Purdue CS440 (CS490-LDA): Large-Scale Data Analytics (Fall 2023)




























50 Slides1.72 MB
Purdue CS440 (CS490-LDA): Large-Scale Data Analytics (Fall 2023) Lecture 29 & 30: Cloud Data Analytics Jianguo Wang 11/27/2023
Outline What’s cloud computing? How to build cloud-native data systems? 2
Cloud Computing 3
Motivating Example Consider you want to build a startup called xyz.com, then how to build your IT infrastructure? Buy servers But how many? How much memory, disk, CPU, GPU? Challenge: don’t know the load (e.g., how many users) and the load changes a lot (e.g., weekends and Black Fridays) Simple solution: provision for peak load, but underutilize in most times [AFG 09] 4
Motivating Example Build a data center Where to physically put the servers? What if the machines are crashed? What if software upgrade? Cooling techniques All is possible without Personnel cloud, but at what cost? Hiring skilled engineers (hard for startups) 5
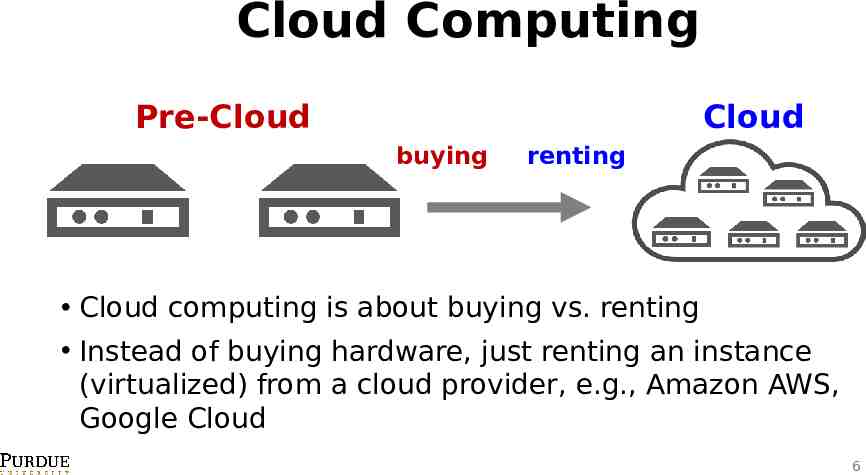
Cloud Computing Pre-Cloud Cloud buying renting Cloud computing is about buying vs. renting Instead of buying hardware, just renting an instance (virtualized) from a cloud provider, e.g., Amazon AWS, Google Cloud 6
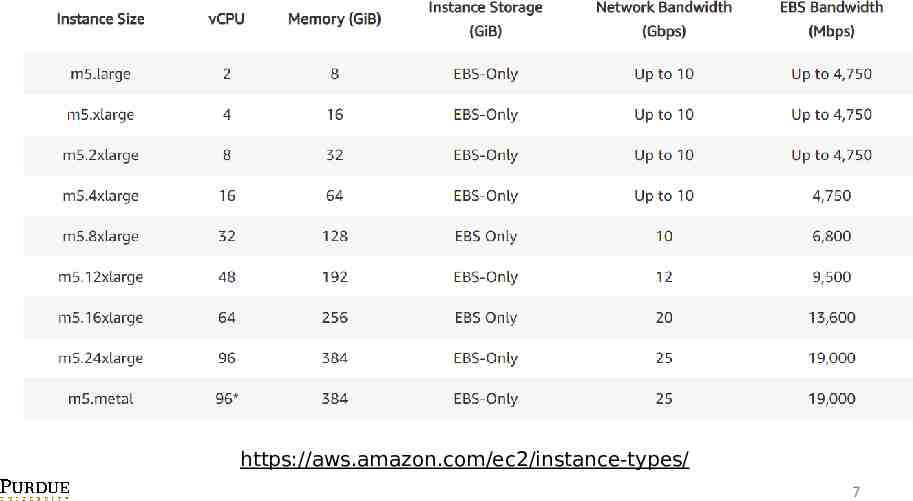
https://aws.amazon.com/ec2/instance-types/ 7
Cloud Computing But cloud computing is more than renting hardware Definition from National Institute of Standards and Technology (NIST) “Cloud computing is a model for enabling ubiquitous, convenient, ondemand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.” https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf 8
