Sequential data access with Oracle and Hadoop:

















30 Slides1.89 MB
Sequential data access with Oracle and Hadoop: a performance comparison Zbigniew Baranowski Luca Canali Eric Grancher CERN IT Department CH-1211 Geneva 23 Switzerland 20th International Conference on Computing in High Energy and Nuclear Physics
Outline Motivation Test setup Results Summary 2
Outline Motivation Test setup Results Summary 3
Motivation for testing Relational model sometimes is not optimial for – data analytics – very big data volumes Why? – transaction-support features of relational database engines are not used for these workloads – table joins don’t scale well for large tables – indexes can waste a lot of storage and be less efficient than full scans – e. g. ATLAS Events Metadata catalogue Full data scans (brute force) work best! 4
Full Scan Scan What do we want to test? ? 5
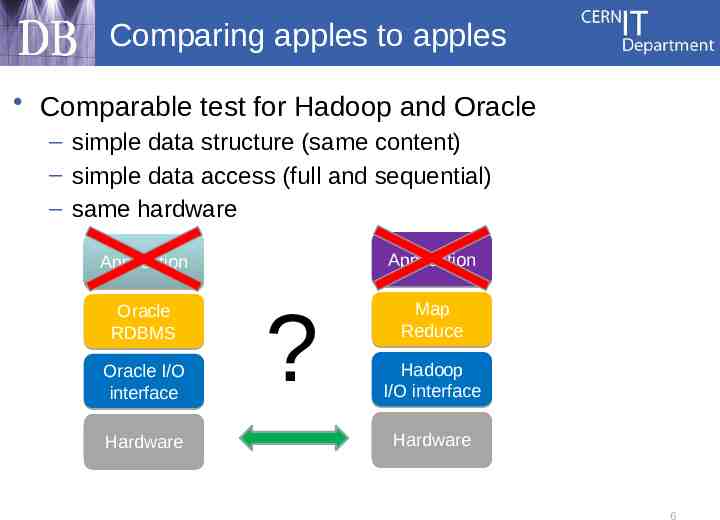
Comparing apples to apples Comparable test for Hadoop and Oracle – simple data structure (same content) – simple data access (full and sequential) – same hardware Application Application Oracle RDBMS Oracle I/O interface Hardware ? Map Reduce Hadoop I/O interface Hardware 6
