Performance evaluation of Java for numerical computing Roldan Pozo
































44 Slides494.00 KB
Performance evaluation of Java for numerical computing Roldan Pozo Leader, Mathematical Software Group National Institute of Standards and Technology
Background: Where we are coming from. National Institute of Standards and Technology – US Department of Commerce – NIST (3,000 employees, mainly scientists and engineers) middle to large-scale simulation modeling mainly Fortran , C/C applications utilize many tools: Matlab, Mathematica, Tcl/Tk, Perl, GAUSS, etc. typical arsenal: IBM SP2, SGI/ Alpha/PC clusters
Mathematical & Computational Sciences Division Algorithms for simulation and modeling High performance computational linear algebra Numerical solution of PDEs Multigrid and hierarchical methods Numerical Optimization Special Functions Monte Carlo simulations
Exactly what is Java? Programming language – general-purpose object oriented Standard runtime system – Java Virtual Machine API Specifications – AWT, Java3D, JBDC, etc. JavaBeans, JavaSpaces, etc. Verification – 100% Pure Java
Example: Successive Over-Relaxation public static final void SOR(double omega, double G[][], int num iterations) { int M G.length; int N G[0].length; double omega over four omega * 0.25; double one minus omega 1.0 - omega; for (int p 0; p num iterations; p ) { for (int i 1; i M-1; i ) { for (int j 1; j N-1; j ) G[i][j] omega over four * (G[i-1][j] Gi[i 1][j] G[i][j-1] G[i][j 1]) one minus omega * Gi[j]; } } }
Why Java? Portability of the Java Virtual Machine (JVM) Safe, minimize memory leaks and pointer errors Network-aware environment Parallel and Distributed computing – Threads – Remote Method Invocation (RMI) Integrated graphics Widely adopted – embedded systems, browsers, appliances – being adopted for teaching, development
Portability Binary portability is Java’s greatest strength – several million JDK downloads – Java developers for intranet applications greater than C, C , and Basic combined JVM bytecodes are the key Almost any language can generate Java bytecodes Issue: – can performance be obtained at bytecode level?
Why not Java? Performance – interpreters too slow – poor optimizing compilers – virtual machine
Why not Java? lack of scientific software – computational libraries – numerical interfaces – major effort to port from f77/C
Performance
What are we really measuring? language vs. virtual machine (VM) Java - bytecode translator bytecode execution (VM) – interpreted – just-in-time compilation (JIT) – adaptive compiler (HotSpot) underlying hardware
Making Java fast(er) Native methods (JNI) stand-alone compliers (.java - .exe) modified JVMs – (fused mult-adds, bypass array bounds checking) aggressive bytecode optimization – JITs, flash compilers, HotSpot bytecode transformers concurrency
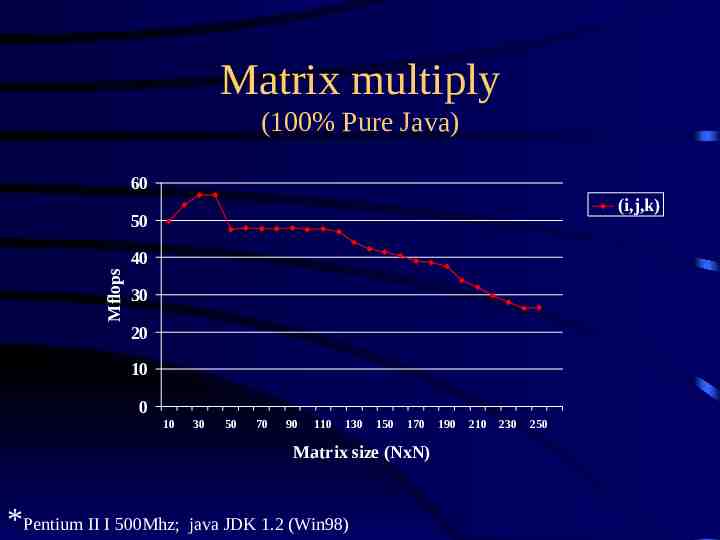
Matrix multiply (100% Pure Java) 60 (i,j,k) 50 Mflops 40 30 20 10 0 10 30 50 70 90 110 130 150 170 Matrix size (NxN) *Pentium II I 500Mhz; java JDK 1.2 (Win98) 190 210 230 250
Optimizing Java linear algebra Use native Java arrays: A[][] algorithms in 100% Pure Java exploit – – – – multi-level blocking loop unrolling indexing optimizations maximize on-chip / in-cache operations can be done today with javac, jview, J , etc.
