Programming Support and Resource Management for Cluster-based Internet




























51 Slides898.50 KB
Programming Support and Resource Management for Cluster-based Internet Services Hong Tang Department of Computer Science University of California, Santa Barbara
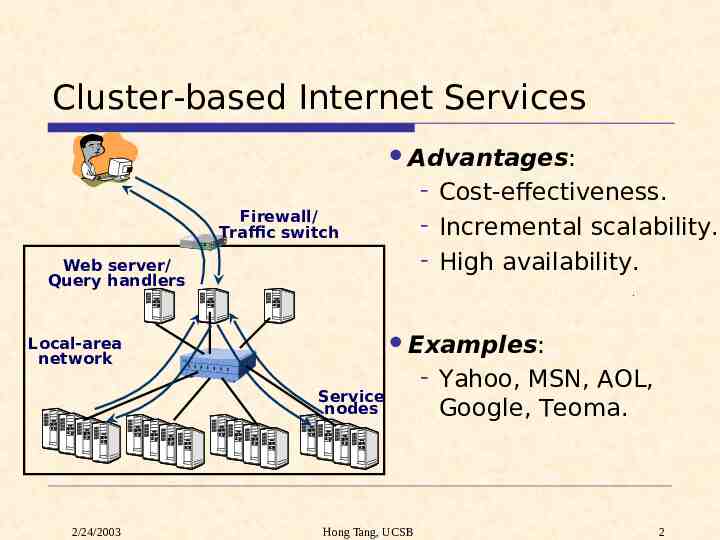
Cluster-based Internet Services Advantages: - Cost-effectiveness. - Incremental scalability. - High availability. Firewall/ Traffic switch Web server/ Query handlers Examples: Local-area network Service nodes 2/24/2003 Hong Tang, UCSB - Yahoo, MSN, AOL, Google, Teoma. 2
Challenges Hardware failures and configuration errors due to a large number of components. Platform heterogeneity due to irregularity in hardware, networking, data partitions. Serving highly concurrent and fluctuating traffic under interactive response constraint. 2/24/2003 Hong Tang, UCSB 3
Neptune: Programming and Runtime Support for Cluster-based Internet Services Programming support: - Component-oriented style allows programers to focus on application functionality. - Neptune API provides high-level primitives for service programming. Runtime support: - Neptune runtime glues components together and takes care of reliability and scalability issues. Applications: - Discussion groups; online auctions; index search; persistent cache utility; BLAST-based protein sequence match. Industrial Deployment: Teoma/AskJeeves. 2/24/2003 Hong Tang, UCSB 4
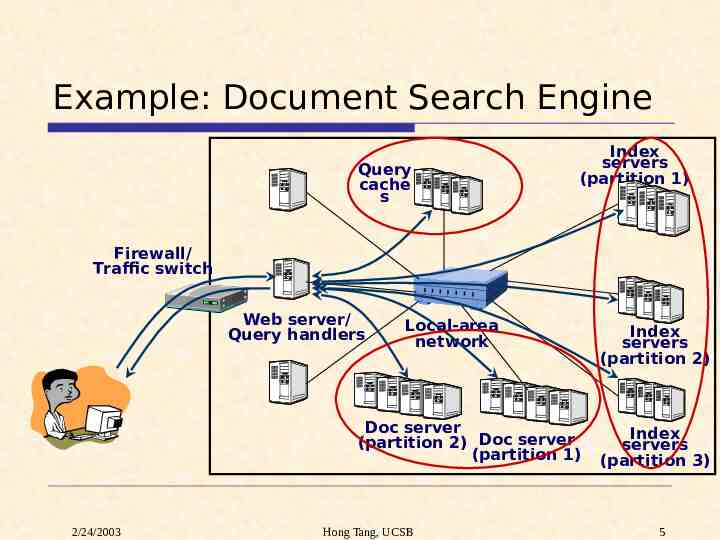
Example: Document Search Engine Query cache s Index servers (partition 1) Firewall/ Traffic switch Web server/ Query handlers Local-area network Doc server (partition 2) Doc server (partition 1) 2/24/2003 Hong Tang, UCSB Index servers (partition 2) Index servers (partition 3) 5
Outline Cluster-based Internet services: Background and challenges. Programming support for data aggregation operations. Integrated resource management and QoS support. Future work. 2/24/2003 Hong Tang, UCSB 6
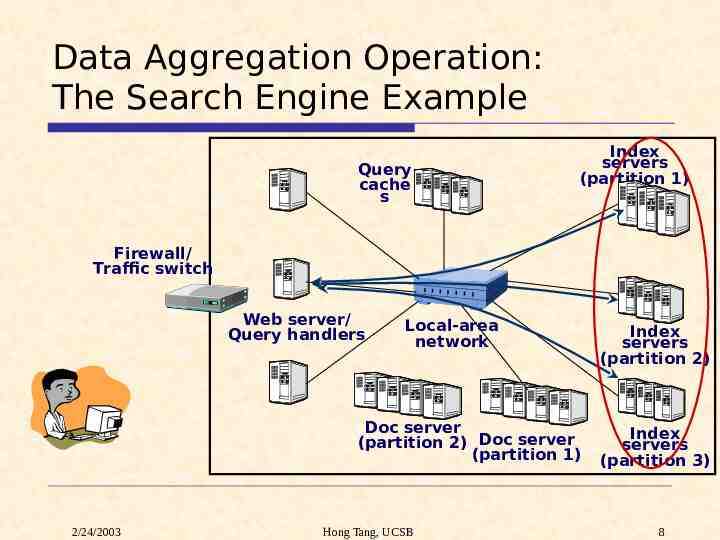
Data Aggregation Operation Aggregate request processing results from multiple data partitions. Examples: search engine, discussing groups, Naïve approach: - Rely on a fixed server for data collection and aggregation. - The fixed server is a scalability bottleneck. - Actually used in TACC framework ([Fox97]) and previous version of Neptune system. Need explicit programming support and efficient runtime system design! 2/24/2003 Hong Tang, UCSB 7
