The Universal Dataplane







29 Slides4.27 MB
The Universal Dataplane
FD.io: The Universal Dataplane Project at Linux Foundation Multi-party Multi-project Software Dataplane High throughput Low Latency Feature Rich Resource Efficient Bare Metal/VM/Container Multiplatform Fd.io Scope: Network IO - NIC/vNIC - cores/threads Packet Processing – Classify/Transform/Prioritize/Forward/Terminate Dataplane Management Agents - ControlPlane Bare Bare Metal/VM/Container Metal/VM/Container Dataplane Management Agent Packet Processing Network IO fd.io Foundation 2
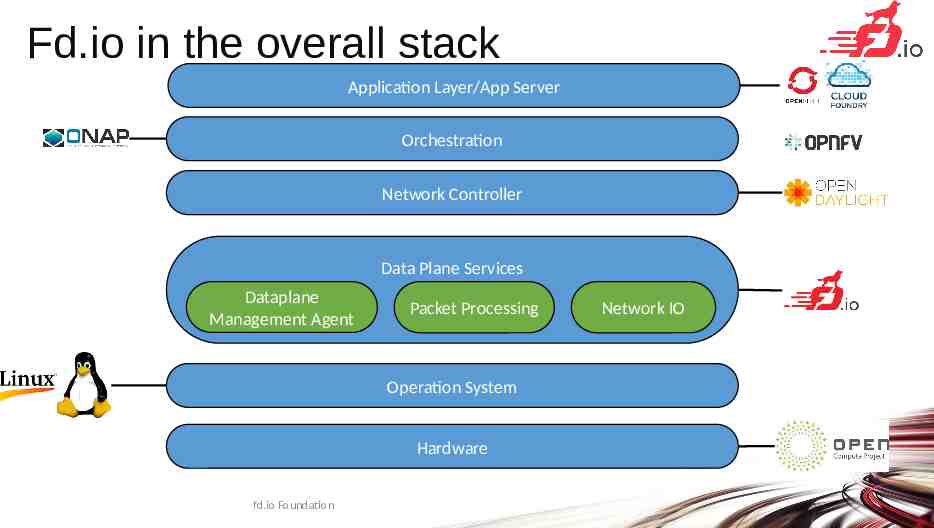
Fd.io in the overall stack Application Layer/App Server Orchestration Network Controller Data Plane Services Dataplane Management Agent Packet Processing Network IO Operation System Hardware fd.io Foundation 3
Multiparty: Broad Membership Service Providers Network Vendors Chip Vendors Integrators fd.io Foundation 4
Multiparty: Broad Contribution Qiniu Yandex Universitat Politècnica de Catalunya (UPC) fd.io Foundation 5
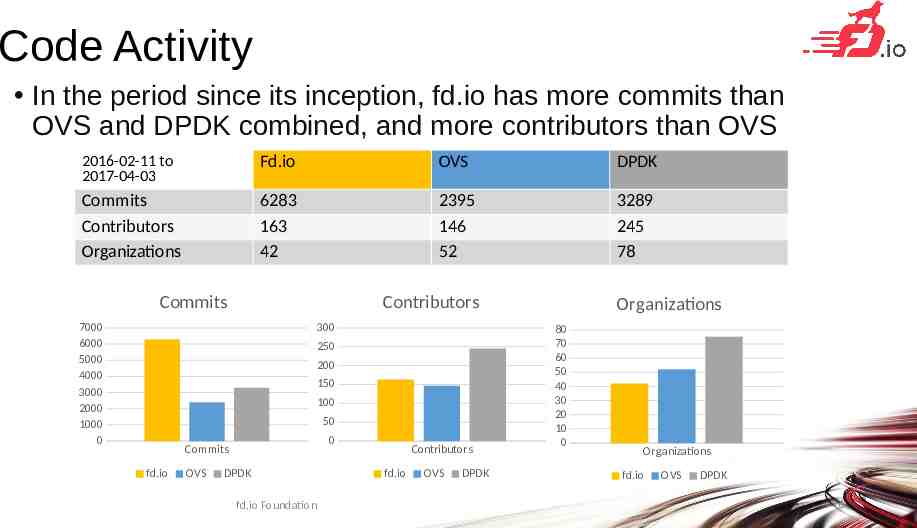
Code Activity In the period since its inception, fd.io has more commits than OVS and DPDK combined, and more contributors than OVS 2016-02-11 to 2017-04-03 Fd.io OVS DPDK Commits Contributors Organizations 6283 163 42 2395 146 52 3289 245 78 Commits 7000 6000 5000 4000 3000 2000 1000 0 Contributors 300 250 200 150 100 50 0 Commits fd.io OVS DPDK fd.io Foundation Contributors fd.io OVS DPDK Organizations 80 70 60 50 40 30 20 10 0 Organizations fd.io OVS DPDK 6
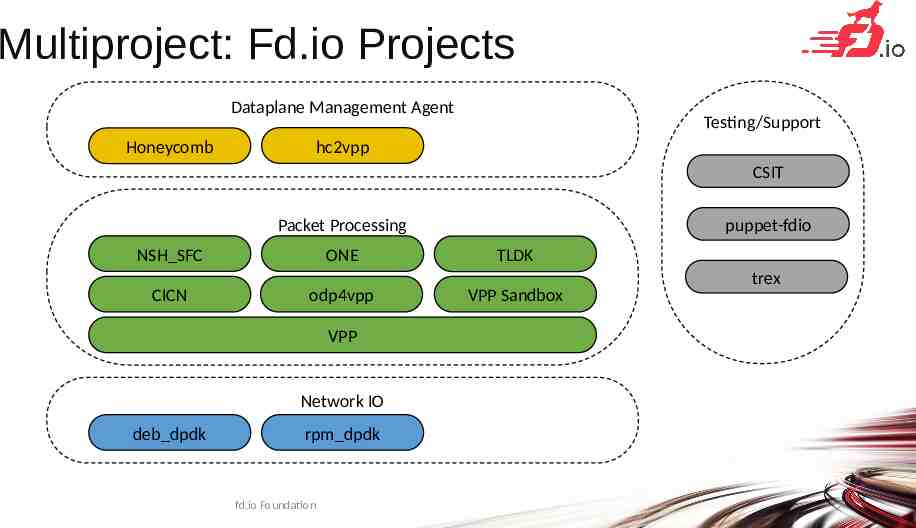
Multiproject: Fd.io Projects Dataplane Management Agent Testing/Support hc2vpp Honeycomb CSIT puppet-fdio Packet Processing NSH SFC CICN ONE odp4vpp TLDK VPP Sandbox trex VPP Network IO deb dpdk rpm dpdk fd.io Foundation 7
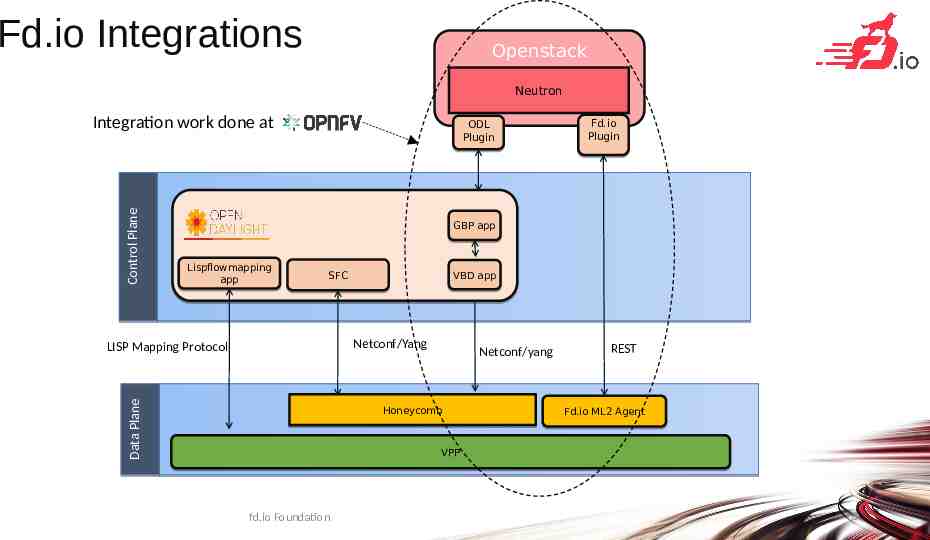
Fd.io Integrations Openstack Neutron Control Control Plane Plane Integration work done at ODL Plugin Fd.io Plugin GBP app Lispflowmapping app VBD app SFC Netconf/Yang Data Data Plane Plane LISP Mapping Protocol Netconf/yang Honeycomb REST Fd.io ML2 Agent VPP fd.io Foundation 8
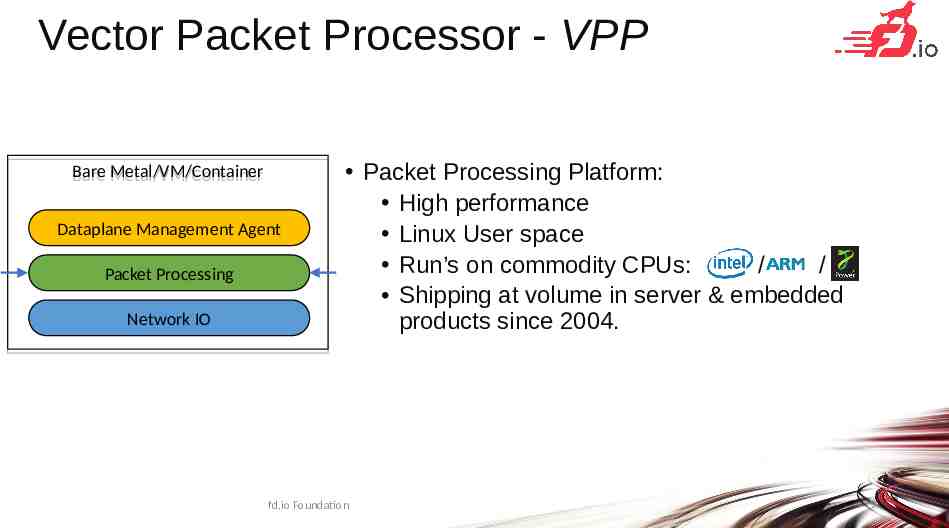
Vector Packet Processor - VPP Bare Bare Metal/VM/Container Metal/VM/Container Dataplane Management Agent Packet Processing Network IO Packet Processing Platform: High performance Linux User space Run’s on commodity CPUs: / / Shipping at volume in server & embedded products since 2004. fd.io Foundation 9
