QSX: Querying Social Graphs Graph Queries and Algorithms Graph






























50 Slides1.26 MB
QSX: Querying Social Graphs Graph Queries and Algorithms Graph search (traversal) PageRank Nearest neighbors Keyword search Graph pattern matching 1
Basic graph queries and algorithms Graph search (traversal) PageRank Nearest neighbors Keyword search Graph pattern matching (a full treatment of itself) Algorithms in MapReduce (lecture 4) and other parallel models (lecture 5) Widely used in graph algorithms 2
Graph representation 3
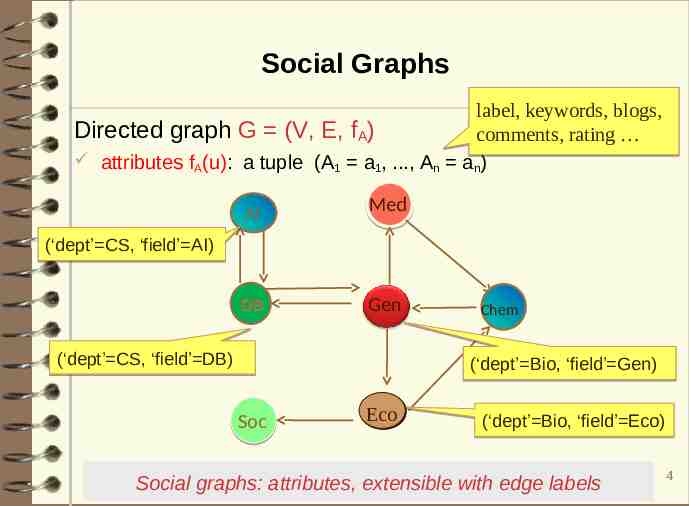
Social Graphs label, keywords, blogs, Directed graph G (V, E, fA) comments, rating attributes fA(u): a tuple (A1 a1, ., An an) AI Med DB Gen (‘dept’ CS, ‘field’ AI) (‘dept’ CS, ‘field’ DB) Chem (‘dept’ Bio, ‘field’ Gen) Soc Eco Eco (‘dept’ Bio, ‘field’ Eco) Social graphs: attributes, extensible with edge labels 4
Relational representation Node relation: node( nodeId, label, attributes) e.g., node(02, book, “Graphs”), node(03, author, “John Doe”) Edge relation: edge( sid, did, label) sid, did: source and destination nodes; e.g., edge(03, 02, write) Possibly with an attribute relation Pros and cons Lossless: the original graph can be reconstructed Ignore topological structure Querying efficiency: Requires multi-table joins or self joins for simple queries, e.g., book[author “Bush”]/chapter/title requires 3 joins of the edge relation! Nontrivial to leverage existing relational techniques 5
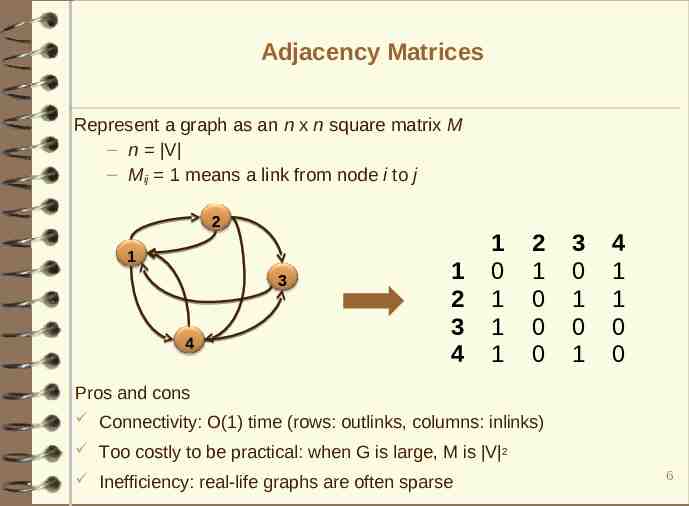
Adjacency Matrices Represent a graph as an n x n square matrix M – n V – Mij 1 means a link from node i to j 2 1 3 4 1 2 3 4 1 0 1 1 1 2 1 0 0 0 3 0 1 0 1 4 1 1 0 0 Pros and cons Connectivity: O(1) time (rows: outlinks, columns: inlinks) Too costly to be practical: when G is large, M is V 2 Inefficiency: real-life graphs are often sparse 6
Adjacency Lists Each node carries a list of adjacent edges 1 2 3 4 1 0 1 1 1 2 1 0 0 0 3 0 1 0 1 4 1 1 0 0 1: 2, 4 2: 1, 3, 4 3: 1 4: 1, 3 Pros and cons efficient, especially for sparse graphs; easy to compute over outlinks difficult to compute over inlinks 7
Graph search (traversal) 8
Path queries Reachability Input: A directed graph G, and a pair of nodes s and t in G Question: Does there exist a path from s to t in G? Distance Input: A directed weighted graph G, and a node s in G Output: The lengths of shortest paths from s to all nodes in G Regular path Input: A node-labeled directed graph G, a pair of nodes s and t in G, and a regular expression R Question: Does there exist a path p from s to t that satisfies R? What do you know about these? 9