Key Characteristics Pay-as-you-go Only pay for what you use with fine-grained metering, no up-front commitment E.g., CPU per hour, memory per GB Elasticity Users can release resources if not needed or request additional resources if needed, ideally automatically (e.g., serverless computing) Virtualization All the resources (e.g., CPU, memory, disk, network) are virtualized, no software is bounded to hardware Resourced are pooled to serve multiple users (multi-tenancy) Automation No human interaction, E.g., start/stop a machine, crash, backup Everything is managed by cloud providers 9
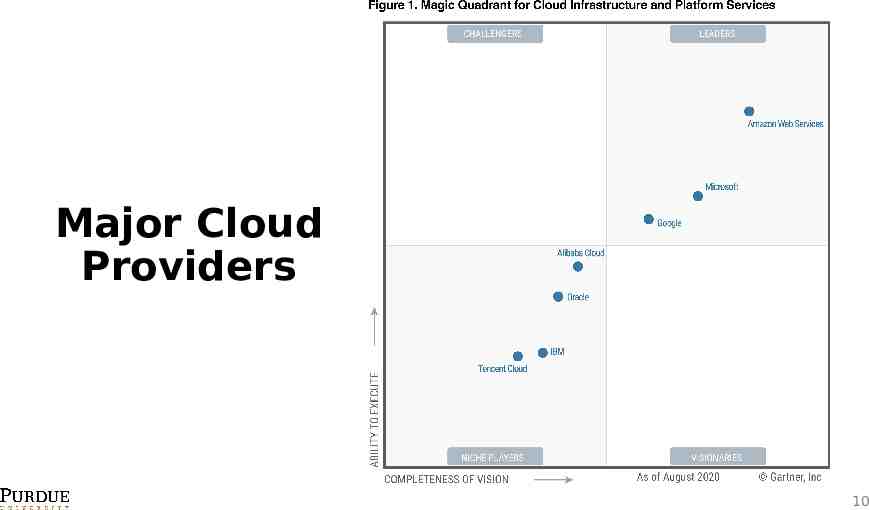
Major Cloud Providers 10
Why Cloud Providers? Customers can save money by using cloud computing, but why companies want to be cloud providers? Two major reasons Economies of scale: 5 7X cheaper Re-use existing investments, e.g., data centers, expertise Above the Clouds: A Berkeley View of Cloud Computing 11 https://www2.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.html
Cloud-Native Databases 12
Early Cloud Databases How to build databases on the cloud? 2010 2015: cloud-hosting database Treat each cloud machine the same as in-house machine Run existing database systems directly https://aws.amazon.com/rds/ 13
Early Cloud Databases Some research questions Storage: shared-nothing or shared storage? Data model: key-value, SQL, or? OLAP or OLTP: which one best fits cloud, ACID or not? Virtualization & multi-tenancy: how to put more instances to a physical server while keeping SLA (service-level agreement)? 14