Data Aggregation Operation: The Search Engine Example Query cache s Index servers (partition 1) Firewall/ Traffic switch Web server/ Query handlers Local-area network Doc server (partition 2) Doc server (partition 1) 2/24/2003 Hong Tang, UCSB Index servers (partition 2) Index servers (partition 3) 8
Data Aggregation Operation Aggregate request processing results from multiple data partitions. Examples: search engine, discussion groups, Naïve approach: - Rely on a fixed server for data collection and aggregation. - The fixed server is a scalability bottleneck. - Actually used in TACC framework ([Fox97]) and previous version of Neptune system. Need explicit programming support and efficient runtime system design! 2/24/2003 Hong Tang, UCSB 9
Design Objectives An easy-to-use programming primitive. Scalable to a large number of partitions. Interactive responses and high throughput. Reminder: All must be achieved in a cluster environment! - Component failures. - Platform heterogeneity. 2/24/2003 Hong Tang, UCSB 10
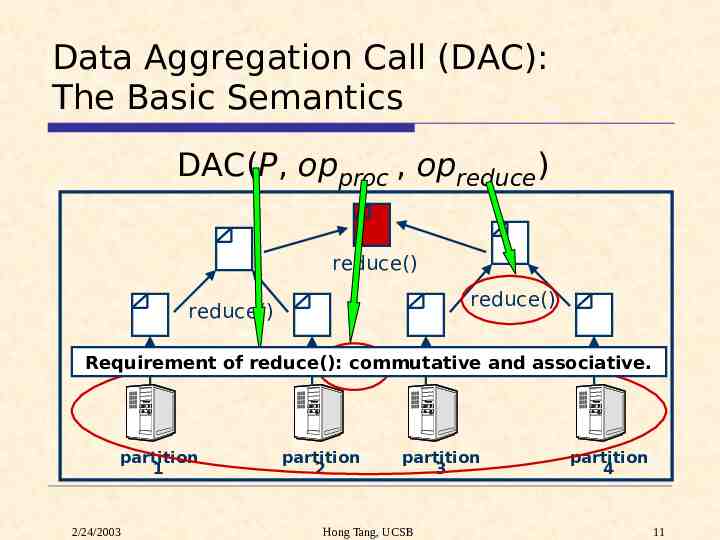
Data Aggregation Call (DAC): The Basic Semantics DAC(P, opproc , opreduce) reduce() reduce() reduce() Requirement commutative proc() of reduce(): proc() proc()and associative. proc() partition 1 2/24/2003 partition 2 partition 3 Hong Tang, UCSB partition 4 11
Adding Quality Control to DAC What if some server fails? - Partial aggregation results may still be useful. - Provide aggregation quality guarantee . - Aggregation quality: Percentage of partitions contributed to the aggregation result. What if some server is very slow? - Better return partial results than waiting. - Provide soft deadline guarantee . DAC(P, opproc , opreduce ,q, T) 2/24/2003 Hong Tang, UCSB 12
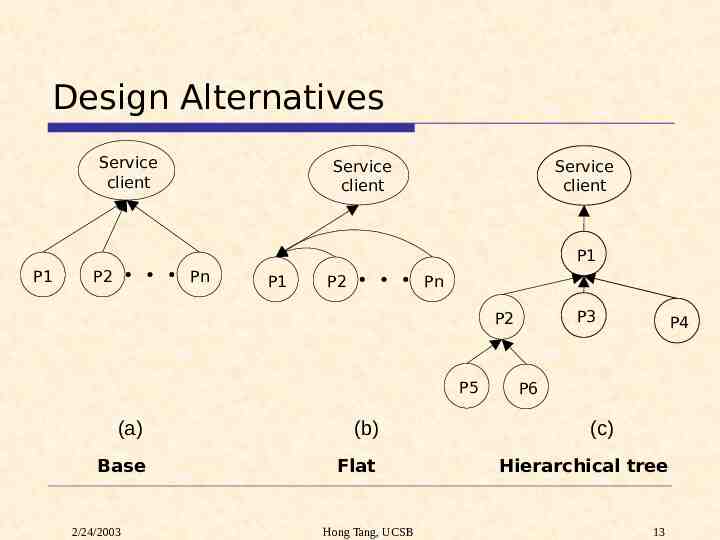
Design Alternatives Service client Service client Service client P1 P1 P2 Pn P1 P2 Pn P3 P2 P5 (a) (b) Base Flat 2/24/2003 Hong Tang, UCSB P4 P6 (c) Hierarchical tree 13
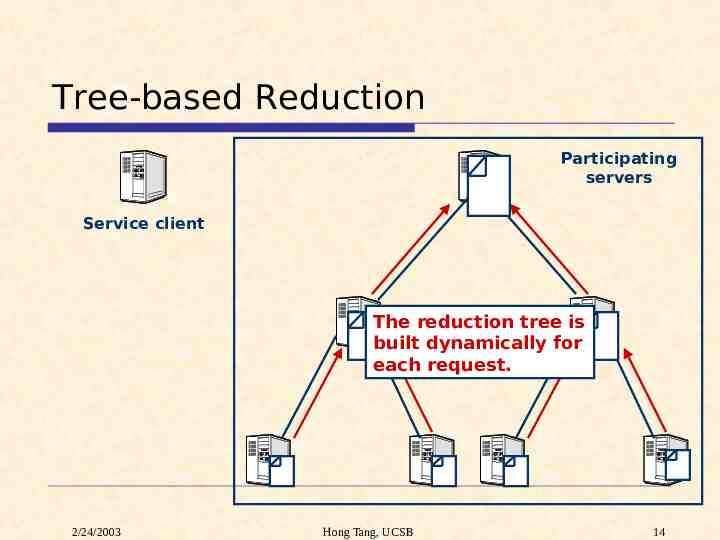
Tree-based Reduction Participating servers Service client The reduction tree is built dynamically for each request. 2/24/2003 Hong Tang, UCSB 14
