Spark Sisters Shuchen Song, Bei Pang 1





























38 Slides2.43 MB
Spark Sisters Shuchen Song, Bei Pang 1
Spark Overview DAG RDD - Partition RDD - cache/spill Shuffle 2
TR-Spark: Transient Computing for Big Data Analytics 3
TR-Spark: Transient Computing for Big Data Analytics Motivation: Investment of billions of dollars on cloud infrastructures Low average utilization of provisioned server capacity Competitive pressure to increase utilization Reasons for the low utilization: Some capacity is required as buffer to handle failures Demand fluctuation causes capacity to be unused Over-provisioning servers for load spikes Churn induces empty capacity 4
To Increase Server Capacity Utilization Solution: Run delay-insensitive or non-customer facing workloads with temporarily spare capacities. Ideal for expensive but not latency critical tasks: Big data analytic tasks Machine learning training Challenge: Existing tools,MapReduce and Spark, are designed as primary tasks Performance of these applications is severely compromised on transient resources 5
TR-Spark Principle modules: Resource stability and data size reduction-aware scheduling Lineage-aware checkpointing Intuitively: Re-computation cost can be reduced by checkpointing The number of re-computation can be reduced by prioritized scheduling Trade-off is necessary between checkpointing and re-computation 6
TR-Scheduling The task selection is done through scanning the non-blocking tasks (no need to wait for other tasks to finish) ordered according to a certain priority rule. TR-Scheduling priority rule: Task’s output and input data sizes: A task which generates less output data than it takes in as input, effectively reduces the size of data for checkpointing and checkpointing costs. Task’s execution time and success probability: A task with shorter execution time has less risk of being impacted by a failure (the VM’s success probability exceeds threshold γ, 7
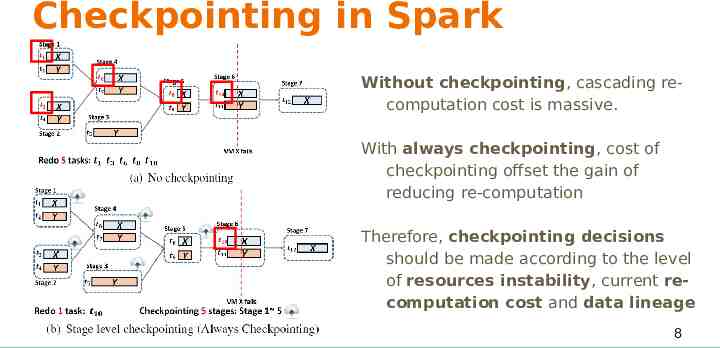
Checkpointing in Spark Without checkpointing, cascading recomputation cost is massive. With always checkpointing, cost of checkpointing offset the gain of reducing re-computation Therefore, checkpointing decisions should be made according to the level of resources instability, current recomputation cost and data lineage 8
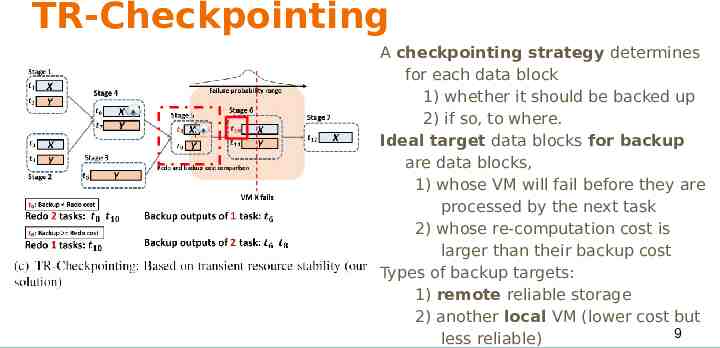
TR-Checkpointing A checkpointing strategy determines for each data block 1) whether it should be backed up 2) if so, to where. Ideal target data blocks for backup are data blocks, 1) whose VM will fail before they are processed by the next task 2) whose re-computation cost is larger than their backup cost Types of backup targets: 1) remote reliable storage 2) another local VM (lower cost but 9 less reliable)
Cost Estimation Essential for effective TRCheckpointing and TR-Scheduling Use probability approach to estimate costs of various decisions: Transient Resource Instability Re-computation Cost Backup Cost (remote & local) Transient Resource Instability: Given this VM’s failure PDF f(x): Assume that a VM v has been running for time τ. The probability that v will fail at time t: The expected lifetime of v between time ti and tj is: If the exact VM lifetime distribution is not available, collect VMs’ historical lifetime 10