Cloud-Native Database (2016 ) What’s cloud-native database? People realize that cloud servers are different from on-premise bare-metal servers Cloud-native databases are re-architectured to fully leverage the cloud infrastructure Resource disaggregation, e.g., storage disaggregation Resource pooling, e.g., storage pooling Examples: Amazon Aurora, Alibaba PolarDB, Microsoft Socrates, Snowflake 15
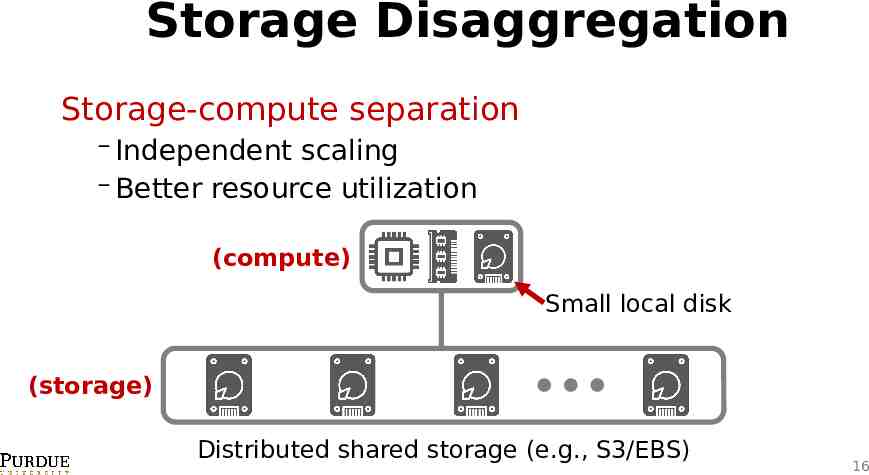
Storage Disaggregation Storage-compute separation Independent scaling Better resource utilization (compute) Small local disk (storage) Distributed shared storage (e.g., S3/EBS) 16
Implications What’re the implications of storage disaggregation and storage pooling? Database software level needs to be aware of the underlying hardware-level resource disaggregation Software-level disaggregation In order to enable more optimizations Distributed database architecture needs to be changed From shared-nothing to shared-storage 17
Amazon Aurora: A Cloud-Native Database 18
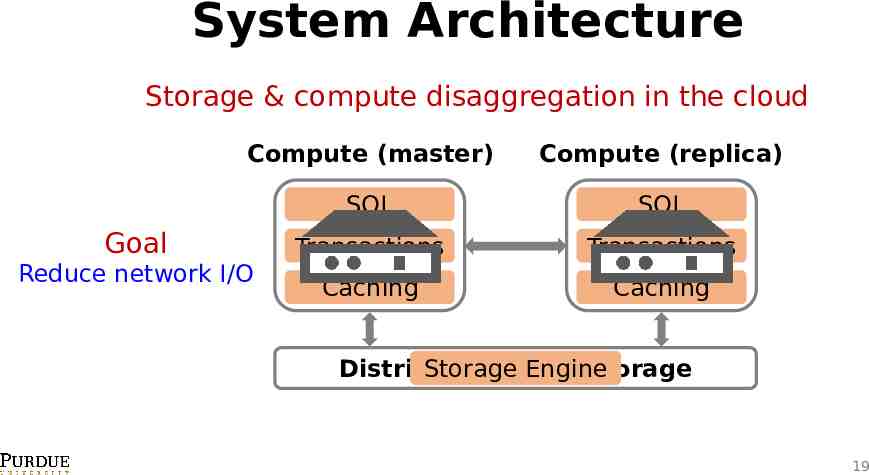
System Architecture Storage & compute disaggregation in the cloud Compute (master) Compute (replica) SQL SQL Transactions Transactions Caching Caching Goal Reduce network I/O Distributed Storage Cloud Engine Storage 19
Main Ideas Log is the database Only write redo logs on network Push log applicator to storage tier Asynchronous processing Materialize pages in background Buffer cache To avoid network I/O Can read pages upon cache miss Compute (master) SQL Transactions Caching ONLY LOGS Storage Engine 20
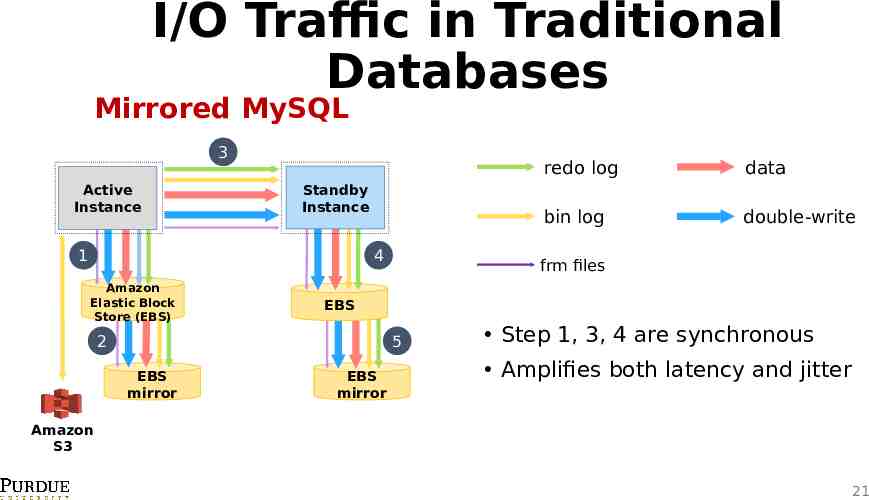
