Support Vector Machines Note to other teachers and users of these

















































65 Slides582.00 KB
Support Vector Machines Note to other teachers and users of these slides. Andrew would be delighted if you found this source material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit your own needs. PowerPoint originals are available. If you make use of a significant portion of these slides in your own lecture, please include this message, or the following link to the source repository of Andrew’s tutorials: http://www.cs.cmu.edu/ awm/tutori als . Comments and corrections gratefully received. Andrew W. Moore Professor School of Computer Science Carnegie Mellon University www.cs.cmu.edu/ awm [email protected] 412-268-7599 Copyright 2001, 2003, Andrew W. Moore Nov 23rd, 2001
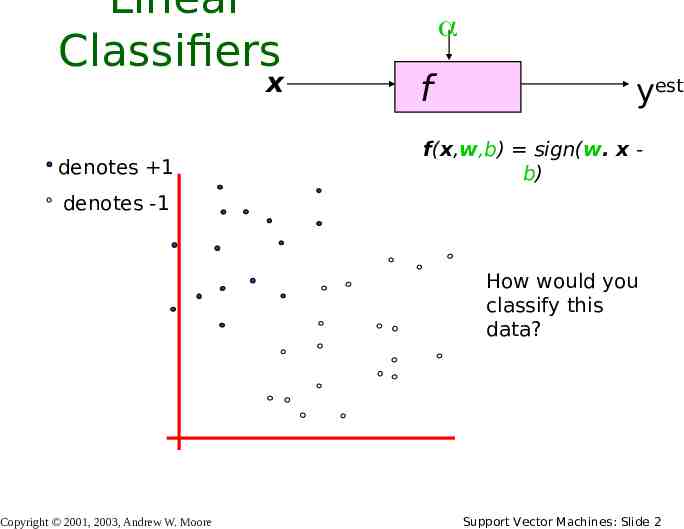
Linear Classifiers x denotes 1 f yest f(x,w,b) sign(w. x b) denotes -1 How would you classify this data? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 2
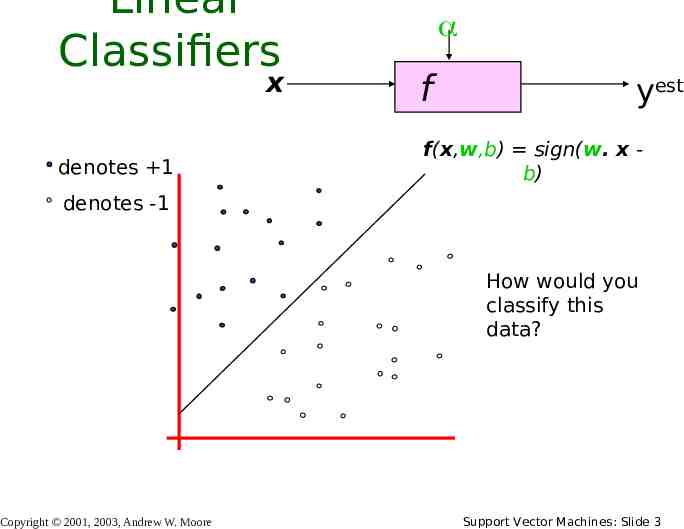
Linear Classifiers x denotes 1 f yest f(x,w,b) sign(w. x b) denotes -1 How would you classify this data? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 3
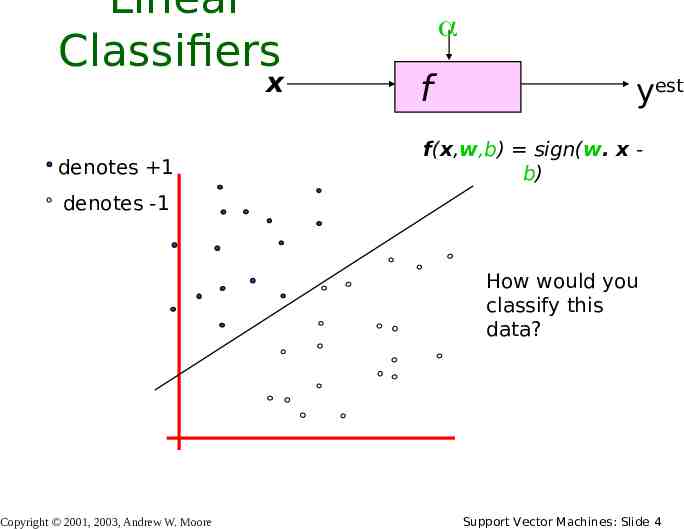
Linear Classifiers x denotes 1 f yest f(x,w,b) sign(w. x b) denotes -1 How would you classify this data? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 4
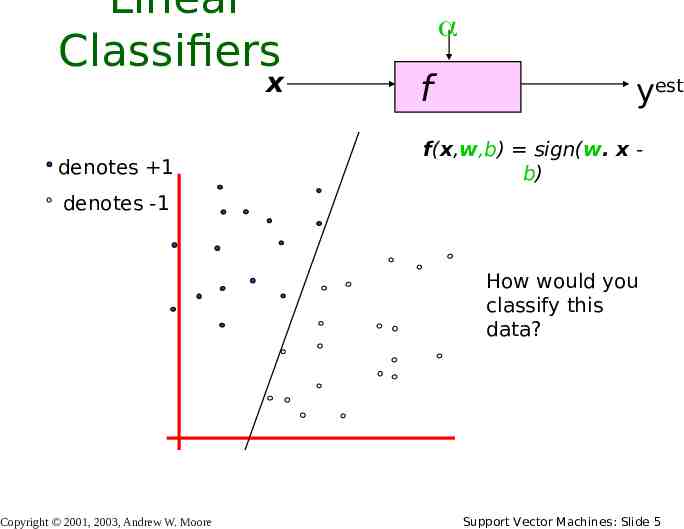
Linear Classifiers x denotes 1 f yest f(x,w,b) sign(w. x b) denotes -1 How would you classify this data? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 5
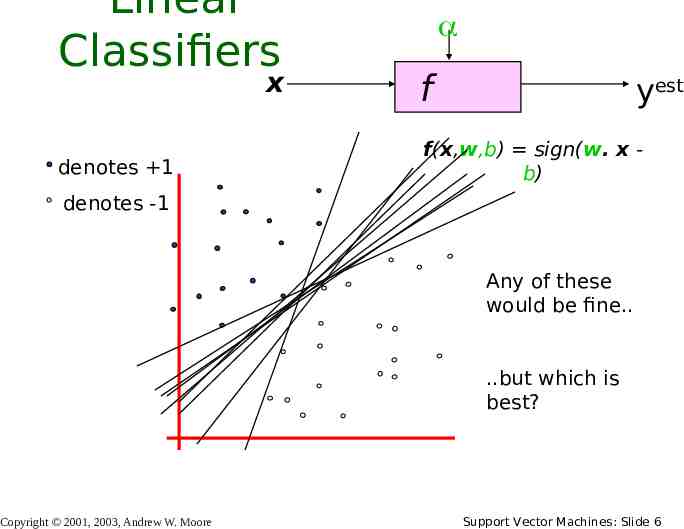
Linear Classifiers x denotes 1 f yest f(x,w,b) sign(w. x b) denotes -1 Any of these would be fine. .but which is best? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 6