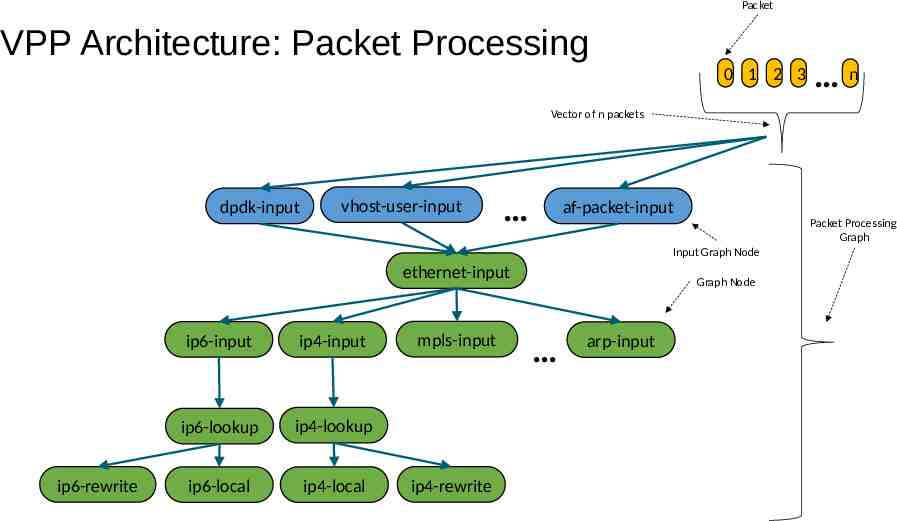
Packet VPP Architecture: Packet Processing 0 1 2 3 n Vector of n packets dpdk-input vhost-user-input af-packet-input Packet Processing Graph Input Graph Node ethernet-input ip6-rewrite ip6-input ip4-input ip6-lookup ip4-lookup ip6-local ip4-local mpls-input ip4-rewrite Graph Node arp-input
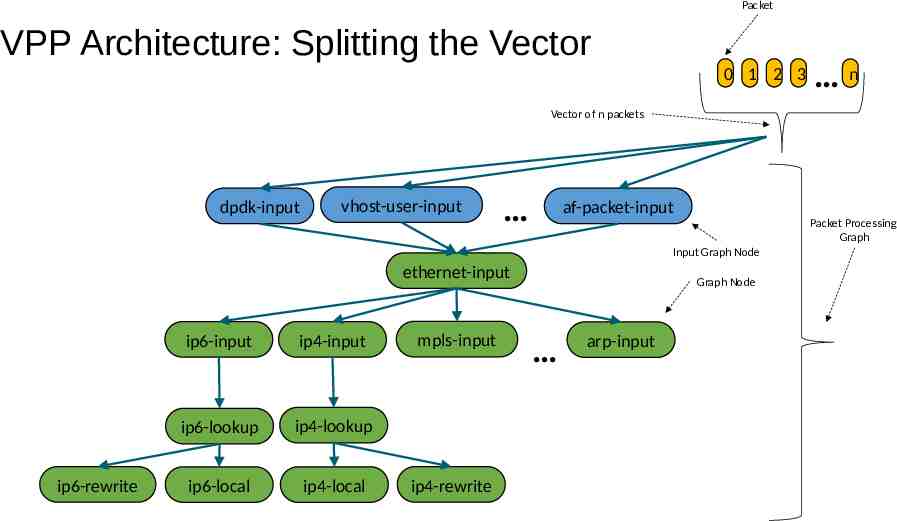
Packet VPP Architecture: Splitting the Vector 0 1 2 3 n Vector of n packets dpdk-input vhost-user-input af-packet-input Packet Processing Graph Input Graph Node ethernet-input ip6-rewrite ip6-input ip4-input ip6-lookup ip4-lookup ip6-local ip4-local mpls-input ip4-rewrite Graph Node arp-input
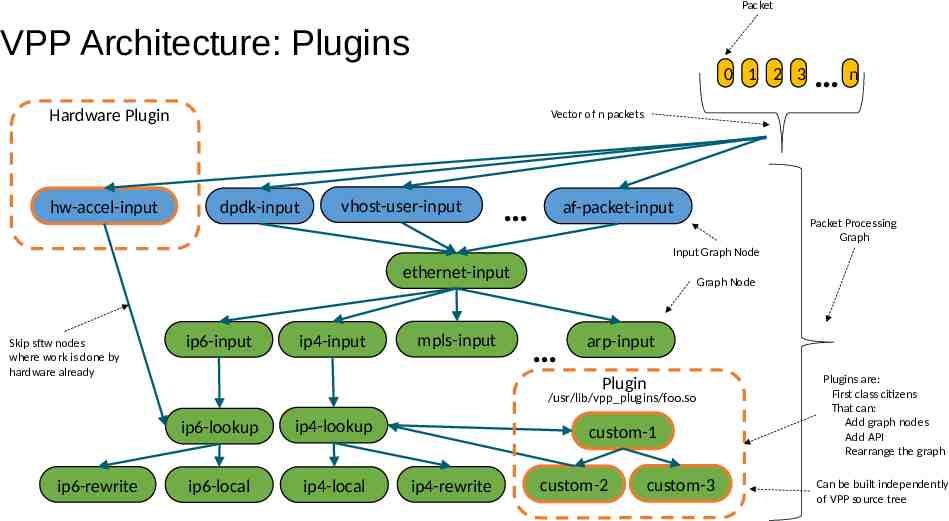
Packet VPP Architecture: Plugins 0 1 2 3 Hardware Plugin hw-accel-input n Vector of n packets dpdk-input vhost-user-input af-packet-input Packet Processing Graph Input Graph Node ethernet-input Skip sftw nodes where work is done by hardware already ip6-input ip4-input mpls-input Graph Node arp-input Plugin /usr/lib/vpp plugins/foo.so ip6-rewrite ip6-lookup ip4-lookup ip6-local ip4-local custom-1 ip4-rewrite custom-2 custom-3 Plugins are: First class citizens That can: Add graph nodes Add API Rearrange the graph Can be built independently of VPP source tree
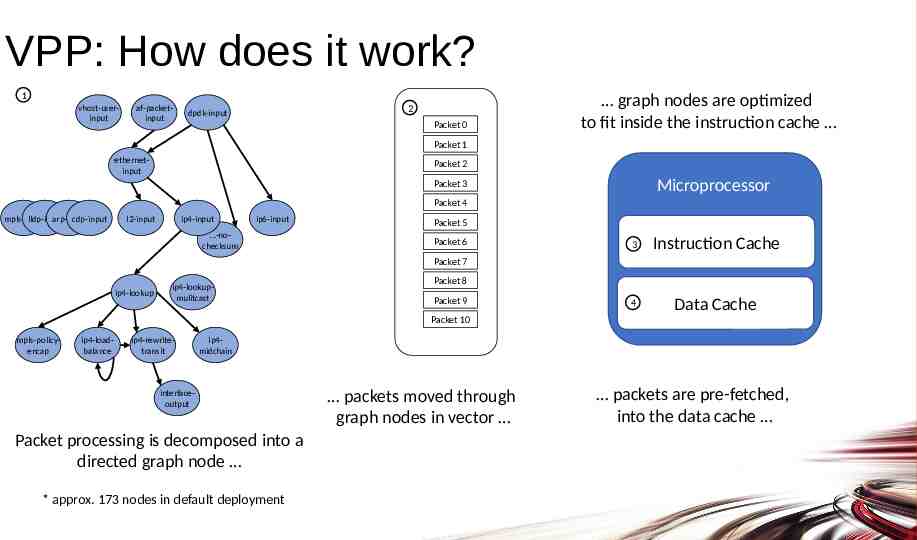
VPP: How does it work? 1 vhost-userinput af-packetinput 2 dpdk-input Packet 0 graph nodes are optimized to fit inside the instruction cache Packet 1 ethernetinput Packet 2 Microprocessor Packet 3 Packet 4 mpls-input lldp-input arp-input cdp-input l2-input ip4-input ip6-input .-nochecksum Packet 5 Packet 6 3 Instruction Cache 4 Data Cache Packet 7 ip4-lookup ip4-lookupmulitcast Packet 8 Packet 9 Packet 10 mpls-policyencap ip4-loadbalance ip4-rewritetransit ip4midchain interfaceoutput Packet processing is decomposed into a directed graph node * approx. 173 nodes in default deployment packets moved through graph nodes in vector packets are pre-fetched, into the data cache
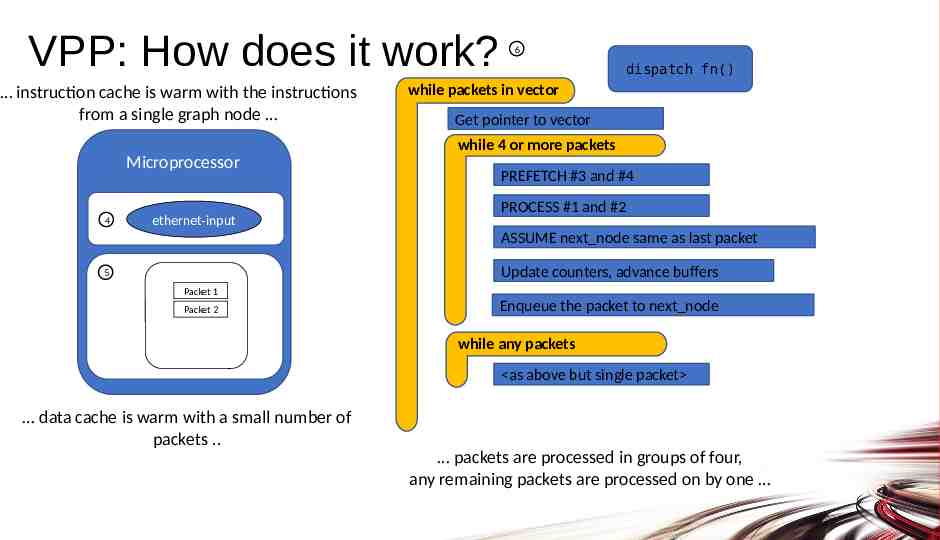
VPP: How does it work? instruction cache is warm with the instructions from a single graph node 6 dispatch fn() while packets in vector Get pointer to vector while 4 or more packets Microprocessor 4 ethernet-input PREFETCH #3 and #4 PROCESS #1 and #2 ASSUME next node same as last packet Update counters, advance buffers 5 Packet 1 Packet 2 Enqueue the packet to next node while any packets as above but single packet data cache is warm with a small number of packets . packets are processed in groups of four, any remaining packets are processed on by one