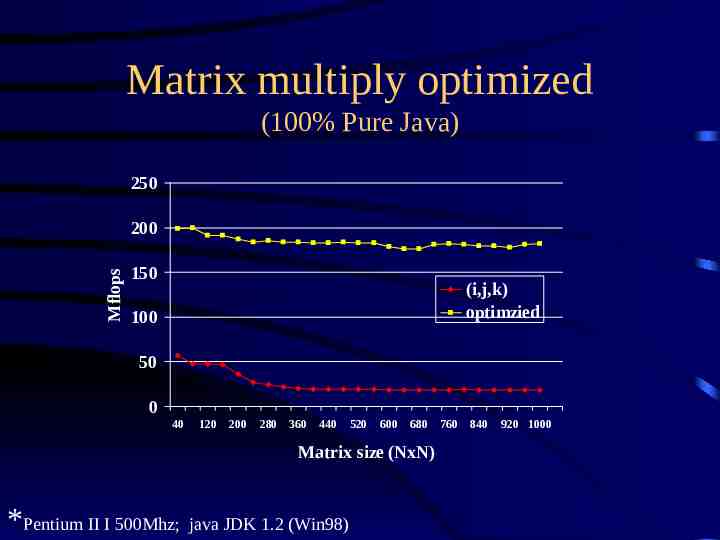
Matrix Multiply: data blocking 1000x1000 matrices (out of cache) Java: 181 Mflops 2-level blocking: – 40x40 (cache) – 8x8 unrolled (chip) subtle trade-off between more temp variables and explicit indexing block size selection important: 64x64 yields only 143 Mflops *Pentium III 500Mhz; Sun JDK 1.2 (Win98)
Matrix multiply optimized (100% Pure Java) 250 Mflops 200 150 (i,j,k) optimzied 100 50 0 40 120 200 280 360 440 520 600 680 Matrix size (NxN) *Pentium II I 500Mhz; java JDK 1.2 (Win98) 760 840 920 1000
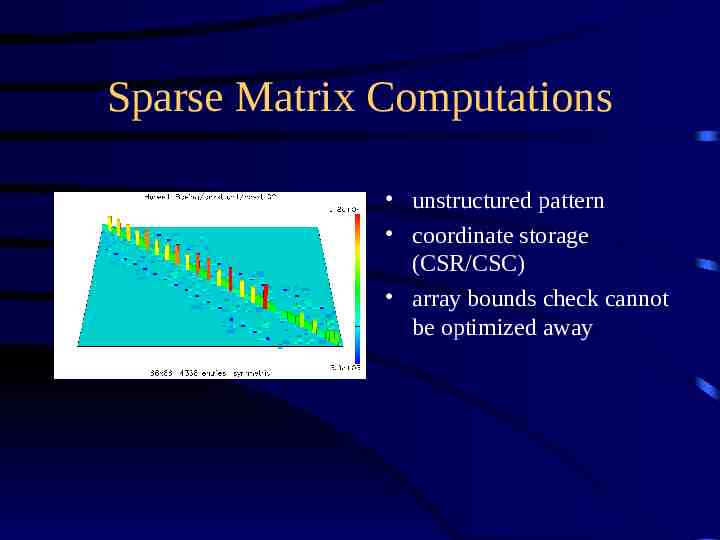
Sparse Matrix Computations unstructured pattern coordinate storage (CSR/CSC) array bounds check cannot be optimized away
Sparse matrix/vector Multiplication (Mflops) Matrix size C/C Java 371 43.9 33.7 20,033 21.4 14.0 24,382 23.2 17.0 126,150 11.1 9.1 (nnz) *266 MHz PII, Win95: Watcom C 10.6, Jview (SDK 2.0)
Java Benchmarking Efforts Caffine Mark SPECjvm98 Java Linpack Java Grande Forum Benchmarks SciMark Image/J benchmark BenchBeans VolanoMark Plasma benchmark RMI benchmark JMark JavaWorld benchmark .