I/O Traffic in Traditional Databases Mirrored MySQL 3 Active Instance Standby Instance 1 4 Amazon Elastic Block Store (EBS) data bin log double-write frm files EBS 2 5 EBS mirror redo log EBS mirror Step 1, 3, 4 are synchronous Amplifies both latency and jitter Amazon S3 21
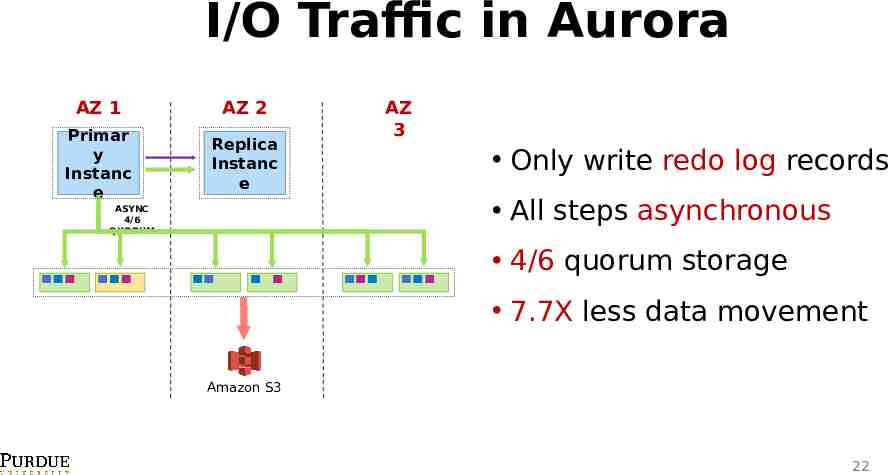
I/O Traffic in Aurora AZ 1 AZ 2 Primar y Instanc e Replica Instanc e AZ 3 Only write redo log records All steps asynchronous ASYNC 4/6 QUORUM 4/6 quorum storage 7.7X less data movement Amazon S3 22
How Does Database Work with Logs? Read Cache Replication Write Commit Recovery 23
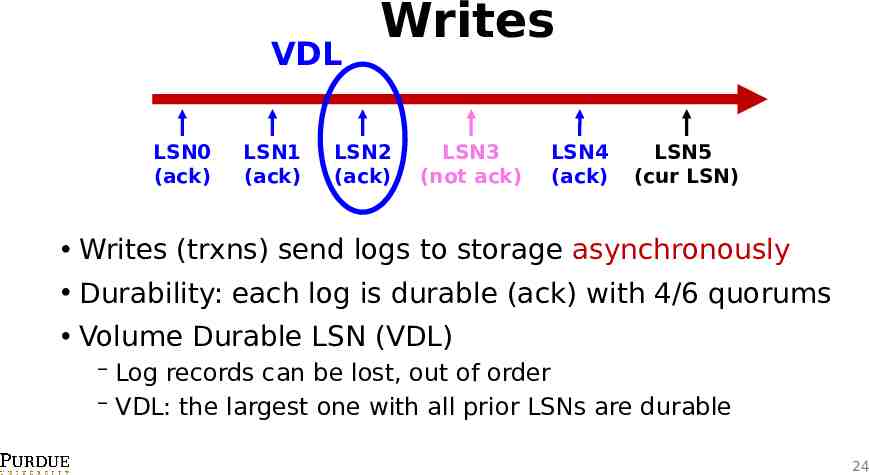
VDL LSN0 (ack) LSN1 (ack) Writes LSN2 (ack) LSN3 (not ack) LSN4 (ack) LSN5 (cur LSN) Writes (trxns) send logs to storage asynchronously Durability: each log is durable (ack) with 4/6 quorums Volume Durable LSN (VDL) Log records can be lost, out of order VDL: the largest one with all prior LSNs are durable 24
Transaction Commits LSN0 (ack) LSN1 (ack) LSN2 (ack) LSN3 LSN4 (not ack)(commit LSN) VDL Transaction commits asynchronously When a transaction commits, mark its commit LSN Commit only if VDL commit LSN 25
Replication: Scalability Writer Reader1 R2 R15 Distributed Shared Storage 1 writer and up to 15 reader instances Question: why 1 writer? How to keep data consistent between writer and readers? 26
Replication: Scalability Writer Reader1 R2 R15 Distributed Shared Storage How to keep data consistent between writer and readers? The writer sends logs to readers at the same time Once the reader receives logs, it will check if the page is in the cache If yes, apply the log; Otherwise, discard it Replication lag: 20ms 27