Reachability queries Reachability Input: A directed graph G, and a pair of nodes s and t in G Question: Does there exist a path from s to t in G? Applications: a routine operation Social graphs: are two people related for security reasons? Biological networks: find genes that are (directly or indirectly) influenced by a given molecule Nodes: molecules, reactions or physical interections Edges: interactions How to evaluate reachability queries? 10
Breadth-first search BFS (G, s, t): 1. while Que is nonempty do Use (a) a queue Que, initialized with s, (b) flag(v) for each node, initially false; and (c) adjacency lists to store G a. v Que.dequeue(); b. if v t then return true; c. for all adjacent edges e (v, u) of v do Why do we need the test? a) if not flag(u) Breadth-first, by using a queue then flag(u) true; enqueue u onto Que; 2. return false Complexity: each node and edge is examined at most once What is the complexity? 11
Breadth-first search Reachability: NL-complete Too costly as a routine operation when G is large BFS (G, s, t): O( V E ) time and space 1. while Que is nonempty do a. v Que.dequeue(); b. if v t then return true; c. for all adjacent edges e (v, u) of v do a) if not flag(u) then flag(u) true; enqueue u onto Que; 2. return false O(1) time? Yes, adjacency matrix, but O( V 2) space How to strike a balance? 12
2-hop cover For each node v in G, 2hop(v) (Lin(v), Lout(v)) Lin(v): a set of nodes in G that can reach v Lout(v): a set of nodes in G that v can reach To ensure: node s can reach t if and only if Lout(s) Lin(t) Testing: better than O( V E ) on average Space: O( V E 1/2) Find a minimum 2-hop cover? NP-hard Find a minimum 2-hop cover? NP-hard Maintenance cost in response to changes to G? Left as a project (LN 7) A number of algorithms for reachability queries (see reading list)13
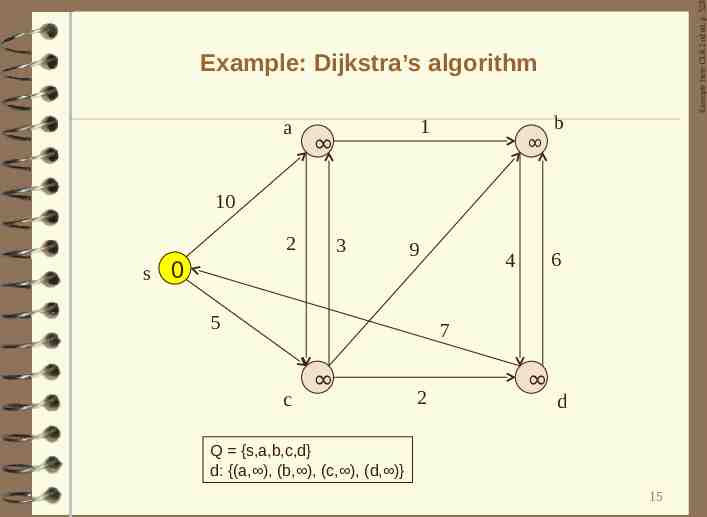
Distance queries Distance: single-source shortest-path problem Input: A directed weighted graph G, and a node s in G Output: The lengths of shortest paths from s to all nodes in G Application: transportation networks Dijkstra (G, s, w): 1. Use a priority queue Que; v): weight of edge (u, v); the distance from s to u for all nodes v in V do a. d[v] ; 2. d[s] 0; Que V; 3. while Que is nonempty do Extract one with the minimum d(u) a. u ExtractMin(Que); b. for all nodes v in adj(u) do a) w(u, d(u): if d[v] d[u] w(u, v) then d[v] d[u] w(u, v); 14