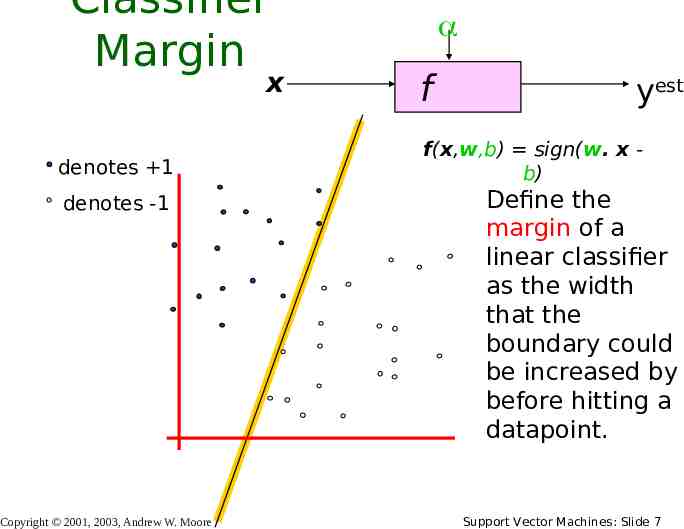
Classifier Margin x denotes 1 denotes -1 Copyright 2001, 2003, Andrew W. Moore f yest f(x,w,b) sign(w. x b) Define the margin of a linear classifier as the width that the boundary could be increased by before hitting a datapoint. Support Vector Machines: Slide 7
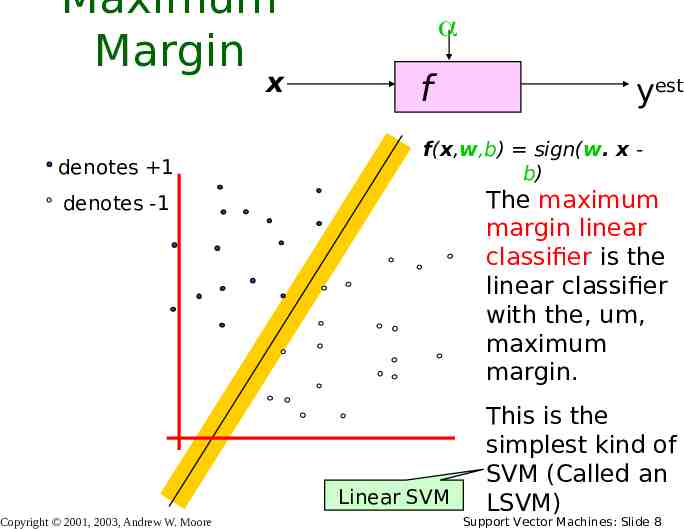
Maximum Margin x denotes 1 f f(x,w,b) sign(w. x b) The maximum margin linear classifier is the linear classifier with the, um, maximum margin. denotes -1 Linear SVM Copyright 2001, 2003, Andrew W. Moore yest This is the simplest kind of SVM (Called an LSVM) Support Vector Machines: Slide 8
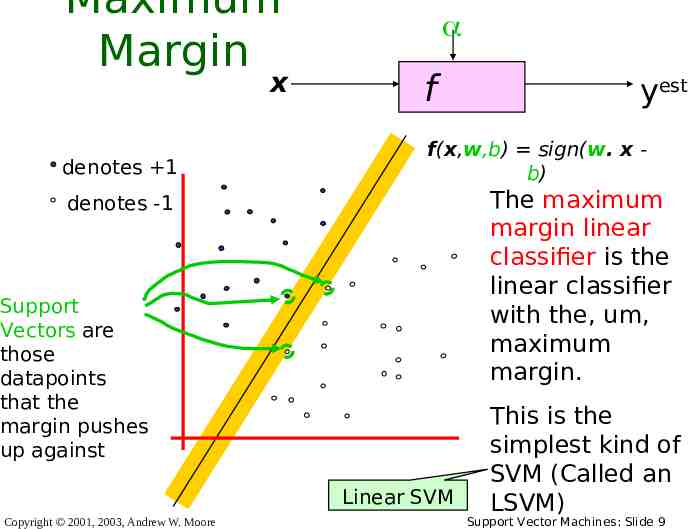
Maximum Margin x denotes 1 f f(x,w,b) sign(w. x b) The maximum margin linear classifier is the linear classifier with the, um, maximum margin. denotes -1 Support Vectors are those datapoints that the margin pushes up against Linear SVM Copyright 2001, 2003, Andrew W. Moore yest This is the simplest kind of SVM (Called an LSVM) Support Vector Machines: Slide 9
Why Maximum Margin? 1. Intuitively this feels safest. denotes 1 denotes -1 Support Vectors are those datapoints that the margin pushes up against Copyright 2001, 2003, Andrew W. Moore f(x,w,b) sign(w. 2. If we’ve made a small error x in- the b) location of the boundary (it’s The maximum been jolted in its perpendicular direction) this gives us least margin linear chance of causing a classifier is the misclassification. linear classifier 3. LOOCV is easy with since the, the model um, is immune to removal of any nonmaximum support-vector datapoints. margin. 4. There’s some theory (using VC is theto (but dimension) thatThis is related not the same as) the proposition simplest kind of that this is a good thing. SVM (Called an 5. Empirically it works very very LSVM) Support Vector Machines: Slide 10 well.