Reads (Caching) Each reader instance has a buffer (cache) Upon reads, check cache first The cache is supposed to contain the latest data pages Except replication lags What if the cache is full? Always evict a clean page: a page that’s durable (pageLSN VDL) Why? Otherwise, need to write dirty pages to storage, which increases network overhead 28
Crash Recovery Writer Reader1 R2 R15 Distributed Shared Storage If writer (master) is crashed, detected by HM (health monitor), promote a reader to writer first, and perform recovery What if the failed writer comes back? Contact HM Sometimes two masters many unexpected issues 29
Crash Recovery Traditional Databases Aurora Have to replay logs since the last checkpoint Typically 5 minutes between checkpoints No need to generate pages during recovery (very fast) Just need to re-establish VDL make sure storage is consistent Generate pages asynchronously, in parallel Single-threaded in MySQL; requires a large number of disk accesses DB engine undo partial transactions Typically a few seconds 30
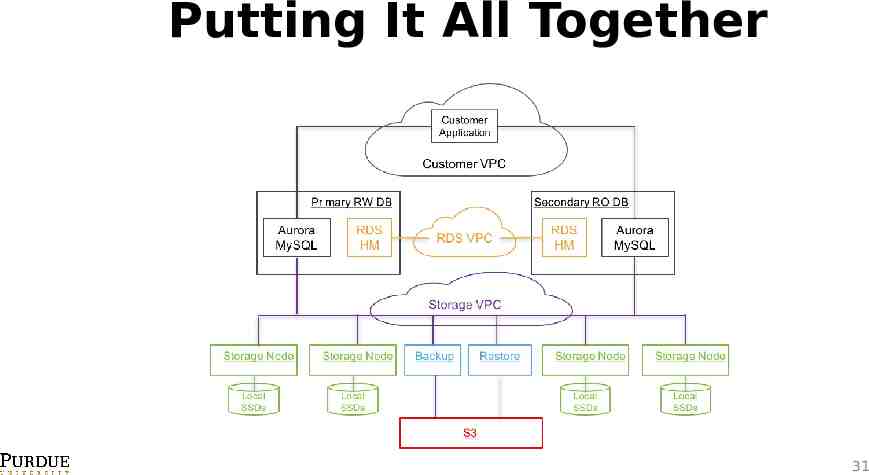
Putting It All Together 31
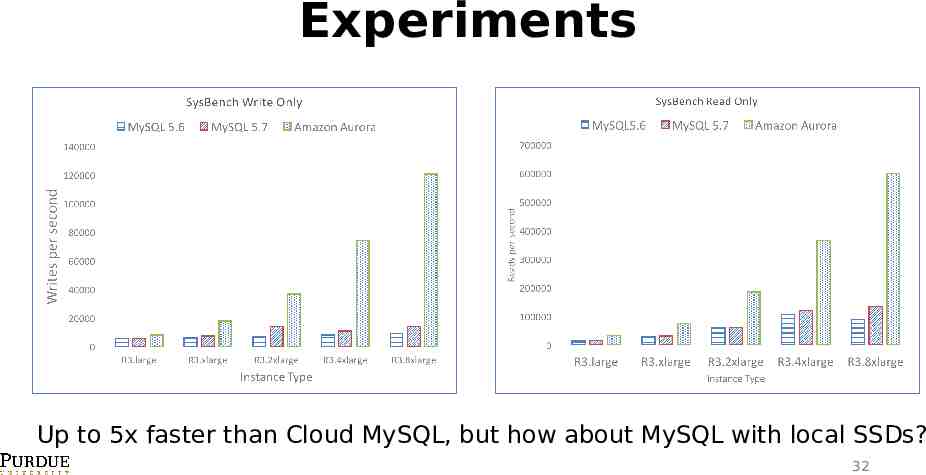
Experiments Up to 5x faster than Cloud MySQL, but how about MySQL with local SSDs? 32
Comments on Aurora New way of building cloud DB systems Monolithic (since 1970s) disaggregation Hardware & software Widely adopted in industry Microsoft Socrates DB Alibaba PolarDB Tencent CynosDB Huawei TaurusDB 33