Example from CLR 2nd ed. p. 528 Example: Dijkstra’s algorithm a 1 b 10 2 s 3 0 9 5 6 4 7 c 2 d Q {s,a,b,c,d} d: {(a, ), (b, ), (c, ), (d, )} 15
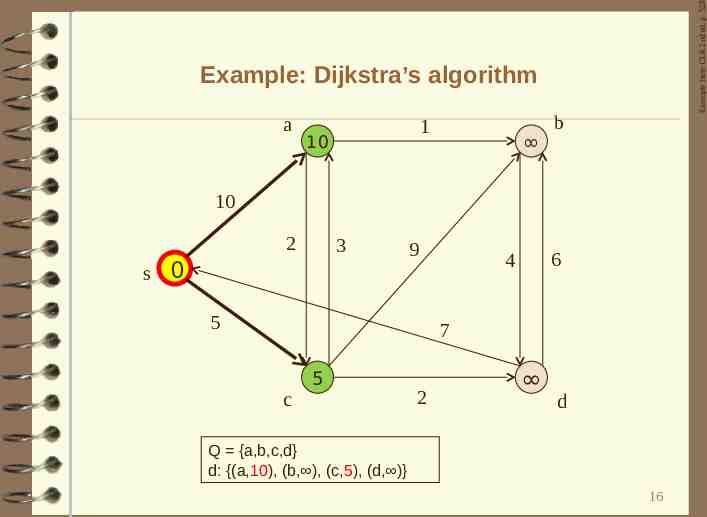
Example from CLR 2nd ed. p. 528 Example: Dijkstra’s algorithm a 1 10 b 10 2 s 3 0 9 5 6 4 7 c 5 2 d Q {a,b,c,d} d: {(a,10), (b, ), (c,5), (d, )} 16
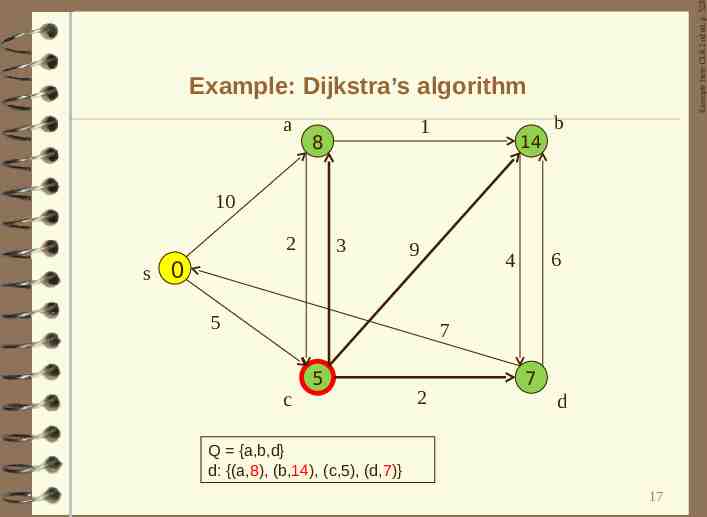
Example from CLR 2nd ed. p. 528 Example: Dijkstra’s algorithm a 1 8 14 b 10 2 s 3 0 9 5 6 4 7 c 5 2 7 d Q {a,b,d} d: {(a,8), (b,14), (c,5), (d,7)} 17
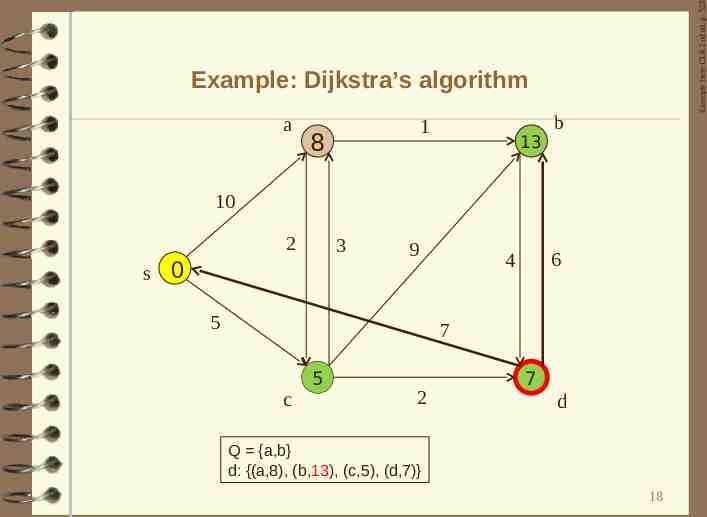
Example from CLR 2nd ed. p. 528 Example: Dijkstra’s algorithm a 1 8 13 b 10 2 s 3 0 9 5 6 4 7 c 5 2 7 d Q {a,b} d: {(a,8), (b,13), (c,5), (d,7)} 18
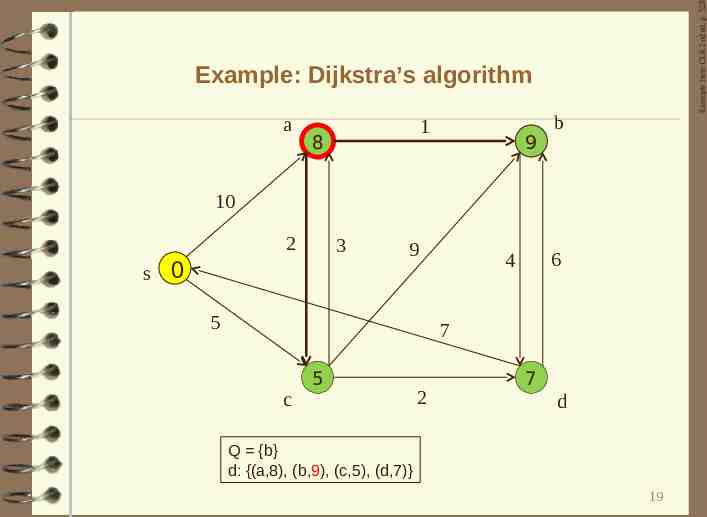
Example from CLR 2nd ed. p. 528 Example: Dijkstra’s algorithm a 1 8 9 b 10 2 s 3 0 9 5 6 4 7 c 5 2 7 d Q {b} d: {(a,8), (b,9), (c,5), (d,7)} 19
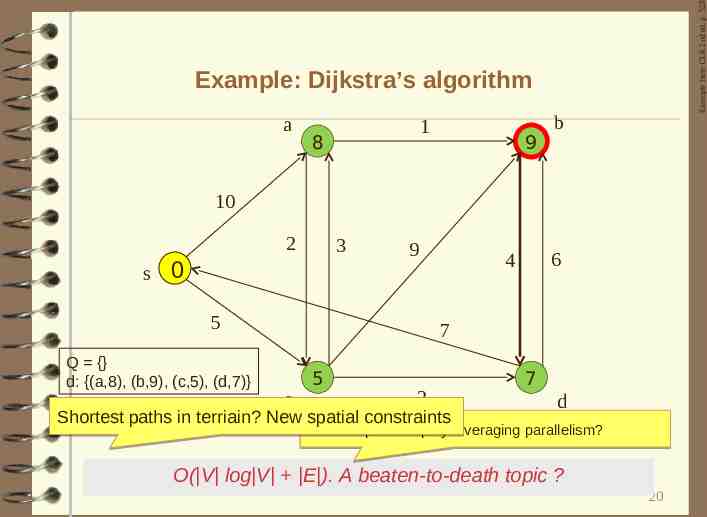
Example from CLR 2nd ed. p. 528 Example: Dijkstra’s algorithm a 1 8 9 b 10 2 s 3 0 9 5 Q {} d: {(a,8), (b,9), (c,5), (d,7)} 6 4 7 c 5 2 Shortest paths in terriain? New spatial constraints 7 d How to speed it up by leveraging parallelism? O( V log V E ). A beaten-to-death topic ? 20
Regular path queries Regular simple path Input: A node-labeled directed graph G, a pair of nodes s and t in G, and a regular expression R Question: Does there exist a simple path p from s to t such Mendelzon, andon P.pT.form Wood. Finding that the labels of A. adjacent nodes a string in R? Regular Simple Paths In Graph What isDatabases. the complexity? SICOMP 24(6), 1995 NP-complete, even when R is a fixed regular expression (00)* or 0*10*. In PTIME when G is a DAG (directed acyclic graph) Patterns of social links Why do we care about regular path queries? 21
Regular path queries Regular path Input: A node-labeled directed graph G, a pair of nodes s and t in G, and a regular expression R Question: Does there exist a path p from s to t such that the labels of adjacent nodes on p form a string in R? What is the complexity? PTIME Show that the regular path problem is in O( G R ) time Graph queries are nontrivial, even for path queries 22