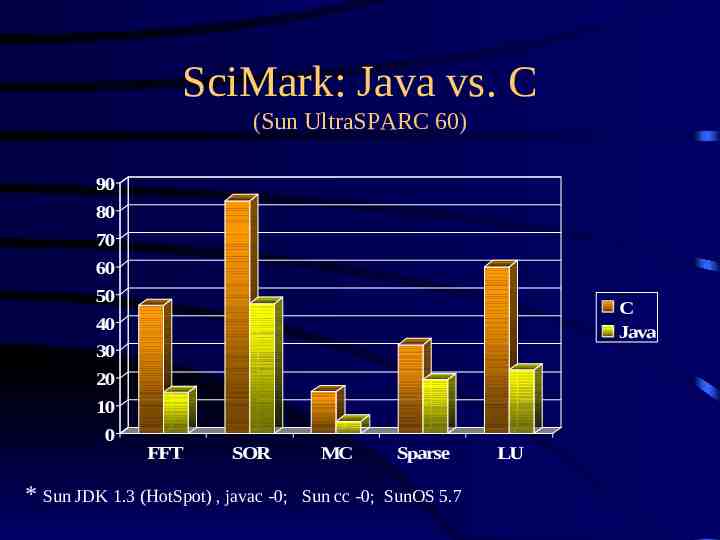
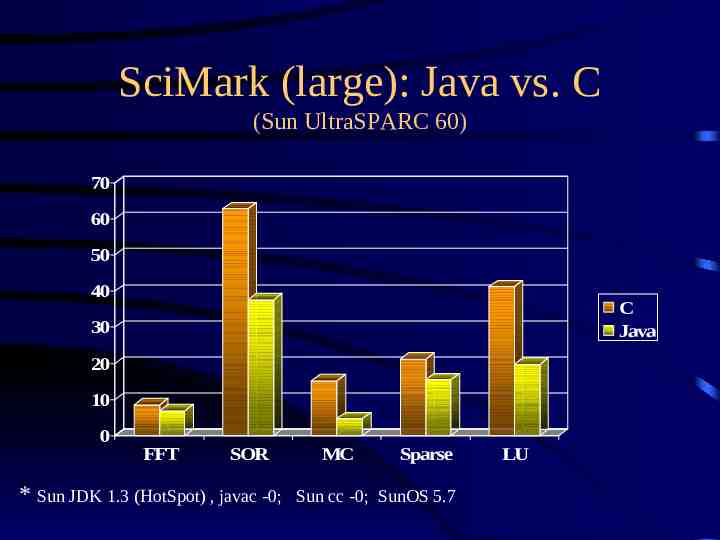
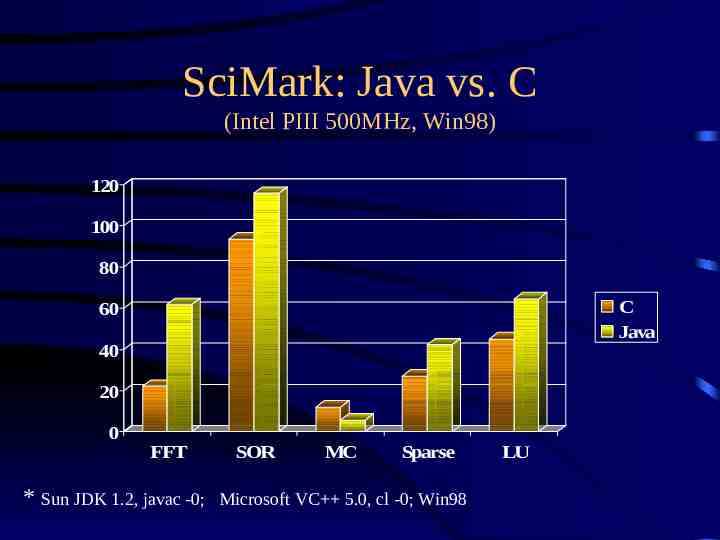
SciMark Benchmark Numerical benchmark for Java, C/C composite results for five kernels: – – – – – FFT (complex, 1D) Successive Over-relaxation Monte Carlo integration Sparse matrix multiply dense LU factorization results in Mflops two sizes: small, large
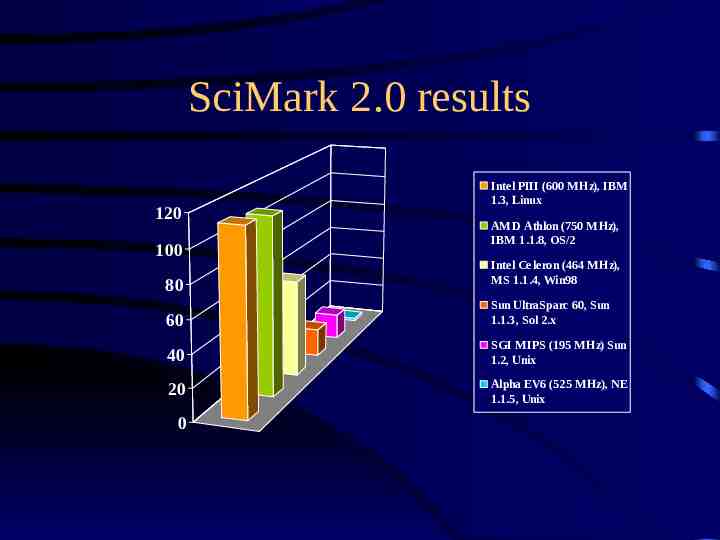
SciMark 2.0 results 120 100 80 Intel PIII (600 MHz), IBM 1.3, Linux AMD Athlon (750 MHz), IBM 1.1.8, OS/2 Intel Celeron (464 MHz), MS 1.1.4, Win98 60 Sun UltraSparc 60, Sun 1.1.3, Sol 2.x 40 SGI MIPS (195 MHz) Sun 1.2, Unix 20 Alpha EV6 (525 MHz), NE 1.1.5, Unix 0
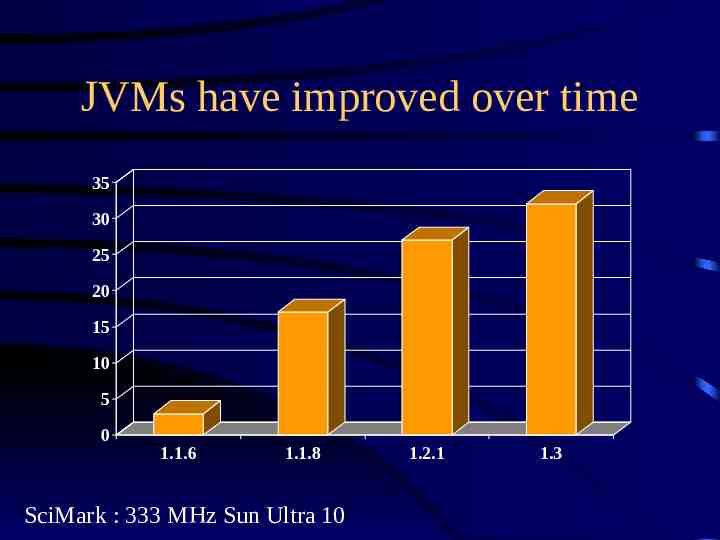
JVMs have improved over time 35 30 25 20 15 10 5 0 1.1.6 1.1.8 SciMark : 333 MHz Sun Ultra 10 1.2.1 1.3
SciMark: Java vs. C (Sun UltraSPARC 60) 90 80 70 60 50 C Java 40 30 20 10 0 FFT SOR * Sun JDK 1.3 (HotSpot) , javac -0; MC Sparse Sun cc -0; SunOS 5.7 LU
SciMark (large): Java vs. C (Sun UltraSPARC 60) 70 60 50 40 C Java 30 20 10 0 FFT SOR * Sun JDK 1.3 (HotSpot) , javac -0; MC Sparse Sun cc -0; SunOS 5.7 LU
SciMark: Java vs. C (Intel PIII 500MHz, Win98) 120 100 80 C Java 60 40 20 0 FFT * Sun JDK 1.2, javac -0; SOR MC Sparse Microsoft VC 5.0, cl -0; Win98 LU
