Reference Book Principles of Distributed Database System Chapters

















19 Slides132.50 KB
Reference Book Principles of Distributed Database System Chapters 4. Distributed DBMS Architecture 5. Distributed Database Design 7.5 Layers of Query Processing Preethi Vishwanath Week 2 : 5th September 2006 – 12th September 2006
ANSI/SPARC Architecture – External View, which is that of the user, who might be a programmer basically concerned with how users view the data. – Conceptual view, that of the enterprise – Internal View, that of a system or a machine, deals with the physical definition and organization of data. Users External View Conceptual View Internal View
Possible ways to put together multiple databases Autonomy of Local Systems – Refers to distribution of control – Indicates degree of independence of individual databases Alternatives to autonomy – Tight Integration Single image of entire db Is available for any user who wants to share the info, which may reside in multiple db . – Semiautonomous systems Consists of DBMSs that can operate independently, but have decided to participate in a federation. – Total Isolation Stand Alone DBMs
Distribution – Deals with Physical distribution of data over multiple sites – Three alternative architectures available Client-Server, communication duties are shared between the client machines and servers. Peer-to-peer systems, no distinction of client machines versus servers. Non-distributed systems
Heterogeneity – Occurs in Various forms – Data models: Representing data with different modeling tools – Query Languages: Not only involves the use of completely different data access paradigms in different data models, but also covers difference in languages, even when the individual systems use the same data model.
Client-Server architecture Multiple Client – Multiple Server Distinguish the functionality and divide these functions into two classes, server functions and client functions. Server does most of the data management work – – – – – – 1. query processing data management Optimization Transaction management etc – – – Application User interface DBMS Client model Multiple Client - Single Server – Single Server accessed by multiple clients Heavy client Systems – – – Client performs 2. Multiple Servers accessed by multiple clients 2 alternate management strategies Each client manages its own connection to the appropriate server. Simplifies server code Loads client machines with additional responsibilities Light Client Systems – – Each client knows of only its “home server” which then communicates with other servers as required. Concentrates on data management functionality at the servers.
Peer-to-Peer Distributed Systems Schemas Present – Individual internal schema definition at each site, local internal schema – Enterprise view of data is described the global conceptual schema. – Local organization of data at each site is describe in the local conceptual schema. – User applications and user access to the database is supported by external schemas. Local conceptual schemas are mappings of the global schema onto each site. Databases are typically designed in a top-down fashion, and, therefore all external view definitions are made globally. Major Components of a Peerto-Peer System – User Processor – Data processor
Peer-to-Peer Distributed Systems User Processor User-interface handler responsible for interpreting user commands, and formatting the result data Semantic data controller checks if the user query can be processed. Global Query optimizer and decomposer determines an execution strategy Translates global queries into local one. Distributed execution Coordinates the distributed execution of the user request Data processor Local query optimizer Acts as the access path selector Responsible for choosing the best access path Local Recovery Manager Makes sure local database remains consistent Run-time support processor Is the interface to the operating system and contains the database buffer Responsible for maintaining the main memory buffers and managing the data access.
