Parallelism-Aware Batch Scheduling Enhancing both Performance
























36 Slides1.55 MB
Parallelism-Aware Batch Scheduling Enhancing both Performance and Fairness of Shared DRAM Systems Onur Mutlu and Thomas Moscibroda Computer Architecture Group Microsoft Research
Outline Background and Goal Motivation Parallelism-Aware Batch Scheduling Destruction of Intra-thread DRAM Bank Parallelism Batching Within-batch Scheduling System Software Support Evaluation Summary 2
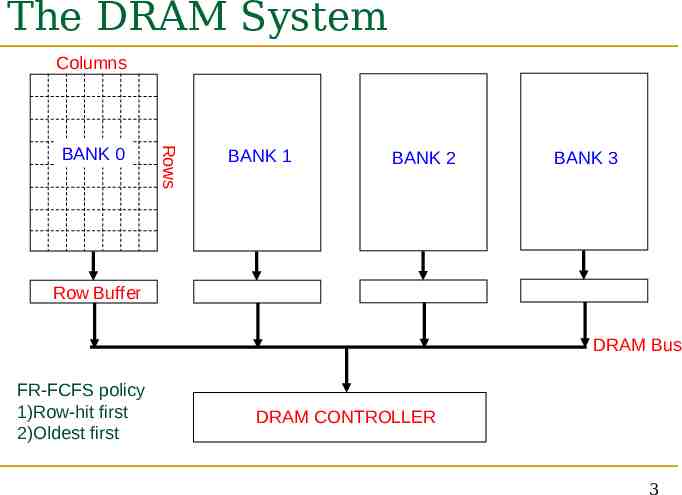
The DRAM System Columns Rows BANK 0 BANK 1 BANK 2 BANK 3 Row Buffer DRAM Bus FR-FCFS policy 1)Row-hit first 2)Oldest first DRAM CONTROLLER 3
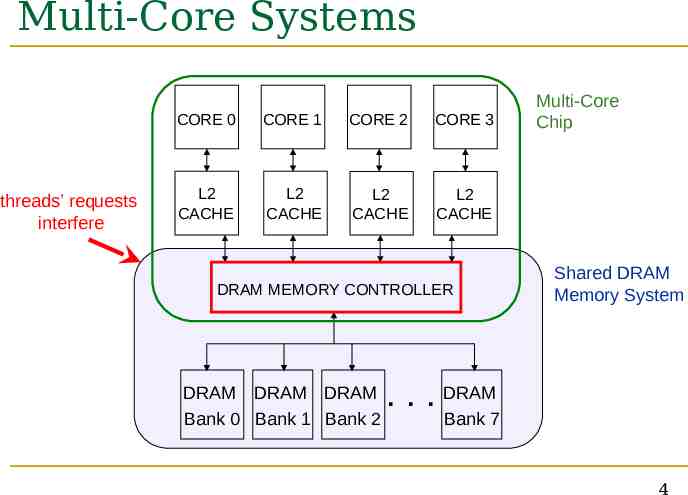
Multi-Core Systems threads’ requests interfere CORE 0 CORE 1 CORE 2 CORE 3 L2 CACHE L2 CACHE L2 CACHE L2 CACHE DRAM MEMORY CONTROLLER DRAM DRAM DRAM Bank 0 Bank 1 Bank 2 Multi-Core Chip Shared DRAM Memory System . . . DRAM Bank 7 4
Inter-thread Interference in the DRAM System Threads delay each other by causing resource contention: Threads can also destroy each other’s DRAM bank parallelism Bank, bus, row-buffer conflicts [MICRO 2007] Otherwise parallel requests can become serialized Existing DRAM schedulers are unaware of this interference They simply aim to maximize DRAM throughput Thread-unaware and thread-unfair No intent to service each thread’s requests in parallel FR-FCFS policy: 1) row-hit first, 2) oldest first Unfairly prioritizes threads with high row-buffer locality 5
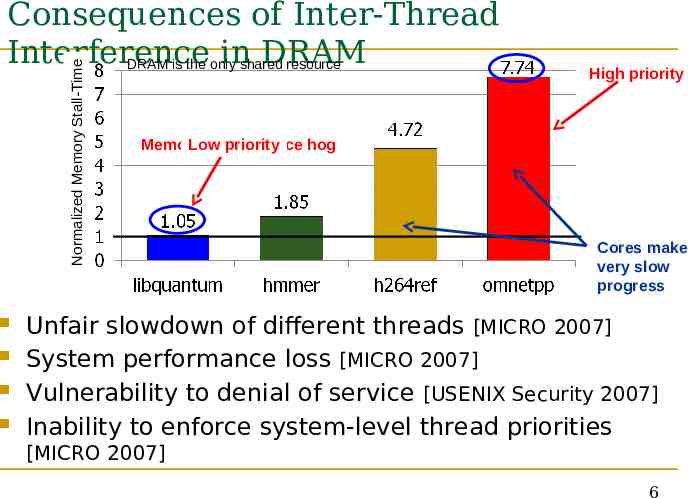
Normalized Memory Stall-Time Consequences of Inter-Thread Interference inshared DRAM DRAM is the only resource High priority Memory Low performance priority hog Cores make very slow progress Unfair slowdown of different threads [MICRO 2007] System performance loss [MICRO 2007] Vulnerability to denial of service [USENIX Security 2007] Inability to enforce system-level thread priorities [MICRO 2007] 6
