The Software Infrastructure for Electronic Commerce Databases and



















































58 Slides170.00 KB
The Software Infrastructure for Electronic Commerce Databases and Data Mining Lecture 4: An Introduction To Data Mining (II) Johannes Gehrke [email protected] http://www.cs.cornell.edu/johannes
Lectures Three and Four Data preprocessing Multidimensional data analysis Data mining Association rules Classification trees Clustering
Types of Attributes Numerical: Domain is ordered and can be represented on the real line (e.g., age, income) Nominal or categorical: Domain is a finite set without any natural ordering (e.g., occupation, marital status, race) Ordinal: Domain is ordered, but absolute differences between values is unknown (e.g., preference scale, severity of an injury)
Classification Goal: Learn a function that assigns a record to one of several predefined classes.
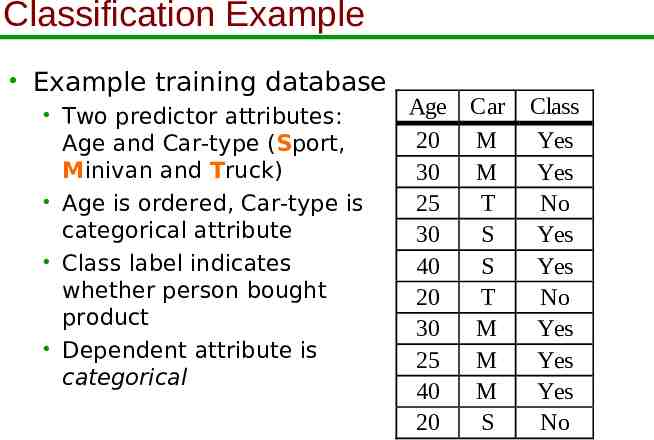
Classification Example Example training database Two predictor attributes: Age and Car-type (Sport, Minivan and Truck) Age is ordered, Car-type is categorical attribute Class label indicates whether person bought product Dependent attribute is categorical Age Car 20 M 30 M 25 T 30 S 40 S 20 T 30 M 25 M 40 M 20 S Class Yes Yes No Yes Yes No Yes Yes Yes No
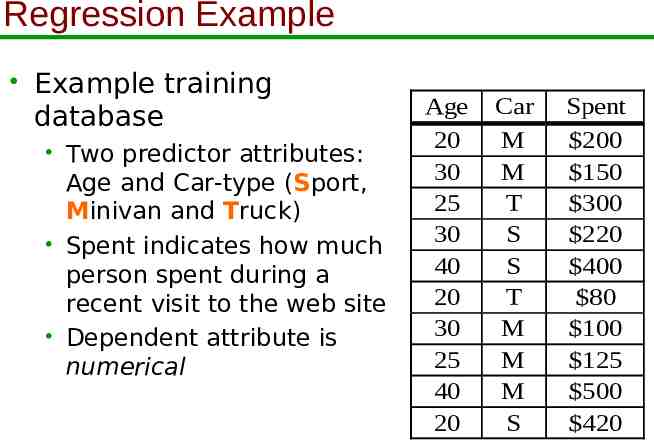
Regression Example Example training database Two predictor attributes: Age and Car-type (Sport, Minivan and Truck) Spent indicates how much person spent during a recent visit to the web site Dependent attribute is numerical Age 20 30 25 30 40 20 30 25 40 20 Car M M T S S T M M M S Spent 200 150 300 220 400 80 100 125 500 420
Types of Variables (Review) Numerical: Domain is ordered and can be represented on the real line (e.g., age, income) Nominal or categorical: Domain is a finite set without any natural ordering (e.g., occupation, marital status, race) Ordinal: Domain is ordered, but absolute differences between values is unknown (e.g., preference scale, severity of an injury)
Definitions Random variables X1, , Xk (predictor variables) and Y (dependent variable) Xi has domain dom(Xi), Y has domain dom(Y) P is a probability distribution on dom(X1) x x dom(Xk) x dom(Y) Training database D is a random sample from P A predictor d is a function d: dom(X1) dom(Xk) dom(Y)
Classification Problem If Y is categorical, the problem is a classification problem, and we use C instead of Y. dom(C) J. C is called the class label, d is called a classifier. Take r be record randomly drawn from P. Define the misclassification rate of d: RT(d,P) P(d(r.X1, , r.Xk) ! r.C) Problem definition: Given dataset D that is a random sample from probability distribution P, find classifier d such that RT(d,P) is minimized.
Regression Problem If Y is numerical, the problem is a regression problem. Y is called the dependent variable, d is called a regression function. Take r be record randomly drawn from P. Define mean squared error rate of d: RT(d,P) E(r.Y - d(r.X1, , r.Xk))2 Problem definition: Given dataset D that is a random sample from probability distribution P, find regression function d such that RT(d,P) is minimized.
