SPSS Tutorial Ángel M. Ramos Domínguez Curso de Doctorado




































42 Slides638.50 KB
SPSS Tutorial Ángel M. Ramos Domínguez Curso de Doctorado Análisis Conjunto
Análisis Cluster Guía Análisis Cluster Ejemplo de análisis cluster Trabajo sobre asignación
Análisis Cluster Es una clase de técnicas utilizadas para clasificar casos en grupos que son relativamente homogéneos dentro de si mismos y heterogéneos entre ellos, sobre la base de un conjunto definido de variables. Estos grupos se llaman Clusters o Conglomerados.
Análisis Cluster e Investigación de mercados Segmentación de Mercados. Agrupamiento de consumidores de acuerdo a sus preferencias de atributos Comprender el comportamiento de los compradores. Los consumidores con similares comportamientos/características son agrupados juntos. Identificar oportunidades de nuevos productos. Los clusters de similares marcas/productos pueden ayudar a identificar competidores/oportunidades de mercado Reducción de los datos. En mapas de preferencias
Etapas de un Análisis cluster 1. Seleccionar una medida de distancia 2. Seleccionar un algoritmo de agrupamiento 3. Determinar el número de clusters 4. Validar el análisis
3 REGR factor score 1 for analysis 1 2 1 0 -1 -2 -3 -4 -3 -2 -1 0 REGR factor score 2 for analysis 1 2 1 3 4
Definición de la distancia: La distancia Euclídea n Dij x ki k 1 xkj 2 Dij distancia entre los casos i y j xki valor de la variable Xk para el caso j Problemas: Diferentes medidas diferentes ponderaciones Correlación entre variables (redundancia) Solución: Análisis de componentes principales
Procedimientos de Clustering Procedimientos jerarquicos – Aglomerativo (comienza desde n clusters, hasta llegar a obtener 1 cluster) – Divisivo (comienza desde 1 cluster, hasta obtener n cluster) Procedimientos no jerarquicos – Cluster de K-medias
Agrupamiento aglomerativo
Agrupamiento aglomerativo Métodos de enlace – – – Enlace simple (distancia mínima) Enlace Completo (distancia máxima) Enlace promedio Método de Ward 1. 2. Calcular la suma de las distancias al cuadrado dentro de los clusters Agregar clusters con incremento mínimo en la suma de cuadrados total Método del centroide – La distancia entre dos clusters se define como la distancia entre los centroides (medias de los cluster)