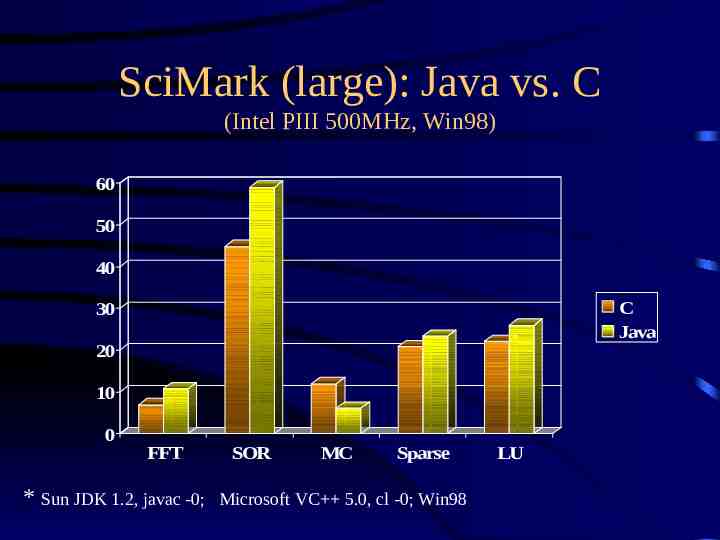
SciMark (large): Java vs. C (Intel PIII 500MHz, Win98) 60 50 40 C Java 30 20 10 0 FFT * Sun JDK 1.2, javac -0; SOR MC Sparse Microsoft VC 5.0, cl -0; Win98 LU
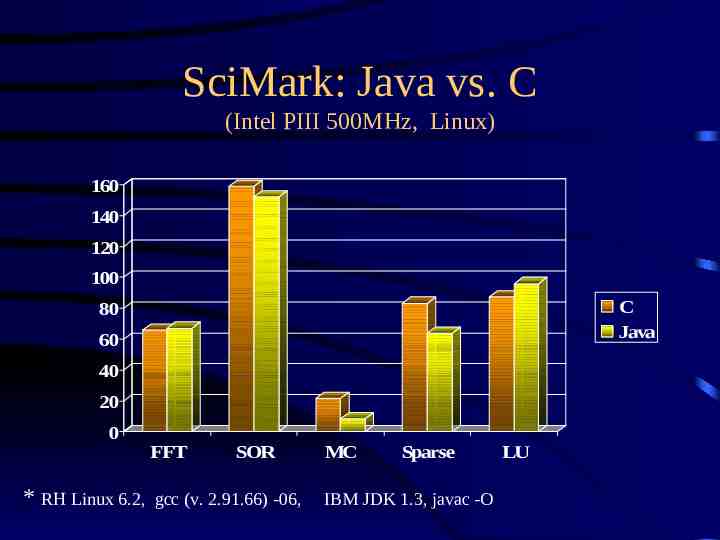
SciMark: Java vs. C (Intel PIII 500MHz, Linux) 160 140 120 100 C Java 80 60 40 20 0 * RH Linux 6.2, FFT SOR gcc (v. 2.91.66) -06, MC Sparse IBM JDK 1.3, javac -O LU
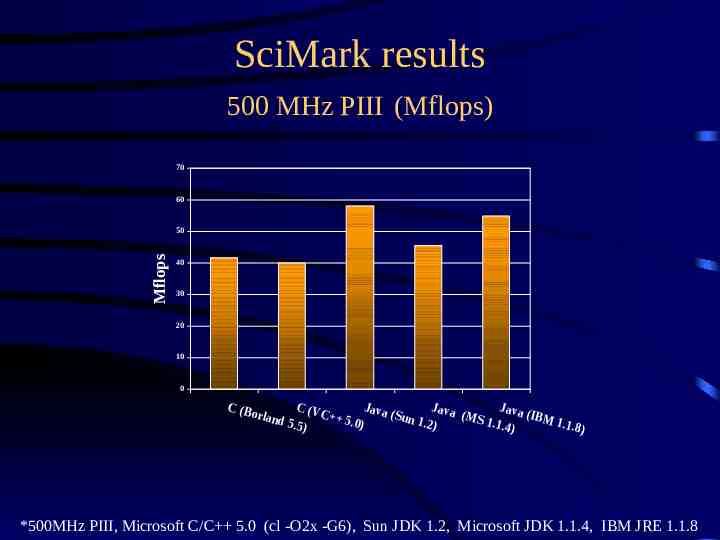
SciMark results 500 MHz PIII (Mflops) 70 60 Mflops 50 40 30 20 10 0 C (B C (V Java Java Java o rlan C ( (IBM ( S M u n S 5. 0) d 5. 5 1.2) 1.1. 4 1. 1. 8 ) ) ) *500MHz PIII, Microsoft C/C 5.0 (cl -O2x -G6), Sun JDK 1.2, Microsoft JDK 1.1.4, IBM JRE 1.1.8
C vs. Java Why C is faster than Java – direct mapping to hardware – more opportunities for aggressive optimization – no garbage collection Why Java is faster than C (?) – different compilers/optimizations – performance more a factor of economics than technology – PC compilers aren’t tuned for numerics
Current JVMs are quite good. 1000x1000 matrix multiply over 180Mflops – 500 MHz Intel PIII, JDK 1.2 Scimark high score: 224 Mflops – 1.2 GHz AMD Athlon, IBM 1.3.0, Linux
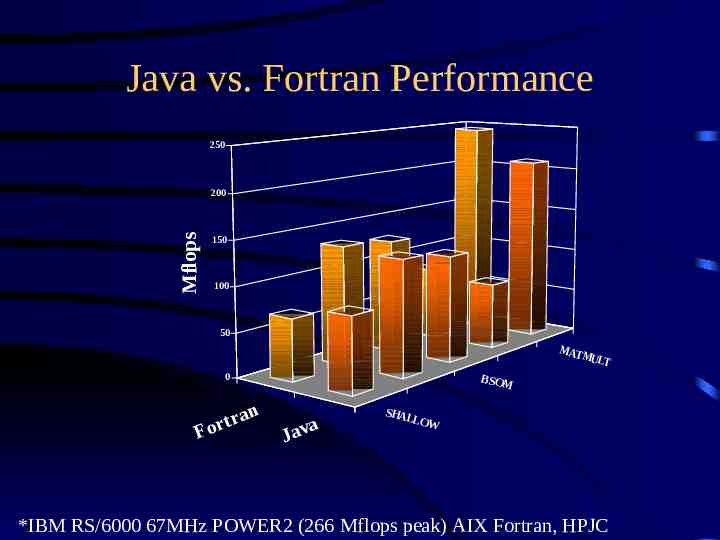