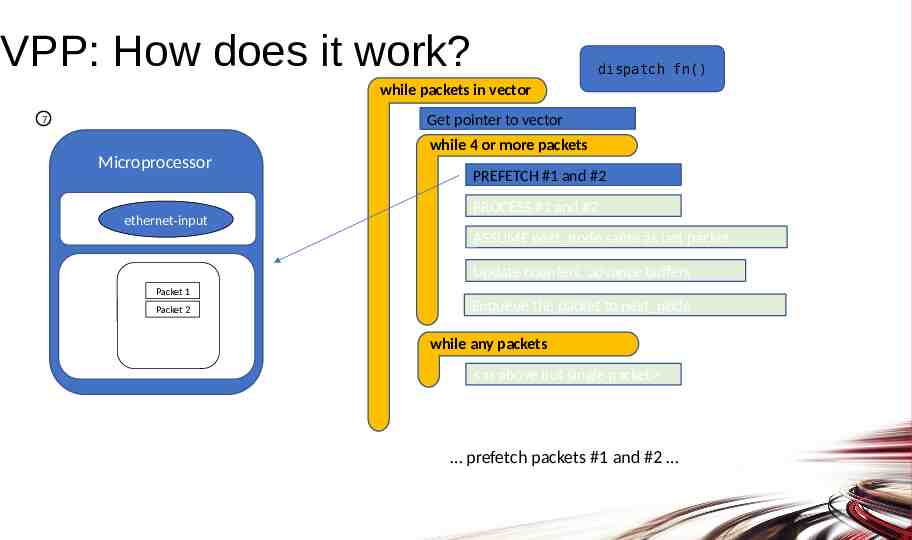
VPP: How does it work? dispatch fn() while packets in vector Get pointer to vector 7 while 4 or more packets Microprocessor ethernet-input PREFETCH #1 and #2 PROCESS #1 and #2 ASSUME next node same as last packet Update counters, advance buffers Packet 1 Packet 2 Enqueue the packet to next node while any packets as above but single packet prefetch packets #1 and #2
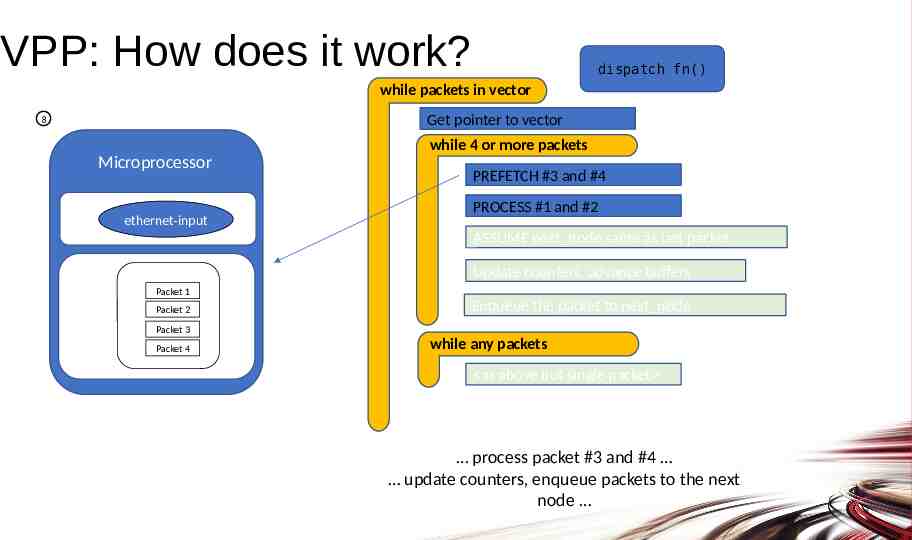
VPP: How does it work? dispatch fn() while packets in vector Get pointer to vector 8 while 4 or more packets Microprocessor ethernet-input PREFETCH #3 and #4 PROCESS #1 and #2 ASSUME next node same as last packet Update counters, advance buffers Packet 1 Packet 2 Enqueue the packet to next node Packet 3 Packet 4 while any packets as above but single packet process packet #3 and #4 update counters, enqueue packets to the next node
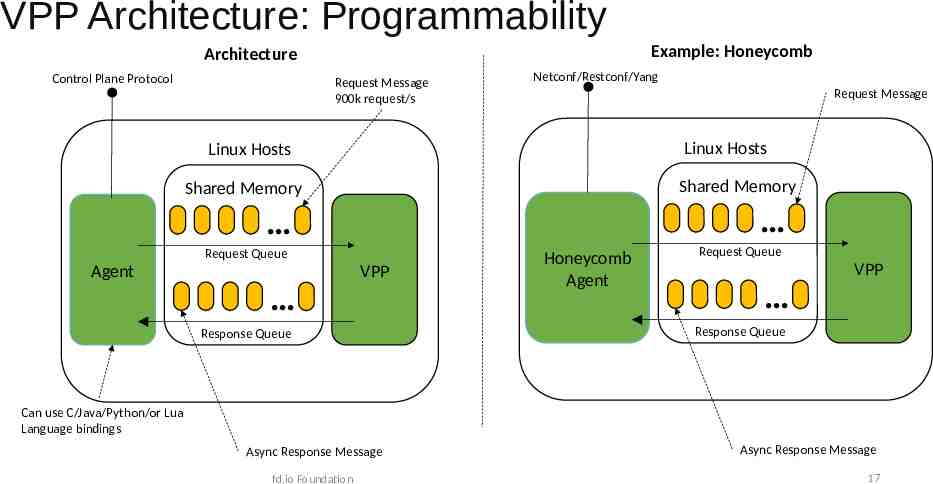
VPP Architecture: Programmability Example: Honeycomb Architecture Control Plane Protocol Request Message 900k request/s Netconf/Restconf/Yang Request Message Linux Hosts Linux Hosts Shared Memory Shared Memory Request Queue Agent VPP Response Queue Honeycomb Agent Request Queue VPP Response Queue Can use C/Java/Python/or Lua Language bindings Async Response Message fd.io Foundation Async Response Message 17
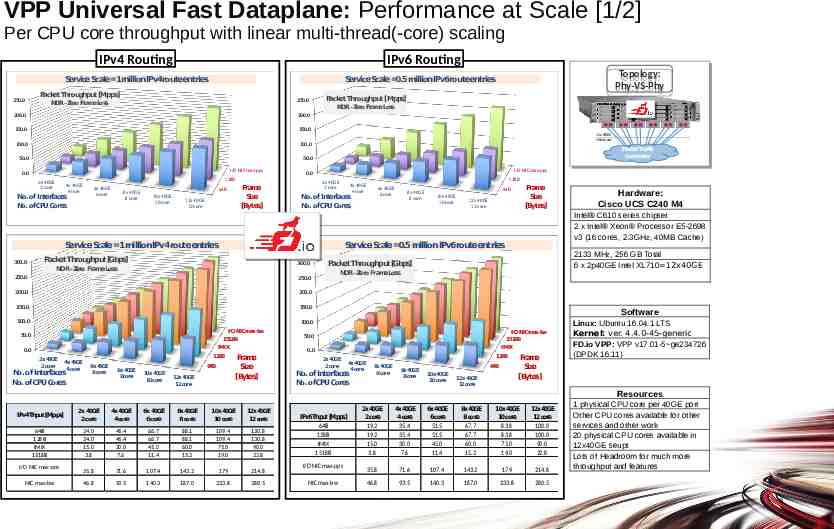
VPP Universal Fast Dataplane: Performance at Scale [1/2] Per CPU core throughput with linear multi-thread(-core) scaling IPv4 Routing IPv6 Routing ServiceScale 1millionIPv4routeentries PacketThroughput[Mpps] 250.0 250.0 NDR- Zero FrameLoss 200.0 150.0 150.0 100.0 100.0 50.0 50.0 I/O NIC max-pps 0.0 4x 40GE 4 core 6x 40GE 6 core 8x 40GE 8 core Frame Size [Bytes] 64B 10x 40GE 10 core 12x 40GE 12 core 12x 40GE interfaces PacketTraffic Generator I/O NIC max-pps 0.0 128B No. ofInterfaces No. ofCPU Cores PacketThroughput[Mpps] NDR-Zero FrameLoss 200.0 2x 40GE 2 core 128B 2x 40GE 2 core 4x 40GE 4 core 6x 40GE 6 core No. ofInterfaces No. ofCPU Cores ServiceScale 1millionIPv4routeentries 8x 40GE 8 core Frame Size [Bytes] 64B 10x 40GE 10 core 12x 40GE 12 core 300.0 NDR-Zero FrameLoss