Cluster de K-medias 1. 2. El número k de clusters es fijo Se proporciona un conjunto inicial de k “semillas” (centros de agregación) 3. K primeros elementos Otras semillas Dado un cierto umbral, todas unidades son asignadas a la más cercana semilla del grupo 4. Se calculan nuevas semillas 5. Volver a la etapa 3 hasta que no sea necesaria una reclasificación Las unidades pueden ser reasingnadas en etapas sucesivas (partición óptima)
Métodos jerarquicos vs no jerarquicos Agrupamiento jerarquico No hay decisión acerca del número de clusters Existen problemas cuando los datos contienen un alto nivel de error Puede ser muy lento La decisión inicial influye mucho (una etapa única) Agrupamiento no jerarquico Más rápido, más fíable Es necesario especificar el número de clusters (arbitrario) Es necesario establecer la semilla inicial (arbitrario)
Método sugerido 1. Primero ejecutar un método jerárquico para definir el número de clusters 2. Luego utilizar el procedimiento kmedias para formar los clusters
Definición del número de clusters: regla del codazo (1) Agglomeration Schedule n Stage Number of clusters 0 12 1 11 2 10 3 9 4 8 5 7 6 6 7 5 8 4 9 3 10 2 11 1 Stage 1 2 3 4 5 6 7 8 9 10 11 Cluster Combined Cluster 1 Cluster 2 Coefficients 4 7 .015 6 10 .708 8 9 .974 4 8 1.042 1 6 1.100 4 5 3.680 1 4 3.492 1 11 6.744 1 2 8.276 1 12 8.787 1 3 11.403 Stage Cluster First Appears Cluster 1 Cluster 2 Next Stage 0 0 4 0 0 5 0 0 4 1 3 6 0 2 7 4 0 7 5 6 8 7 0 9 8 0 10 9 0 11 10 0 0
12 Regla del codazo (2): El diagram scree 10 Distance 8 6 4 2 0 11 10 9 8 7 6 5 Number of clusters 4 3 2 1
Validación del análisis Impacto de las semillas iniciales / orden de los casos Impacto del método seleccionado Considerar la relevancia del conjunto de variables elegido
SPSS Example
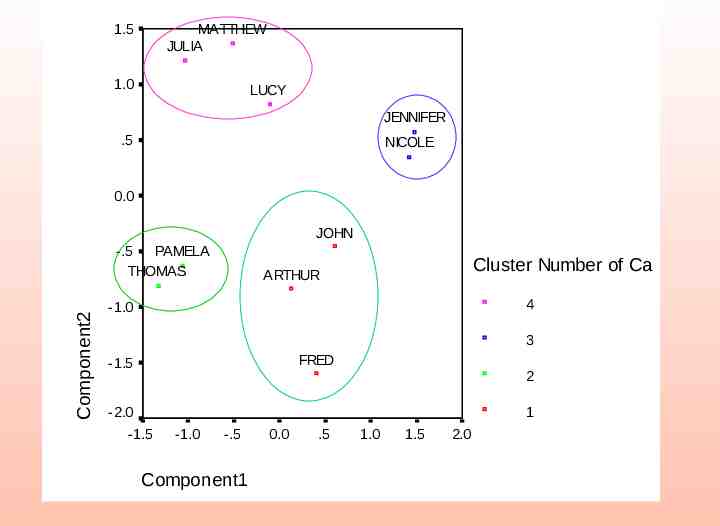
MATTHEW 1.5 JULIA 1.0 LUCY JENNIFER .5 NICOLE 0.0 JOHN -.5 PAMELA THOMAS ARTHUR Component2 -1.0 FRED -1.5 -2.0 -1.5 -1.0 Component1 -.5 0.0 .5 1.0 1.5 2.0