Our Goal Control inter-thread interference in DRAM Design a shared DRAM scheduler that provides high system performance provides fairness to threads sharing the DRAM system preserves each thread’s DRAM bank parallelism equalizes memory-slowdowns of equal-priority threads is controllable and configurable enables different service levels for threads with different priorities 7
Outline Background and Goal Motivation Parallelism-Aware Batch Scheduling Destruction of Intra-thread DRAM Bank Parallelism Batching Within-batch Scheduling System Software Support Evaluation Summary 8
The Problem Processors try to tolerate the latency of DRAM requests by generating multiple outstanding requests Memory-Level Parallelism (MLP) Out-of-order execution, non-blocking caches, runahead execution Effective only if the DRAM controller actually services the multiple requests in parallel in DRAM banks Multiple threads share the DRAM controller DRAM controllers are not aware of a thread’s MLP Can service each thread’s outstanding requests serially, not in parallel 9
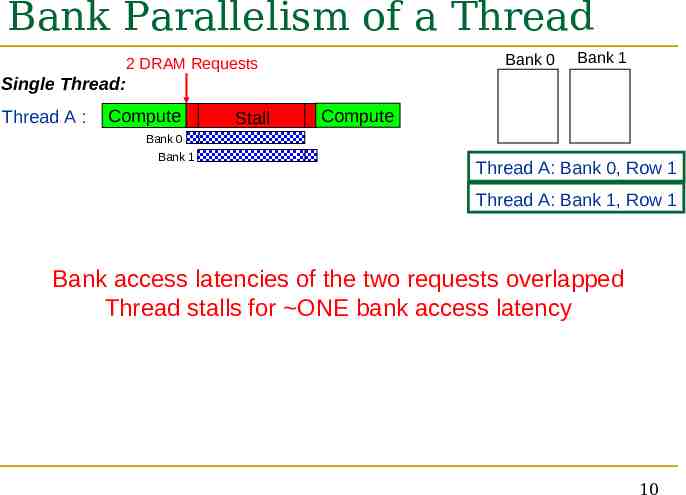
Bank Parallelism of a Thread Bank 0 2 DRAM Requests Bank 1 Single Thread: Thread A : Compute Stall Compute Bank 0 Bank 1 Thread A: Bank 0, Row 1 Thread A: Bank 1, Row 1 Bank access latencies of the two requests overlapped Thread stalls for ONE bank access latency 10
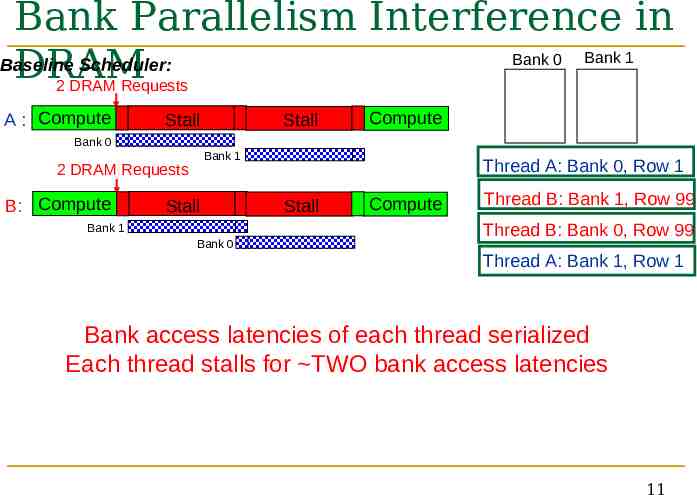
Bank Parallelism Interference in Baseline Scheduler: DRAM Bank 0 Bank 1 2 DRAM Requests A : Compute Stall Stall Compute Bank 0 Bank 1 2 DRAM Requests B: Compute Stall Bank 1 Bank 0 Thread A: Bank 0, Row 1 Stall Compute Thread B: Bank 1, Row 99 Thread B: Bank 0, Row 99 Thread A: Bank 1, Row 1 Bank access latencies of each thread serialized Each thread stalls for TWO bank access latencies 11
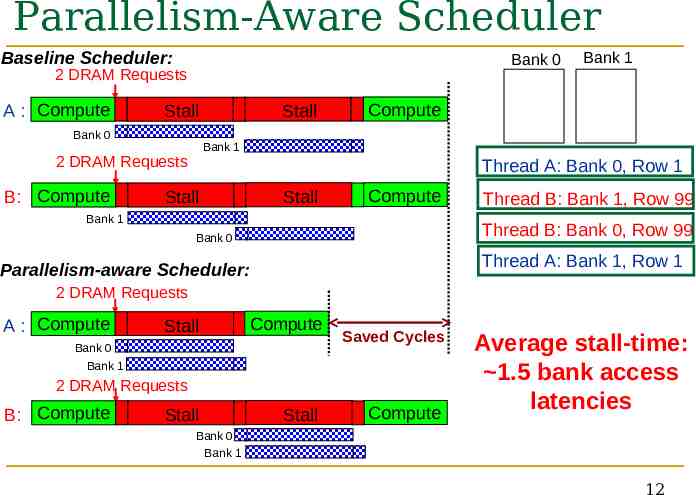
Parallelism-Aware Scheduler Baseline Scheduler: Bank 0 2 DRAM Requests A : Compute Bank 0 Compute Bank 1 2 DRAM Requests B: Compute Stall Stall Bank 1 Thread A: Bank 0, Row 1 Stall Stall Compute Bank 1 Thread B: Bank 1, Row 99 Thread B: Bank 0, Row 99 Bank 0 Thread A: Bank 1, Row 1 Parallelism-aware Scheduler: 2 DRAM Requests A : Compute Stall Compute Bank 0 Saved Cycles Bank 1 2 DRAM Requests B: Compute Stall Stall Compute Average stall-time: 1.5 bank access latencies Bank 0 Bank 1 12