Hardware: Cisco UCS C240 M4 Intel C610 series chipset 2 x Intel Xeon Processor E5-2698 v3 (16 cores, 2.3GHz, 40MB Cache) ServiceScale 0.5millionIPv6routeentries PacketThroughput[Gbps] 300.0 Topology: Topology: Phy-VS-Phy Phy-VS-Phy ServiceScale 0.5millionIPv6routeentries 2133 MHz, 256 GB Total 6 x 2p40GE Intel XL710 12x40GE PacketThroughput[Gbps] NDR-Zero FrameLoss 250.0 250.0 200.0 200.0 150.0 150.0 Software 100.0 100.0 Linux: Ubuntu 16.04.1 LTS Kernel: ver. 4.4.0-45-generic FD.io VPP: VPP v17.01-5 ge234726 (DPDK 16.11) I/ONICmax-bw 1518B 50.0 IMIX 0.0 2x40GE 2core 128B 4x40GE 4core No. ofInterfaces No. ofCPU Cores 6x40GE 6core 24 8x40GE 8core 45.36 64B 10x40GE 10core 66.72 12x40GE 88.08 12co re Frame Size [Bytes] 109.44 130.8 IPv4Thput[Mpps] 2x40GE 2core 4x40GE 4core 6x40GE 6core 8x40GE 8core 10x40GE 10core 12x40GE 12core 64B 128B IMIX 1518B 24.0 24.0 15.0 3.8 45.4 45.4 30.0 7.6 66.7 66.7 45.0 11.4 88.1 88.1 60.0 15.2 109.4 109.4 75.0 19.0 130.8 130.8 90.0 22.8 35.8 71.6 107.4 143.2 179 214.8 46.8 93.5 140.3 187.0 233.8 280.5 NIC max-bw IMIX 0.0 2x40GE 2core 128B 4x40GE 4core No. ofInterfaces No. ofCPU Cores actual m-core scaling (mid-points interpolated) actual m-core scaling (mid-points interpolated) I/O NIC max-pps I/ONICmax-bw 1518B 50.0 IPv6Thput[Mpps] 64B 128B IMIX 1518B I/O NIC max-pps NIC max-bw 6x40GE 6core 19.2 8x40GE 8core 35.36 64B 10x40GE 10core 51.52 12x40GE 12core 67.68 Frame Size [Bytes] 83.84 100 2x40GE 2core 19.2 19.2 15.0 3.8 4x40GE 4core 35.4 35.4 30.0 7.6 6x40GE 6core 51.5 51.5 45.0 11.4 8x40GE 8core 67.7 67.7 60.0 15.2 10x40GE 10core 83.8 83.8 75.0 19.0 12x40GE 12core 100.0 100.0 90.0 22.8 35.8 71.6 107.4 143.2 179 214.8 46.8 93.5 140.3 187.0 233.8 280.5 Resources 1 physical CPU core per 40GE port Other CPU cores available for other services and other work 20 physical CPU cores available in 12x40GE seupt Lots of Headroom for much more throughput and features
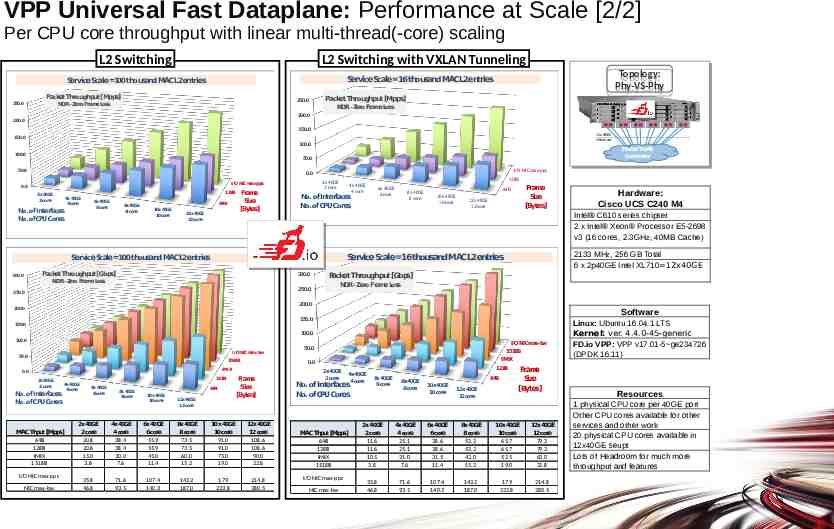
VPP Universal Fast Dataplane: Performance at Scale [2/2] Per CPU core throughput with linear multi-thread(-core) scaling L2 Switching L2 Switching with VXLAN Tunneling PacketThroughput[Mpps] 250.0 Topology: Topology: Phy-VS-Phy Phy-VS-Phy ServiceScale 16thousandMACL2entries ServiceScale 100thousandMACL2entries 250.0 NDR-Zero FrameLoss Packet Throughput[Mpps] NDR-Zero FrameLoss 200.0 200.0 150.0 12x 40GE interfaces 150.0 100.0 100.0 PacketTraffic