Agglomeration Schedule Stage 1 2 3 4 5 6 7 8 9 Cluster Combined Cluster 1 Cluster 2 3 6 2 5 4 9 1 7 4 10 1 8 1 2 3 4 1 3 Coefficients .026 .078 .224 .409 .849 1.456 4.503 9.878 18.000 Stage Cluster First Appears Cluster 1 Cluster 2 0 0 0 0 0 0 0 0 3 0 4 0 6 2 1 5 7 8 Number of clusters: 10 – 6 4 Next Stage 8 7 5 6 8 7 9 9 0
1.5 MATTHEW JULIA 1.0 LUCY JENNIFER .5 NICOLE 0.0 JOHN Component2 -.5 PAMELA THOMAS Cluster Number of Ca ARTHUR 4 -1.0 3 FRED -1.5 2 -2.0 1 -1.5 -1.0 -.5 Component1 0.0 .5 1.0 1.5 2.0
Open the dataset supermarkets.sav From your N: directory (if you saved it there last time Or download it from: http://www.rdg.ac.uk/ aes02mm/ supermarket.sav http://www.rdg.ac.uk/ aes02mm/ supermarket.sav Open it in SPSS
The supermarkets.sav dataset
Run Principal Components Analysis and save scores Select the variables to perform the analysis Set the rule to extract principal components Give instruction to save the principal components as new variables
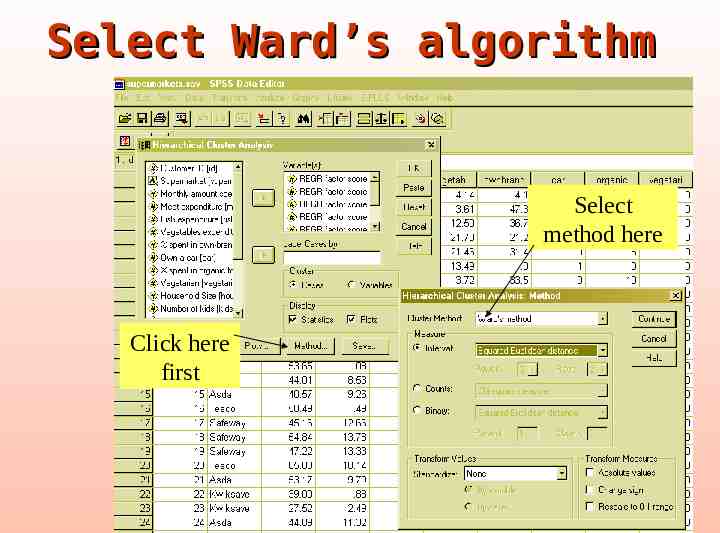
Cluster analysis: basic steps Apply Ward’s methods on the principal components score Check the agglomeration schedule Decide the number of clusters Apply the k-means method
Analyse / Classify
Select the component scores Select from here Untick this
Select Ward’s algorithm Select method here Click here first
Output: Agglomeration schedule
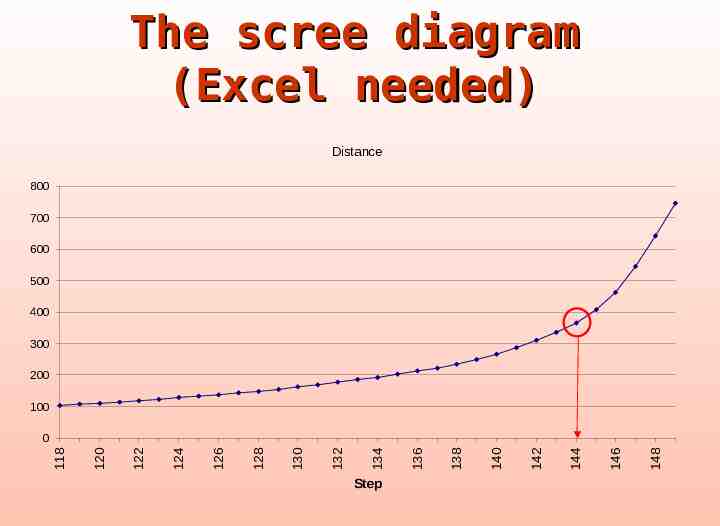
Number of clusters Identify the step where the “distance coefficients” makes a bigger jump
The scree diagram (Excel needed) Distance 800 700 600 500 400 300 200 100 Step 148 146 144 142 140 138 136 134 132 130 128 126 124 122 120 118 0
Number of clusters Number of cases 150 Step of ‘elbow’ 144 Number of clusters 6
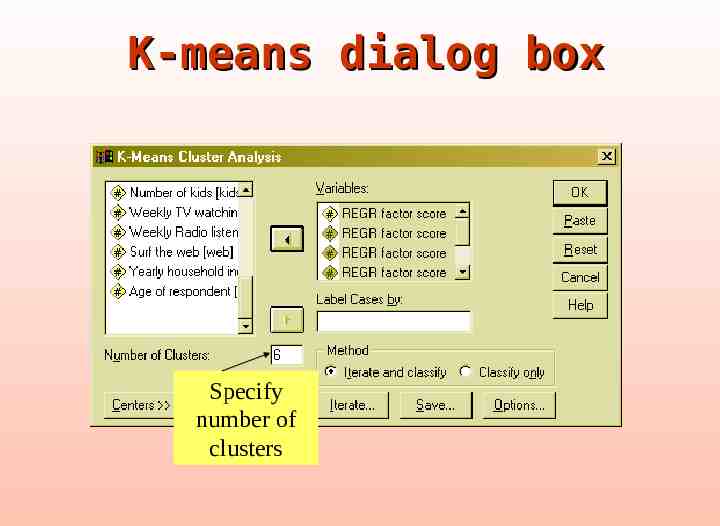
Now repeat the analysis Choose the k-means technique Set 6 as the number of clusters Save cluster number for each case Run the analysis
K-means
K-means dialog box Specify number of clusters
Save cluster membership Click here first Thick here
Final output
Cluster membership
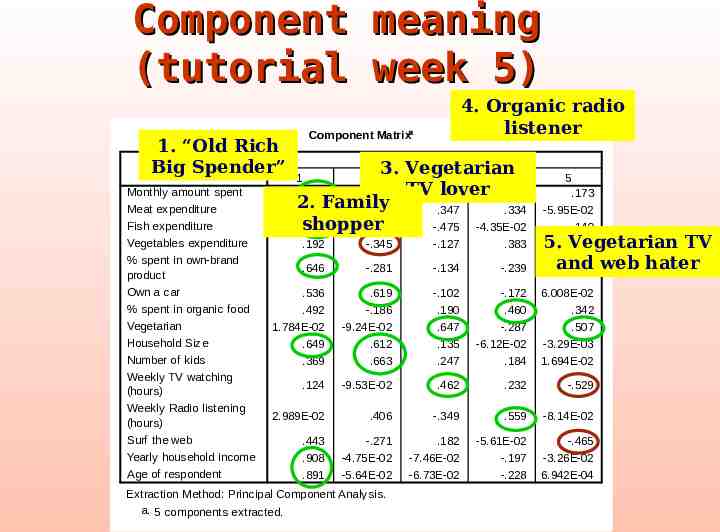