Goals and Requirements Goals: To produce an accurate classifier/regression function To understand the structure of the problem Requirements on the model: High accuracy Understandable by humans, interpretable Fast construction for very large training databases
Different Types of Classifiers Linear discriminant analysis (LDA) Quadratic discriminant analysis (QDA) Density estimation methods Nearest neighbor methods Logistic regression Neural networks Fuzzy set theory Decision Trees
Difficulties with LDA and QDA Multivariate normal assumption often not true Not designed for categorical variables Form of classifier in terms of linear or quadratic discriminant functions is hard to interpret
Histogram Density Estimation Curse of dimensionality Cell boundaries are discontinuities. Beyond boundary cells, estimate falls abruptly to zero.
Kernel Density Estimation How to choose kernel bandwith h? The optimal h depends on a criterion The optimal h depends on the form of the kernel The optimal h might depend on the class label The optimal h might depend on the part of the predictor space How to choose form of the kernel?
K-Nearest Neighbor Methods Difficulties: Data must be stored; for classification of a new record, all data must be available Computationally expensive in high dimensions Choice of k is unknown
Difficulties with Logistic Regression Few goodness of fit and model selection techniques Categorical predictor variables have to be transformed into dummy vectors.
Neural Networks and Fuzzy Set Theory Difficulties: Classifiers are hard to understand How to choose network topology and initial weights? Categorical predictor variables?
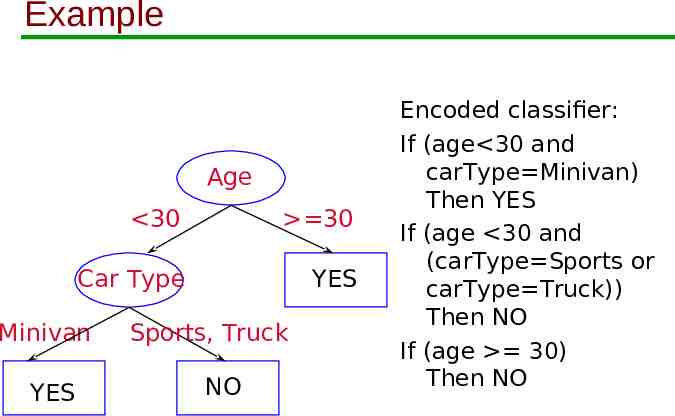
What are Decision Trees? Age 30 30 Car Type Minivan YES YES Sports, Truck Minivan YES Sports, Truck NO YES NO 0 30 60 Age
Decision Trees A decision tree T encodes d (a classifier or regression function) in form of a tree. A node t in T without children is called a leaf node. Otherwise t is called an internal node.
Internal Nodes Each internal node has an associated splitting predicate. Most common are binary predicates. Example predicates: Age 20 Profession in {student, teacher} 5000*Age 3*Salary – 10000 0
Internal Nodes: Splitting Predicates Binary Univariate splits: Numerical or ordered X: X c, c in dom(X) Categorical X: X in A, A subset dom(X) Binary Multivariate splits: Linear combination split on numerical variables: Σ aiXi c k-ary (k 2) splits analogous
Leaf Nodes Consider leaf node t Classification problem: Node t is labeled with one class label c in dom(C) Regression problem: Two choices Piecewise constant model: t is labeled with a constant y in dom(Y). Piecewise linear model: t is labeled with a linear model Y yt Σ aiXi
Example Age 30 30 Car Type YES Minivan YES Sports, Truck NO Encoded classifier: If (age 30 and carType Minivan) Then YES If (age 30 and (carType Sports or carType Truck)) Then NO If (age 30) Then NO
Choice of Classification Algorithm? Example study: (Lim, Loh, and Shih, Machine Learning 2000) 33 classification algorithms 16 (small) data sets (UC Irvine ML Repository) Each algorithm applied to each data set Experimental measurements: Classification accuracy Computational speed Classifier complexity
Classification Algorithms Tree-structure classifiers: IND, S-Plus Trees, C4.5, FACT, QUEST, CART, OC1, LMDT, CAL5, T1 Statistical methods: LDA, QDA, NN, LOG, FDA, PDA, MDA, POL Neural networks: LVQ, RBF
Experimental Details 16 primary data sets, created 16 more data sets by adding noise Converted categorical predictor variables to 0-1 dummy variables if necessary Error rates for 6 data sets estimated from supplied test sets, 10-fold crossvalidation used for the other data sets
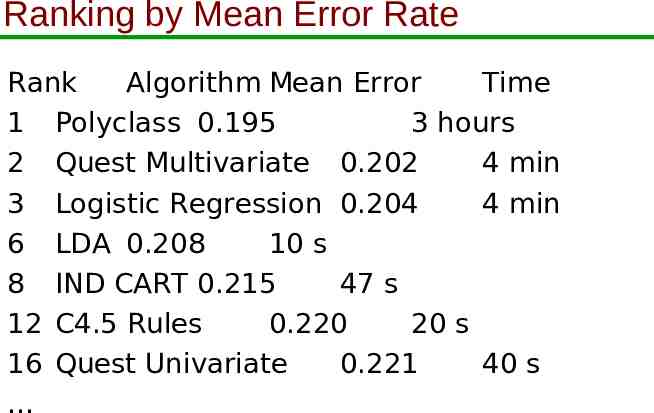
Ranking by Mean Error Rate Rank Algorithm Mean Error Time 1 Polyclass 0.195 3 hours 2 Quest Multivariate 0.202 4 min 3 Logistic Regression 0.204 4 min 6 LDA 0.208 10 s 8 IND CART 0.215 47 s 12 C4.5 Rules 0.220 20 s 16 Quest Univariate 0.221 40 s
