The Operating System (OS) Layer Dr. Sanjay P. Ahuja, Ph.D. Fidelity


































38 Slides2.07 MB
The Operating System (OS) Layer Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF
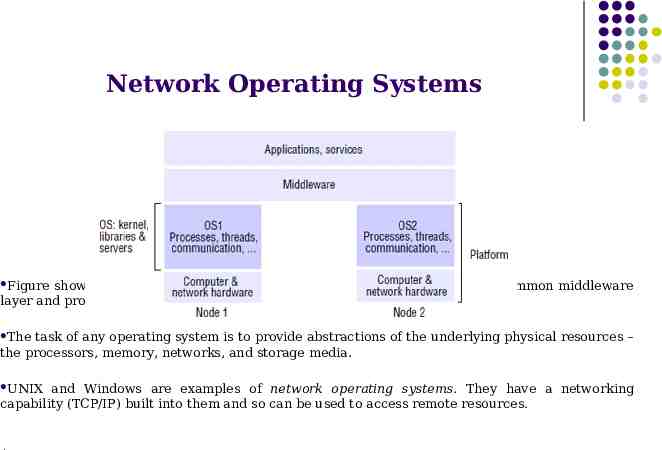
Network Operating Systems Figure shows the operating system layer at each of two nodes supporting a common middleware layer and providing distributed infrastructure for applications and services. The task of any operating system is to provide abstractions of the underlying physical resources – the processors, memory, networks, and storage media. UNIX and Windows are examples of network operating systems. They have a networking capability (TCP/IP) built into them and so can be used to access remote resources. .
Network Operating System Access is network-transparent for some – not all – types of resource. For example, through a distributed file system such as NFS, users have network-transparent access to files. But FTP/TELNET (or SSH) do not provide such network transparent access. The defining characteristic is that the nodes running a network operating system retain autonomy in managing their own processing resources. In other words, there are multiple system images, one per node. With a network operating system, a user can remotely log into another computer, using SSH, for example, and run processes there. However, while the operating system manages the processes running at its own node, it does not manage processes across the nodes.
Distributed Operating System On the other hand, we can envisage an operating system in which users are never concerned with where their programs run, or the location of any resources. There is a single system image. The operating system has control over all the nodes in the system, and it transparently locates new processes at whatever node suits its scheduling policies. For example, it could create a new process at the least-loaded node in the system, to prevent individual nodes becoming unfairly overloaded. An operating system that produces a single system image like this for all the resources in a distributed system is called a distributed operating system.
Distributed Operating System There are no distributed operating systems in general use, only network operating systems such as UNIX, Mac OS and Windows. There are two reasons. The first is that users have much invested in their application software, which often meets their current problem-solving needs; they will not adopt a new operating system that will not run their applications, whatever efficiency advantages it offers. The second reason against the adoption of distributed operating systems is that users tend to prefer to have a degree of autonomy for their machines, even in a closely knit organization. This is particularly so because of performance. The combination of middleware and network operating systems provides an acceptable balance between the requirement for autonomy on the one hand and network transparent resource access on the other. The network operating system enables users to run their favorite word processors and other standalone applications. Middleware enables them to take advantage of services that become available in their distributed system.
Core OS Functionality Core OS functionality includes process and thread management, memory management and communication between processes on the same computer. The kernel supplies much of this functionality – all of it in the case of some operating systems.
Core OS Functionality The core OS components and their responsibilities are: Process manager: Creation of and operations upon processes. A process is a unit of resource management, including an address space and one or more threads. Thread manager: Thread creation, synchronization and scheduling. Threads are schedulable activities attached to processes. Communication manager: Communication between threads attached to different processes on the same computer. Some kernels also support communication between threads in remote processes. Memory manager: Management of physical and virtual memory. Supervisor: Dispatching of interrupts, system call traps and other exceptions; control of memory management unit and hardware caches; processor and floating-point unit register manipulations.