Outline Background and Goal Motivation Parallelism-Aware Batch Scheduling (PAR-BS) Destruction of Intra-thread DRAM Bank Parallelism Request Batching Within-batch Scheduling System Software Support Evaluation Summary 13
Parallelism-Aware Batch Scheduling (PAR-BS) Principle 1: Parallelism-awareness Schedule requests from a thread (to different banks) back to back Preserves each thread’s bank parallelism But, this can cause starvation Principle 2: Request Batching Group a fixed number of oldest requests from each thread into a “batch” Service the batch before all other requests Form a new batch when the current one is done Eliminates starvation, provides fairness Allows parallelism-awareness within a batch T1 T1 T2 T0 T2 T2 T3 T2 T0 T3 T2 T1 T1 T0 Bank 0 Bank 1 Batch 14
PAR-BS Components Request batching Within-batch scheduling Parallelism aware 15
Request Batching Each memory request has a bit (marked) associated with it Batch formation: Marked requests are prioritized over unmarked ones Mark up to Marking-Cap oldest requests per bank for each thread Marked requests constitute the batch Form a new batch when no marked requests are left No reordering of requests across batches: no starvation, high fairness How to prioritize requests within a batch? 16
Within-Batch Scheduling Can use any existing DRAM scheduling policy FR-FCFS (row-hit first, then oldest-first) exploits row-buffer locality But, we also want to preserve intra-thread bank parallelism Service each thread’s requests back to back HOW? Scheduler computes a ranking of threads when the batch is formed Higher-ranked threads are prioritized over lower-ranked ones Improves the likelihood that requests from a thread are serviced in parallel by different banks Different threads prioritized in the same order across ALL banks 17