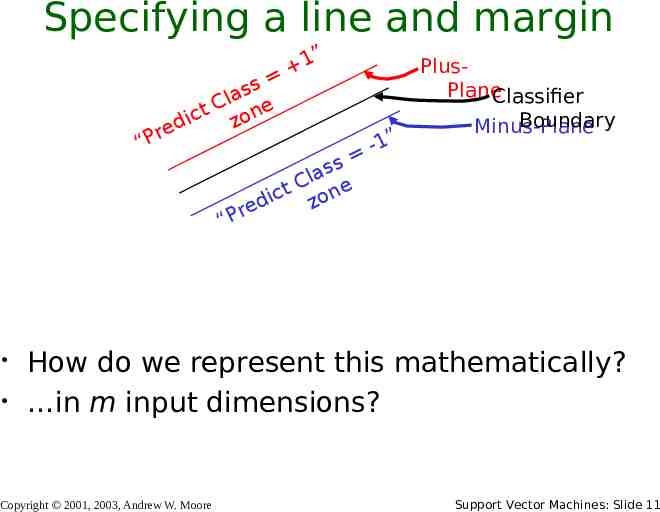
Specifying a line and margin “Pr s s la e C ict zon d e “ 1 ” s s la C t one c i d z e r P -1” PlusPlaneClassifier Boundary Minus-Plane How do we represent this mathematically? in m input dimensions? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 11
Specifying a line and margin “Pr s s la e C ict zon d e 1 b wx 0 b wx b 1 wx “ 1 ” s s la C t one c i d z e r P -1” PlusPlaneClassifier Boundary Minus-Plane Plus-plane { x : w . x b 1 } Minus-plane { x : w . x b -1 } Classify as. 1 if w . x b 1 -1 if w . x b -1 Universe explodes if -1 w . x b 1 Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 12
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx 1 ” M Margin Width s “P las C t one c i z red -1” How do we compute M in terms of w and b? Plus-plane { x : w . x b 1 } Minus-plane { x : w . x b -1 } Claim: The vector w is perpendicular to the Plus Plane. Why? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 13
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx 1 ” M Margin Width s “P las C t one c i z red -1” How do we compute M in terms of w and b? Plus-plane { x : w . x b 1 } Minus-plane { x : w . x b -1 } Claim: The vector w is perpendicular to the Plus Plane. Why? Let u and v be two vectors on And so of course the vector w is also perpendicular to the Minus Copyright 2001,Plane 2003, Andrew W. Moore the Plus Plane. What is w . ( u –v)? Support Vector Machines: Slide 14
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx “P 1 ” x x s las C t one c i z red M Margin Width -1” How do we compute M in terms of w and b? Plus-plane { x : w . x b 1 } Minus-plane { x : w . x b -1 } The vector w is perpendicular to the Plus Plane Any location in R ::not not Let x- be any point on the minus plane necessarily a Let x be the closest plus-plane-point to x-. datapoint Copyright 2001, 2003, Andrew W. Moore mm Support Vector Machines: Slide 15
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx “P 1 ” x x s las C t one c i z red M Margin Width -1” How do we compute M in terms of w and b? Plus-plane { x : w . x b 1 } Minus-plane { x : w . x b -1 } The vector w is perpendicular to the Plus Plane Let x- be any point on the minus plane Let x be the closest plus-plane-point to x-. Claim: x x- w for some value of . Why? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 16
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx 1 ” x M Margin Width The line from x- to x is perpendicular to 1” How do we sx s the planes. M in compute Cla t one c i z red terms of wxand So to get from to x travel b? some Plus-plane { x : w . x b distance 1 } in direction Minus-plane { x : w . x b w. -1 } The vector w is perpendicular to the Plus Plane Let x- be any point on the minus plane Let x be the closest plus-plane-point to x-. Claim: x x- w for some value of . Why? Copyright 2001, 2003, Andrew W. Moore “P Support Vector Machines: Slide 17
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx “P 1 ” x x s las C t one c i z red M Margin Width -1” What we know: w . x b 1 w . x- b -1 x x- w x - x- M It’s now easy to get M in terms of w and b Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 18
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx What we know: w . x b 1 w . x- b -1 x x- w x - x- M It’s now easy to get M in terms of w and b Copyright 2001, 2003, Andrew W. Moore “ 1 ” x M Margin Width -1” x s las C t one c i d z e w . (x r P - w) b 1 w . x - b w .w 1 -1 w .w 1 2 λ w.w Support Vector Machines: Slide 19
Computing the margin width e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx What we know: w . x b 1 w . x- b -1 x x- w x - x- M “ 1 ” x M Margin Width 2 w.w -1” x s las C t one c i d z e M x x r P w λ w λ w.w 2 w.w 2 w.w w.w 2 λ w.w Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 20
Learning the Maximum Margin Classifier e “Pr s s la e C t n dic zo 1 b wx 0 b wx b 1 wx “P 1 ” x x s las C t one c i z red M Margin Width 2 w.w -1” Given a guess of w and b we can Compute whether all data points in the correct half-planes Compute the width of the margin So now we just need to write a program to search the space of w’s and b’s to find the widest margin that matches all the datapoints. How? Gradient descent? Simulated Annealing? Matrix Inversion? EM? Newton’s Method? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 21