Microsoft Socrates Similar to Amazon Aurora, it’s also designed for storagecompute disaggregation Key difference: separate log service from page service Philosophy: separate durability (implemented by logs) from availability (implemented by pages) Allow customized optimizations for logs and pages Durability does not require copies in fast storage Availability does not require a fixed number of replicas Antonopoulos et al. Socrates: The New SQL Server in the Cloud. SIGMOD 2019. 34
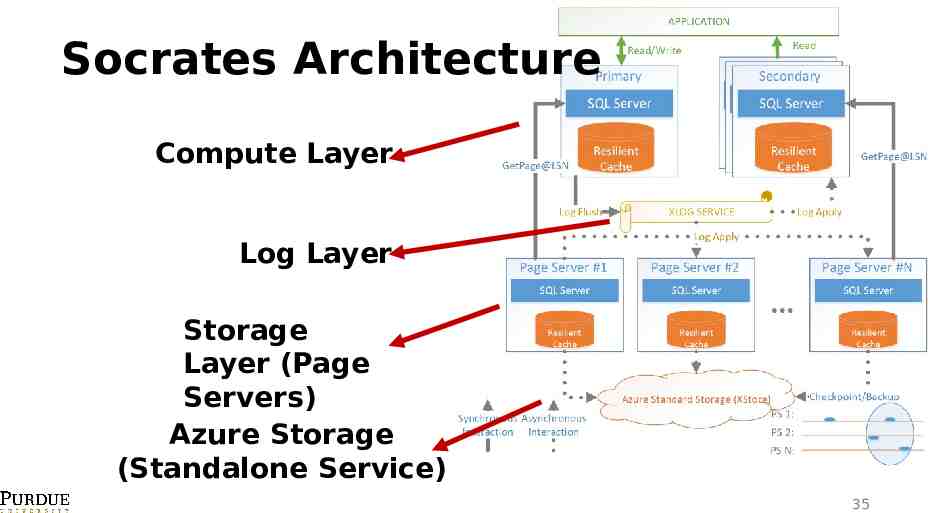
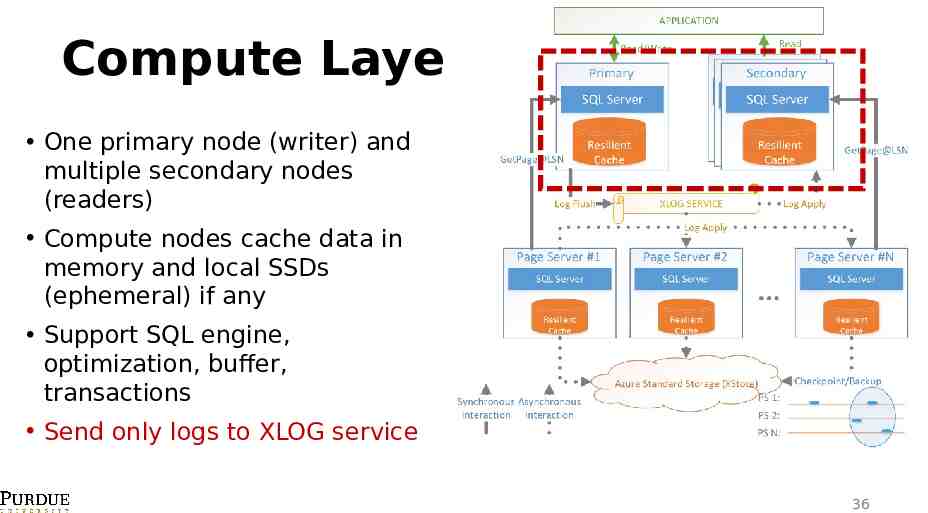
Socrates Architecture Compute Layer Log Layer Storage Layer (Page Servers) Azure Storage (Standalone Service) 35
Compute Layer One primary node (writer) and multiple secondary nodes (readers) Compute nodes cache data in memory and local SSDs (ephemeral) if any Support SQL engine, optimization, buffer, transactions Send only logs to XLOG service 36
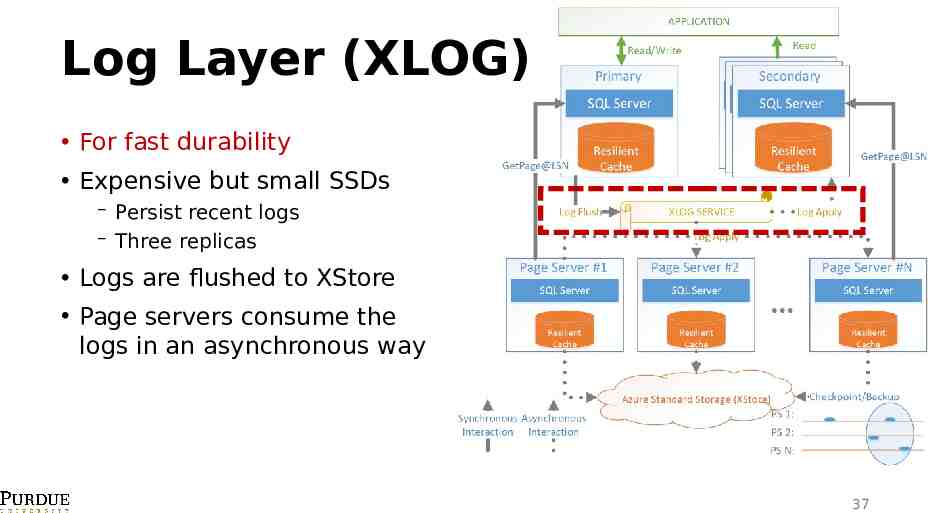
Log Layer (XLOG) For fast durability Expensive but small SSDs Persist recent logs Three replicas Logs are flushed to XStore Page servers consume the logs in an asynchronous way 37
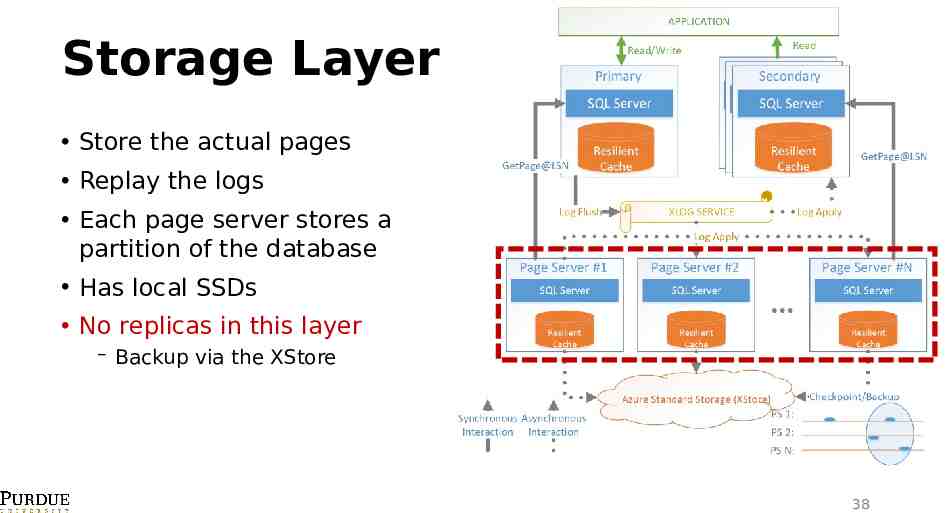
Storage Layer Store the actual pages Replay the logs Each page server stores a partition of the database Has local SSDs No replicas in this layer Backup via the XStore 38
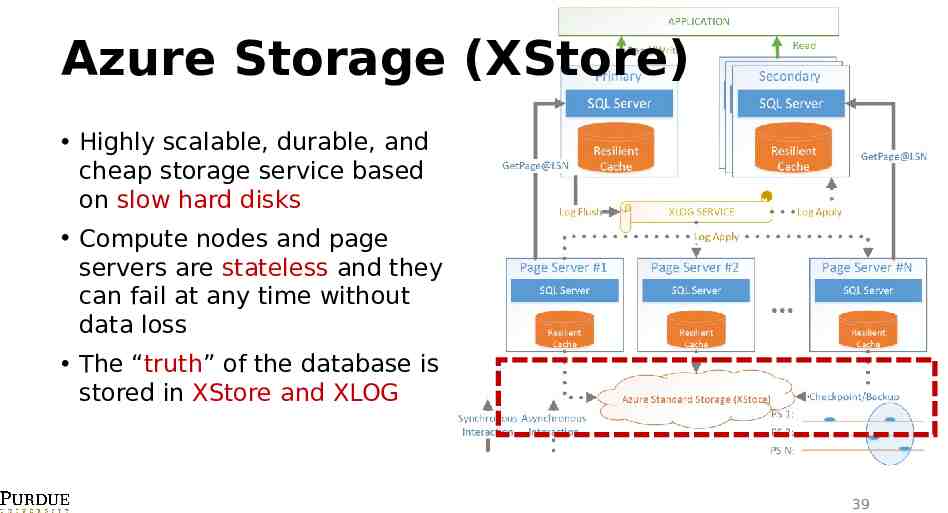
Azure Storage (XStore) Highly scalable, durable, and cheap storage service based on slow hard disks Compute nodes and page servers are stateless and they can fail at any time without data loss The “truth” of the database is stored in XStore and XLOG 39
Appendix 40
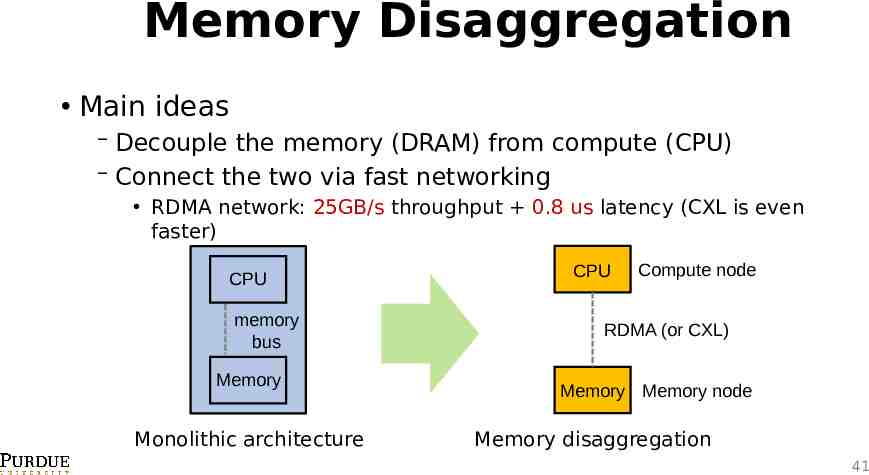