Processes and Threads A process consists of an execution environment together with one or more threads. An execution environment consists of: address space; thread synchronization and communication resources such as semaphores and communication interfaces such as sockets; higher-level resources such as open files. 1. 2. 3. Execution environments are expensive to create and manage (more OS overhead), but several threads can share them – that is, they can share all resources accessible within them. Threads can be created and destroyed dynamically. Multiple threads of execution help maximize the degree of concurrent execution, thus enabling the overlap of computation with input and output, and enabling concurrent processing on multiprocessors. Threads can be helpful within servers by reducing bottlenecks. For e.g. one thread can process a client’s request while a second thread servicing another request waits for a disk access to complete.
Address Space An address space, is a unit of management of a process’s virtual memory. It is large (typically up to 232 bytes, and sometimes up to 264 bytes) and consists of code, data, heap, and stack segments. Threads or Light-weight Process (LWP) within a process, share the code, data, and heap sections but have their own stack segments. Threads share static variables and instance variables of an object.
Creation of a New Process The creation of a new process has traditionally been an indivisible operation provided by the operating system. For example, the UNIX fork system call creates a process with an execution environment copied from the caller (except for the return value from fork). The UNIX exec system call transforms the calling process into one executing the code of a named program. For a distributed system, the design of the process-creation mechanism has to take into account the utilization of multiple computers. The creation of a new process can be separated into two independent aspects: the choice of a target host, for example, the host may be chosen from among the nodes in a cluster of computers acting as a compute server the creation of an execution environment (and an initial thread within it).
Choice of Process Host The choice of the node at which the new process will reside depends on the process allocation policy. Process allocation policies range from always running new processes at their originator’s workstation to sharing the processing load between a set of computers. The transfer policy determines whether to situate a new process locally or remotely. This may depend, for example, on whether the local node is lightly or heavily loaded. The location policy determines which node should host a new process selected for transfer. This decision may depend on the relative loads of nodes, on their machine architectures or on any specialized resources they may possess. E.g. In the Amoeba system the run server transparently chooses a host for each process from a shared pool of processors. Process location policies may be static or adaptive. Static policies operate without regard to the current state of the system, although they are designed according to the optimizing a system parameter such as the overall process throughput.
Choice of Process Host contd. Adaptive policies apply heuristics to make their allocation decisions, based on runtime factors such as a measure of the load on each node. Load-sharing systems may be centralized or decentralized. In the centralized case there is one load manager component, and in a decentralized load-sharing system, nodes exchange information with one another directly to make allocation decisions. In sender-initiated load-sharing algorithms, the node that requires a new process to be created is responsible for initiating the transfer decision. It typically initiates a transfer when its own load crosses a threshold. By contrast, in receiver-initiated algorithms, a node whose load is below a given threshold advertises its existence to other nodes so that relatively loaded nodes can transfer work to it. Migratory load-sharing systems can shift load at any time, not just when a new process is created. They use a mechanism called process migration: the transfer of an executing process from one node to another.
Choice of Process Host contd. While several process migration mechanisms have been constructed, they have not been widely deployed. This is largely because of their expense and the tremendous difficulty of extracting the state of a process that lies within the kernel, in order to move it to another node. Conclusion: Simplicity is an important property of any load-sharing scheme. This is because relatively high overheads – for example, statecollection overheads – can outweigh the advantages of more complex schemes.