Learning via Quadratic Programming QP is a well-studied class of optimization algorithms to maximize a quadratic function of some real-valued variables subject to linear constraints. Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 22
Quadratic Programming Find T u Ru T arg max c d u 2 u Subject to a11u1 a12u2 . a1mu m b1 a21u1 a22u2 . a2 mum b2 : an1u1 an 2u 2 . anmum bn n additional linear inequality constraints a( n 1)1u1 a( n 1) 2u2 . a( n 1) mum b( n 1) a( n 2 )1u1 a( n 2) 2u2 . a( n 2 ) mum b( n 2 ) : a( n e )1u1 a( n e ) 2u2 . a( n e ) m um b( n e ) Copyright 2001, 2003, Andrew W. Moore e additional linear equality constraints And subject to Quadratic criterion Support Vector Machines: Slide 23
Quadratic Programming Find T u Ru T arg max c d u 2 u Subject to Quadratic criterion a11u1 a12u2 . a1mhumms r1 ob f gorit l a t ed s i n i x a e r t e s r a21uT1 h ea22u2 . cao2nmum b h c u h2 s c u g n m i d a fin ptim o c i t d a quadr : fficiently an more e an gradient an1u1 anre2ulia2 b ly.th anmt.um bn n additional linear inequality constraints : a( n e )1u1 a( n e ) 2u2 . a( n e ) m um b( n e ) Copyright 2001, 2003, Andrew W. Moore e additional linear equality constraints ascen ou y And subject y l fiadd u b y r e a u a u . v e to ( n 1)1 1 ( ne 1y) 2ar2 (w n a1n ) mt to m ( n 1) h t t ’ t n (Bu y do l b a b o a( n 2 )1u1 a(pn r 2) 2u2e on.e yoau( nr s2e)lmf)um b( n 2 ) writ Support Vector Machines: Slide 24
Learning the Maximum Margin Classifier “Pr s s Cla ne t ic zo ed 1 b wx 0 b wx b 1 wx “Pr ” 1 s s la C ict zone d e M -1” What should our quadratic optimization criterion be? Copyright 2001, 2003, Andrew W. Moore Given guess of w , b we can 2 Compute whether all data w.w points are in the correct half-planes Compute the margin width Assume R datapoints, each (xk,yk) where yk /- 1 How many constraints will we have? What should they be? Support Vector Machines: Slide 25
Learning the Maximum Margin Classifier “Pr s s Cla ne t ic zo ed 1 b wx 0 b wx b 1 wx “Pr ” 1 s s la C ict zone d e M -1” What should our quadratic optimization criterion be? Minimize w.w Given guess of w , b we can 2 Compute whether all data w.w points are in the correct half-planes Compute the margin width Assume R datapoints, each (xk,yk) where yk /- 1 How many constraints will we have? R What should they be? w . xk b 1 if yk 1 w . xk b -1 if yk -1 Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 26
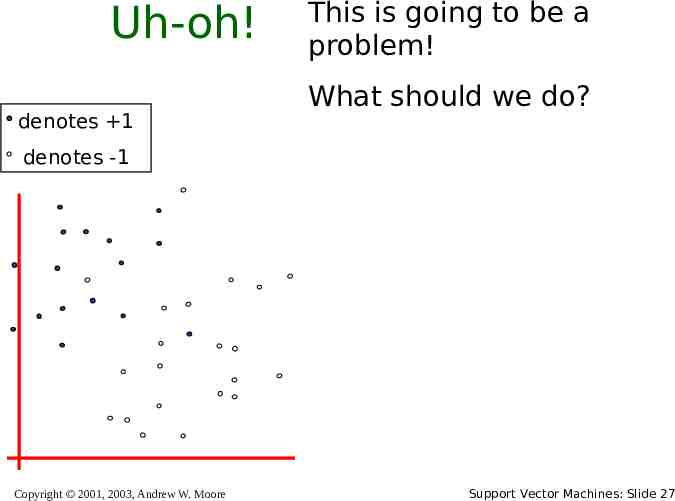
Uh-oh! denotes 1 This is going to be a problem! What should we do? denotes -1 Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 27
Uh-oh! denotes 1 denotes -1 This is going to be a problem! What should we do? Idea 1: Find minimum w.w, while minimizing number of training set errors. Problemette: Two things to minimize makes for an illdefined optimization Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 28
Uh-oh! denotes 1 denotes -1 This is going to be a problem! What should we do? Idea 1.1: Minimize w.w C (#train errors) Tradeoff parameter There’s a serious practical problem that’s about to make us reject this Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 29
Uh-oh! This is going to be a problem! What should we do? denotes 1 Idea 1.1: denotes -1 Minimize w.w C (#train errors) Tradeoff Can’t be expressed as a Quadratic parameter Programming problem. Solving it may be too slow. (Also, doesn’t distinguish between ny a o practical S disastrous errorsThere’s and near a serious other ? misses)problem that’s about ideas to make us reject this Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 30
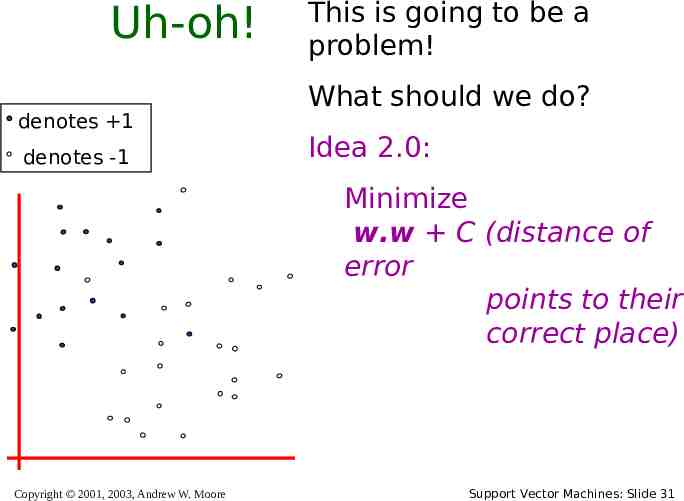
Uh-oh! denotes 1 denotes -1 This is going to be a problem! What should we do? Idea 2.0: Minimize w.w C (distance of error points to their correct place) Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 31
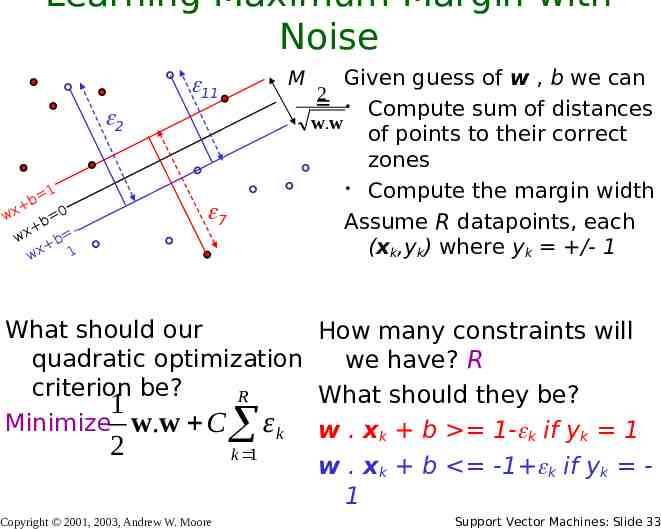
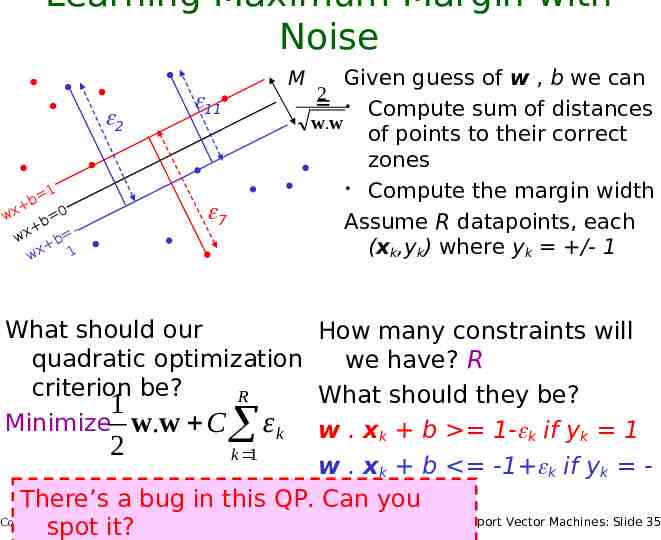
Learning Maximum Margin with Noise M Given guess of w , b we can 2 Compute sum of distances w.w 1 b wx 0 b wx b 1 wx of points to their correct zones Compute the margin width Assume R datapoints, each (xk,yk) where yk /- 1 What should our quadratic optimization criterion be? How many constraints will we have? What should they be? Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 32