Generator 50.0 50.0 I/O NIC max-pps 0.0 0.0 128B 2x40GE 2core 4x40GE 4core 6x40GE 6core No. ofInterfaces No. ofCPU Cores 8x40GE 8core 64B 10x40GE 10core 12x40GE 12core Frame Size [Bytes] 128B 2x 40GE 2 core I/ONICmax-pps 4x 40GE 4 core 8x 40GE 8 core Frame Size [Bytes] 64B 10x 40GE 10 core 12x 40GE 12 core 2133 MHz, 256 GB Total 6 x 2p40GE Intel XL710 12x40GE ServiceScale 16thousandMACL2entries PacketThroughput[Gbps] 300.0 NDR-Zero FrameLoss Packet Throughput[Gbps] NDR-Zero FrameLoss 250.0 250.0 200.0 200.0 Software 150.0 150.0 100.0 100.0 I/ONICmax-bw 50.0 1518B 2x40GE 2core No. ofInterfaces No. ofCPU Cores 128B 4x40GE 4core actual m-core scaling (mid-points interpolated) MACThput [Mpps] 64B 128B IMIX 1518B I/O NIC max-pps NIC max-bw 6x40GE 6core 8x40GE 8core 64B 10x40GE 10core 12x40GE 12core I/ONICmax-bw 1518B IMIX 50.0 0.0 IMIX 0.0 Frame Size [Bytes] 20.8 38.36 55.92 73.48 91.04 108.6 2x40GE 2core 20.8 20.8 15.0 3.8 4x40GE 4core 38.4 38.4 30.0 7.6 6x40GE 6core 55.9 55.9 45.0 11.4 8x40GE 8core 73.5 73.5 60.0 15.2 10x40GE 10core 91.0 91.0 75.0 19.0 12x40GE 12core 108.6 108.6 90.0 22.8 35.8 46.8 71.6 93.5 107.4 140.3 143.2 187.0 179 233.8 214.8 280.5 Hardware: Cisco UCS C240 M4 Intel C610 series chipset 2 x Intel Xeon Processor E5-2698 v3 (16 cores, 2.3GHz, 40MB Cache) ServiceScale 100thousandMACL2entries 300.0 6x 40GE 6 core No. ofInterfaces No. ofCPU Cores 2x40GE 2core 128B 4x40GE 4core No. ofInterfaces No. ofCPU Cores actual m-core scaling (mid-points interpolated) MACThput [Mpps] 64B 128B IMIX 1518B I/O NIC max-pps NIC max-bw 6x40GE 6core 8x40GE 8core 64B 10x40GE 10core 12x40GE 12core Frame Size [Bytes] 11.6 25.12 38.64 52.16 65.68 79.2 2x40GE 2core 11.6 11.6 10.5 3.8 4x40GE 4core 25.1 25.1 21.0 7.6 6x40GE 6core 38.6 38.6 31.5 11.4 8x40GE 8core 52.2 52.2 42.0 15.2 10x40GE 10core 65.7 65.7 52.5 19.0 12x40GE 12core 79.2 79.2 63.0 22.8 35.8 46.8 71.6 93.5 107.4 140.3 143.2 187.0 179 233.8 214.8 280.5 Linux: Ubuntu 16.04.1 LTS Kernel: ver. 4.4.0-45-generic FD.io VPP: VPP v17.01-5 ge234726 (DPDK 16.11) Resources 1 physical CPU core per 40GE port Other CPU cores available for other services and other work 20 physical CPU cores available in 12x40GE seupt Lots of Headroom for much more throughput and features
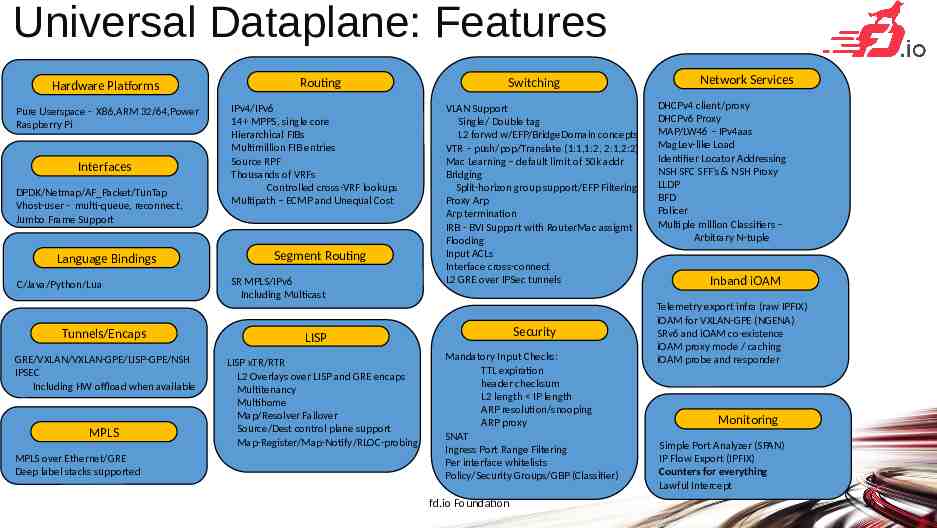