Other Results Number of leaves for tree-based classifiers varied widely (median number of leaves between 5 and 32 (removing some outliers)) Mean misclassification rates for top 26 algorithms are not statistically significantly different, bottom 7 algorithms have significantly lower error rates
Decision Trees: Summary Powerful data mining model for classification (and regression) problems Easy to understand and to present to nonspecialists TIPS: Even if black-box models sometimes give higher accuracy, construct a decision tree anyway Construct decision trees with different splitting variables at the root of the tree
Clustering Input: Relational database with fixed schema Output: k groups of records called clusters, such that the records within a group are more similar to records in other groups More difficult than classification (unsupervised learning: no record labels are given) Usage: Exploratory data mining Preprocessing step (e.g., outlier detection)
Clustering (Contd.) In clustering we partitioning a set of records into meaningful sub-classes called clusters. Cluster: a collection of data objects that are “similar” to one another and thus can be treated collectively as one group. Clustering helps users to detect inherent groupings and structure in a data set.
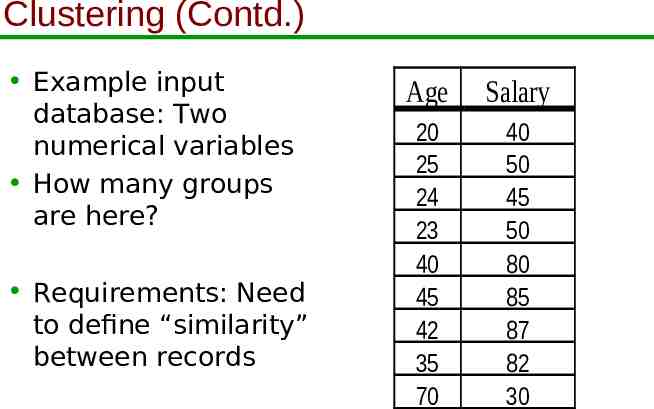
Clustering (Contd.) Example input database: Two numerical variables How many groups are here? Requirements: Need to define “similarity” between records Age Salary 20 25 24 23 40 45 42 35 70 40 50 45 50 80 85 87 82 30
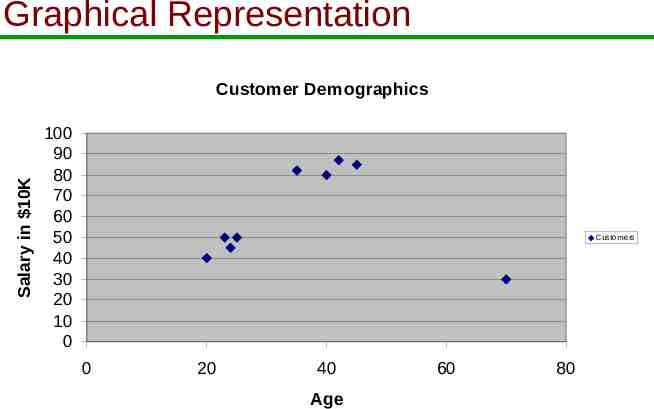
Graphical Representation Salary in 10K Customer Demographics 100 90 80 70 60 50 40 30 20 10 0 Customers 0 20 40 Age 60 80
Clustering (Contd.) Output of clustering: Representative points for each cluster Labeling of each record with each cluster number Other description of each cluster Important: Use the “right” distance function Scale or normalize all attributes. Example: seconds, hours, days Assign different weights associated with importance of the attribute
Clustering: Summary Finding natural groups in data Common post-processing steps: Build a decision tree with the cluster label as class label Try to explain the groups using the decision tree Visualize the clusters Examine the differences between the clusters with respect to the fields of the dataset Try different number of clusters
Web Usage Mining Data sources: Web server log Information about the web site: Site graph Metadata about each page (type, objects shown) Object concept hierarchies Preprocessing: Detect session and user context (Cookies, user authentication, personalization)
Web Usage Mining (Contd.) Data Mining Association Rules Sequential Patterns Classification Action Personalized pages Cross-selling Evaluation and Measurement Deploy personalized pages selectively Measure effectiveness of each implemented action
Large Case Study: Churn Telecommunications industry Try to predict churn (whether customer will switch long-distance carrier) Dataset: 5000 records (tiny dataset, but manageable here in class) 21 attributes, both numerical and categorical attributes (very few attributes) Data is already cleaned! No missing values, inconsistencies, etc. (again, for classroom purposes)
Churn Example: Dataset Columns State Account length: Number of months the customer has been with the company Area code Phone number International plan: yes/no Voice mail: yes/no Number of voice: Average number of voice messages per day Total (day, evening, night, international) minutes: Average number of minutes charged Total (day, evening, night, international) calls: Average number of calls made Total (day, evening, night, international) charge: Average amount charged per day Number customer service calls: Number of calls made to customer support in the last six months Churned: Did the customer switch long-distance carriers in the last six months
Churn Example: Analysis We start out by getting familiar with the dataset Record viewer Statistics visualization Evidence classifier Visualizing joint distributions Visualizing geographic distribution of churn
Churn Example: Analysis (Contd.) Building and interpreting data mining models Decision trees Clustering