Learning Maximum Margin with Noise M 11 2 1 b wx 0 b wx b 1 wx Given guess of w , b we can 2 Compute sum of distances w.w of points to their correct zones Compute the margin width Assume R datapoints, each (xk,yk) where yk /- 1 7 What should our How many constraints will quadratic optimization we have? R criterion be? R What should they be? 1 Minimize w.w C εk w . xk b 1- k if yk 1 2 Copyright 2001, 2003, Andrew W. Moore k 1 w . xk b -1 k if yk 1 Support Vector Machines: Slide 33
Learning Maximum Margin with Noise m # input Given guessdimension of w , b we can 2 11 Compute sums of distances w.w of points to their correct Our original (noiseless zones data) QP had m 1 variables: w1, w2, the wmargin Compute m, andwidth b. 7 Assume R datapoints, each (xk,yk) where yk /- 1 M 2 1 b wx 0 b wx b 1 wx Our new (noisy data) QP has m 1 R variables: w1, w2, wm, b, k , 1 , What should our R How many constraints will R # quadratic optimization we have? R records criterion be? R What should they be? 1 Minimize w.w C εk w . xk b 1- k if yk 1 2 Copyright 2001, 2003, Andrew W. Moore k 1 w . xk b -1 k if yk 1 Support Vector Machines: Slide 34
Learning Maximum Margin with Noise M 2 1 b wx 0 b wx b 1 wx 11 Given guess of w , b we can 2 Compute sum of distances w.w of points to their correct zones Compute the margin width Assume R datapoints, each (xk,yk) where yk /- 1 7 What should our How many constraints will quadratic optimization we have? R criterion be? R What should they be? 1 Minimize w.w C εk w . xk b 1- k if yk 1 2 k 1 w . xk b -1 k if yk 1 you There’s a bug in this QP. Can Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 35 spot it?
Learning Maximum Margin with Noise M 2 1 b wx 0 b wx b 1 wx 11 Given guess of w , b we can 2 Compute sum of distances w.w of points to their correct zones Compute the margin width Assume R datapoints, each (xk,yk) where yk /- 1 7 What should our How many constraints will we have? 2R quadratic optimization criterion be? What should they be? R 1 Minimize w.w C εk w . xk b 1- k if yk 1 2 k 1 w . xk b -1 k if yk -1 k 0 for all k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 36
QP Warning: up until Rong Zhang spotted my error in Oct 2003, this equation had been wrong in earlier versions of the notes. This version is correct. R 1 R R Maximi αk αk αl Qkl where Qkl y k yl ( x k .x l ) 2 k 1 l 1 ze k 1 Subject to these constraints: Then define: 0 αk C k R α k y k 0 k 1 R Then classify with: w αk yk x k f(x,w,b) sign(w. x - b) k 1 b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 37
An Equivalent QP Warning: up until Rong Zhang spotted my error in Oct 2003, this equation had been wrong in earlier versions of the notes. This version is correct. R 1 R R Maximi αk αk αl Qkl where Qkl y k yl ( x k .x l ) 2 k 1 l 1 ze k 1 Subject to these constraints: Then define: 0 αk C k R α k y k 0 k 1 Datapoints with k 0 will be the Then classify support vectors with: R w αk yk x k f(x,w,b) sign(w. x - b) .so this sum only b y K (1 ε K ) x K .w K needs to be over the support where K arg max αk vectors. k 1 k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 38
An Equivalent QP R 1 R R Maximi αk αk αl Qkl where Qkl y k yl ( x k .x l ) 2 k 1 l 1 ze k 1 Why did I tell you about thisR equivalent QP? k 0 α C Subject to αk k these It’s a formulation that QPk 1 constraints: packages can optimize Then define: Datapoints with k more quickly R w αk k 1 y k 0 0 will be the Thenjawclassify support vectors with: y xBecause of further k k dropping developments f(x,w,b) sign(w. x - b) sum only you’re about.so to this learn. b y K (1 ε K ) x K .w K where K arg max αk needs to be over the support vectors. k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 39
Suppose we’re in 1-dimension What would SVMs do with this data? x 0 Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 40
Suppose we’re in 1-dimension Not a big surprise x 0 Positive “plane” Copyright 2001, 2003, Andrew W. Moore Negative “plane” Support Vector Machines: Slide 41
Harder 1-dimensional dataset That’s wiped the smirk off SVM’s face. What can be done about this? x 0 Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 42