Why Hadoop? Emerging technology – Yahoo, Google (BigTable/GFS) that people are interested in – ATLAS poster P4.29 Strong for data analytics and data warehousing – On this field Oracle can be hard to optimize and/or can be very expensive (Exadata) 7
Why Oracle? 30 years at CERN – a lot of data already in Oracle Full ACID transactional system Optimized for various data access methods 8
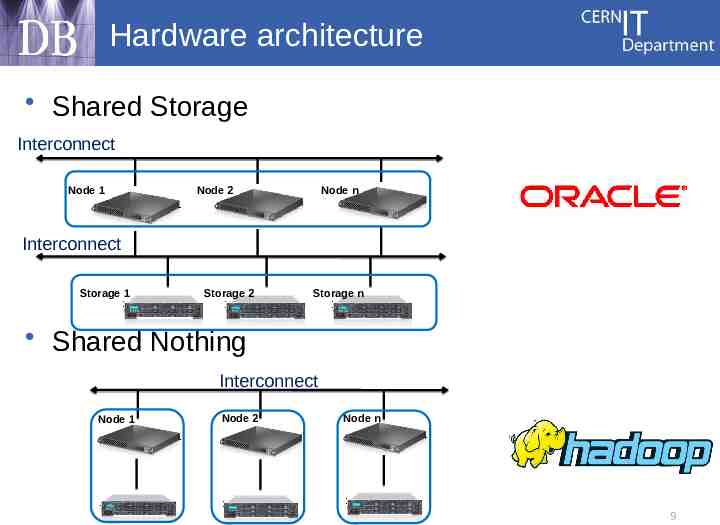
Hardware architecture Shared Storage Interconnect Node 1 Node 2 Node n Interconnect Storage 1 Storage 2 Storage n Shared Nothing Interconnect Node 1 Node 2 Node n 9
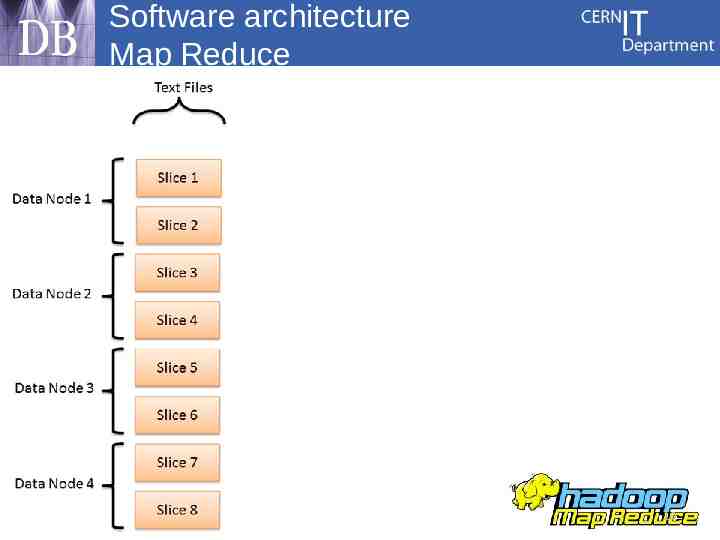
Software architecture Map Reduce 10
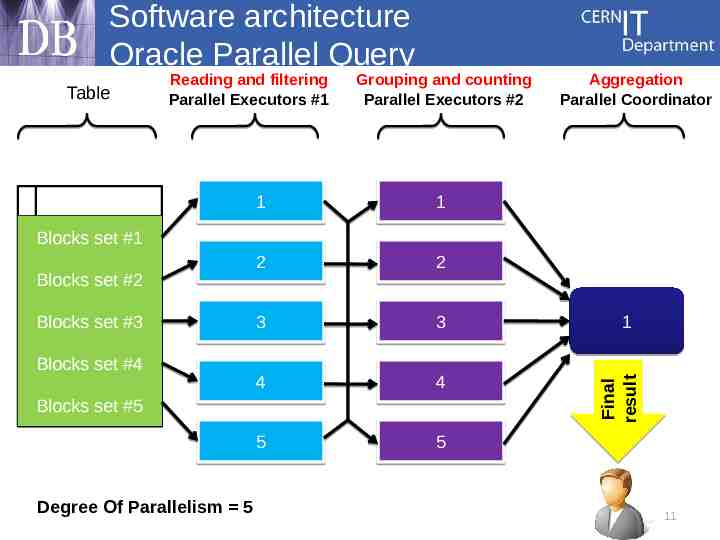
Software architecture Oracle Parallel Query Table Reading and filtering Parallel Executors #1 Grouping and counting Parallel Executors #2 1 1 2 2 3 3 4 4 5 5 Aggregation Parallel Coordinator Blocks set #1 Blocks set #3 Blocks set #4 Blocks set #5 Degree Of Parallelism 5 1 Final Final result result Blocks set #2 11
Outline Motivation Test setup Results Summary 12
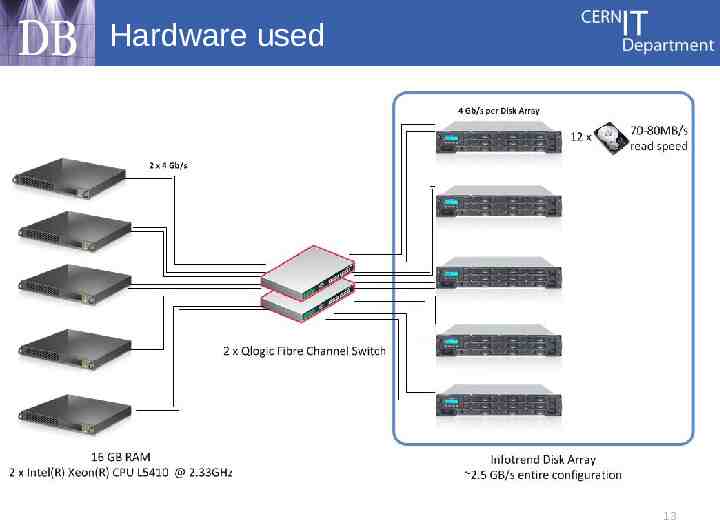
Hardware used 13
Hardware config for Hadoop Shared nothing implementation 14
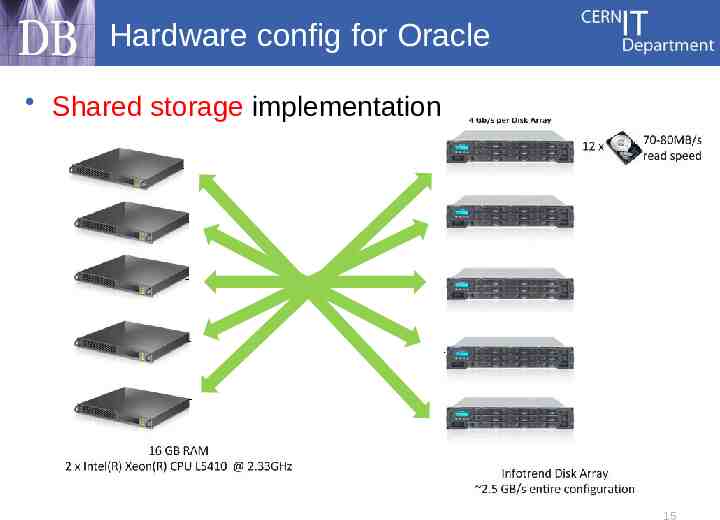
Hardware config for Oracle Shared storage implementation 15