How to Rank Threads within a Batch Ranking scheme affects system throughput and fairness Maximize system throughput Minimize unfairness (Equalize the slowdown of threads) Minimize average stall-time of threads within the batch Service threads with inherently low stall-time early in the batch Insight: delaying memory non-intensive threads results in high slowdown Shortest stall-time first (shortest job first) ranking Provides optimal system throughput [Smith, 1956]* Controller estimates each thread’s stall-time within the batch Ranks threads with shorter stall-time higher * W.E. Smith, “Various optimizers for single stage production,” Naval Research Logistics Quarterly, 1956. 18
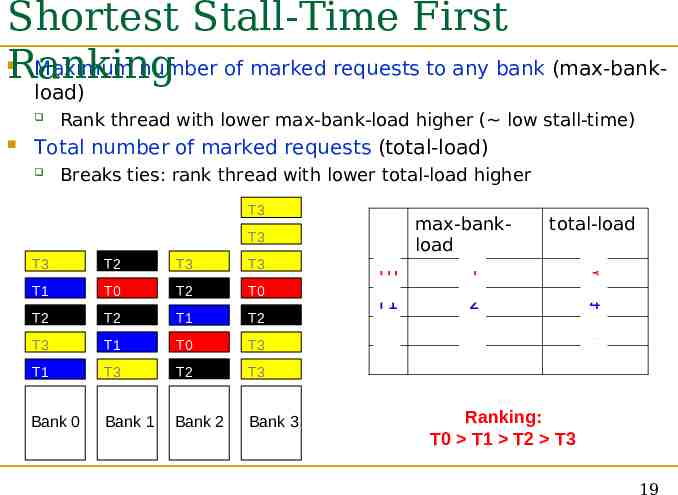
Shortest Stall-Time First Maximum number of marked requests to any bank (max-bankRanking load) Rank thread with lower max-bank-load higher ( low stall-time) Total number of marked requests (total-load) Breaks ties: rank thread with lower total-load higher T3 max-bankload T3 T3 T2 T3 T3 T1 T0 T2 T0 T2 T2 T1 T2 T3 T1 T0 T3 T1 T3 T2 T3 Bank 0 Bank 1 Bank 2 Bank 3 total-load T0 1 3 T1 2 4 T2 2 6 T3 5 9 Ranking: T0 T1 T2 T3 19
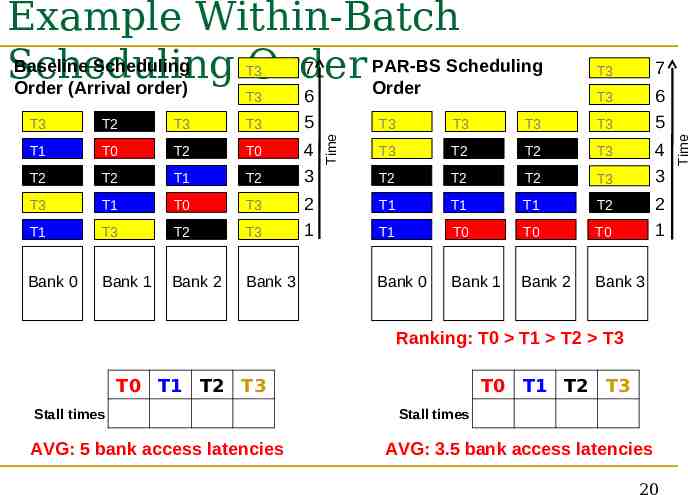
T3 T3 T2 T3 T3 T1 T0 T2 T0 T2 T2 T1 T2 T3 T1 T0 T3 T1 T3 T2 T3 Bank 0 Bank 1 Bank 2 Bank 3 6 5 4 3 2 1 Time T3 T3 7 T3 6 5 T3 T3 T3 T3 T3 T2 T2 T3 T2 T2 T2 T3 T1 T1 T1 T2 T1 T0 T0 T0 Bank 0 Bank 1 Bank 2 Bank 3 4 3 2 1 Ranking: T0 T1 T2 T3 T0 T1 T2 T3 Stall times 4 4 5 7 AVG: 5 bank access latencies T0 T1 T2 T3 Stall times 1 2 4 7 AVG: 3.5 bank access latencies 20 Time Example Within-Batch Baseline Scheduling PAR-BS Scheduling 7 Scheduling Order Order (Arrival order) Order
Putting It Together: PAR-BS Scheduling Policy PAR-BS Scheduling Policy (1) Marked requests first Batching (2) Row-hit requests first Parallelism-aware (3) Higher-rank thread first (shortest stall-time first) within-batch (4) Oldest first scheduling Three properties: Exploits row-buffer locality and intra-thread bank parallelism Work-conserving Marking-Cap is important Services unmarked requests to banks without marked requests Too small cap: destroys row-buffer locality Too large cap: penalizes memory non-intensive threads Many more trade-offs analyzed in the paper 21