Universal Dataplane: Features Hardware Platforms Pure Userspace - X86,ARM 32/64,Power Raspberry Pi Interfaces DPDK/Netmap/AF Packet/TunTap Vhost-user - multi-queue, reconnect, Jumbo Frame Support Language Bindings C/Java/Python/Lua Tunnels/Encaps GRE/VXLAN/VXLAN-GPE/LISP-GPE/NSH IPSEC Including HW offload when available MPLS MPLS over Ethernet/GRE Deep label stacks supported Routing IPv4/IPv6 14 MPPS, single core Hierarchical FIBs Multimillion FIB entries Source RPF Thousands of VRFs Controlled cross-VRF lookups Multipath – ECMP and Unequal Cost Segment Routing SR MPLS/IPv6 Including Multicast Switching VLAN Support Single/ Double tag L2 forwd w/EFP/BridgeDomain concepts VTR – push/pop/Translate (1:1,1:2, 2:1,2:2) Mac Learning – default limit of 50k addr Bridging Split-horizon group support/EFP Filtering Proxy Arp Arp termination IRB - BVI Support with RouterMac assigmt Flooding Input ACLs Interface cross-connect L2 GRE over IPSec tunnels Security LISP LISP xTR/RTR L2 Overlays over LISP and GRE encaps Multitenancy Multihome Map/Resolver Failover Source/Dest control plane support Map-Register/Map-Notify/RLOC-probing Mandatory Input Checks: TTL expiration header checksum L2 length IP length ARP resolution/snooping ARP proxy SNAT Ingress Port Range Filtering Per interface whitelists Policy/Security Groups/GBP (Classifier) fd.io Foundation Network Services DHCPv4 client/proxy DHCPv6 Proxy MAP/LW46 – IPv4aas MagLev-like Load Identifier Locator Addressing NSH SFC SFF’s & NSH Proxy LLDP BFD Policer Multiple million Classifiers – Arbitrary N-tuple Inband iOAM Telemetry export infra (raw IPFIX) iOAM for VXLAN-GPE (NGENA) SRv6 and iOAM co-existence iOAM proxy mode / caching iOAM probe and responder Monitoring Simple Port Analyzer (SPAN) IP Flow Export (IPFIX) Counters for everything Lawful Intercept 20
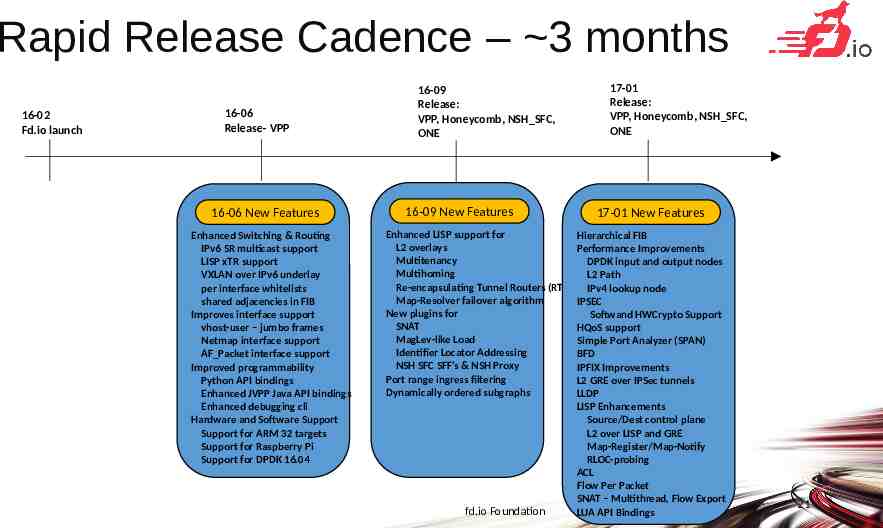
Rapid Release Cadence – 3 months 16-02 Fd.io launch 16-06 Release- VPP 16-06 New Features Enhanced Switching & Routing IPv6 SR multicast support LISP xTR support VXLAN over IPv6 underlay per interface whitelists shared adjacencies in FIB Improves interface support vhost-user – jumbo frames Netmap interface support AF Packet interface support Improved programmability Python API bindings Enhanced JVPP Java API bindings Enhanced debugging cli Hardware and Software Support Support for ARM 32 targets Support for Raspberry Pi Support for DPDK 16.04 16-09 Release: VPP, Honeycomb, NSH SFC, ONE 16-09 New Features 17-01 Release: VPP, Honeycomb, NSH SFC, ONE 