Building Dynamic Reduction Trees Objective: - High throughput and low response time. Achieving high throughput: - Balance load, keep all servers busy. Achieving low response time? 2/24/2003 Hong Tang, UCSB 15
Building Dynamic Reduction Trees 2/24/2003 Hong Tang, UCSB 16
Building Dynamic Reduction Trees Objective: - High throughput and low response time. Achieving high throughput: - Balance load, keep all servers busy. Achieving low response time: - Reducing the longest queue length. - Queue length indicates server load. - Balance load! Observation: Under highly concurrent workload, the goals of reducing response time and improving throughput require us to balance load! Decisions: Tree shape server assignment. 2/24/2003 Hong Tang, UCSB 17
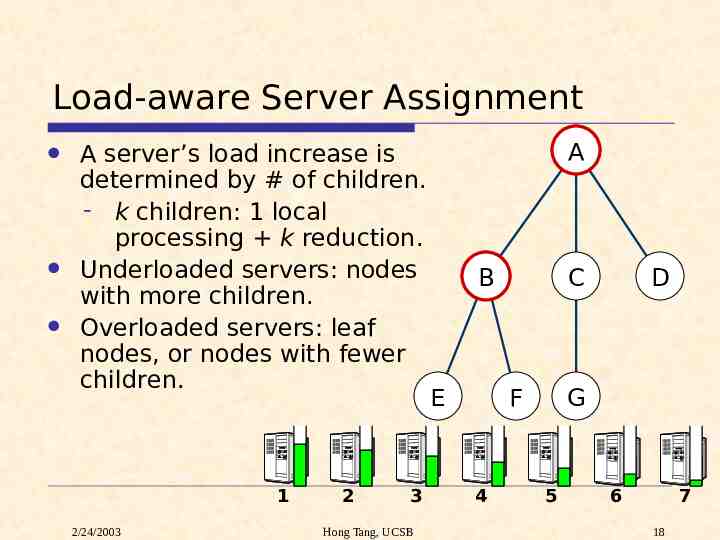
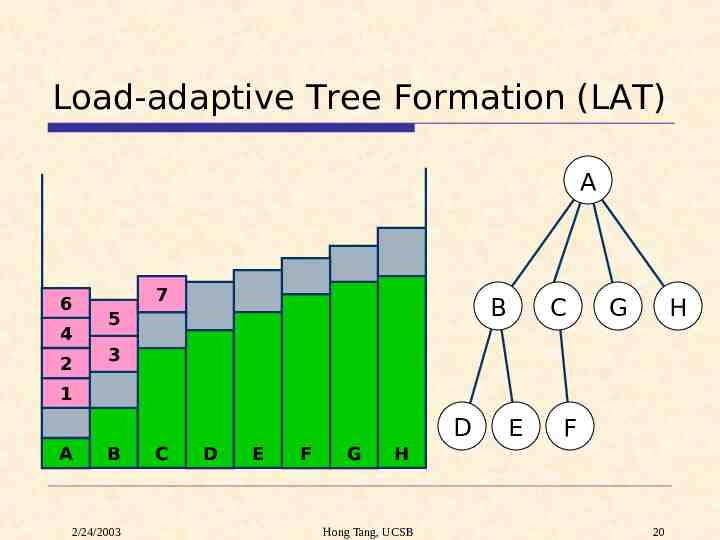
Load-aware Server Assignment A server’s load increase is determined by # of children. - k children: 1 local processing k reduction. Underloaded servers: nodes with more children. Overloaded servers: leaf nodes, or nodes with fewer children. 1 2/24/2003 2 3 Hong Tang, UCSB A B E C F 4 D G 5 6 7 18
Choosing Reduction Tree Shapes Static tree shapes: Balanced d-ary tree; binomial tree. Problem: Not sufficient to correct load imbalance caused by platform heterogeneity in a cluster environment. 2/24/2003 Hong Tang, UCSB 19
Load-adaptive Tree Formation (LAT) A 6 4 2 7 B 5 C G H 3 1 D A B 2/24/2003 C D E F G E F H Hong Tang, UCSB 20
LAT Adjustment Problem: When all servers have similar load, LAT will assign one reduction operation per server, resulting in a link list. Solution: Final adjustment ensures the depth is no more than logN. If a subtree is in the form of a link list, change it to a binomial tree. 2/24/2003 Hong Tang, UCSB 21
LAT Summary Steps: 1. Collecting server load information. 2. Assigning operations to servers. 3. Constructing the reduction tree. 4. Adjusting the tree shape. Time complexity: O(nlogn). 2/24/2003 Hong Tang, UCSB 22
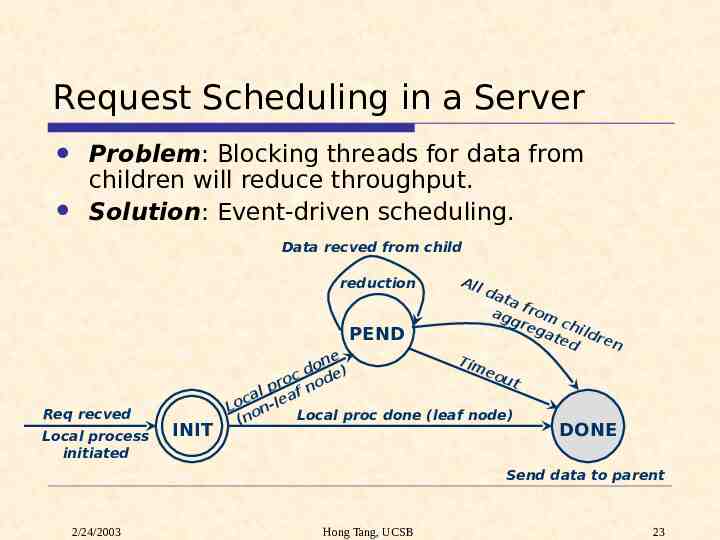
Request Scheduling in a Server Problem: Blocking threads for data from children will reduce throughput. Solution: Event-driven scheduling. Data recved from child reduction PEND Req recved Local process initiated INIT All da ta ag from g re c ga hild ted ren Tim eo ut e on ) d oc od e r p n al eaf c l Lo onLocal proc done (leaf node) (n DONE Send data to parent 2/24/2003 Hong Tang, UCSB 23