Data set used Could be generic, but How do we know if we are getting the same results? 1TB CSV file with physics data – Numeric values (integers, floats) – 244 columns/attributes per record/line – 532M lines/records 16
Test case Counting „exotic” muons in the collection – Oracle version select /* parallel(x) */ count(*) from iotest.muon1tb where col93 100000 and col20 1; – MapReduce //MAP body //REDUCER body LongWritable long sum 0; one new LongWritable(1); NullWritable nw NullWritable.get(); while (values.hasNext()) { String[] records line.split(','); sum values.next().get(); } tight Integer.parseInt(records[19]); pt Float.parseFloat(records[92]); output.collect(NullWritable.get(), new LongWritable(sum)); if (tight 1 && pt 100000) { collector.collect(nw,one); } 17
Software configuration Hadoop – v1.0.3 – Cluster file system: HDFS on top of ext3 – More specific configuration/optimization Delayed Fair Scheduler JVM reuse File block size 1GB Oracle database – 12c RAC – Cluster file system: Oracle’s ASM – Configuration recommended by Oracle 18
Outline Motivation Test setup Results Summary 19
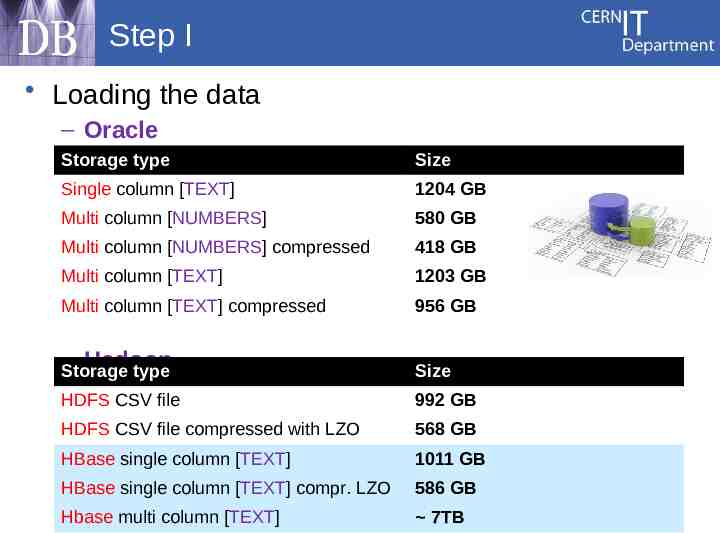