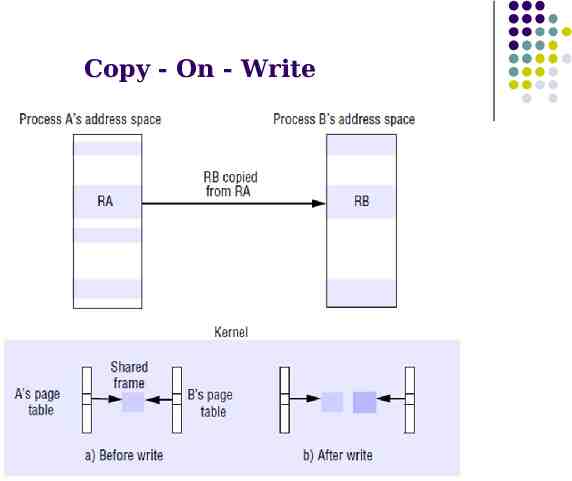
Creation of a new execution environment Once the host computer has been selected, a new process requires an execution environment consisting of an address space with initialized contents (such as default open files). In the case of UNIX fork semantics, for example, the newly created child process physically shares the parent’s text region and has heap and stack regions that are copies of the parent’s in extent (as well as in initial contents). Each region of the parent process may be inherited by (or omitted from) the child process. An inherited region may either be shared with or logically copied from the parent’s region. When parent and child share a region, the page frames (units of physical memory corresponding to virtual memory pages) belonging to the parent’s region are mapped simultaneously into the corresponding child region. Mach, for example, applies an optimization called copy-on-write when an inherited region is copied from the parent. The region is copied, but no physical copying takes place. The page frames that make up the inherited region are shared between the two address spaces. A page in the region is only physically copied when one or another process attempts to modify it.
Copy - On - Write
Copy – On – Write Example Let us follow through an example of regions RA and RB, whose memory is shared copy-on-write between two processes, A and B. Let us assume that process A set region RA to be copy-inherited by its child, process B, and that the region RB was thus created in process B. Assume for the sake of simplicity that the pages belonging to region A are resident in memory. Initially, all page frames associated with the regions are shared between the two processes’ page tables. The pages are initially write-protected at the hardware level, even though they may belong to regions that are logically writable. If a thread in either process attempts to modify the data, a hardware exception called a page fault is taken. Let us say that process B attempted the write. The page fault handler allocates a new frame for process B and copies the original frame’s data into it byte for byte. The old frame number is replaced by the new frame number in one process’s page table – it does not matter which – and the old frame number is left in the other page table. The two corresponding pages in processes A and B are then each made writable once more at the hardware level. After all of this has taken place, process B’s modifying instruction is allowed to proceed.
Threads We examine the advantages of enabling client and server processes to possess more than one thread. Consider the server shown in the Figure. The server has a pool of one or more threads, each of which repeatedly removes a request from a queue of received requests and processes it. Let us assume that each request takes, on average, 2 milliseconds of processing plus 8 milliseconds of I/O (input/output) delay when the server reads from a disk (there is no caching). Let us further assume for the moment that the server executes at a single-processor computer.
Threads – server throughput computation Consider the maximum server throughput, measured in client requests handled per second, for different numbers of threads. For one thread only: If a single thread has to perform all processing, then the turnaround time for handling any request is on average 2 8 10 milliseconds, so this server can handle: 1000 msecs / 10 msecs 100 client requests per second. Any new request messages that arrive while the server is handling a request are queued at the server port. Server contains two threads: Assume that threads are independently schedulable – that is, one thread can be scheduled when another becomes blocked for I/O. Then thread number two can process a second request while thread number one is blocked, and vice versa. This increases the server throughput. But it is possible that the threads may become blocked behind the single disk drive. If all disk requests are serialized and take 8 milliseconds each, then the maximum throughput is 1000/8 125 requests per second.
Threads – server throughput computation with disk caching Now assume that disk block caching is introduced. The server keeps the data that it reads in buffers in its address space; a server thread that is asked to retrieve data first examines the shared cache and avoids accessing the disk if it finds the data there. Given that the server requires 2.5 msecs of CPU time when the server finds the requested block in the cache, and takes an additional 8 msecs of disk I/O time otherwise. The hit ratio is 75%. Single-threaded: The mean turnaround time per request: (0.75 * 2.5 0.25 (2.5 8)) 1.875 2.625 4.5 msecs per request Server’s throughput 1000 / 4.5 222 requests/second Two-threaded running on a single CPU: The mean I/O time per request: (0.75 * 0 0.25 * 8) 2 msecs (So the theoretical maximum throughput 1000 / 2 500 requests/second) However in this case, the CPU time 2.5 msecs now exceeds the mean I/O time and so the 2-threaded server is limited by the CPU. It can handle at most 1000 / 2.5 400 requests/second.