Another approach. Use an aggressive optimizing compiler code using Array classes which mimic Fortran storage – e.g. A[i][j] becomes A.get(i,j) – ugly, but can be fixed with operator overloading extensions exploit hardware (FMAs) result: 85 % of Fortran on RS/6000
IBM High Performance Compiler Snir, Moreria, et. al native compiler (.java - .exe) requires source code can’t embed in browser, but produces very fast codes
Java vs. Fortran Performance 250 Mflops 200 150 100 50 MAT MUL T 0 F an r t r o BS O M a Jav S HA LLO W *IBM RS/6000 67MHz POWER2 (266 Mflops peak) AIX Fortran, HPJC
Yet another approach. HotSpot – Sun Microsystems Progressive profiler/compiler trades off aggressive compilation/optimization at code bottlenecks quicker start-up time than JITs tailors optimization to application
Concurrency Java threads – runs on multiprocessors in NT, Solaris, AIX – provides mechanisms for locks, synchornization – can be implemented in native threads for performance – no native support for parallel loops, etc.
Concurrency Remote Method Invocation (RMI) – – – – – – extension of RPC high-level than sockets/network programming works well for functional parallelism works poorly for data parallelism serialization is expensive no parallel/distribution tools
Numerical Software (Libraries)
Scientific Java Libraries Matrix library (JAMA) – NIST/Mathworks – LU, QR, SVD, eigenvalue solvers Java Numerical Toolkit (JNT) – special functions – BLAS subset Visual Numerics – LINPACK – Complex IBM – Array class package Univ. of Maryland – Linear Algebra library JLAPACK – port of LAPACK
Java Numerics Group industry-wide consortium to establish tools, APIs, and libraries – IBM, Intel, Compaq/Digital, Sun, MathWorks, VNI, NAG – NIST, Inria – Berkeley, UCSB, Austin, MIT, Indiana component of Java Grande Forum – Concurrency group
Numerics Issues complex data types lightweight objects operator overloading generic typing (templates) IEEE floating point model
Parallel Java projects Java-MPI JavaPVM Titanium (UC Berkeley) HPJava DOGMA JTED Jwarp DARP Tango DO! Jmpi MpiJava JET Parallel JVM
Conclusions Java numerics can be competitive with C – 50% “rule of thumb” for many instances – can achieve efficiency of optimized C/Fortran best Java performance on commodity platforms biggest challenge now: – integrate array and complex into Java – more libraries!
Scientific Java Resources Java Numerics Group – http://math.nist.gov/javanumerics Java Grande Forum – http://www.javagrade.org SciMark Benchmark – http://math.nist.gov/scimark