Hardware Cost 1.5KB storage cost for 8-core system with 128-entry memory request buffer No complex operations (e.g., divisions) Not on the critical path Scheduler makes a decision only every DRAM cycle 22
Outline Background and Goal Motivation Parallelism-Aware Batch Scheduling Destruction of Intra-thread DRAM Bank Parallelism Batching Within-batch Scheduling System Software Support Evaluation Summary 23
System Software Support OS conveys each thread’s priority level to the controller Controller enforces priorities in two ways Mark requests from a thread with priority X only every Xth batch Within a batch, higher-priority threads’ requests are scheduled first Purely opportunistic service Levels 1, 2, 3, (highest to lowest priority) Special very low priority level L Requests from such threads never marked Quantitative analysis in paper 24
Outline Background and Goal Motivation Parallelism-Aware Batch Scheduling Destruction of Intra-thread DRAM Bank Parallelism Batching Within-batch Scheduling System Software Support Evaluation Summary 25
Evaluation Methodology 4-, 8-, 16-core systems Detailed DRAM model based on Micron DDR2-800 x86 processor model based on Intel Pentium M 4 GHz processor, 128-entry instruction window 512 Kbyte per core private L2 caches, 32 L2 miss buffers 128-entry memory request buffer 8 banks, 2Kbyte row buffer 40ns (160 cycles) row-hit round-trip latency 80ns (320 cycles) row-conflict round-trip latency Benchmarks Multiprogrammed SPEC CPU2006 and Windows Desktop applications 100, 16, 12 program combinations for 4-, 8-, 16-core experiments 26