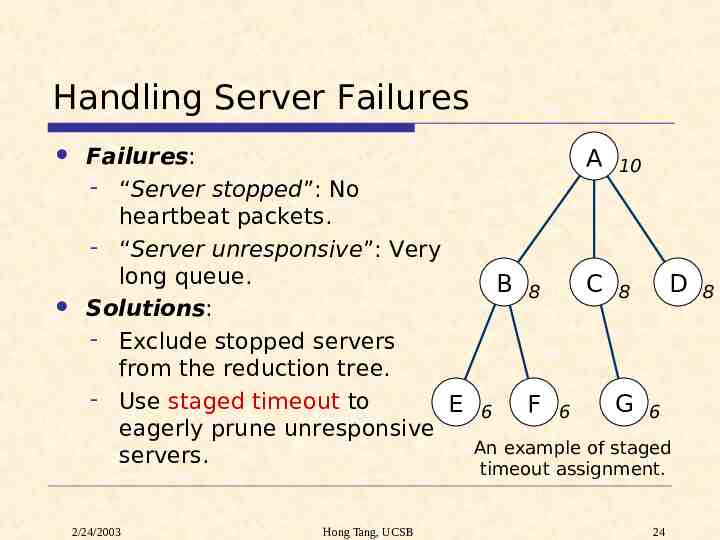
Handling Server Failures Failures: - “Server stopped”: No heartbeat packets. - “Server unresponsive”: Very long queue. Solutions: - Exclude stopped servers from the reduction tree. - Use staged timeout to E eagerly prune unresponsive servers. 2/24/2003 Hong Tang, UCSB B 6 8 F 6 A 10 C 8 G D 6 An example of staged timeout assignment. 24 8
Evaluation Settings A cluster of Linux servers (kernel ver. 2.4.18): - 30 dual-CPU (400MHz P-II), 512MB MEM; 4 quad-CPU (500MHz P-II), 1GB MEM. Benchmark I: Search engine index server. - Dataset: 28 partitions, 1-1.2GB each. - Workload: Trace-driven. - One week trace from Ask Jeeves. - Contains only uncached queries. Benchmark II: CPU-spinning microbenchmark. - Workload: Synthetic. 2/24/2003 Hong Tang, UCSB 25
Ease of Use Applications: Index server; NCBI’s BLAST protein sequence matcher; online facial recognizer. First implemented without DAC. A graduate student modified it with DAC. Services Code Size (lines) Index 2384 BLAST 1060K Face 4306 2/24/2003 Changed Lines 142 (5.9%) Effort (days) 1.5 307 (0.03%) 2 190 (4.4%) 1 Hong Tang, UCSB 26
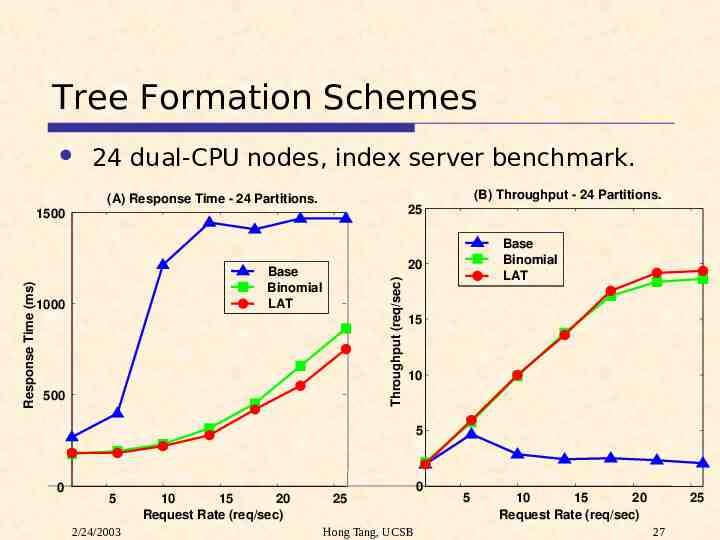
Tree Formation Schemes 24 dual-CPU nodes, index server benchmark. (B) Throughput - 24 Partitions. (A) Response Time - 24 Partitions. 25 1000 Base Binomial LAT 20 Base Binomial LAT Throughput (req/sec) Response Time (ms) 1500 500 15 10 5 0 5 2/24/2003 10 15 20 Request Rate (req/sec) 25 Hong Tang, UCSB 0 5 10 15 20 Request Rate (req/sec) 25 27
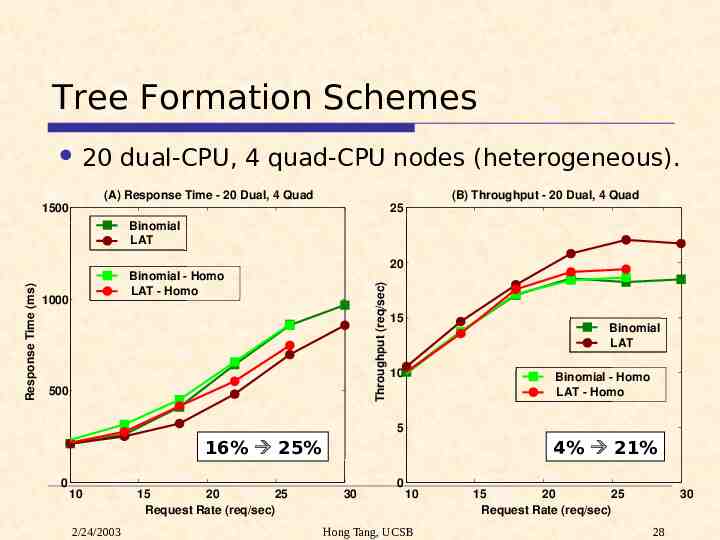
Tree Formation Schemes 20 dual-CPU, 4 quad-CPU nodes (heterogeneous). (A) Response Time - 20 Dual, 4 Quad (B) Throughput - 20 Dual, 4 Quad 1500 25 Binomial LAT Binomial - Homo LAT - Homo 1000 Throughput (req/sec) Response Time (ms) 20 500 15 Binomial LAT 10 Binomial - Homo LAT - Homo 5 16% 25% 0 10 2/24/2003 15 20 25 Request Rate (req/sec) 4% 21% 30 0 10 Hong Tang, UCSB 15 20 25 Request Rate (req/sec) 30 28
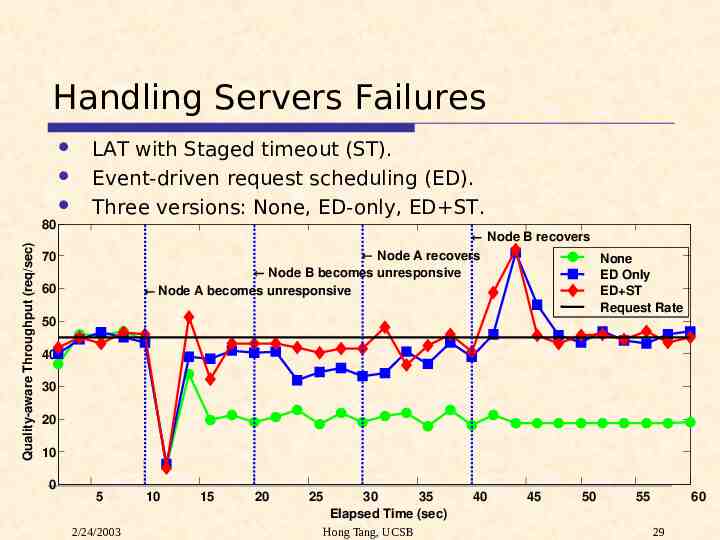
Handling Servers Failures Quality-aware Throughput (req/sec) 80 LAT with Staged timeout (ST). Event-driven request scheduling (ED). Three versions: None, ED-only, ED ST. Node B recovers Node A recovers 70 None ED Only ED ST Request Rate Node B becomes unresponsive 60 Node A becomes unresponsive 50 40 30 20 10 0 5 2/24/2003 10 15 20 25 30 35 Elapsed Time (sec) Hong Tang, UCSB 40 45 50 55 60 29