Harder 1-dimensional dataset Remember how permitting nonlinear basis functions made linear regression so much nicer? Let’s permit them here too x 0 Copyright 2001, 2003, Andrew W. Moore z k ( xk , xk2 ) Support Vector Machines: Slide 43
Harder 1-dimensional dataset Remember how permitting nonlinear basis functions made linear regression so much nicer? Let’s permit them here too x 0 Copyright 2001, 2003, Andrew W. Moore z k ( xk , xk2 ) Support Vector Machines: Slide 44
Common SVM basis functions zk ( polynomial terms of xk of degree 1 to q) zk ( radial basis functions of x kx)k c j z k [ j ] φ j (x k ) KernelFn KW zk ( sigmoid functions of xk ) This is sensible. Is that the end of the story? Copyright 2001, 2003, Andrew W. Moore No there’s one more trick! Support Vector Machines: Slide 45
1 Constant Term 2 x1 2 x2 Linear Terms : 2 x m 2 x1 2 Pure x 2 Quadratic : Terms 2 xm Φ(x) 2 x1 x2 2 x1 x3 : 2 x1 xm Quadratic Cross-Terms 2 x x 2 3 : 2 x x 1 m : 2 xm 1 xm Copyright 2001, 2003, Andrew W. Moore Basis Functions Number of terms (assuming m input dimensions) (m 2)choose-2 (m 2)(m 1)/2 (as near as makes no difference) m2/2 2 You may be wondering what those ’s are doing. You should be happy that they do no harm You’ll find out why they’re there Support Vector Machines: Slide 46 soon.
QP with basis functions Warning: up until Rong Zhang spotted my error in Oct 2003, this equation had been wrong in earlier versions of the notes. This version is correct. R 1 R R αk αl Qkl where Qkl yk yl (Φ(x k ).Φ(x l )) Maximize αk 2 k 1 l 1 k 1 Subject to these constraints: Then define: w 0 αk C k R α k y k 0 k 1 α k y k Φ( x k ) k s.t. α k 0 Then classify with: f(x,w,b) sign(w. (x) - b) b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 47
QP with basis functions R 1 R R αk αl Qkl where Qkl yk yl (Φ(x k ).Φ(x l )) Maximize αk 2 k 1 l 1 k 1 Subject to these constraints: Then define: w We must do R2/2 dot products to get this matrixRready. 0 αk CEach dot k product α k y km 0 requires /2 2 k 1 additions and multiplications The whole thing costs R2 m2 /4. Yeeks! α k y k Φ( x k ) k s.t. α k 0 or does it? Then classify with: f(x,w,b) sign(w. (x) - b) b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 48
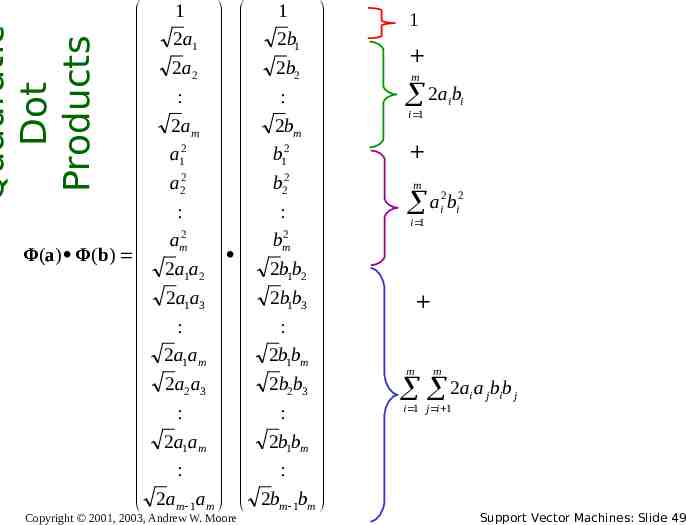
Quadratic Dot Products 1 1 2a1 2b1 2 a2 2b2 : : 2 a 2 b m m 2 2 b1 a1 2 2 a b 2 2 : : 2 2 a b m m Φ(a) Φ(b) 2a1a2 2b1b2 2a1a3 2b1b3 : : 2a1am 2b1bm 2 a a 2 b b 2 3 2 3 : : 2 a a 2 b b 1 m 1 m : : 2am 1am 2bm 1bm Copyright 2001, 2003, Andrew W. Moore 1 m 2a b i i i 1 m 2 2 a i bi i 1 m m 2a a b b i j i j i 1 j i 1 Support Vector Machines: Slide 49
Quadratic Dot Products Just out of casual, innocent, interest, let’s look at another function of a and b: (a.b 1) 2 (a.b) 2 2a.b 1 m ai bi 2 ai bi 1 i 1 i 1 Φ(a) Φ(b) m m m 2 2 i i m 1 2 ai bi a b i 1 2 m i 1 i j i m ai bi a j b j 2 ai bi 1 m 2a a b b m j i 1 j 1 i 1 i 1 j i 1 m 2 m (ai bi ) 2 i 1 Copyright 2001, 2003, Andrew W. Moore m aba b i 1 j i 1 i i j m j 2 ai bi 1 i 1 Support Vector Machines: Slide 50
Quadratic Dot Products Just out of casual, innocent, interest, let’s look at another function of a and b: (a.b 1) 2 (a.b) 2 2a.b 1 m ai bi 2 ai bi 1 i 1 i 1 Φ(a) Φ(b) m m m 2 2 i i m 1 2 ai bi a b i 1 2 m i 1 i j i m ai bi a j b j 2 ai bi 1 m 2a a b b m j i 1 j 1 i 1 i 1 j i 1 m 2 m (ai bi ) 2 i 1 m aba b i 1 j i 1 i i j m j 2 ai bi 1 i 1 They’re the same! And this is only O(m) to compute! Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 51
QP with Quadratic basis functions Warning: up until Rong Zhang spotted my error in Oct 2003, this equation had been wrong in earlier versions of the notes. This version is correct. R 1 R R αk αl Qkl where Qkl yk yl (Φ(x k ).Φ(x l )) Maximize αk 2 k 1 l 1 k 1 Subject to these constraints: Then define: w We must do R2/2 dot products to get this matrixRready. 0 αk CEach dot k product y k 0 nowαkonly k 1 and requires m additions multiplications α k y k Φ( x k ) k s.t. α k 0 Then classify with: f(x,w,b) sign(w. (x) - b) b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 52
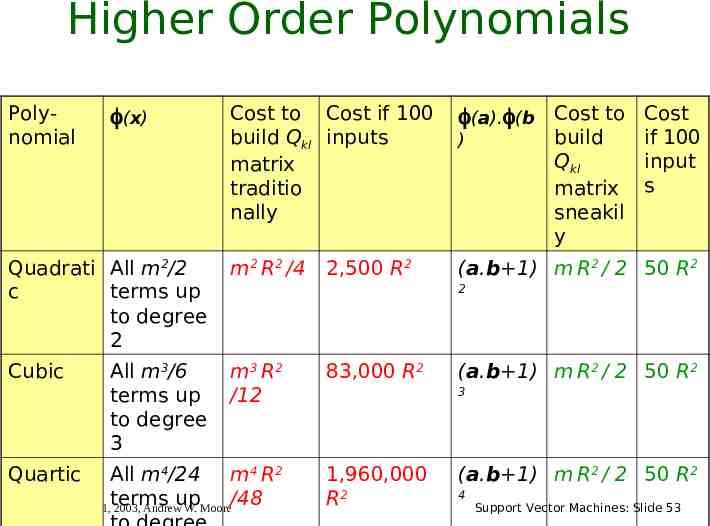