Strongly connected components A strongly connected component in a direct graph G is a set V of nodes in G such that for any pair (u, v) in V, u can reach v and v can reach u; and V is maximal: adding any node to V makes it no longer strongly connected Find social circles: how large? How many? Find social circles: how large? How many? SCC Input: A graph G Question: all strongly connected components of G What is the complexity? by extending search algorithms, e.g., BFS O( V E ) 23
PageRank 24
Introduction to PageRank To measure the “quality” of a Web page Input: A directed graph G modelling the Web, in which nodes represent Web pages, and edges indicate hyperlinks Output: For each node v in G, P(v): the likelihood that a random walk over G will arrive at v. Intuition: how a random walk can reach v? The chances of hitting v among V pages A random jump: (1/ V ) : random jump factor (teleportation factor) Following a hyperlink: (1 - ) (u L(v)) P(u)/C(u) (1 - ): damping factor (1 - ) (u L(v)) P(u)/C(u): the chances for one to click a hyperlink at a page u and reach v Two parts 25
Intuition Following a hyperlink: (1 - ) (u L(v)) P(u)/C(u) L(v): the set of pages that link to v; C(u): the out-degree of node (the number linkspage on u) The chances of ureaching page voffrom u P(u)/C(u): the probability of u being visited itself the probability of clicking the link to v among C(u) many links on page u Intuition: the more pages link to v, and the more popular those pages that link to v, v has a higher chance to be visited One of the models 26
Putting together The likelihood that page v is visited by a random walk: P(v) (1/ V ) (1 - ) (u L(v)) P(u)/C(u) random jump following a link from other pages Recursive computation: for each page v in G, until compute P(v) by using P(u) for all u L(v) too expensive; use an error factor converge: no changes to any P(v) after a fixed number of iterations costly: trillions of pages Parallel computation How to speed it up? 27
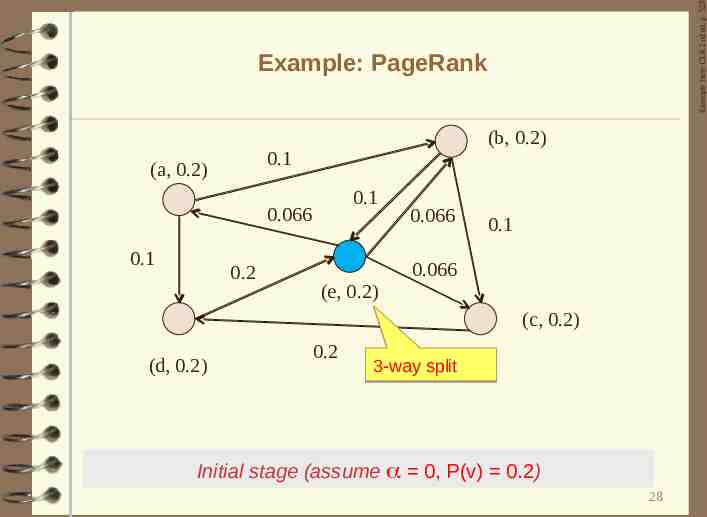
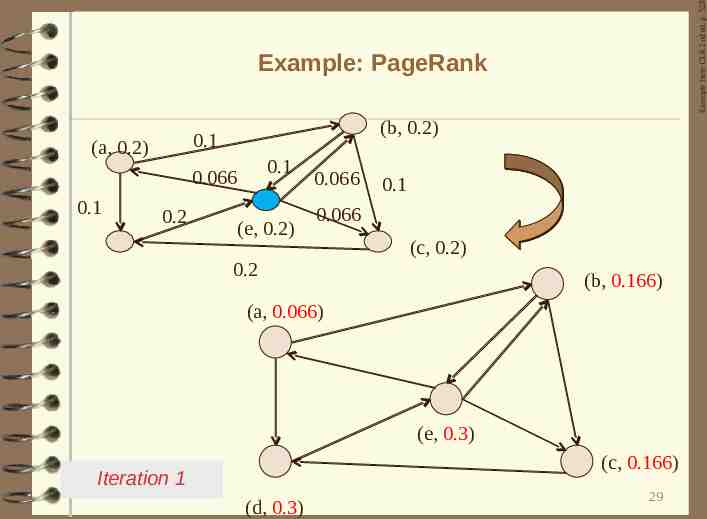
Example from CLR 2nd ed. p. 528 Example: PageRank (b, 0.2) 0.1 (a, 0.2) 0.1 0.066 0.1 0.2 (e, 0.2) 0.066 0.1 0.066 (c, 0.2) (d, 0.2) 0.2 3-way split Initial stage (assume 0, P(v) 0.2) 28
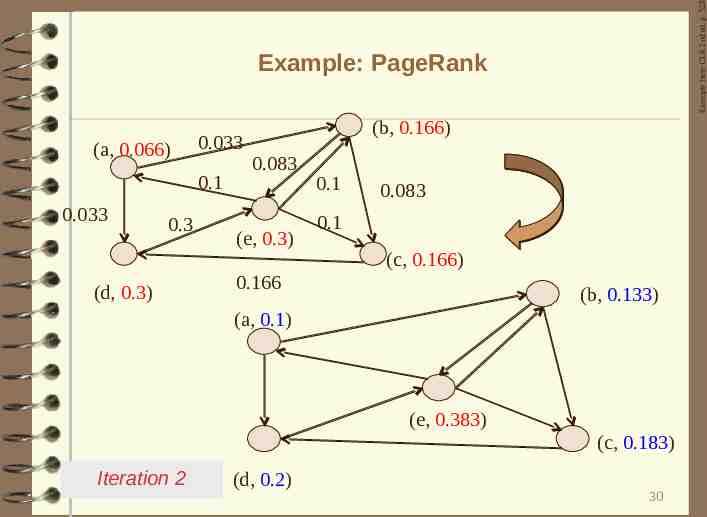