Re-computation Cost Re-computation Cost: Ck is the running time (cost) of task k. The re-computation of task k’s output block bk is a cascading process. The re- SetN is the set of k’s dependent tasks whose computation cost is the sum of task k and all of k’s parent tasks. Er(t,k) is the expected re-computation cost of task k if the Vm fails at time t. SetA is the set of k’s dependent tasks whose data blocks are lost. result data blocks will be lost at a near future time t. The calculation of Er is thus recursive. In practice, a recursion depth limit can be applied. 11
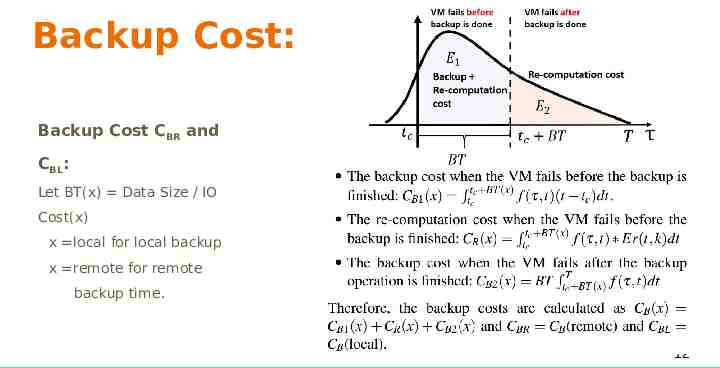
Backup Cost: Backup Cost CBR and CBL: Let BT(x) Data Size / IO Cost(x) x local for local backup x remote for remote backup time. 12
Implementation Safety Belt Guarantee the total job running time to be less than twice the cost of always checkpointing. Degrade to always checkpointing is necessary. Increasing resource utilization Data block which is assigned to be backed up locally or remotely should be checkpointed immediately in order to avoid data loss caused by resource instability During the backup execution, schedule the next task to maximize the concurrency of checkpointing and task execution, if there is a free CPU resource Dynamic task splitting & duplication 13
Evaluation “TR-Spark performs nearly as well as Spark running on stable resources” Evaluated on a home-built simulator and Microsoft Azure with different parameters and environment settings: Spark without checkpointing Spark with Always Checkpointing TR-Spark(deterministic,local) - only local backup is available TR-Spark(deterministic,remote) - remote backup is available 14
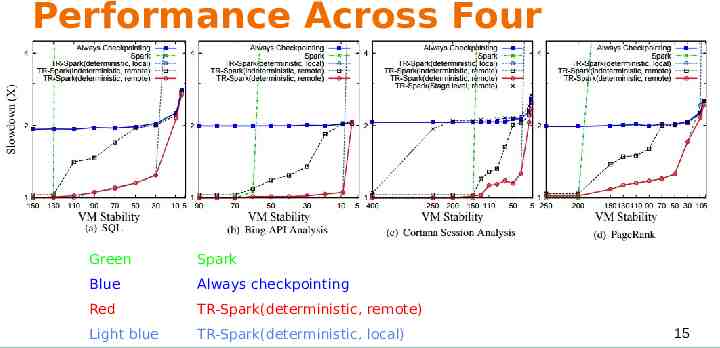
Performance Across Four Different Workloads Green Spark Blue Always checkpointing Red TR-Spark(deterministic, remote) Light blue TR-Spark(deterministic, local) 15
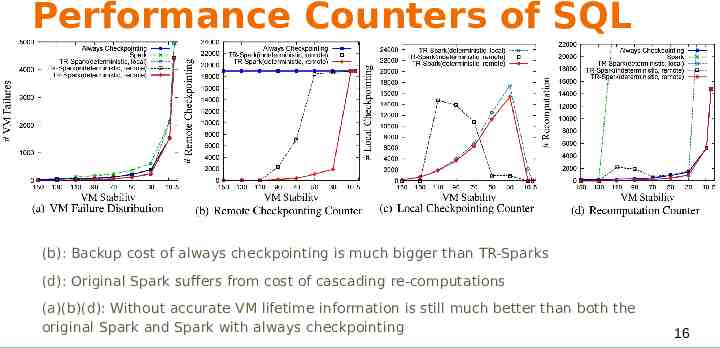
Performance Counters of SQL Workload (b): Backup cost of always checkpointing is much bigger than TR-Sparks (d): Original Spark suffers from cost of cascading re-computations (a)(b)(d): Without accurate VM lifetime information is still much better than both the original Spark and Spark with always checkpointing 16
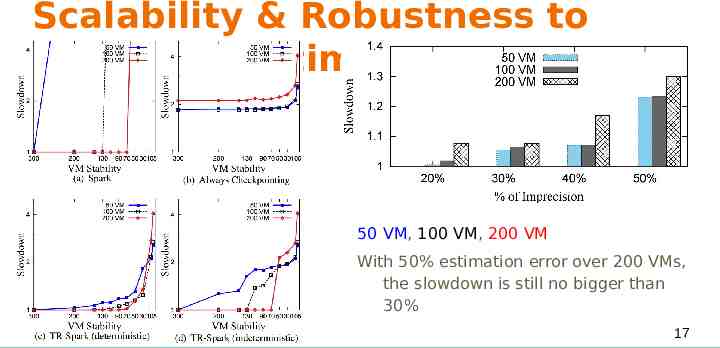
Scalability & Robustness to Imprecise Estimation 50 VM, 100 VM, 200 VM With 50% estimation error over 200 VMs, the slowdown is still no bigger than 30% 17
Take Away Statistical estimation as a tool in system design Usage of transient resources is crucial to capacity utilization Checkpointing is crucial for fault-recovery of Spark Benchmarks are not always trustworthy 18
SystemML: Declarative Machine Learning on Spark 19
SystemML: Motivation Rising of machine learning Growth of data size Easier use for data scientists Various of scenarios. E.x. single node & large-scale distributed 20