Comparison with Other DRAM Controllers Baseline FR-FCFS [Zuravleff and Robinson, US Patent 1997; Rixner et al., ISCA 2000] FCFS [Intel Pentium 4 chipsets] Oldest-first; low DRAM throughput Unfairly penalizes memory non-intensive threads Network Fair Queueing (NFQ) Prioritizes row-hit requests, older requests Unfairly penalizes threads with low row-buffer locality, memory nonintensive threads [Nesbit et al., MICRO 2006] Equally partitions DRAM bandwidth among threads Does not consider inherent (baseline) DRAM performance of each thread Unfairly penalizes threads with high bandwidth utilization [MICRO 2007] Unfairly prioritizes threads with bursty access patterns [MICRO 2007] Stall-Time Fair Memory Scheduler (STFM) 2007] [Mutlu & Moscibroda, MICRO Estimates and balances thread slowdowns relative to when run alone Unfairly treats threads with inaccurate slowdown estimates Requires multiple (approximate) arithmetic operations 27
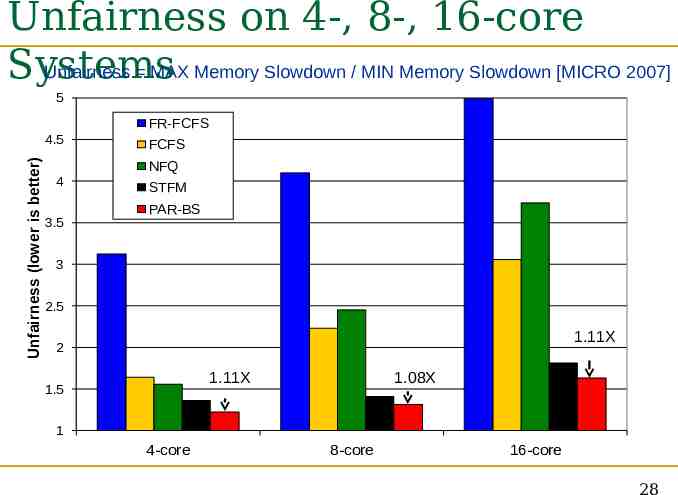
Unfairness on 4-, 8-, 16-core Systems Unfairness MAX Memory Slowdown / MIN Memory Slowdown [MICRO 2007] 5 FR-FCFS Unfairness (lower is better) 4.5 FCFS NFQ 4 3.5 STFM PAR-BS 3 2.5 1.11X 2 1.11X 1.5 1.08X 1 4-core 8-core 16-core 28
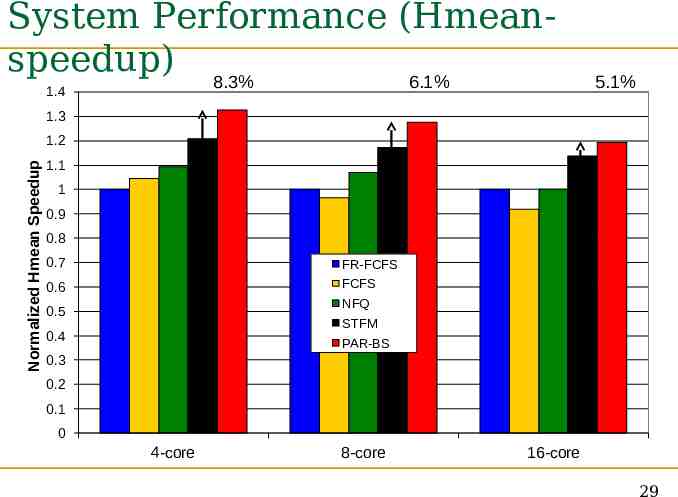
System Performance (Hmeanspeedup) 8.3% 6.1% 1.4 5.1% 1.3 Normalized Hmean Speedup 1.2 1.1 1 0.9 0.8 0.7 FR-FCFS 0.6 FCFS NFQ 0.5 STFM 0.4 PAR-BS 0.3 0.2 0.1 0 4-core 8-core 16-core 29
Outline Background and Goal Motivation Parallelism-Aware Batch Scheduling Destruction of Intra-thread DRAM Bank Parallelism Batching Within-batch Scheduling System Software Support Evaluation Summary 30
Summary Inter-thread interference can destroy each thread’s DRAM bank parallelism A new approach to fair and high-performance DRAM scheduling Serializes a thread’s requests reduces system throughput Makes techniques that exploit memory-level parallelism less effective Existing DRAM controllers unaware of intra-thread bank parallelism Batching: Eliminates starvation, allows fair sharing of the DRAM system Parallelism-aware thread ranking: Preserves each thread’s bank parallelism Flexible and configurable: Supports system-level thread priorities QoS policies PAR-BS provides better fairness and system performance than previous DRAM schedulers 31
Thank you. Questions?