MDBS Architecture Models Using a Global Conceptual Schema GCS is defined by integrating either the external schemas of local autonomous databases or parts of their local conceptual schema Users of a local DBMS define their own views on the local database. If heterogeneity exists in the system, then two implementation alternatives exist: unilingual and multilingual Unilingual requires the users to utilize possibly different data models and languages Basic philosophy of multilingual architecture, is to permit each user to access the global database. GCS in multi-DBMS – Mapping is from local conceptual schema to a global schema – Bottom-up design Models without a global conceptual schema Consists of two layers, local system layer and multi database layer. Local system layer , present to the multi-database layer the part of their local database they are willing share with users of other database. System views are constructed above this layer Responsibility of providing access to multiple database is delegated to the mapping between the external schemas and the local conceptual schemas. Full-fledged DBMs, exists each of which manages a different database. GCS in Logically integrated distributed DBMS – Mapping is from global schema to local conceptual schema – Top-down procedure
Global Directory Issues Global Directory is an extension of the normal directory, including information about the location of the fragments as well as the makeup of the fragments, for cases of distributed DBMS or a multiDBMS, that uses a global conceptual schema, Global Directory Issues – Relevant for distributed DBMS or a multi-DBMS that uses a global conceptual schema – Includes information about the location of the fragments as well as the makeup of fragments. – Directory is itself a database that contains meta-data about the actual data stored in database. – Three issues A directory may either be global to the entire database or local to each site. Directory may be maintained centrally at one site, or in a distributed fashion by distributing it over a number of sites. – If system is distributed, directory is always distributed Replication, may be single copy or multiple copies. – Multiple copies would provide more reliability
Organization of Distributed systems Three orthogonal dimensions – Level of sharing No sharing, each application and data execute at one site Data sharing, all the programs are replicated at other sites but not the data. Data-plus-program sharing, both data and program can be shared – Behavior of access patterns Static – Does not change over time – Very easy to manage Dynamic – Most of the real life applications are dynamic – Level of knowledge on access pattern behavior. No information Complete information – Access patterns can be reasonably predicted – No deviations from predictions Partial information – Deviations from predictions
Top Down Design – Suitable for applications where database needs to be build from scratch – Activity begins with requirement analysis – Requirement document is input to two parallel activities: view design activity, deals with defining the interfaces for end users conceptual design, process by which enterprise is examined – Can be further divided into 2 related activity groups Entity analyses, concerned with determining the entities, attributes and the relationship between them Functional analyses, concerned with determining the fun Distributed design activity consists of two steps – Fragmentation – Allocation Bottom-Up Approach – – – Suitable for applications where database already exists Starting point is individual conceptual schemas Exists primarily in the context of heterogeneous database.
Fragmentation Advantages 1. Permits a number of transactions to executed concurrently 2. Results in parallel execution of a single query 3. Increases level of concurrency, also referred to as, intra query concurrency 4. Increased System throughput Disadvantages 1. Applications whose views are defined on more than one fragment may suffer performance degradation, if applications have conflicting requirements. 2. Simple asks like checking for dependencies, would result in chasing after data in a number of sites
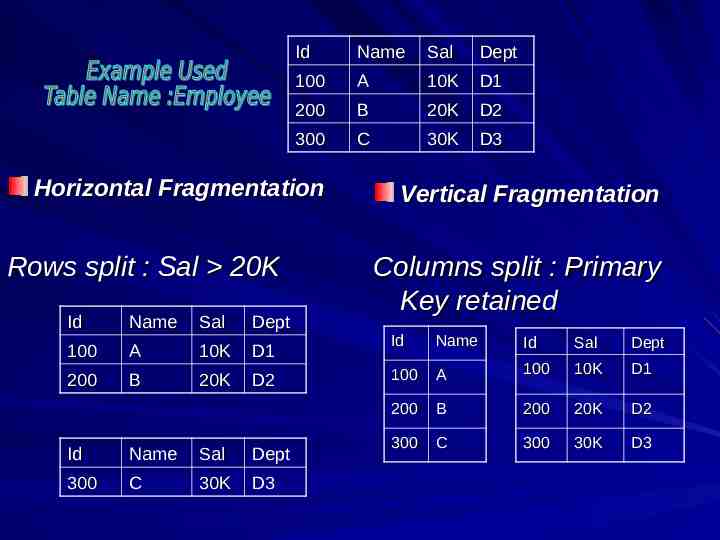
Id Name Sal Dept 100 A 10K D1 200 B 20K D2 300 C 30K D3 Horizontal Fragmentation Rows split : Sal 20K Id Name Sal Dept 100 A 10K D1 200 B 20K D2 Id Name Sal Dept 300 C 30K D3 Vertical Fragmentation Columns split : Primary Key retained Id Name Id Sal Dept 100 A 100 10K D1 200 B 200 20K D2 300 C 300 30K D3
Correctness rules of fragmentation Completeness If a relation instance R is decomposed into fragments R1,R2 . Rn, each data item that can be found in R can also be found in one or more of Ri’s. Reconstruction If a relation R is decomposed into fragments R1,R2 . Rn, it should be possible to define a relational operator such that R Ri, Ri ε FR , Please note the operator would be different for the different forms of fragmentation Disjointness If a relation R is horizontally decomposed into fragments R1,R2 . Rn, and data item di is in Rj, it is not in any other fragment Rk (k ! j).