SystemML: Introduction (§1) Overview Separating algorithm semantics from underlying data representations and runtime Cost-based compiler automatically generates hybrid runtime execution plans Declarative language fits any algorithms can be expressed using vectorized operations On Spark Advantages to improve the efficiency Importantly, Spark suits repeated, read-only data access in iterative ML algorithms Integration with data collection process 21
SystemML: Architecture (§2) Language: Declarative ML. (with either R- or Python-like syntax) Supports user-defined functions, “parfor”, etc. Performs syntactic & live variable analysis, and semantic validation Retrieve data characteristic Optimizer: Algebraically, operator reordering, etc. Memory requirement estimation 22
SystemML: Optimizer Integration Core idea: Less re-partitioning Less repeated read/write to disk Satisfying other constraints and parallel(distribute) when possible Spark-Specific Rewrites (for automatically data handling) (§3.1) Caching/Checkpoint Injection After every persistent read or reblock Before loops for read-only variables in loop body (except parfor) 23
SystemML: Optimizer Integration Memory Budgets and Constraints (§3.2) Memory Budgets User-defined basic memory budgets and derivations from that Memory Estimates Worst-case. Inputs, intermediates and outputs For operator selection Operator Selection (§3.3) Schedule to Spark if M(op) M {cp} 24
SystemML: Optimizer Integration Operator Selection (§3.3) . Avoid shuffle; exploit sparsity; reduce the number of intermediate results; reduce buffer pool evictions Example: sum(W (U V X) 2 ). W,X sparse 25
SystemML: Optimizer Integration Extended ParFor Optimizer (§3.4) 3 operators: local, remote, remote dp partitions a given input matrix into disjoint slices and executes the per slice. Deferred Checkpoint/Repartition Injection Eager Checkpointing/Repartitioning Fair Scheduling for Concurrent Jobs increase temporal locality, allows for implicit scan sharing Degree of Parallelism 26
SystemML: Runtime Integration Distributed Matrix Representation (§4.1) MatrixIndexes, MatrixBlock , MatrixIndexes are (long,long)-pairs Usually square, size 1K, or 8MB single-node computation: Sparse matrix: MCSR, CSR entire matrix as a single matrix block enable reuse and consistency Custom block serialization Prevent re-shuffling Default hash partitioner 27
SystemML: Runtime Integration Buffer Pool Integration (§4.2) Basic abstraction: Matrix objects are meta-data handles to in-memory or distributed matrices and internally interact with the buffer pool. Every Spark instruction that creates an output RDD maintains the lineage to input RDDs and broadcasts. For out-of-memory situation, use guarded collect and guarded parallelize where the data transfer is redirected over HDFS if necessary. Two-level broadcast partitioning Dynamic Recompilation (§4.3) 28
SystemML: Runtime Integration Partitioning-Preserving Operations (§4.4) Restrictive APIs, Fallback to full partition computation, declared as partitioning preserving Refrain from changing the number of partitions, create new operator Specific Runtime Optimizations (§4.5) Lazy Spark-Context Creation In case we are only run single-noded Short-Circuit Read bypasses the checkpoint based on lineage information 29