Parallelism-Aware Batch Scheduling Enhancing both Performance and Fairness of Shared DRAM Systems Onur Mutlu and Thomas Moscibroda Computer Architecture Group Microsoft Research
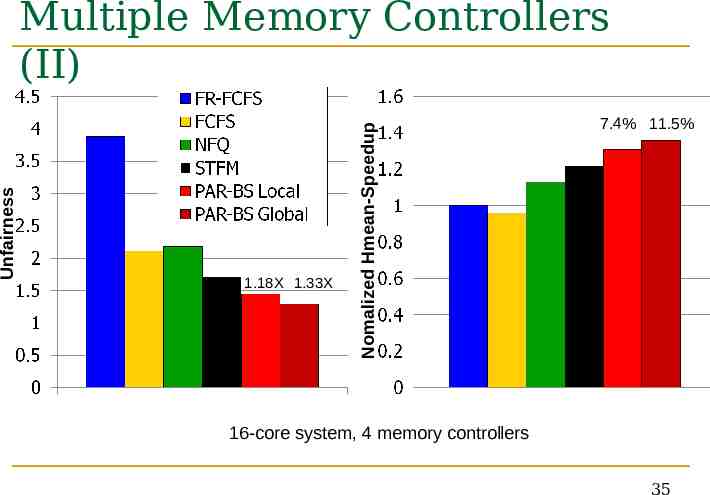
Multiple Memory Controllers (I) Local ranking: Each controller uses PAR-BS independently Global ranking: Meta controller that computes a global ranking across all controllers based on global information Computes its own ranking based on its local requests Only needs to track bookkeeping info about each thread’s requests to the banks in each controller The difference between the ranking computed by each scheme depends on the balance of the distribution of requests to each controller Balanced Local and global rankings are similar 34
1.18X 1.33X Nomalized Hmean-Speedup Unfairness Multiple Memory Controllers (II) 7.4% 11.5% 16-core system, 4 memory controllers 35
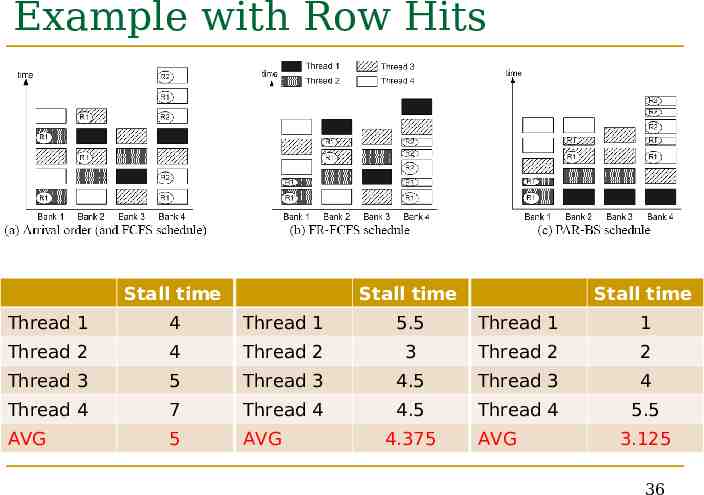
Example with Row Hits Stall time Stall time Stall time Thread 1 4 Thread 1 5.5 Thread 1 1 Thread 2 4 Thread 2 3 Thread 2 2 Thread 3 5 Thread 3 4.5 Thread 3 4 Thread 4 7 Thread 4 4.5 Thread 4 5.5 AVG 5 AVG 4.375 AVG 3.125 36