Component meaning (tutorial week 5) 1. “Old Rich Big Spender” Monthly amount spent Meat expenditure Fish expenditure Vegetables expenditure % spent in own-brand product Own a car % spent in organic food Vegetarian Household Size Number of kids Weekly TV watching (hours) Weekly Radio listening (hours) Surf the web Yearly household income Age of respondent 4. Organic radio listener Component Matrixa Component 3. Vegetarian 1 2 3 4 TV lover .810 -.294 -4.26E-02 .183 2. Family .480 -.152 .347 .334 shopper .525 -.206 -.475 -4.35E-02 5 .173 -5.95E-02 .140 5. Vegetarian .199 TV and -.207 web hater .192 -.345 -.127 .383 .646 -.281 -.134 -.239 .536 .492 1.784E-02 .649 .369 .619 -.186 -9.24E-02 .612 .663 -.102 .190 .647 .135 .247 -.172 .460 -.287 -6.12E-02 .184 6.008E-02 .342 .507 -3.29E-03 1.694E-02 .124 -9.53E-02 .462 .232 -.529 2.989E-02 .406 -.349 .559 -8.14E-02 .443 .908 .891 -.271 -4.75E-02 -5.64E-02 .182 -7.46E-02 -6.73E-02 -5.61E-02 -.197 -.228 -.465 -3.26E-02 6.942E-04 Extraction Method: Principal Component Analysis. a. 5 components extracted.
Final Cluster Centers Cluster 1 REGR factor score 1 for analysis 1 REGR factor score 2 for analysis 1 REGR factor score 3 for analysis 1 REGR factor score 4 for analysis 1 REGR factor score 5 for analysis 1 2 3 4 5 6 -1.34392 .21758 .13646 .77126 .40776 .72711 .38724 -.57755 -1.12759 .84536 .57109 -.58943 -.22215 -.09743 1.41343 .17812 1.05295 -1.39335 .15052 -.28837 -.30786 1.09055 -1.34106 .04972 .04886 -.93375 1.23631 -.11108 .31902 .87815
Cluster interpretation through mean component values Cluster 1 is very far from profile 1 (-1.34) and more similar to profile 2 (0.38) Cluster 2 is very far from profile 5 (-0.93) and not particularly similar to any profile Cluster 3 is extremely similar to profiles 3 and 5 and very far from profile 2 Cluster 4 is similar to profiles 2 and 4 Cluster 5 is very similar to profile 3 and very far from profile 4 Cluster 6 is very similar to profile 5 and very far from profile 3
Which cluster to target? Objective: target the organic consumer Which is the cluster that looks more “organic”? Compute the descriptive statistics on the original variables for that cluster
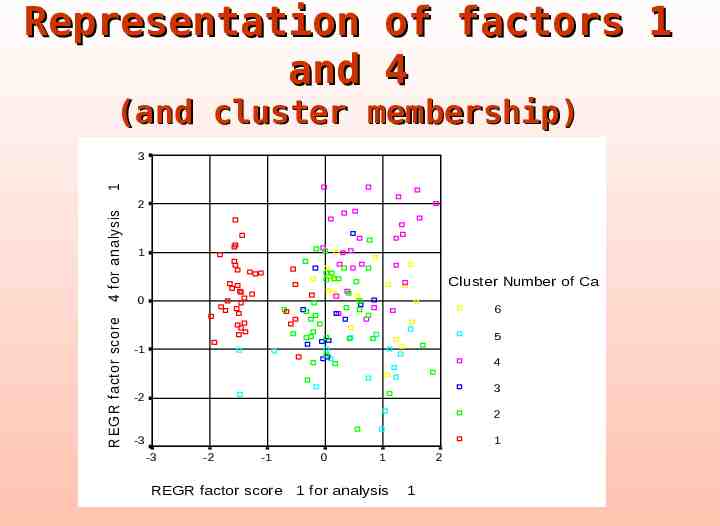
Representation of factors 1 and 4 (and cluster membership) REG R factor score 4 for analysis 1 3 2 1 Cluster Number of Ca 0 6 5 -1 4 3 -2 2 -3 1 -3 -2 -1 REGR factor score 0 1 1 for analysis 2 1






