Relational Database Concepts






























33 Slides129.50 KB
Relational Database Concepts
Let’s start with a simple example of a database application Assume that you want to keep track of your clients’ names, addresses, and phone numbers.
Client information to store and retrieve Name Address Phone Number
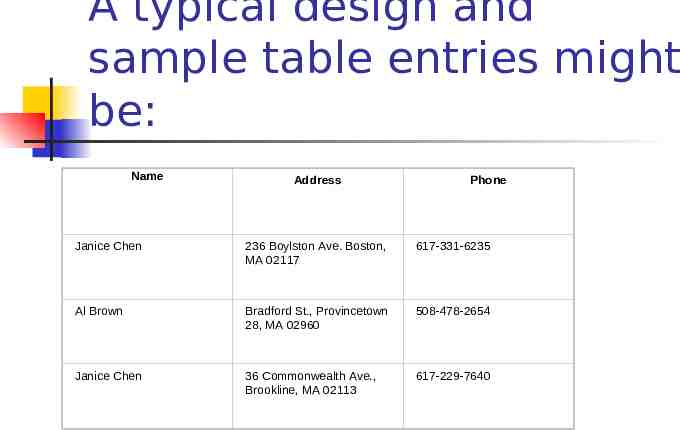
A typical design and sample table entries might be: Name Address Phone Janice Chen 236 Boylston Ave. Boston, MA 02117 617-331-6235 Al Brown Bradford St., Provincetown 28, MA 02960 508-478-2654 Janice Chen 36 Commonwealth Ave., Brookline, MA 02113 617-229-7640
But if we wanted to sort the records in alphabetical order by name in the usual way, there would be a problem because the last name is buried in the Name field. Solution: Split the Name field into 2 atomic fields, Last Name and First Name.
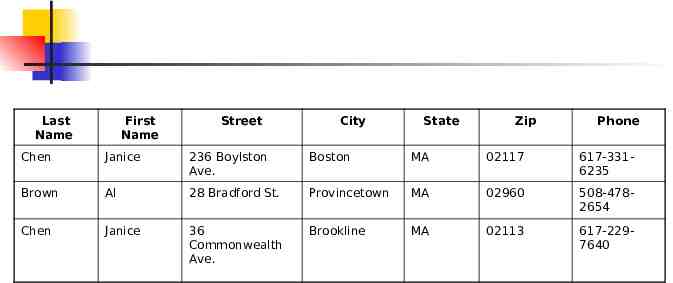
Similarly, we may want to query the database for all clients from MA, or all clients from Brookline, or group clients by ZIP code for mass mailings. To do this, we need to break the address into several smaller atomic fields as well. Our table then looks as follows:
Last Name First Name Street City State Zip Phone Chen Janice 236 Boylston Ave. Boston MA 02117 617-3316235 Brown Al 28 Bradford St. Provincetown MA 02960 508-4782654 Chen Janice 36 Commonwealth Ave. Brookline MA 02113 617-2297640
Primary key How can we identify a record in this table uniquely? Notice that the last name is not sufficient; nor is the combination of last name and first name. Perhaps the combination of all the name and address fields is sufficient.
A primary key in a table is a field or combination of fields that uniquely distinguishes any record from all other records. Every table in a relational database must have a primary key.
So in this example, perhaps we could specify the combination of all the name and address fields as the primary key (or perhaps the combination of the 2 name fields along with the phone number).
A single field is generally preferable as a primary key, so one choice we have available for our database is to add an additional field – Social Security Number. These are guaranteed to identify individuals uniquely. An alternative is to generate our own numbering system for clients, say C001, C002, etc.
Now let’s consider a slightly more involved example Assume that you have a small company selling books and you want to keep track of your customers’ orders. To keep things simple, let’s assume that among the data we intend to keep track of for each order is the following:
Data to store and retrieve about customer orders Customer Name Customer Address Book Title Quantity Ordered Date Shipped Purchase Price etc.
As before, we’ll probably want to break the name and address fields down further, but here we’ll take those details for granted and emphasize some additional considerations.