Higher Order Polynomials Polynomial Cost to Cost if 100 build Qkl inputs matrix traditio nally (a). (b Cost to Cost Quadrati All m2/2 c terms up to degree 2 m2 R2 /4 (a.b 1) m R2 / 2 50 R2 Cubic m3 R2 /12 83,000 R2 All m4/24 m4 R2 terms up /48 Copyright 2001, 2003, Andrew W. Moore 1,960,000 R2 Quartic (x) All m3/6 terms up to degree 3 2,500 R2 ) build if 100 Qkl input matrix s sneakil y 2 (a.b 1) m R2 / 2 50 R2 3 (a.b 1) m R2 / 2 50 R2 4 Support Vector Machines: Slide 53
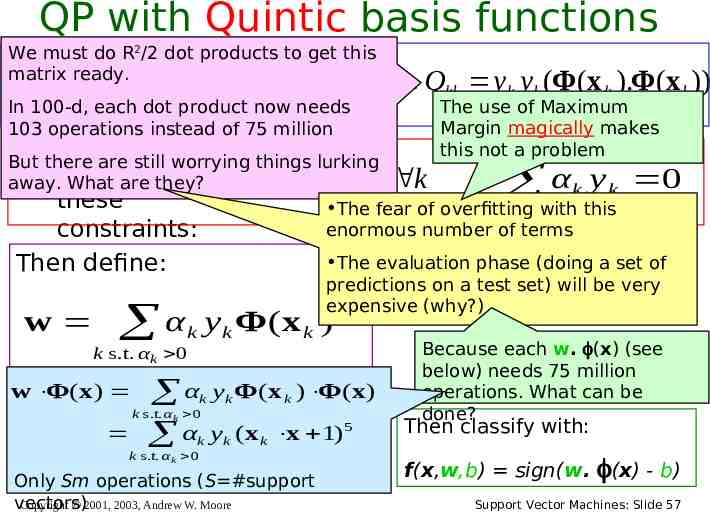
QP with Quintic basis functions We must do RR2/2 dot products to get this R R matrix ready. where Maximi k k l kl In 100-d, each k 1 dot product k 1 l 1now needs ze 103 operations instead of 75 million α α α Q But there are still worrying things lurking Subject to away. What are they? k 0 α C k these constraints: Then define: w α k k s.t. α k 0 Qkl yk yl (Φ(x k ).Φ(x l )) R α k y k 0 k 1 y k Φ( x k ) b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore Then classify with: f(x,w,b) sign(w. (x) - b) Support Vector Machines: Slide 54
QP with Quintic basis functions We must do RR2/2 dot products to get this R R matrix ready. where Maximi k k l kl In 100-d, each k 1 dot product k 1 l 1now needs ze 103 operations instead of 75 million α α α Q Qkl yk yl (Φ(x k ).Φ(x l )) R But there are still worrying things lurking Subject to away. What are they? k k k these The fear of overfitting k 1with this enormous number of terms constraints: 0 α C k Then define: w α k k s.t. α k 0 α y 0 The evaluation phase (doing a set of predictions on a test set) will be very expensive (why?) y k Φ( x k ) b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore Then classify with: f(x,w,b) sign(w. (x) - b) Support Vector Machines: Slide 55
QP with Quintic basis functions We must do RR2/2 dot products to get this R R matrix ready. where Maximi k k l kl In 100-d, each k 1 dot product k 1 l 1now needs ze 103 operations instead of 75 million α α α Q Qkl yk yl (Φ(x k ).Φ(x l )) The use of Maximum Margin magically makes this not aRproblem But there are still worrying things lurking Subject to away. What are they? k k k these The fear of overfitting k 1with this enormous number of terms constraints: 0 α C k Then define: w α k k s.t. α k 0 y 0 The evaluation phase (doing a set of predictions on a test set) will be very expensive (why?) y k Φ( x k ) b y K (1 ε K ) x K .w K where K arg max αk k Copyright 2001, 2003, Andrew W. Moore α Because each w. (x) (see below) needs 75 million operations. What can be done? Then classify with: f(x,w,b) sign(w. (x) - b) Support Vector Machines: Slide 56
QP with Quintic basis functions We must do RR2/2 dot products to get this R R matrix ready. where Maximi k k l kl In 100-d, each k 1 dot product k 1 l 1now needs ze 103 operations instead of 75 million α α α Q Qkl yk yl (Φ(x k ).Φ(x l )) The use of Maximum Margin magically makes this not aRproblem But there are still worrying things lurking Subject to away. What are they? k k k these The fear of overfitting k 1with this enormous number of terms constraints: 0 α C k Then define: w α k k s.t. α k 0 y k Φ( x k ) k s.t. α k 0K K K 5 α y ( x x 1 ) k k k where K arg max α k s.t. α k 0 y 0 The evaluation phase (doing a set of predictions on a test set) will be very expensive (why?) w Φ(y x) x k ) . w Φ( x) b (1 εαk y)k Φ (x K α k Only Sm operations (S #support vectors) Copyright 2001, 2003, Andrew W. Moore k Because each w. (x) (see below) needs 75 million operations. What can be done? Then classify with: f(x,w,b) sign(w. (x) - b) Support Vector Machines: Slide 57
QP with Quintic basis functions We must do RR2/2 dot products to get this R R matrix ready. where Maximi k k l kl In 100-d, each k 1 dot product k 1 l 1now needs ze 103 operations instead of 75 million α α α Q Qkl yk yl (Φ(x k ).Φ(x l )) The use of Maximum Margin magically makes this not aRproblem But there are still worrying things lurking Subject to away. What are they? k k k these The fear of overfitting k 1with this enormous number of terms constraints: 0 α C k Then define: w α k k s.t. α k 0 y k Φ( x k ) k s.t. α k 0K K K 5 α y ( x x 1 ) k k k where K arg max α k s.t. α k 0 y 0 The evaluation phase (doing a set of predictions on a test set) will be very expensive (why?) w Φ(y x) x k ) . w Φ( x) b (1 εαk y)k Φ (x K α k Only Sm operations (S #support vectors) Copyright 2001, 2003, Andrew W. Moore k Because each w. (x) (see below) needs 75 million operations. What can be done? Then When classify you see this with: many callout bubbles on a slide it’s time to wrap the author in a blanket, gently take f(x,w,b) sign(w. (x) - b) him away and murmur “someone’s been at the PowerPoint for too long.” Support Vector Machines: Slide 58
