Problem-solving using MapReduce/Hadoop B. RAMAMURTHY THIS IS WORK IS





















22 Slides231.12 KB
Problem-solving using MapReduce/Hadoop B. RAMAMURTHY THIS IS WORK IS SUPPORTED BY NSF G R A N T N S F - D U E -T U E S - 0 9 2 0 3 3 5 ( P H A S E 2 ) & N S F- A C I - 1 0 4 1 2 8 0
Topics for Discussion Problem solving approaches for big-data Origins of MR/Hadoop Algorithms, data structures and infrastructures Hello “Wordcount” Wordcount mapreduce version MapReduce Hadoop Linked structures PageRank mapreduce version Infrastructure Local: Single node hadoop Local: CCR cluster Amazon aws cloud MR/Hadoop infrastructure Google appEngine Mapreduce
Big-data Problem Solving Approaches Algorithmic: after all we have working towards this for ever: scalable/tractable High Performance computing (HPC: multi-core) CCR has machines that are: 16 CPU , 32 core machine with 128GB RAM. GPGPU programming: general purpose graphics processor (NVIDIA) Statistical packages like R running on parallel threads on powerful machines Machine learning algorithms on super computers
Different Type of Storage Internet introduced a new challenge in the form web logs, web crawler’s data: large scale “peta scale” But observe that this type of data has an uniquely different characteristic than your transactional or the “customer order” data, or “bank account data” : The data type is “write once read many (WORM)” ; Privacy protected healthcare and patient information; Historical financial data; Other historical data Relational file system and tables are insufficient. Large key, value stores (files) and storage management system. Built-in features for fault-tolerance, load balancing, data-transfer and aggregation, Clusters of distributed nodes for storage and computing. Computing is inherently parallel 01/29/2023 4
MR-data Concepts Originated from the Google File System (GFS) is the special key, value store Hadoop Distributed file system (HDFS) is the open source version of this. (Currently an Apache project) Parallel processing of the data using MapReduce (MR) programming model Challenges Formulation of MR algorithms Proper use of the features of infrastructure (Ex: sort) Best practices in using MR and HDFS An extensive ecosystem consisting of other components such as column-based store (Hbase, BigTable), big data warehousing (Hive), workflow languages, etc. 01/29/2023 5
Hadoop-MapReduce MapReduce like algorithms on Hadoop-like infrastructures: typically batch processing Distributed parallelism among commodity machines WORM key, value pairs Challenges Formulation of MR algorithms Proper use of the features of infrastructure (Ex: sort) Best practices in using MR and HDFS
MapReduce Design 7 You focus on Map function, Reduce function and other related functions like combiner etc. Mapper and Reducer are designed as classes and the function defined as a method. Configure the MR “Job” for location of these functions, location of input and output (paths within the local server), scale or size of the cluster in terms of #maps, # reduce etc., run the job. Thus a complete MapReduce job consists of code for the mapper, reducer, combiner, and partitioner, along with job configuration parameters. The execution framework handles everything else. CSE4/587 01/29/2023
The code 8 1: 2: 3: 4: class Mapper method Map(docid a; doc d) for all term t in doc d do Emit(term t; count 1) 1: 2: 3: 4: 5: 6: class Reducer method Reduce(term t; counts [c1; c2; : : :]) sum 0 for all count c in counts [c1; c2; : : :] do sum sum c Emit(term t; count sum) CSE4/587 01/29/2023
MapReduce Example: Mapper with Combiner 9 This is a cat Cat sits on a roof this 1 is 1 a 1,1, cat 1,1 sits 1 on 1 roof 1 The roof is a tin roof There is a tin can on the roof the 1,1 roof 1,1,1 is 1,1 a 1,1 tin 1,1 then 1 can 1 on 1 Cat kicks the can It rolls on the roof and falls on the next roof cat 1 kicks 1 the 1,1 can 1 it 1 roll 1 on 1,1 roof 1,1 and 1 falls 1 next 1 The cat rolls too It sits on the can the 1,1 cat 1 rolls 1 too 1 it 1 sits 1 on 1 cat 1 CSE4/587 01/29/2023
MapReduce Example: Combiner, Reducer, Shuffle, Sort 10 this 1 is 1 a 1,1, cat 1,1 sits 1 on 1 roof 1 the 1,1 roof 1,1,1 is 1,1 a 1,1 tin 1,1 then 1 can 1 on 1 cat 1 kicks 1 the 1,1 can 1 it 1 roll 1 on 1,1 roof 1,1 and 1 falls 1 next 1 the 1,1 cat 1 rolls 1 too 1 it 1 sits 1 on 1 cat 1 Input to the reducers: cat 1,1,1,1 roof 1,1,1,1,1,1 can 1, 1,1 Reduce (sum in this case) the counts: Can use non-traditional methods for summing cat 4 can 3 roof 6 CSE4/587 01/29/2023
More on MR 11 All Mappers work in parallel. Barriers enforce all mappers completion before Reducers start. Mappers and Reducers typically execute on the same server You can configure job to have other combinations besides Mapper/Reducer: ex: identify mappers/reducers for realizing “sort” (that happens to be a benchmark) Mappers and reducers can have side effects; this allows for sharing information between iterations. CSE4/587 01/29/2023
Classes of problems “mapreducable” 12 Benchmark for comparing: Jim Gray’s challenge on data- intensive computing. Ex: “Sort” Google uses it (we think) for wordcount, adwords, pagerank, indexing data. Simple algorithms such as grep, text-indexing, reverse indexing Bayesian classification: data mining domain Facebook uses it for various operations: demographics Financial services use it for analytics Astronomy: Gaussian analysis for locating extra-terrestrial objects. Expected to play a critical role in semantic web and web3.0 Probably many classical math problems. CCSCNE 2009 Plattsburg, April 24 2009 B.Ramamurthy & K.Madurai
Page Rank
General idea Consider the world wide web with all its links. Now imagine a random web surfer who visits a page and clicks a link on the page Repeats this to infinity Pagerank is a measure of how frequently will a page will be encountered. In other words it is a probability distribution over nodes in the graph representing the likelihood that a random walk over the linked structure will arrive at a particular node.