17-01 New Features Enhanced LISP support for Hierarchical FIB L2 overlays Performance Improvements Multitenancy DPDK input and output nodes Multihoming L2 Path Re-encapsulating Tunnel Routers (RTR) support IPv4 lookup node Map-Resolver failover algorithm IPSEC New plugins for Softwand HWCrypto Support SNAT HQoS support MagLev-like Load Simple Port Analyzer (SPAN) Identifier Locator Addressing BFD NSH SFC SFF’s & NSH Proxy IPFIX Improvements Port range ingress filtering L2 GRE over IPSec tunnels Dynamically ordered subgraphs LLDP LISP Enhancements Source/Dest control plane L2 over LISP and GRE Map-Register/Map-Notify RLOC-probing ACL Flow Per Packet SNAT – Multithread, Flow Export fd.io Foundation LUA API Bindings 21
New in 17.04 – Due Apr 19 VPP Userspace Host Stack TCP stack DHCPv4 relay multi-destination DHCPv4 option 82 DHCPv6 relay multi-destination DHPCv6 relay remote-id ND Proxy Segment Routing v6 Security Groups Routed interface support L4 filters with IPv6 Extension Headers SR policies with weighted SID lists Binding SID SR steering policies SR LocalSIDs Framework to expand local SIDs w/plugins API SNAT CGN: Configurable port allocation CGN: Configurable Address pooling CPE: External interface DHCP support NAT64, LW46 Move to CFFI for Python binding Python Packaging improvements CLI over API Improved C/C language binding iOAM UDP Pinger w/path fault isolation IOAM as type 2 metadata in NSH IOAM raw IPFIX collector and analyzer Anycast active server selection IPFIX Collect IPv6 information Per flow state fd.io Foundation 22
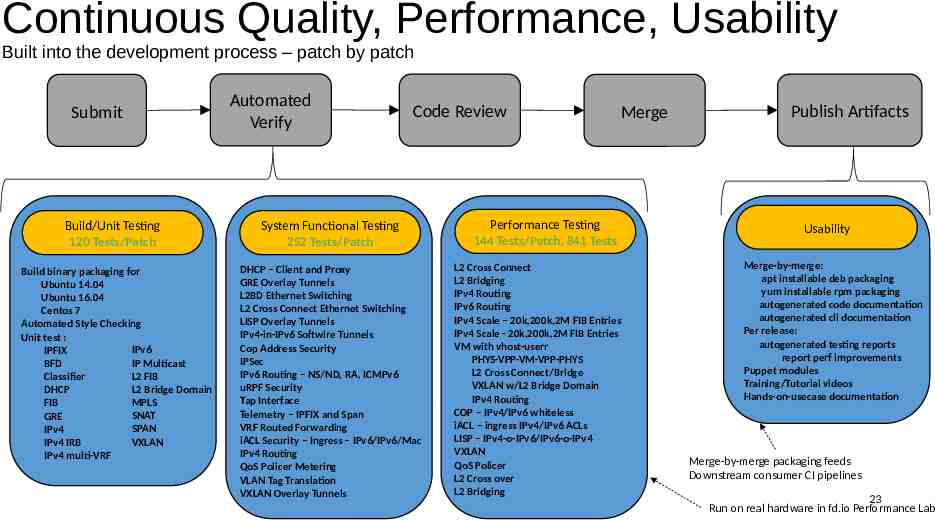
Continuous Quality, Performance, Usability Built into the development process – patch by patch Submit Build/Unit Testing 120 Tests/Patch Build binary packaging for Ubuntu 14.04 Ubuntu 16.04 Centos 7 Automated Style Checking Unit test : IPv6 IPFIX IP Multicast BFD L2 FIB Classifier L2 Bridge Domain DHCP MPLS FIB SNAT GRE SPAN IPv4 VXLAN IPv4 IRB IPv4 multi-VRF Automated Verify Code Review System Functional Testing 252 Tests/Patch DHCP – Client and Proxy GRE Overlay Tunnels L2BD Ethernet Switching L2 Cross Connect Ethernet Switching LISP Overlay Tunnels IPv4-in-IPv6 Softwire Tunnels Cop Address Security IPSec IPv6 Routing – NS/ND, RA, ICMPv6 uRPF Security Tap Interface Telemetry – IPFIX and Span VRF Routed Forwarding iACL Security – Ingress – IPv6/IPv6/Mac IPv4 Routing QoS Policer Metering VLAN