Step I Loading the data – Oracle Storage type Size Single column [TEXT] 1204 GB Multi column [NUMBERS] 580 GB Multi column [NUMBERS] compressed 418 GB Multi column [TEXT] 1203 GB Multi column [TEXT] compressed 956 GB – Hadoop Storage type Size HDFS CSV file 992 GB HDFS CSV file compressed with LZO 568 GB HBase single column [TEXT] 1011 GB HBase single column [TEXT] compr. LZO 586 GB Hbase multi column [TEXT] 7TB 20
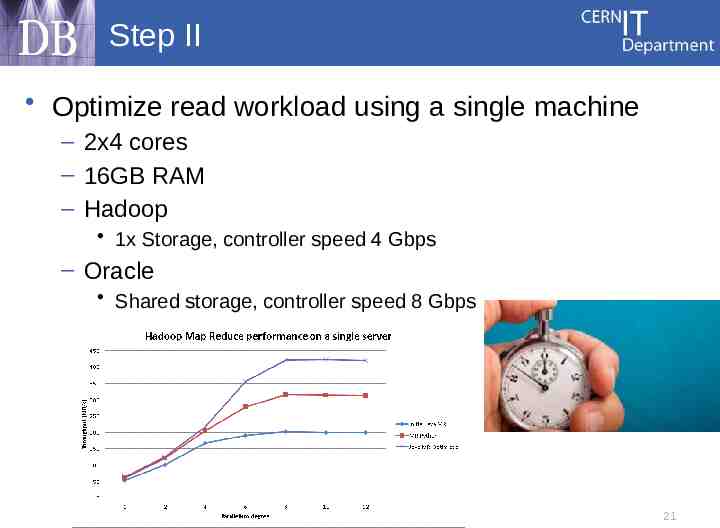
Step II Optimize read workload using a single machine – 2x4 cores – 16GB RAM – Hadoop 1x Storage, controller speed 4 Gbps – Oracle Shared storage, controller speed 8 Gbps 21
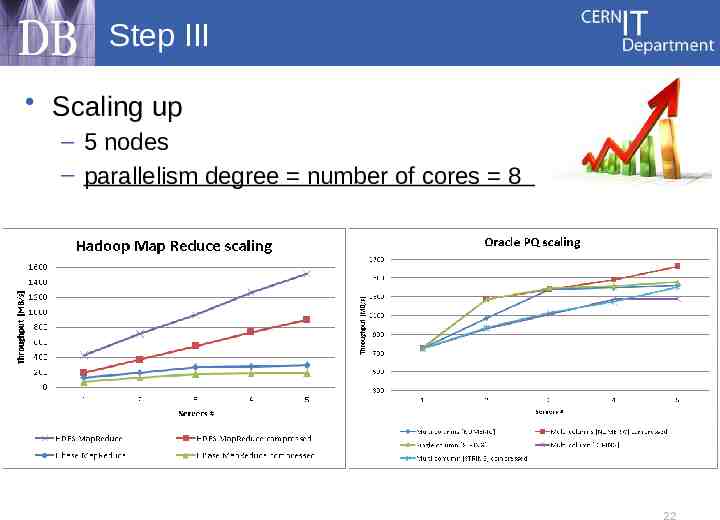
Step III Scaling up – 5 nodes – parallelism degree number of cores 8 22
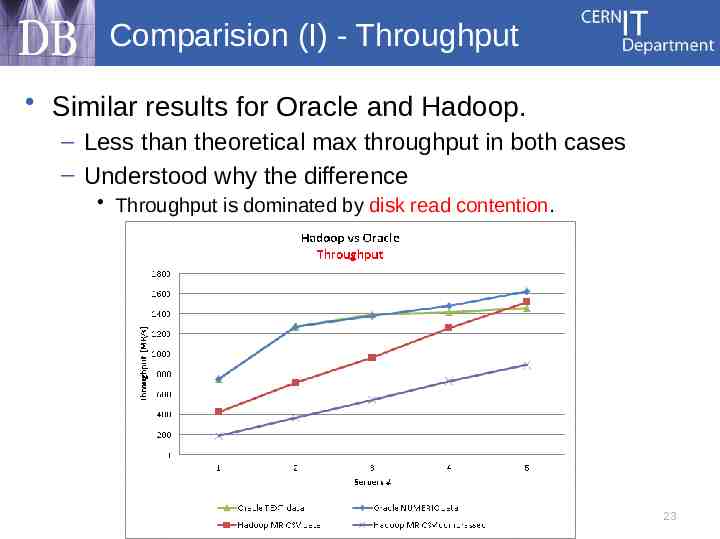
Comparision (I) - Throughput Similar results for Oracle and Hadoop. – Less than theoretical max throughput in both cases – Understood why the difference Throughput is dominated by disk read contention. 23
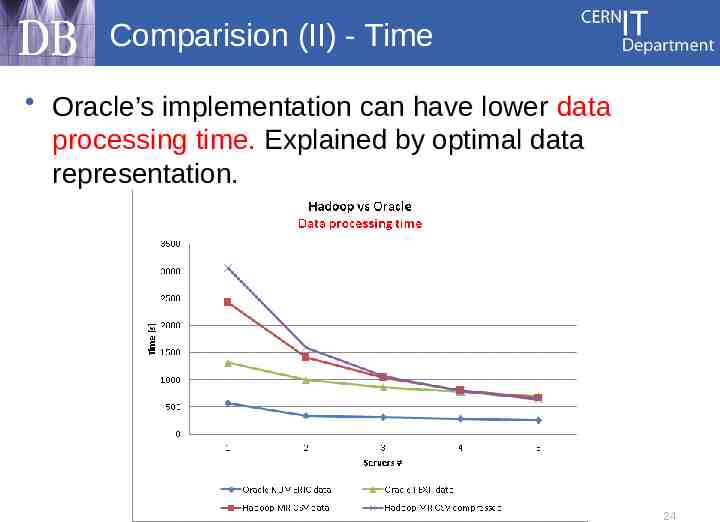
Comparision (II) - Time Oracle’s implementation can have lower data processing time. Explained by optimal data representation. 24
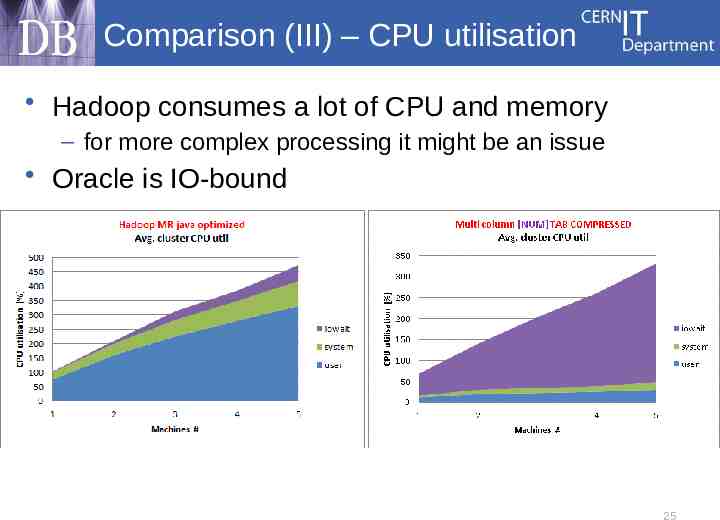
Comparison (III) – CPU utilisation Hadoop consumes a lot of CPU and memory – for more complex processing it might be an issue Oracle is IO-bound 25