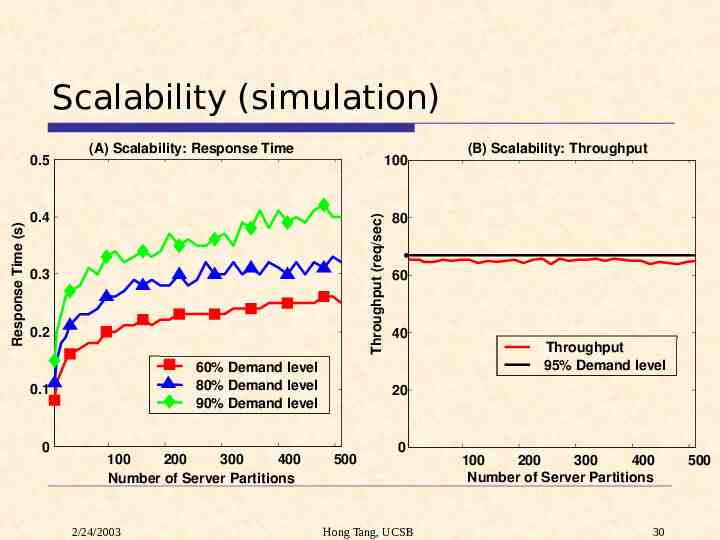
Scalability (simulation) (A) Scalability: Response Time 100 0.4 Throughput (req/sec) Response Time (s) 0.5 0.3 0.2 60% Demand level 80% Demand level 90% Demand level 0.1 0 100 200 300 400 Number of Server Partitions 2/24/2003 (B) Scalability: Throughput 80 60 40 Throughput 95% Demand level 20 500 0 Hong Tang, UCSB 100 200 300 400 Number of Server Partitions 30 500
Summary Programming support: - DAC primitive. Runtime system: - LAT tree formation. - Event-driven scheduling. - Staged timeout. [PPoPP’03]. 2/24/2003 Hong Tang, UCSB 31
Outline Cluster-based Internet services: background and challenges. Programming support for data aggregation operations. Integrated resource management and QoS support. Future work. 2/24/2003 Hong Tang, UCSB 32
Research Objectives Service-specific resource management objectives. - Previous research: Rely on concrete metrics to measure resource management efficiency. - Observation: Different services may have different objectives. - Statement: Resource management objectives should not be built into the runtime system. Differentiated services qualities for multiple request classes (QoS). - Internet traffic is bursty – 3:1 peak-to-average load ratio reported at Ask Jeeves. - Prioritized resource allocation is desirable. 2/24/2003 Hong Tang, UCSB 33
Service Yield Function Service yield: The benefit achieved from serving a request. A monotonically non-increasing function of response time. Service yield function Y(r) : Specified by service providers. Optimization goal: Maximize aggregate yield Yi (ri .) i 2/24/2003 Hong Tang, UCSB 34
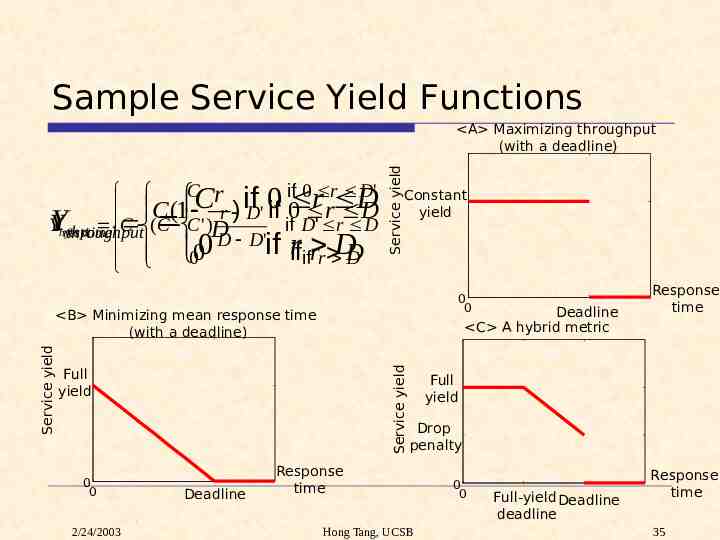
Sample Service Yield Functions C r if 0 r D ' C if 0 rr C (1 r ) D' if 0 D D Yhybrid Y Y C ( C C ' ) if D ' r D D resptime throughput 00 D D'if if rifr r DDD 0 Service yield A Maximizing throughput (with a deadline) Constant yield 0 0 Deadline C A hybrid metric Service yield Service yield B Minimizing mean response time (with a deadline) Full yield 0 0 2/24/2003 Deadline Response time Full yield Drop penalty Response time Hong Tang, UCSB 0 0 Full-yield Deadline deadline Response time 35