Memory Disaggregation Main ideas Decouple the memory (DRAM) from compute (CPU) Connect the two via fast networking RDMA network: 25GB/s throughput 0.8 us latency (CXL is even faster) CPU memory bus Memory Monolithic architecture CPU Compute node RDMA (or CXL) Memory Memory node Memory disaggregation 41
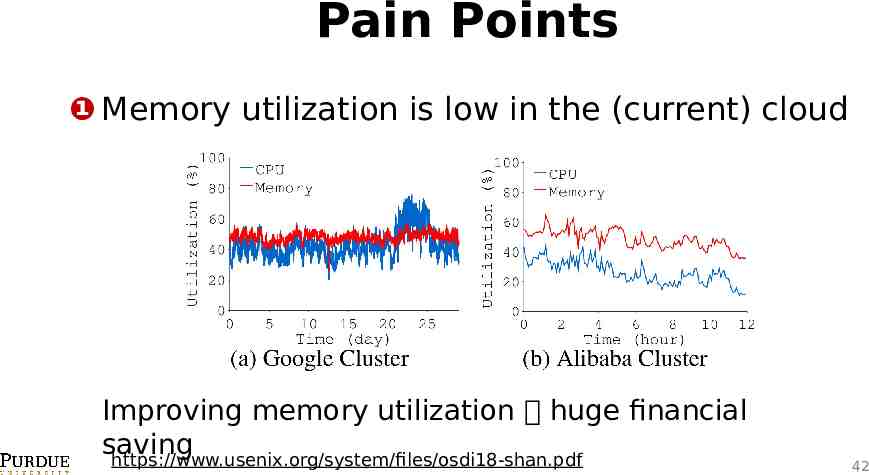
Pain Points ❶ Memory utilization is low in the (current) cloud Improving memory utilization huge financial saving https://www.usenix.org/system/files/osdi18-shan.pdf 42
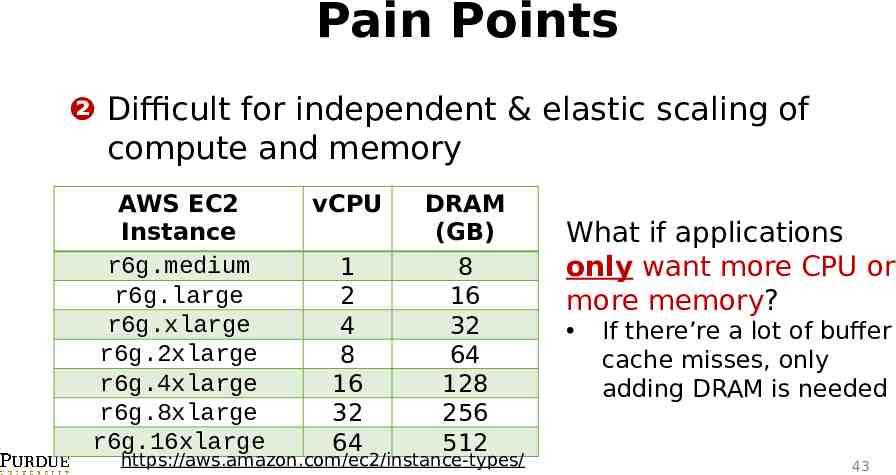
Pain Points ❷ Difficult for independent & elastic scaling of compute and memory AWS EC2 Instance r6g.medium r6g.large r6g.xlarge r6g.2xlarge r6g.4xlarge r6g.8xlarge r6g.16xlarge vCPU 1 2 4 8 16 32 64 DRAM (GB) 8 16 32 64 128 256 512 https://aws.amazon.com/ec2/instance-types/ What if applications only want more CPU or more memory? If there’re a lot of buffer cache misses, only adding DRAM is needed 43
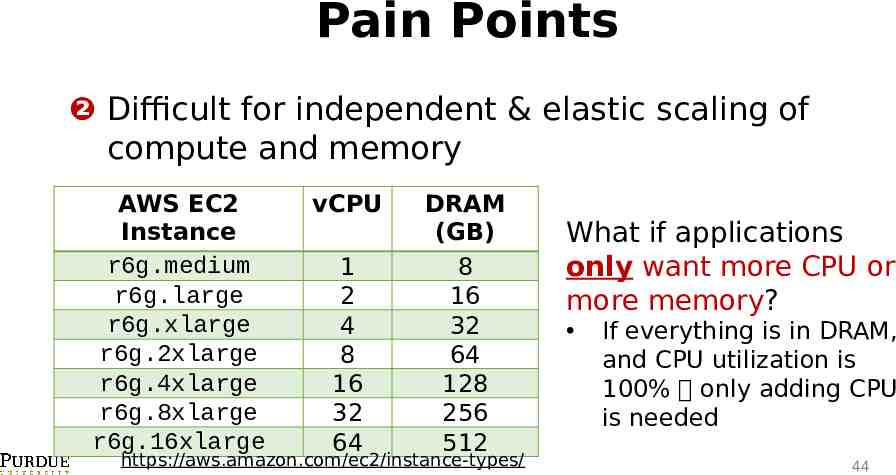
Pain Points ❷ Difficult for independent & elastic scaling of compute and memory AWS EC2 Instance r6g.medium r6g.large r6g.xlarge r6g.2xlarge r6g.4xlarge r6g.8xlarge r6g.16xlarge vCPU 1 2 4 8 16 32 64 DRAM (GB) 8 16 32 64 128 256 512 https://aws.amazon.com/ec2/instance-types/ What if applications only want more CPU or more memory? If everything is in DRAM, and CPU utilization is 100% only adding CPU is needed 44
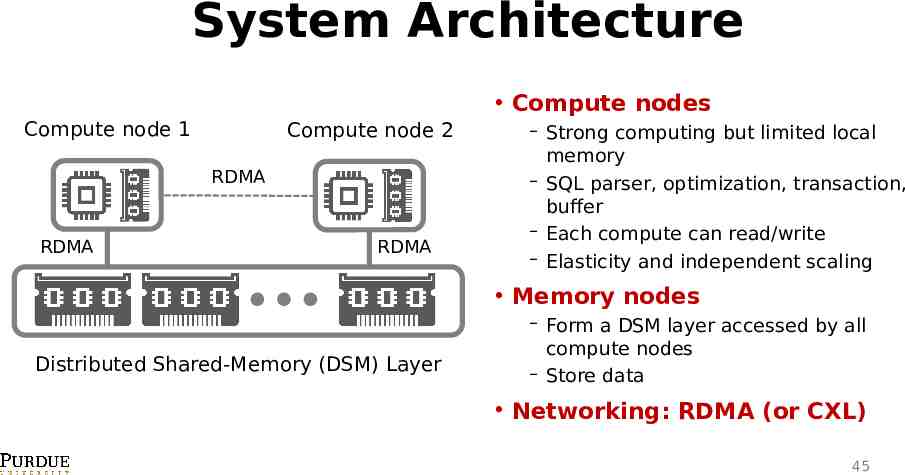
System Architecture Compute nodes Compute node 1 Compute node 2 RDMA RDMA RDMA Strong computing but limited local memory SQL parser, optimization, transaction, buffer Each compute can read/write Elasticity and independent scaling Memory nodes Distributed Shared-Memory (DSM) Layer Form a DSM layer accessed by all compute nodes Store data Networking: RDMA (or CXL) 45