Example from CLR 2nd ed. p. 528 Example: PageRank (b, 0.2) 0.1 (a, 0.2) 0.1 0.066 0.1 0.2 (e, 0.2) 0.066 0.1 0.066 0.2 (c, 0.2) (b, 0.166) (a, 0.066) (e, 0.3) (c, 0.166) Iteration 1 (d, 0.3) 29
Example from CLR 2nd ed. p. 528 Example: PageRank (a, 0.066) 0.033 0.1 0.033 0.3 (d, 0.3) (b, 0.166) 0.083 (e, 0.3) 0.1 0.083 0.1 (c, 0.166) 0.166 (b, 0.133) (a, 0.1) (e, 0.383) (c, 0.183) Iteration 2 (d, 0.2) 30
Find nearest neighbors 31
Nearest neighbor Nearest neighbor (kNN) Input: A set S of points in a space M, a query point p in M, a distance function dist(u, v), and a positive integer k Output: Find top-k points in S that are closest to p based on dist(p, u) Euclidean distance, Hamming distance, continuous variables, Applications POI recommendation: find me top-k restaurants close to where I am Classification: classify an object based on its nearest neighbors Regression: property value as the average of the values of its k nearest neighbors Linear search, space partitioning, locality sensitive hashing, compression/clustering based search, A number of techniques 32
kNN join kNN join Input: Two datasets R and S, a distance function dist(r, s), and a positive integer k Output: pairs (r, s) for all r in R, where s is in S, and is one of the k-nearest neighbors of r Pairwise comparison A naive algorithm Scanning S once for each object in R O( R S ): expensive when R or S is large Can we do better? 33
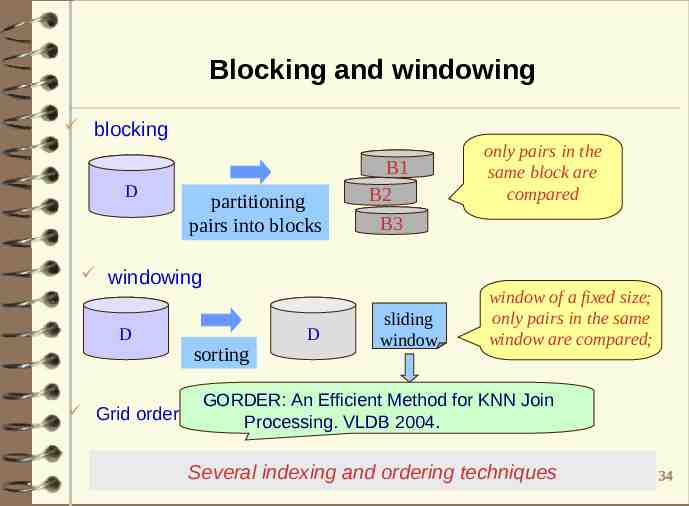
Blocking and windowing blocking D partitioning pairs into blocks B1 B2 B3 windowing D sorting D sliding window only pairs in the same block are compared window of a fixed size; only pairs in the same window are compared; GORDER: An Efficient Method for KNN Join Grid order: rectangle cells, sorted by surrounding points Processing. VLDB 2004. Several indexing and ordering techniques 34
Keyword search 35
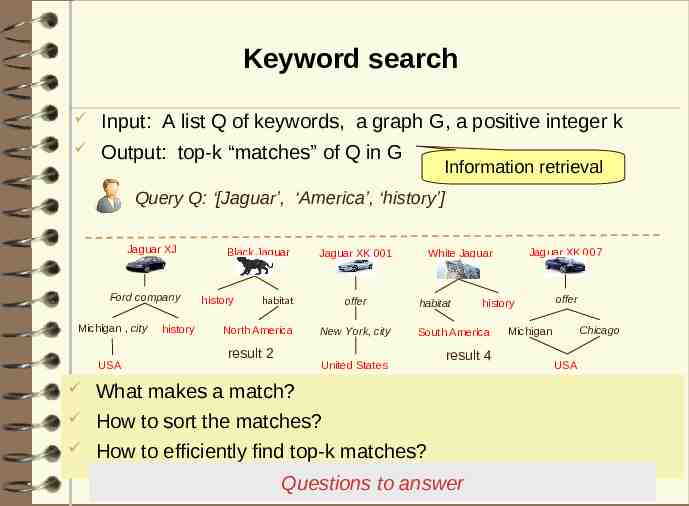
Keyword search Input: A list Q of keywords, a graph G, a positive integer k Output: top-k “matches” of Q in G Information retrieval Query Q: ‘[Jaguar’, ‘America’, ‘history’] Jaguar XJ Ford company Michigan , city USA history Black Jaguar history habitat North America result 2 offer New York, city Jaguar XK 007 White Jaguar Jaguar XK 001 habitat South America United States result 4 resultmakes 1 result 3 What a match? How to sort the matches? How to efficiently find top-k matches? Questions to answer offer history Chicago Michigan USA result 5 36
