on rise because of its flexibility to both ingest realtime data and then perform analytics. It provides various techniques to carryout sentiment analysis on Twitter data including knowledge based technique and machine learning techniques. The project can be extended using sophisticated machine learning Algorithms to predict and classify data.
References [1]E. Kouloumpis, T. Wilson, and J. D. Moore, “Twitter sentiment analysis: The good the bad and the omg!,” Icwsm, vol. 11, no. 538–541, p. 164, 2011. [2] P. Mishra, R. Rajnish, and P. Kumar, “Sentiment analysis of Twitter data: Case study on digital India,” in Information Technology (InCITe)-The Next Generation IT Summit on the Theme-Internet of Things: Connect your Worlds, International Conference on, 2016, pp. 148– 153. [3] J. Ramteke, S. Shah, D. Godhia, and A. Shaikh, “Election result prediction using Twitter sentiment analysis,” in Inventive Computation Technologies (ICICT), International Conference on, 2016, vol. 1, pp. 1–5. [4] Khalid N. Alhayyan, D. Imran Ahmed “Discovering and Analyzing Important Real-Time Trends in Noisy Twitter Streams” [5] M. Frampton, Mastering Apache Spark: gain expertise in processing and storing data by using advanced tecniques with Apache Spark. Birmingham: Packt Publishing, 2015.
Thank You