Service Differentiation Service class: A category of service requests that enjoy the same level of QoS support. - Client identity (paid vs unpaid membership). - Service types (order placement vs catalog browsing). Provision: - Differentiated service yield functions. - Proportional resource allocation guarantee. 2/24/2003 Hong Tang, UCSB 36
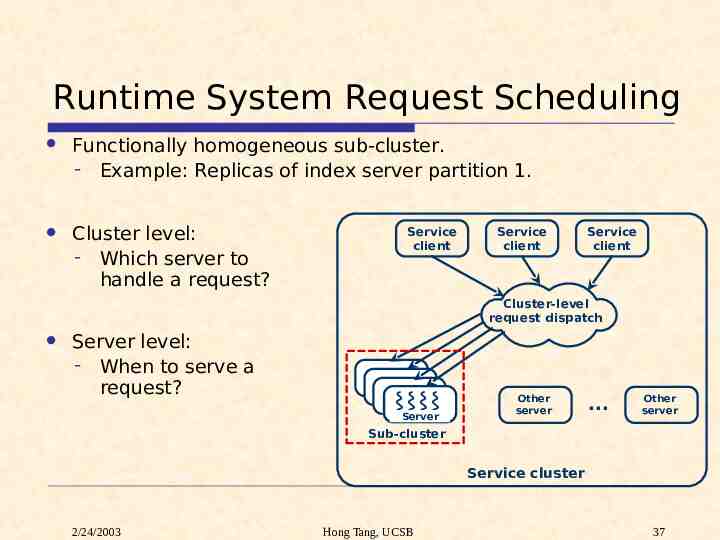
Runtime System Request Scheduling Functionally homogeneous sub-cluster. - Example: Replicas of index server partition 1. Cluster level: - Which server to handle a request? Service client Service client Service client Cluster-level request dispatch Server level: - When to serve a request? Server Server Server Server Other server . Other server Sub-cluster Service cluster 2/24/2003 Hong Tang, UCSB 37
Cluster Level: Partitioning or Not? Periodic server partitioning [Infocom’01]. - Partition the sub-cluster among service classes. Periodically adjust server pool sizes based on request demand of the service classes. Problems: - Decisions are made by a centralized dispatcher. - Periodical adjustment means slow response to demand changes. This work: “Random polling”. - Service differentiation at the server level. Functional-symmetry and decentralization. Better handling of demand spikes and failures. 2/24/2003 Hong Tang, UCSB 38
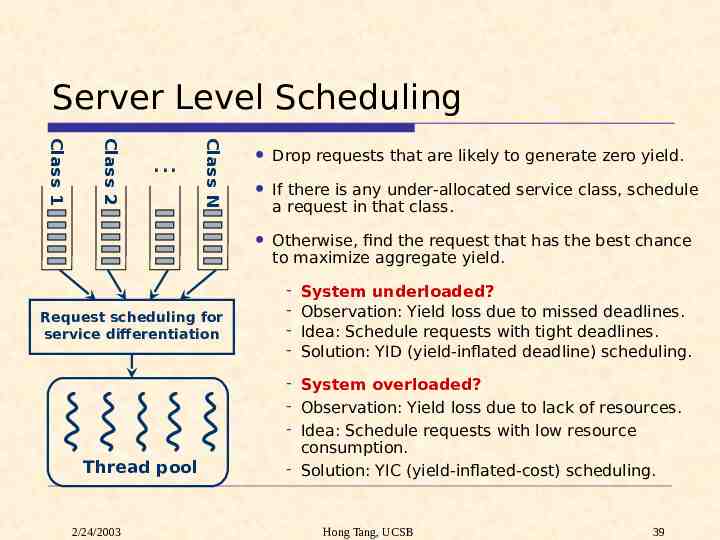
Server Level Scheduling Class N Class 2 Class 1 . Drop requests that are likely to generate zero yield. If there is any under-allocated service class, schedule a request in that class. Otherwise, find the request that has the best chance to maximize aggregate yield. Request scheduling for service differentiation Thread pool 2/24/2003 - System underloaded? Observation: Yield loss due to missed deadlines. Idea: Schedule requests with tight deadlines. Solution: YID (yield-inflated deadline) scheduling. - System overloaded? - Observation: Yield loss due to lack of resources. - Idea: Schedule requests with low resource consumption. - Solution: YIC (yield-inflated-cost) scheduling. Hong Tang, UCSB 39
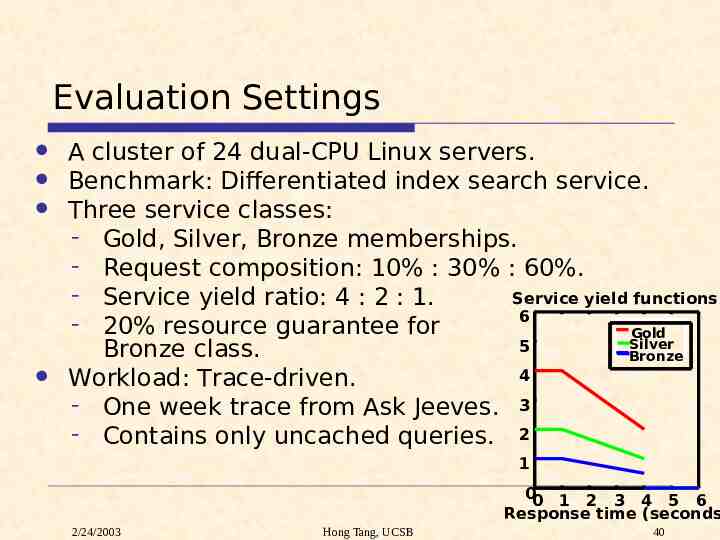
Evaluation Settings A cluster of 24 dual-CPU Linux servers. Benchmark: Differentiated index search service. Three service classes: - Gold, Silver, Bronze memberships. - Request composition: 10% : 30% : 60%. - Service yield ratio: 4 : 2 : 1. Service yield functions 6 - 20% resource guarantee for Gold Silver 5 Bronze class. Bronze 4 Workload: Trace-driven. - One week trace from Ask Jeeves. 3 - Contains only uncached queries. 2 1 00 1 2 3 4 5 6 Response time (seconds 2/24/2003 Hong Tang, UCSB 40