QP with Quintic basis functions R 1 R R Andrew’s of why αk αl Qkl where Qkl opinion yk yl (Φ (x k ).SVMs Φ(x l )) Maximize αk don’t overfit as much as you’d 2 k 1 l 1 k 1 think: Subject to these constraints: Then define: R the basis No matter what function, there are really only up k k to R parameters: k 1 1, 2 . R, and usually most are set to zero by the Maximum Margin. 0 αk C k α y 0 Asking for small w.w is like “weight decay” in Neural Nets and like Ridge Regression k k k parameters in Linear regression k s.t. α k 0 and like the use of Priors in w Φ(x) αk y k Φ( x k ) Φ( x) Bayesian Regression---all K k s.t. α k 0K K K designed to smooth the function 5 Then classify with: and reduce overfitting. αk y k ( x k x 1) w α y Φ( x ) b y (1 ε ) x .w where K arg max αk k s.t. α 0 k k Only Sm operations (S #support vectors) Copyright 2001, 2003, Andrew W. Moore f(x,w,b) sign(w. (x) - b) Support Vector Machines: Slide 59
SVM Kernel Functions K(a,b) (a . b 1)d is an example of an SVM Kernel Function Beyond polynomials there are other very high dimensional basis functions that can be made practical by finding the right Kernel Function Radial-Basis-style Kernel (a b) 2 Function: , and are K (a, b) exp magic parameters that must be chosen by a model selection method Neural-net-style Kernel Function: such as CV or K (a, b) tanh( a.b ) VCSRM* 2 2 *see last lecture Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 60
VC-dimension of an SVM Very very very loosely speaking there is some theory which under some different assumptions puts an upper bound on the VC dimension as Diameter Margin where Diameter is the diameter of the smallest sphere that can enclose all the high-dimensional termvectors derived from the training set. Margin is the smallest margin we’ll let the SVM use This can be used in SRM (Structural Risk Minimization) for choosing the polynomial degree, RBF , etc. But most people just use Cross-Validation Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 61
SVM Performance Anecdotally they work very very well indeed. Example: They are currently the best-known classifier on a well-studied hand-writtencharacter recognition benchmark Another Example: Andrew knows several reliable people doing practical real-world work who claim that SVMs have saved them when their other favorite classifiers did poorly. There is a lot of excitement and religious fervor about SVMs as of 2001. Despite this, some practitioners (including your lecturer) are a little skeptical. Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 62
classification SVMs can only handle two-class outputs (i.e. a categorical output variable with arity 2). What can be done? Answer: with output arity N, learn N SVM’s SVM 1 learns “Output 1” vs “Output ! 1” SVM 2 learns “Output 2” vs “Output ! 2” : SVM N learns “Output N” vs “Output ! N” Then to predict the output for a new input, just predict with each SVM and find out which one puts the prediction the furthest into the positive region. Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 63
References An excellent tutorial on VC-dimension and Support Vector Machines: C.J.C. Burges. A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery, 2(2):955-974, 1998. http://citeseer.nj.nec.com/burges98tutorial.ht ml The VC/SRM/SVM Bible: Statistical Learning Theory by Vladimir Vapnik, Wiley-Interscience; 1998 Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 64
What You Should Know Linear SVMs The definition of a maximum margin classifier What QP can do for you (but, for this class, you don’t need to know how it does it) How Maximum Margin can be turned into a QP problem How we deal with noisy (non-separable) data How we permit non-linear boundaries How SVM Kernel functions permit us to pretend we’re working with ultra-highdimensional basis-function terms Copyright 2001, 2003, Andrew W. Moore Support Vector Machines: Slide 65