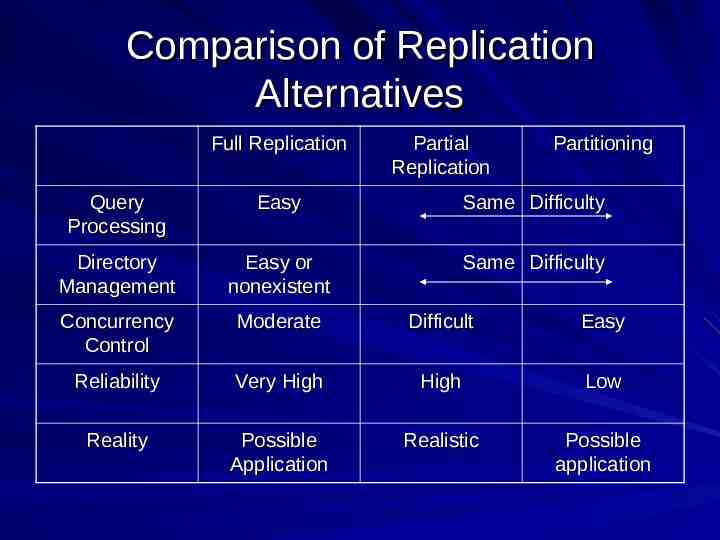
Comparison of Replication Alternatives Full Replication Partial Replication Partitioning Query Processing Easy Same Difficulty Directory Management Easy or nonexistent Same Difficulty Concurrency Control Moderate Difficult Easy Reliability Very High High Low Reality Possible Application Realistic Possible application
Derived Horizontal Fragmentation Defined on a member relation of a link according to a selection operation specified on its owner. Link between the owner and the member relations is defined as equi-join An equi-join can be implemented by means of semijoins. Given a link L where owner (L) S and member (L) R, the derived horizontal fragments of R are defined as Example Consider two tables Emp Id PAY Name Si σ Fi (S) w is the max number of fragments that will be defined on Fi is the formula using which the primary horizontal fragment Si is defined Dept Sal 100 A D1 D1 10K 200 B D2 D2 20K 300 C D3 D3 30K PAY1 EMP1 α PAY PAY2 EMP2 α PAY Emp1 σSal 20K (Emp) Emp2 σSal 20K (Emp) Ri R α Si, 1 I w Where, Dept IdPAY1 Name Dept 100 A D1 200 B D2 Id Name PAY2Dept 300 C D3
Primary Horizontal Fragmentation Primary horizontal fragmentation is defined by a selection operation on the owner relation of a database schema. Given relation Ri, its horizontal fragments are given by Ri σFi(R), 1 i w Fi selection formula used to obtain fragment Ri The example mentioned in slide 20, can be represented by using the above formula as Emp1 σSal 20K (Emp) Emp2 σSal 20K (Emp) Vertical Fragmentation Grouping Starts by assigning each attribute to one fragment At each step, joins some of the fragments until some criteria is satisfied. Results in overlapping fragments Splitting Starts with a relation and decides on beneficial partitioning based on the access behavior of applications to the attributes Fits more naturally within the top-down design Generates non-overlapping fragments.
Hybrid Fragmentation Horizontal or vertical fragmentation of a database schema will not be sufficient to satisfy the requirements of user applications. In certain cases, a vertical fragmentation may be followed by a horizontal one, or vice versa. Since two types of partitioning strategies are applied one after the other, this alternative is called hybrid fragmentation. In case of horizontal fragmentation, one has to stop when each fragment consists of only one tuple, whereas the termination point for vertical fragmentation is one attribute per fragment. Example discussed in slides 20 and 26 can be converted into hybrid fragmentation U R R1 R11 R23 α R2 R12 R21 R22 R11 R12 α R21 R22 R23