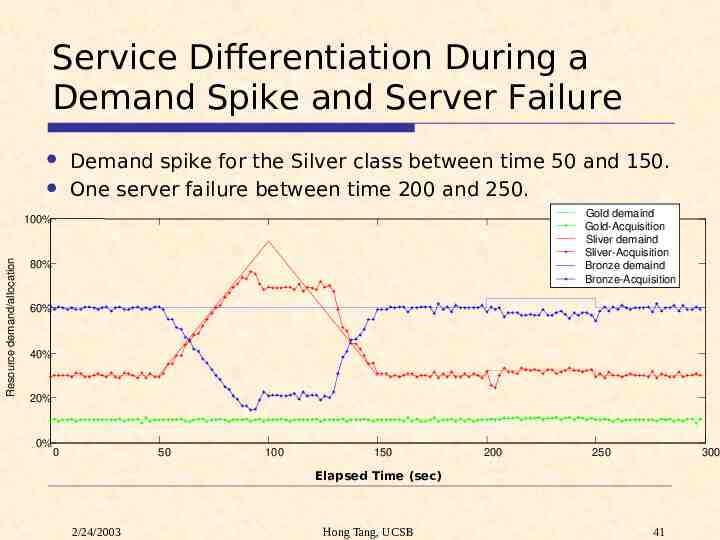
Service Differentiation During a Demand Spike and Server Failure Demand spike for the Silver class between time 50 and 150. One server failure between time 200 and 250. Gold demaind Gold-Acquisition Sliver demaind Sliver-Acquisition Bronze demaind Bronze-Acquisition Resource demand/allocation 100% 80% 60% 40% 20% 0% 0 50 100 150 200 250 300 Elapsed Time (sec) 2/24/2003 Hong Tang, UCSB 41
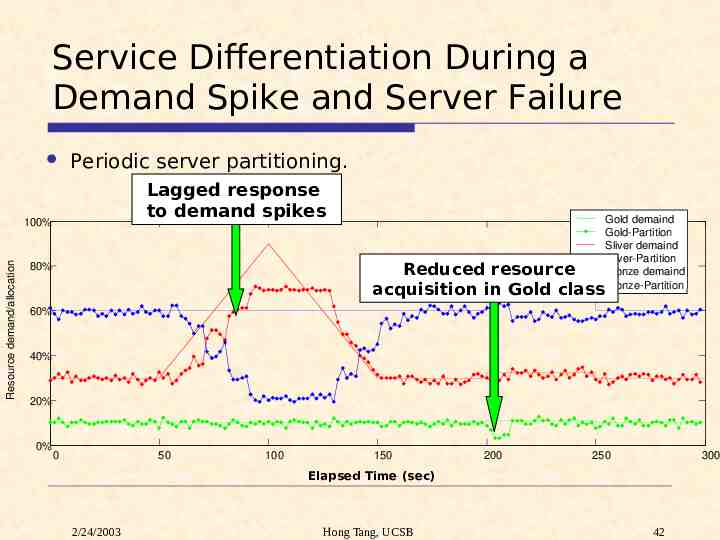
Service Differentiation During a Demand Spike and Server Failure Periodic server partitioning. Lagged response to demand spikes Resource demand/allocation 100% Gold demaind Gold-Partition Sliver demaind Sliver-Partition Bronze demaind Bronze-Partition Reduced resource acquisition in Gold class 80% 60% 40% 20% 0% 0 50 100 150 200 250 300 Elapsed Time (sec) 2/24/2003 Hong Tang, UCSB 42
Summary Service yield function. - As a mechanism to express resource management objectives. - As a means to differentiate service qualities. Two-level decentralized request scheduling. - Cluster level: Random polling. - Server level: Adaptive scheduling. [OSDI’02]. 2/24/2003 Hong Tang, UCSB 43
Related Work Programming support for cluster-based Internet services – TACC [Fox97], MultiSpace [Gribble99], Ninja [von Behren02]. Event-driven request processing – Flash [Pai99], SEDA [Welsh01]. Tree-based reduction in MPI – [Gropp96], MagPIe [Kielmann99], TMPI [Tang01]. Data aggregation – Aggregation queries for databases [Saito99, Madden02], Scientific application [Chang01]. QoS for computer networks – Weighted Fair Queuing [Demers90; Parekh93], Leaky Bucket, LIRA [Stoica98], [Dovrolis99]. QoS or real-time scheduling at the single host level – [Huang89], [Haritsa93], [Waldspurger94], [Mogul96], LRP [Druschel96], [Jones97], Eclipse [Bruno98], Resource Container [Banga99], [Steere99]. QoS and resource management for Web servers – [Almeida98], [Pandey98], [Abdelzaher99], [Bhatti99], [Chandra00], [Li00], [Voigt01]. QoS and load balancing for Internet services – LARD [Pai98], Cluster Reserves [Aron00], [Sullivan00], DDSD [Zhu01], [Chase01], [Goswami93], [Mitzenmacher97], [Zhou87]. 2/24/2003 Hong Tang, UCSB 44