Semantics: Steiner tree Input: A list Q of keywords, a graph G, a weight function w(e) on the edges on G, and a positive integer k Output: top-k Steiner trees that match Q PageRank scores Match: a subtree T of G such that each keyword in Q is contained in a leaf of T Ranking: The total weight of T (the sum of w(e) for all edges e in T) The cost to connect the keywords Complexity? NP-complete What can we do about it? 37
Semantics: distinct-root (tree) Input: A list Q of keywords, a graph G, and a positive integer k Output: top-k distinct trees that match Q Match: a subtree T of G such that each keyword in Q is contained in a leaf of T Ranking: dist(r, q): from the root of T to a leaf q The sum of distances from root to allresult, leaves of T To avoid toothe homogeneous e.g., a hub as a root Diversification: each match in the top-k answer has a distinct root How many candidate matches for root? O( Q ( V log V E )) 38
Semantics: Steiner graphs Input: A list Q of keywords, an undirected (unweighted) graph G, a positive integer r, and a positive integer k Output: Find all r-radius Steiner graphs that match Q Match: a subgraph G’ of G such that it is r-radius: the shortest distance between any pair of nodes in G is at most r (at least one pair with the distance); and each keyword is contained in a content node a Steiner node: on a simple path between a pair of content nodes Computation: Mr, the r-th power of adjacency graph of G Revision: minimum subgraphs 39
Answering keyword queries A host of techniques Backward search Bidirectional search Bi-level indexing G. Bhalotia, A. Hulgeri, C. Nakhe, S. Chakrabarti, and S. Sudarshan. Keyword searching and browsing in databases using BANKS. ICDE 2002. V. Kacholia, S. Pandit, S. Chakrabarti, S. Sudarshan, R. Desai, and H. Karambelkar. Bidirectional expansion for keyword search on graph databases. VLDB 2005. H. He, H. Wang, J. Yang, and P. S. Yu. BLINKS: ranked keyword searches on graphs. SIGMOD 2007. A well studied topic 40
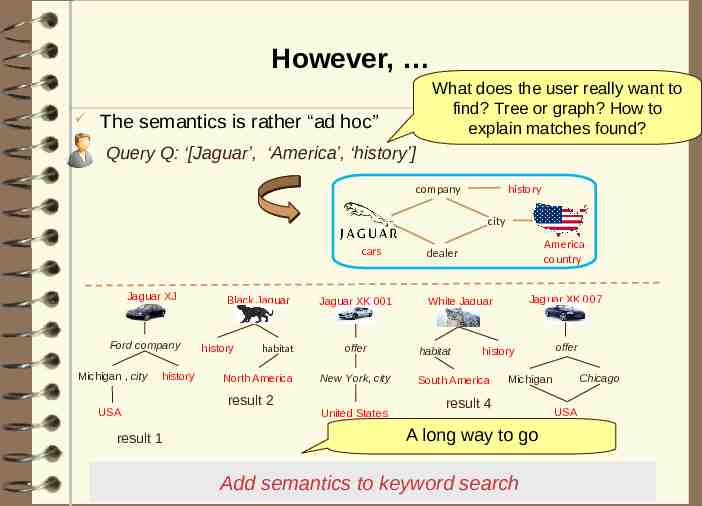
However, What does the user really want to find? Tree or graph? How to explain matches found? The semantics is rather “ad hoc” Query Q: ‘[Jaguar’, ‘America’, ‘history’] history company city cars Jaguar XJ Ford company Michigan , city history USA result 1 Black Jaguar history habitat North America result 2 Jaguar XK 001 offer New York, city United States result 3 America country dealer Jaguar XK 007 White Jaguar habitat history South America offer Chicago Michigan result 4 USA A long way to go result 5 Add semantics to keyword search 41