Concurrency Control Challenge No hardware-supported cache coherence between compute nodes Main difference with multi-core single-node architecture Cannot directly use existing CC protocols, e.g., 2PL, MVCC, OCC 46
Why Is Cache Coherence Important? Do we use the local buffer in each compute node? If yes, need to address cachecoherence problem via softwarelevel overhead If not, performance (many remote accesses) Do we use sharding between compute nodes? 47
Alternative #1: No Sharding, No Cache Each compute node reads/writes all data But doesn't store any data in local buffer No cache coherence issue Data pages are stored in DSM All compute nodes use RDMA CAS (compare & swap) to acquire a lock first But many remote accesses 48
Alternative #2: No Sharding, With Cache Each compute node reads/writes all data Each compute node caches local data How to resolve conflicts? Develop a software-level cache coherence protocol Update-based Invalidation-based Not clear about the overhead 49
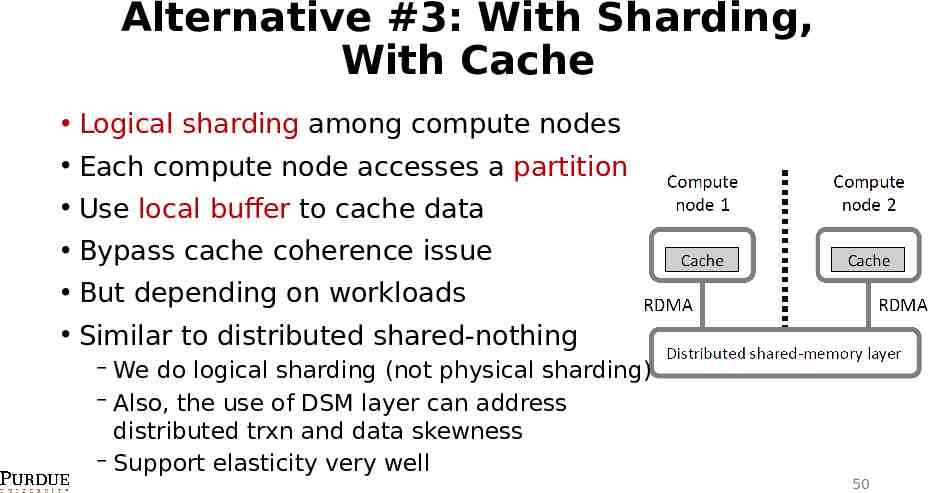
Alternative #3: With Sharding, With Cache Logical sharding among compute nodes Each compute node accesses a partition Use local buffer to cache data Bypass cache coherence issue But depending on workloads Similar to distributed shared-nothing We do logical sharding (not physical sharding) Also, the use of DSM layer can address distributed trxn and data skewness Support elasticity very well 50