Threads – server throughput computation with disk caching Two-threaded running on a 2-CPU machine: Since both threads can run in parallel, the throughput 2 * 222 444 requests/second. Three or more threaded running on a 2-CPU machine: bounded by I/O time, i.e. I/O is the bottleneck: This is now 0.75 * 0 0.25 * 8 2 msecs Maximum Server Throughput 1000 / 2 500 requests/second We can’t go any faster, no matter the number of threads because we have only 1 disk.
Architectures for Multi-Threaded Servers Thread-per-request architecture The I/O thread receives requests from a collection of sockets or ports and spawns a new worker thread for each request, and that worker destroys itself when it has processed the request against its designated remote object. This architecture has the advantage that the threads do not contend for a shared queue, and throughput is potentially maximized because the I/O thread can create as many workers as there are outstanding requests. Its disadvantage is the overhead of the thread creation and destruction operations. E.g. HTTP server
Architectures for Multi-Threaded Servers Thread-per-connection architecture This associates a thread with each connection. The server creates a new worker thread when a client makes a connection and destroys the thread when the client closes the connection. In between, the client may make many requests over the connection, targeted at one or more remote objects. Performance can be improved by using a connection pool (i.e. preexisting threads) E.g. Database connection thread making multiple SQL calls.
Architectures for Multi-Threaded Servers Thread-per-object architecture This associates a thread with each remote object. An I/O thread receives requests and queues them for the workers, but this time there is a per-object queue. E.g. a thread for a Producer object/Consumer object. In each of these last two architectures the server benefits from lower thread management overheads compared with the thread-per-request architecture. Their disadvantage is that clients may be delayed while a worker thread has several outstanding requests but another thread has no work to perform. Architecture 1 is the most common, followed by architecture 2.
Threads within Clients Threads can be useful for clients as well as servers. The figure shows a client process with 2 threads. A client making RMI (Remote method invocations) call typically block the caller, even when there is strictly no need to wait. In this case, one thread can make the call and hence block till the result is returned and have the original (main) thread continue computing further results. The main thread can place its results in buffers, which are emptied by the second thread making RMI calls (like a Producer-Consumer within the client). The main thread is only blocked when all the buffers are full. The case for multi-threaded clients is also evident in the example of web browsers. Users experience substantial delays while pages are fetched; it is essential, therefore, for browsers to handle multiple concurrent requests for web pages. E.g. one HTTP connection is maintained and multiple GET requests made concurrently for the images within a page, each within a new thread.
Threads vs. Multiple Processes Threads allow computation to be overlapped with I/O and, in the case of a multiprocessor, with other computation. The same overlap could be achieved through the use of multiple single-threaded processes. Why, then, should the multi-threaded process model be preferred? l Threads are cheaper to create and manage than processes. l Resource sharing can be achieved more efficiently between threads than between processes because threads share data segments. Thus they share instance and static variables of an object if there are more than thread per object. l Context switching between to a different thread within the same process is cheaper than switching between threads belonging to different processes (need to switch to a different memory segments and data and code segments are different and caches will have more misses till old instruction/data are flushed out.) l But, by the same token, threads within a process are not protected from one another. So programmers need to ensure that critical sections of the code are kept thread safe using primitives such as the Synchronized blocks in Java.