Tag Translation VXLAN Overlay Tunnels fd.io Foundation Merge Performance Testing 144 Tests/Patch, 841 Tests L2 Cross Connect L2 Bridging IPv4 Routing IPv6 Routing IPv4 Scale – 20k,200k,2M FIB Entries IPv4 Scale - 20k,200k,2M FIB Entries VM with vhost-userr PHYS-VPP-VM-VPP-PHYS L2 Cross Connect/Bridge VXLAN w/L2 Bridge Domain IPv4 Routing COP – IPv4/IPv6 whiteless iACL – ingress IPv4/IPv6 ACLs LISP – IPv4-o-IPv6/IPv6-o-IPv4 VXLAN QoS Policer L2 Cross over L2 Bridging Publish Artifacts Usability Merge-by-merge: apt installable deb packaging yum installable rpm packaging autogenerated code documentation autogenerated cli documentation Per release: autogenerated testing reports report perf improvements Puppet modules Training/Tutorial videos Hands-on-usecase documentation Merge-by-merge packaging feeds Downstream consumer CI pipelines 23 Run on real hardware in fd.io Performance Lab
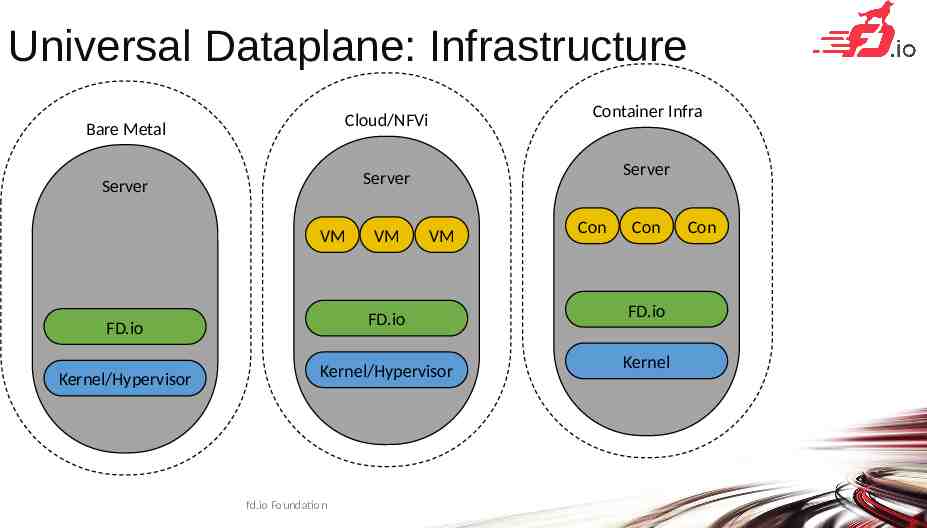
Universal Dataplane: Infrastructure Bare Metal Cloud/NFVi Container Infra Server Server Server VM VM VM Con Con FD.io FD.io FD.io Kernel/Hypervisor Kernel/Hypervisor Kernel fd.io Foundation Con 24
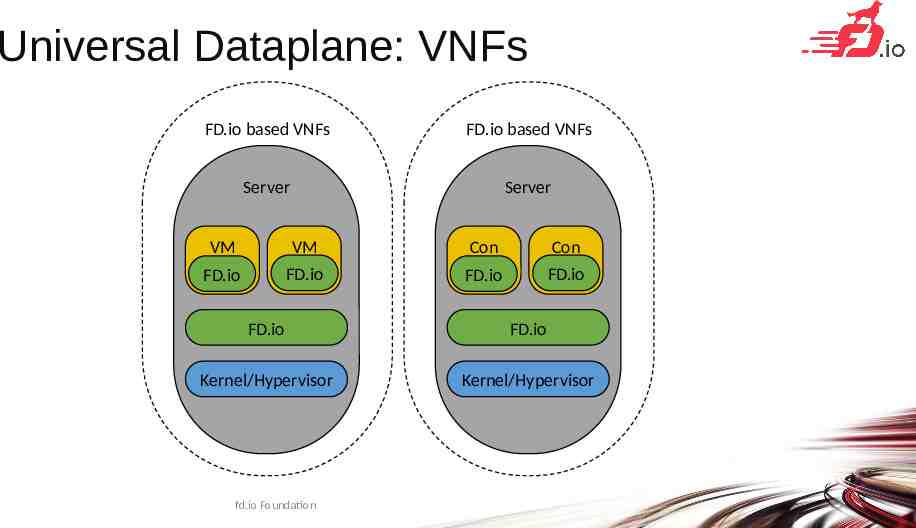
Universal Dataplane: VNFs FD.io based VNFs FD.io based VNFs Server Server VM VM FD.io FD.io Con Con FD.io FD.io FD.io FD.io Kernel/Hypervisor Kernel/Hypervisor fd.io Foundation 25
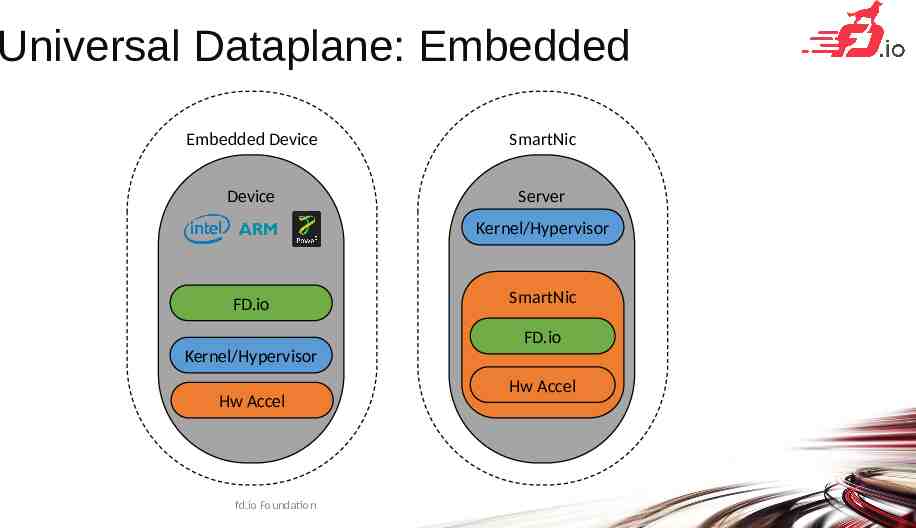
Universal Dataplane: Embedded Embedded Device SmartNic Device Server Kernel/Hypervisor FD.io SmartNic FD.io Kernel/Hypervisor Hw Accel fd.io Foundation Hw Accel 26
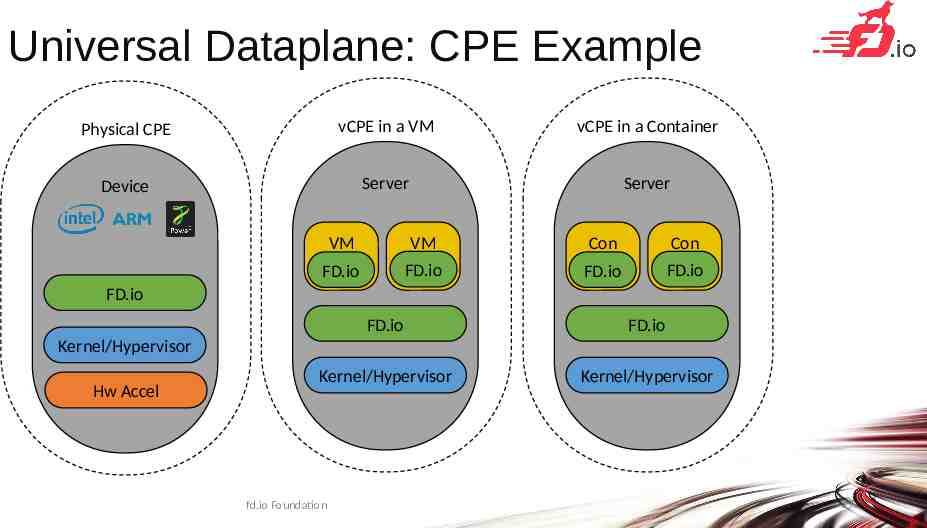
Universal Dataplane: CPE Example Physical CPE vCPE in a VM vCPE in a Container Device Server Server VM VM FD.io FD.io Con Con FD.io FD.io FD.io FD.io FD.io Kernel/Hypervisor Kernel/Hypervisor Kernel/Hypervisor Hw Accel fd.io Foundation 27
Opportunities to Contribute Firewall We invite you to Participate in fd.io IDS Get the Code, Build the Code, Run the C ode Hardware Accelerators Integration with OpenCache Control plane – support your favorite SDN Protocol Agent Spanning Tree Try the vpp user demo Install vpp from binary packages (yum/apt ) Install Honeycomb from binary packages Read/Watch the Tutorials DPI Join the Mailing Lists Test tools Cloud Foundry Integration Container Integration Join the IRC Channels Explore the wiki Join fd.io as a member Packaging Testing fd.io Foundation 28