First, let’s imagine placing all the data in a single table. Since a customer can order books at different times (or even multiple books in a single order), we can end up with multiple records containing the identical name and address information for a customer.
This one table will thus contain redundant information, which can lead to more date entry errors or updating errors if some of the customer data changes. And of course it wastes space.
The solution is to have multiple tables. In particular, we should have a separate Customers table that holds only things like the name and address of customers. We’ll also have an Orders table.
Foreign keys One of the fields in the Orders table will identify which customer the order is for. Instead of using the entire name and address of the customer in the Orders table, we’ll use a simple customer id number to identify the customer.
This customer id number will be used as a primary key in the Customers table, and it will also be used as a foreign key in the Orders table, to identify which customer placed the order. A foreign key is just a kind of pointer to information in a related table.
Many-to-one relationships Since each order is placed by exactly one customer, but each customer may place many orders, there is a many-to-one relationship between orders and customers. Many-to-one relationships always require the use of a foreign key in the “many” table (Orders in this case).
We can expand on this example by considering how we might keep track of our book inventory. In particular, let’s also have a Books table that stores all the information about the books we sell, including title, author, publisher, etc.
Many-to-many relationships One order can be for more than one book, and any book can appear in multiple orders. Thus there is a many-to-many relationship between books and orders.
The way to handle the many-tomany relationship between books and orders is to have an additional table besides the Books and Orders tables. We’ll call this table Order Details.
The Order Details table may contain multiple entries for any particular order and multiple entries for any particular book. It contains foreign keys pointing to the Orders table and to the Books table.
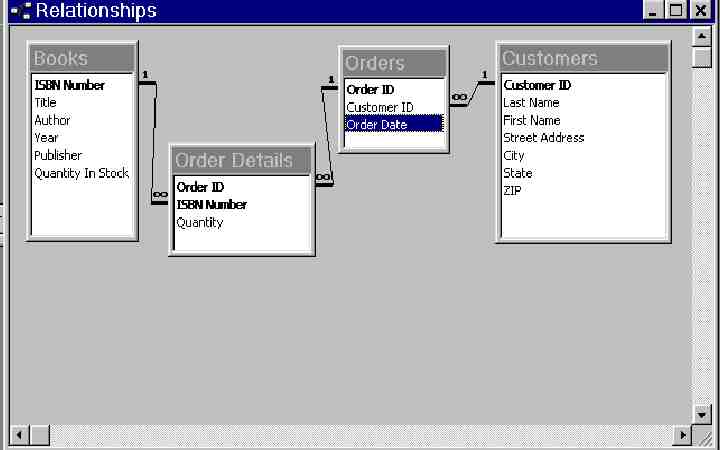
Here is how the Relationships Window in Access displays this information, by listing the names of all the fields in all 4 tables and showing which fields (foreign keys) correspond to which other fields(primary keys) in other tables. Primary keys are indicated in bold. (ISBN number is a standard unique identifier for books.)
Referential Integrity The point of this example has been to show how a useful database may contain multiple tables. But when there are related tables, care must be taken to insure that the relationships between the tables are respected.
Consider what might happen if a customer is deleted from the Customers table. If there is an entry in the Orders table for this customer, it would now contain a meaningless customer id.
There are 2 possible solutions to this problem: Do not allow a customer to be deleted from the Customers table if there are corresponding orders in the Orders table When deleting an entry from the Customers table, delete all corresponding orders for that customer (called cascaded deletion).
Queries and Joins Retrieving information from the database is done using queries. Consider a query of the form: Find the names and addresses of all customers who have ordered books by a particular author.
This involves: looking in the Books table to find all books by that author, then looking in the Order Details table to see which orders were for those books, then looking in the Orders table to see which customers placed those orders, and finally, looking in the Customers table to get the names and addresses of these customers.
On the other hand, if we had kept all the information in just 1 big table, we could have just pulled the information out of that table. The join of 2 or more related tables is conceptually just the same as one large table combining the information from the smaller tables.
A query involving multiple tables is sometimes said to be a query on the join of those tables. The actual join itself need not be determined; it is just a conceptual entity. Just think of the process in the way we described it earlier: looking up information in one table, then in another table, etc.