Threads vs. Multiple Processes The overheads associated with creating a process are in general considerably greater than those of creating a new thread. A new execution environment must first be created, including address space tables. As an example, Anderson et al quote a figure of about 11 milliseconds to create a new UNIX process, and about 1 millisecond to create a thread on the same CVAX processor architecture running the Topaz kernel. Figures quoted by Anderson et al are 1.8 milliseconds for the Topaz kernel to switch between UNIX processes and 0.4 milliseconds to switch between threads belonging to the same execution environment (since threads share the address space, only CPU registers and Program Counter need to be saved/restored).
Thread Lifetimes The Java Thread class includes the constructor and management methods listed in the next slide A new thread is created on the same Java virtual machine (JVM) as its creator, in the SUSPENDED state. After it is made RUNNABLE with the start() method, it executes the run() method of an object designated in its constructor. The JVM and the threads on top of it all execute in a process on top of the underlying operating system. Threads can be assigned a priority, so that a Java implementation that supports priorities will run a particular thread in preference to any thread with lower priority. A thread ends its life when it returns from the run() method or when its destroy() method is called.
Java Thread Class
Thread Synchronization Programming a multi-threaded process requires great care. The main difficult issues are the sharing of objects and the techniques used for thread coordination and cooperation. Each thread’s local variables in methods are private to it – threads have private stacks. However, threads are not given private copies of static (class) variables or object instance variables. Thread synchronization is needed to as two threads may try to alter a shared instance or static variable at the same time. Java allows threads to be blocked and woken up via arbitrary objects that act as condition variables. A thread that needs to block awaiting a certain condition calls an object’s wait() method. Another thread calls notify() to unblock at most one thread or notifyAll() to unblock all threads waiting on that object. As an example, when a worker thread discovers that there are no requests to process, it calls wait() on the instance of Queue. When the I/O thread subsequently adds a request to the queue, it calls the queue’s notify() method to wake up a worker.
Java Thread Synchronization Java provides the synchronized keyword for programmers to designate the well known monitor construct for thread coordination. Programmers designate either entire methods or arbitrary blocks of code as belonging to a monitor associated with an individual object. The monitor’s guarantee is that at most one thread can execute within it at any time. We could serialize the actions of the I/O and worker threads in our example by designating addTo() and removeFrom() methods in the Queue class as synchronized methods. All accesses to variables within those methods would then be carried out in mutual exclusion with respect to invocations of these methods.
Java Thread Synchronization Calls
Thread Implementation Many kernels provide native support for multi-threaded processes, including Windows, Linux, Solaris, Mach and Mac OS X. These kernels provide thread-creation and -management system calls, and they schedule individual threads. Some other kernels have only a single-threaded process abstraction. Multithreaded processes must then be implemented in a library of procedures linked to application programs. In such cases, the kernel has no knowledge of these user-level threads and therefore cannot schedule them independently. A threads runtime library organizes the scheduling of threads. A thread would block the process, and therefore all threads within it, if it made a blocking system call.
Thread Implementation Disadvantages of not having kernel/native support for threads: 1. The threads within a process cannot take advantage of a multiprocessor. 2. A thread that makes a page fault blocks the entire process and all threads within it. 3. A thread would block the process, and therefore all threads within it if made a blocking I/O system call. 4. Threads within different processes cannot be scheduled according to a single scheme of relative prioritization. E.g. the OS can preempt a native thread at any time, say by using the Round-Robin scheduling policy, and run some other thread that was not currently running.
Thread Implementation Advantages of User-level threads implementations: l Certain thread operations are significantly less costly. For example, switching between threads belonging to the same process does not necessarily involve a system call, which entails a relatively expensive trap to the kernel. l Given that the thread-scheduling module is implemented outside the kernel, it can be customized or changed to suit particular application requirements. l Many more user-level threads can be supported than could reasonably be provided by default by a kernel i.e. there is no default value to the number of threads supported by a kernel.