Outline Cluster-based Internet services: background and challenges. Programming support for data aggregation operations. Integrated resource management and QoS support. Future work. 2/24/2003 Hong Tang, UCSB 45
Self-organizing Storage Cluster Challenge: Distributed storage resources are hard to manage and utilize. - Fragmented storage space. - Frequent disk failures. Objective: Let the cluster manage storage resources by itself. - Storage virtualization. - Incrementally scalable. - Automatic redundancy maintenance. 2/24/2003 Hong Tang, UCSB 46
Dynamic Service Composition Challenge: Internet services are evolving rapidly. - More functionality requires more service components. - Reusing existing service components. Objective: Programming and runtime support for dynamic service composition. - Easy to use composition mechanisms. - On-the-fly service reconfiguration. 2/24/2003 Hong Tang, UCSB 47
Q&A Acknowledgement: Tao Yang, Lingkun Chu – UCSB Kai Shen – University of Rochester Project Web Site: http:// www.cs.ucsb.edu/projects/neptune/ Personal home page: http://www.cs.ucsb.edu/ htang/ 2/24/2003 Hong Tang, UCSB 48
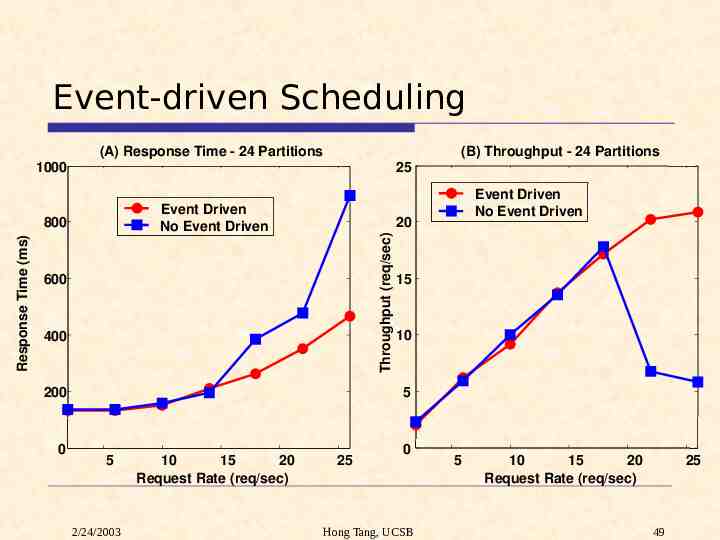
Event-driven Scheduling (B) Throughput - 24 Partitions (A) Response Time - 24 Partitions 25 1000 Event Driven No Event Driven 20 Throughput (req/sec) Response Time (ms) 800 600 400 15 10 5 200 0 Event Driven No Event Driven 5 2/24/2003 10 15 20 Request Rate (req/sec) 25 0 Hong Tang, UCSB 5 10 15 20 Request Rate (req/sec) 25 49
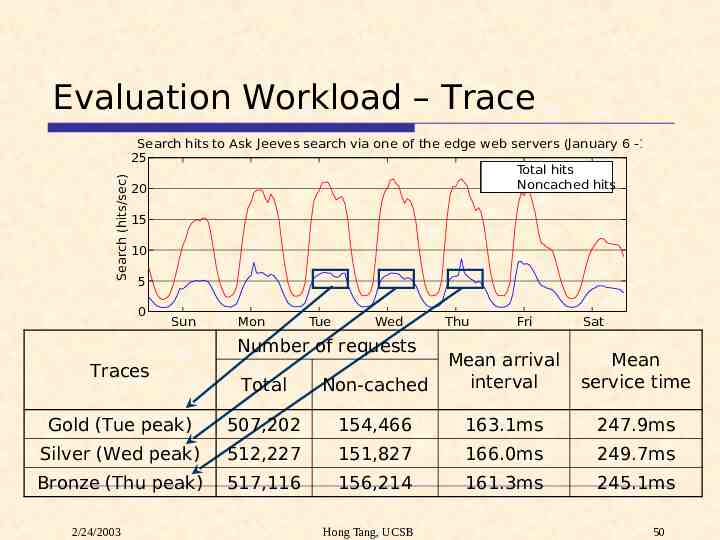
Search (hits/sec) Evaluation Workload – Trace Search hits to Ask Jeeves search via one of the edge web servers (January 6 -12, 2002) 25 Total hits Noncached hits 20 15 10 5 0 Sun Mon Tue Wed Number of requests Thu Fri Sat Total Non-cached Mean arrival interval Gold (Tue peak) 507,202 154,466 163.1ms 247.9ms Silver (Wed peak) 512,227 151,827 166.0ms 249.7ms Bronze (Thu peak) 517,116 156,214 161.3ms 245.1ms Traces 2/24/2003 Hong Tang, UCSB Mean service time 50
Compare MPI Reduce and DAC Primitive semantic s Runtime system design 2/24/2003 MPI Reduce DAC Tolerate failures All or nothing Allow partial results Deadline requirement No Yes Programming Proceduremodel based Requestdriven Tree shape Static Dynamic Server assignment Static Dynamic Hong Tang, UCSB 51