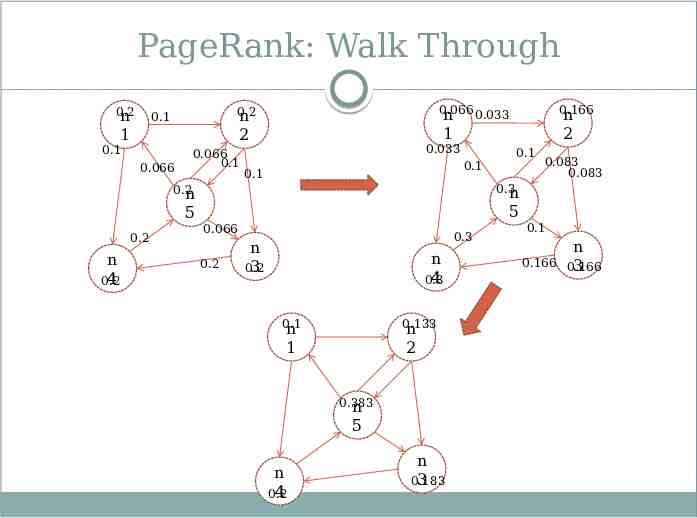
PageRank Formula P(n) α randomness factor G is the total number of nodes in the graph L(n) is all the pages that link to n C(m) is the number of outgoing links of the page m Note that PageRank is recursively defined. It is implemented by iterative MRs. Lets assume α is zero for a simple walk through.
PageRank: Walk Through 0.2 n 0.066 n 0.033 0.2 n 0.1 1 1 2 0.1 0.066 0.066 0.1 2 0.033 0.1 0.1 0.2 n 4 0.2 0.1 0.083 0.083 0.3 n 0.2 n 5 0.166 n 5 0.066 0.2 0.3 n 0.2 3 n 4 0.3 0.1 n 0.133 n 1 2 0.383 n 5 n 4 0.2 n 0.183 3 0.1 0.166 n 0.166 3
Mapper for PageRank Class Mapper method map (nid, Node N) p N.Pagerank/ N.Adajacency emit(nid, N) for all m in N. Adjacencylist emit(nid m, p) “divider”
Reducer for Pagerank Class Reducer method Reduce(nid m, [p1, p2, p3.]) Node M null; s 0; for all p in [p1,p2, .] { if p is a Node then M p else s s p} M.pagerank s emit (nid m, Node M) “aggregator” At the reducer you get two types of items in the list.
Issues; Points to ponder How to account for dangling nodes: one that has many incoming links and no outgoing links Simply redistributes its pagerank to all One iteration requires pagerank computation redistribution of “unused” pagerank Pagerank is iterated until convergence: when is convergence reached? Probability distribution over a large network means underflow of the value of pagerank. Use log based computation MR: How do PRAM algs. translate to MR? how about math algorithms?
Demos Single node: Eclipse Helios, Hadoop (MR)0.2, Hadoop-eclipse plug-in Amazon Elastic cloud computing aws.amazon.com CCR: Video of 100-node cluster for processing a billion node k-nary tree
References Dean, J. and Ghemawat, S. 2008. MapReduce: simplified data processing on large clusters. Communication of ACM 51, 1 (Jan. 2008), 107-113. 2. Lin and Dyer (2010): Data-intensive text processing with MapReduce; http:// beowulf.csail.mit.edu/18.337-2012/MapReduce-book-final.pd f 3. Cloudera Videos by Aaron Kimball: http://www.cloudera.com/hadoop-training-basic 4. Apache Hadoop Tutorial: http://hadoop.apache.org http://hadoop.apache.org/core/docs/current/mapred tutorial. html 1.
Take Home Messages MapReduce (MR) algorithm is for distributed processing of big-data Apache Hadoop (open source) provides the distributed infrastructure for MR Most challenging aspect is designing the MR algorithm for solving a problem; it is different mind-set; Visualizing data as key,value pairs; distributed parallel processing; Probably beautiful MR solutions can be designed for classical Math problems. It is not just mapper and reducer, but also other operations such as combiner, partitioner that have be cleverly used for solving large scale problems.