Hyper Threading Intel technology allows one physical CPU (c0re) to be viewed as 2 logical CPUs. So OS and applications will see 2 CPUs rather than one. So in a dual-core setup with HTT, there will be 4 logical CPUs, so more work (thread execution) can be done (supported). When one logical CPU is going to wait (e.g. if a cache miss or data dependency occurs) then a HALT is issued to that logical CPU by the OS and all physical resources (the core) is then dedicated to the other logical CPU. Performance Gains: Intel claims 30% gain in performance (CPU utilization) for a core with HTT compared to the same core with non-HTT. Scheduler in OS will need tweaks to be made aware of logical CPU, else it might schedule 2 threads to 2 logical CPUs on same physical core rather than different physical cores.
Hyper Threading To enable HTT, some architectural components of a physical CPU/core are duplicated for the 2 logical CPUs (e.g. the registers and L1 cache) whilst the actual execution component (ALU) is shared by the 2 logical CPUs. So due to HTT, multiple threads of an application can execute in parallel within each physical CPU (c0re). In Nehalem (micro-architecture from Intel), even a core that is not busy can be idled and the clock frequency of the other active cores can be increased. Reference: https:// software.intel.com/en-us/articles/performance-insights-to-intel-hyper-threadin g-technology
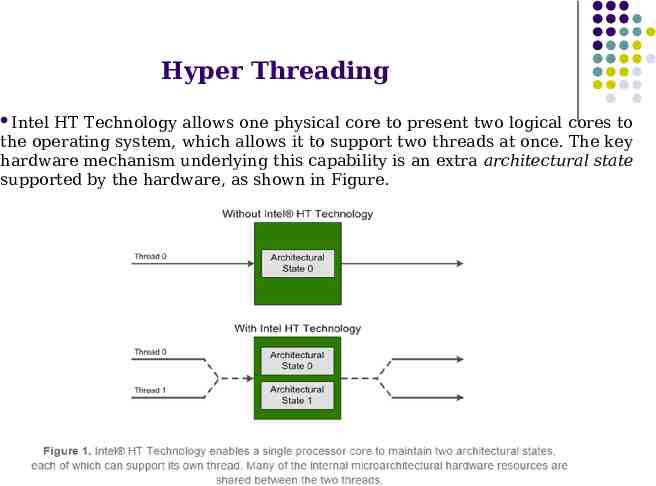
Hyper Threading Intel HT Technology allows one physical core to present two logical cores to the operating system, which allows it to support two threads at once. The key hardware mechanism underlying this capability is an extra architectural state supported by the hardware, as shown in Figure.
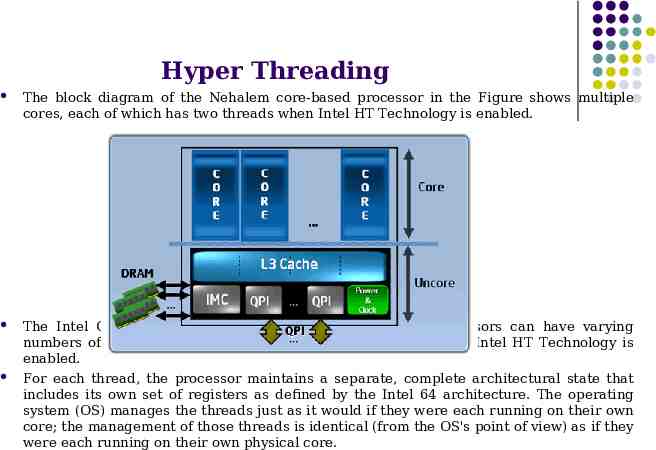
Hyper Threading The block diagram of the Nehalem core-based processor in the Figure shows multiple cores, each of which has two threads when Intel HT Technology is enabled. The Intel Core i7 processor and architecturally similar processors can have varying numbers of cores, each of which can support two threads when Intel HT Technology is enabled. For each thread, the processor maintains a separate, complete architectural state that includes its own set of registers as defined by the Intel 64 architecture. The operating system (OS) manages the threads just as it would if they were each running on their own core; the management of those threads is identical (from the OS's point of view) as if they were each running on their own physical core.