Outline Motivation Test setup Results Summary 26
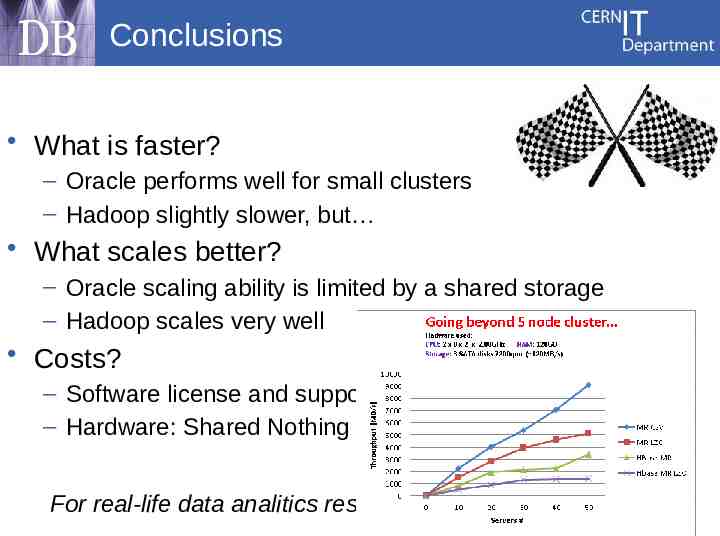
Conclusions What is faster? – Oracle performs well for small clusters – Hadoop slightly slower, but What scales better? – Oracle scaling ability is limited by a shared storage – Hadoop scales very well Costs? – Software license and support – Hardware: Shared Nothing costs less than Shared Storage For real-life data analitics results see poster P2.29 27
Comments Sequential data access on HBase does not give good results – it was design to perform with random reads! Writing efficient Map Reduce code is not trivial – optimized implementation can significantly improve the performance – aviod using String.split() or Tokenizer! Hadoop is in very active development – new releases can address observed issues A lot of data at CERN is already in Oracle – Effort and time of exporting it to other system is not negligible Oracle and Hadoop can compete in the database space for 28 analytics, but not for transactional workloads!
Many Thanks! Tony Cass (CERN IT-DB/CS) Andrei Dumitru (CERN IT-DB) Maaike Limper (CERN IT-DB Stefano Russo (CERN IT-DB) Giacomo Tenaglia (CERN IT-DB) 29
Q&A 30