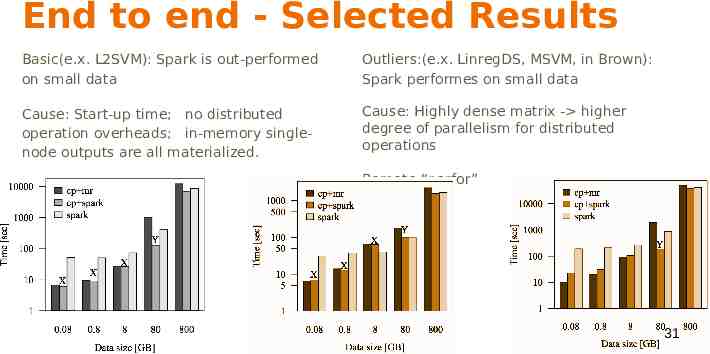
Experiment & Analysis - end to end Different data size: 80MB(XS), 800MB(S), 8GB(M), 80GB(L), and 800GB(XL) XS, S, and M into the driver. L fits into the distributed cache XL is an out-of-core scenario. Different execution modes cp mr, cp spark, and spark To understand the characteristics of SystemML on Spark 30
End to end - Selected Results Basic(e.x. L2SVM): Spark is out-performed on small data Outliers:(e.x. LinregDS, MSVM, in Brown): Spark performes on small data Cause: Start-up time; no distributed operation overheads; in-memory singlenode outputs are all materialized. Cause: Highly dense matrix - higher degree of parallelism for distributed operations Remote “parfor” 31
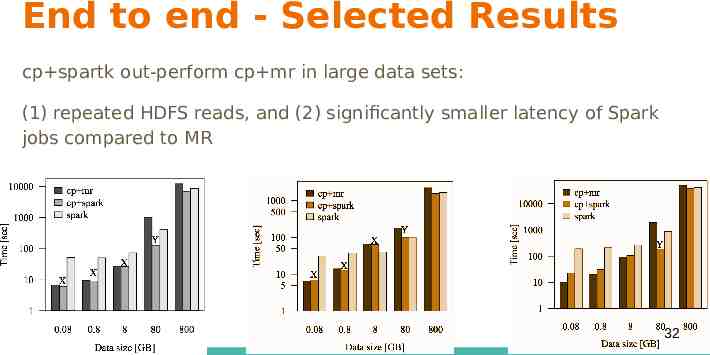
End to end - Selected Results cp spartk out-perform cp mr in large data sets: (1) repeated HDFS reads, and (2) significantly smaller latency of Spark jobs compared to MR 32
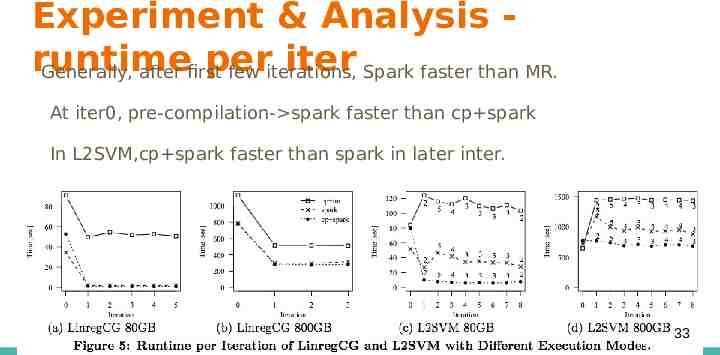
Experiment & Analysis runtime per iter Spark faster than MR. Generally, after first few iterations, At iter0, pre-compilation- spark faster than cp spark In L2SVM,cp spark faster than spark in later inter. In XL, hybrid still important 33
Experiment & Analysis optimizers ParFor-Specific Optimizations Memory-Efficient Sparse Matrices Best when all optimizations on Reduce the chance of data repartition CSR MCSR(serial) MCSR More memory efficient, the better Avoid unnecessary spilling or deserialization overhead 34
Experiment & Analysis - ALS end Different to driver end memory for the experiment setup For S, cp mr and cp spark are all single-noded MR does not finish in L due to large dataset could not fit into memory of MR tasks- repeated spilling 35
Take Away Data partition and re-shuffling is important in optimizing operations on Spark Matrix representation can be addressed in various of ways The author seems build more optimizations on top of Spark Maybe more changes on Spark? CPU/Mem usage Also, GPU? Fully automated runtime. Maybe some room for manually tuning? 36
Questions and Thoughts on TRSpark 1.Use job types on a VM as a factor to estimate VM lifetime distribution 2.No measurement on throughputs 3.Introduces large overhead after downgrade to always checkpointing 4.What's a suitable use case for TR-Spark? 5.Why performance difference between in simulator and real cloud environment is really big? 6.Strong reliance on accurate statistics may be inefficient in other clusters 7.The scalability is not as good as traditional Spark? 37 8.How fast does TR-Spark calculate metrics for making decisions?
Questions and Thoughts on SystemML SystemML - Tensorflow? From paper: These systems, however, only provide limited automatic optimization of runtime plans and/or data independence. SystemML - MlLib? From paper: different abstraction levels of algorithm specification, and (2) different algorithm choices and parameters. Optimizations apply on other systems? Migration to other platform? Matrices: partitioning, reduced spill, less load overhead Other than matrices: two-level broadcasting, optimized collect 38