Evaluating Data Mining Tools
Evaluating Data Mining Tools Checklist: Integration with current applications and your data management infrastructure Ease of usage Automation Scalability to large datasets Number of records Number of attributes Datasets larger than main memory Support of sampling Export of models into your enterprise Stability of the company that offers the product
Integration With Data Management Proprietary storage format? Native support of major database systems: IBM DB2, Informix, Oracle, SQL Server, Sybase ODBC Support of parallel database systems Integration with your data warehouse
Cost Considerations Proprietary or commodity hardware and operating system Client and server might be different What server platforms are supported? Support staff needed Training of your staff members Online training, tutorials On-site training Books, course material
Data Mining Projects Checklist: Start with well-defined business questions Have a champion within the company Define measures of success and failure Main difficulty: No automation Understanding the business problem Selecting the relevant data Data transformation Selection of the right mining methods Interpretation
Understand the Business Problem Important questions: What is the problem that we need to solve? Are there certain aspects of the problem that are especially interesting? Do we need data mining to solve the problem? What information is actionable, and when? Are there important business rules that constrain our solution? What people should we keep in the loop, and with whom should we discuss intermediate results? Who are the (internal) customers of the effort?
Hiring Outside Experts? Factors: One-time problem versus ongoing process Source of data Deployment of data mining models Availability and skills of your own staff
Hiring Experts Types of experts: Your software vendor Consulting companies/centers/individuals Your goal: Develop in-house expertise
The Data Mining Market Revenues for the data mining market: 8 billion (Mega Group 1/1999) Sales of data mining software (Two Crows Corporation 6/99) 1998: 50 million 1999: 75 million 2000: 120 million Hardware companies often use their data mining software as loss-leaders (Examples: IBM, SGI)
Knowledge Management in General Percent of information technology executives citing the systems used in their knowledge management strategy (IW 4/1999) Relational Database 95% Text/Document Search 80% Groupware 71% Data Warehouse 65% Data Mining Tools 58% Expert Database/AI Tools 25%
Crossing the Chasm Data mining is currently trying to cross this chasm. Great opportunities, but also great perils. You have a unique advantage by applying data mining “the right way”. It is not yet common knowledge how to apply data mining “the right way”. No major cooking recipes to make a data mining project work (yet).
Summary Database and data mining technology is crucial for any enterprise We talked about the complete data management infrastructure DBMS technology Querying WWW/DBMS integration Data warehousing and dimensional modeling OLAP Data mining
Additional Material: Web Sites Data mining companies, jobs, courses, publications, datasets, etc: www.kdnuggets.com ACM Special Interest Group on Knowledge Discovery and Data Mining www.acm.org/sigkdd
Additional Material: Books U. Fayyad, G. Piatetsky-Shapiro, P. Smyth, R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Minin g , AAAI/MIT Press, 1996 Michael Berry & Gordon Linoff, Data Mining Techniques for Marketing, Sales and C ustomer Support , John Wiley & Sons, 1997. Ian Witten and Eibe Frank, Data Mining, Practical Machine Learning Tools and Techniques with Java Implementations , Oct 1999 Michael Berry & Gordon Linoff,
Additional Material: Database Systems IBM DB2: www.ibm.com/software/data/db2 Oracle: www.oracle.com Sybase: www.sybase.com Informix: www.informix.com Microsoft: www.microsoft.com/sql NCR Teradata: www.ncr.com/product/teradata
Questions? “Prediction is very difficult, especially about the future.” Niels Bohr