Summing up 42
Graph query languages There have been efforts to develop graph query languages. Querying topological structures SoQL: an SQL-like language to retrieve paths CRPQ: extending conjunctive queries with regular path expressions R. Ronen and O. Shmueli. SoQL: A language for querying and creating data in social networks. ICDE, 2009. P. Barceló, C. A. Hurtado, L. Libkin, and P. T. Wood. Expressive languages for path queries over graph-structured data. In PODS, 2010 SPARQL: for RDF data Read this http://www.w3.org/TR/rdf-sparql-query/ Unfortunately, no “standard” query language for social graphs, yet 43
Summary and review Why are reachability queries? Regular path queries? Connected components? Complexity? Algorithms? What are factors for PageRank? How does PageRank work? What are kNN queries? What is a kNN join? Complexity? What are keyword queries? What is its Steiner tree semantics? Distinct-root semantics? Steiner graph semantics? Complexity? Name a few applications of graph queries you have learned. Find graph queries that are not covered in the lecture. 44
Project (1) Recall regular path queries: Input: A node-labeled directed graph G, a pair of nodes s and t in G, and a regular expression R Question: Does there exist a path p from s to t that satisfies R? Develop two algorithms for evaluating regular path queries: a sequential algorithm by using 2-hop covers; and an algorithm in MapReduce Prove the correctness of your algorithms and give complexity analysis Experimentally evaluate your algorithms, especially their scalability A development project 45
Project (2) GPath. Extend XPath to query directed, node-labeled graphs. Design GPath, a query language for graphs. A GPath query Q starts from a context node v in a graph G, traverses G and returns all the nodes that are reachable from v by following Q. GPath should support the child axis, wildcard *, self-or-descendants (//), and filters (aka qualifiers, such as [p c]). Justify your design. Develop an algorithm that, given a GPath query Q, a graph G, and a context node v in G, computes Q(G), the set of nodes reachable from v in G by following Q. Give a complexity analysis of your algorithm and show its correctness. Experimentally evaluate your algorithm A research project 46
Project (3) Study keyword search in graphs. Pick a semantics for keyword search and an algorithm for implementing keyword search based on the semantics Justify your choice: semantics and algorithm Implement the algorithm in whatever language you like Experimentally evaluate your implementation Demonstrate your keyword search support A development project 47
Reading A. Mendelzon, and P. Wood. Finding regular simple paths in graph databases. SICOMP, 24(6), 1995. ftp://ftp.db.toronto.edu/pub/papers/sicomp95.ps.Z J. Xu and J. Chang. Graph reachability queries: a survey. http://citeseerx.ist.psu.edu/viewdoc/summary?doi 10.1.1.352.2250 J. Xu, L. Qin, and J. Chang. Keyword Search in Relational Databases: A Survey. http://sites.computer.org/debull/A10mar/yu-paper.pdf Acknowledgments: some animation slides are borrowed from www.cs.kent.edu/ jin/Cloud12Spring/GraphAlgorithms.pptx 48
Papers for you to review E. Cohen, E. Halperin, H. Kaplan, and U. Zwick. Reachability and distance queries via 2-hop labels. SODA 2002. http://www.cs.tau.ac.il/ heran/cozygene/publications/papers/labels.pdf R. Bramandia, B. Choi, and W. Ng. On Incremental Maintenance of 2hop Labeling of Graphs. WWW 2008. http://wwwconference.org/www2008/papers/pdf/p845-bramandia.pdf M. Kaul, R.Wong, B. Yang, C. Jensen. Finding Shortest Paths on Terrains by Killing Two Birds with One Stone. VLDB 2014. http://www.vldb.org/pvldb/vol7/p73-kaul.pdf C. Xia, H. Lu, B. Ooi and J. Hu. GORDER: An Efficient Method for KNN Join Processing. VLDB 2004. http://www.vldb.org/conf/2004/RS20P2.PDF 49
Papers for you to review G. Bhalotia, A. Hulgeri, C. Nakhe, S. Chakrabarti, and S. Sudarshan. Keyword searching and browsing in databases using BANKS. ICDE 2002. http://www.cse.iitb.ac.in/ sudarsha/Pubs-dir/BanksICDE2002.pdfR V. Kacholia, S. Pandit, S. Chakrabarti, S. Sudarshan, R. Desai, and H. Karambelkar. Bidirectional expansion for keyword search on graph databases. VLDB 2005. http://www.researchgate.net/publication/ 221310807 Bidirectional Expansion For Keyword Search on Graph Dat abases H. He, H. Wang, J. Yang, and P. S. Yu. BLINKS: ranked keyword searches on graphs. SIGMOD 2007. http://db.cs.duke.edu/papers/2007-SIGMOD-hwyy-kwgraph.pdf Y. Wu, S. Yang, M. Srivatsa, A. Iyengar, X. Yan. Summarizing Answer Graphs Induced by Keyword Queries. VLDB 2014. http://www.cs.ucsb.edu/ yinghui/mat/papers/gsum vldb14.pdf 50






