Parallel Scientific Computing: Algorithms and Tools Lecture #3 APMA

















26 Slides319.00 KB
Parallel Scientific Computing: Algorithms and Tools Lecture #3 APMA 2821A, Spring 2008 Instructors: George Em Karniadakis Leopold Grinberg 1
Levels of Parallelism Job level parallelism: Capacity computing Goal: run as many jobs as possible on a system for given time period. Concerned about throughput; Individual user’s jobs may not run faster. Of interest to administrators Program/Task level parallelism: Capability computing Use multiple processors to solve a single problem. Controlled by users. Instruction level parallelism: Pipeline, multiple functional units, multiple cores. Invisible to users. Bit-level parallelism: Of concern to hardware designers of arithmetic-logic units 2
Granularity of Parallel Tasks Large/coarse grain parallelism: Amount of operations that run in parallel is fairly large e.g., on the order of an entire program Small/fine grain parallelism: Amount of operations that run in parallel is relatively small e.g., on the order of single loop. Coarse/large grains usually result in more favorable parallel performance 3
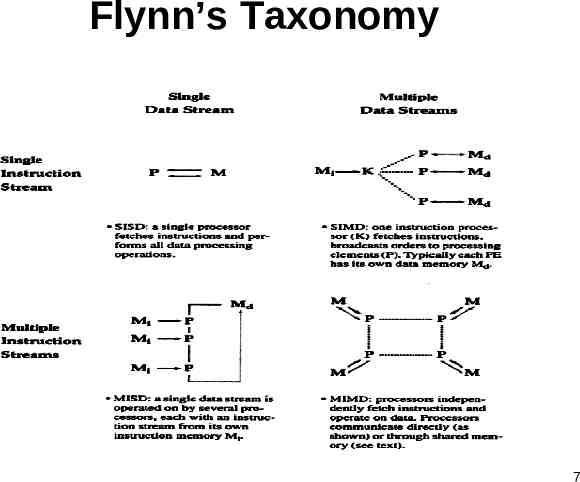
Flynn’s Taxonomy of Computers SISD: Single instruction stream, single data stream MISD: Multiple instruction streams, single data stream SIMD: Single instruction stream, multiple data streams MIMD: Multiple instruction streams, multiple data streams 4
Classification of Computers SISD: single instruction single data Conventional computers CPU fetches from one instruction stream and works on one data stream. Instructions may run in parallel (superscalar). MISD: multiple instruction single data No real world implementation. 5
Classification of Computers SIMD: single instruction multiple data Controller processing elements (PE) Controller dispatches an instruction to PEs; All PEs execute same instruction, but on different data e.g., MasPar MP-1, Thinking machines CM-1, vector computers (?) MIMD: multiple instruction multiple data Processors execute own instructions on different data streams Processors communicate with one another directly, or through shared memory. Usual parallel computers, clusters of workstations 6
Flynn’s Taxonomy 7
Programming Model SPMD: Single program multiple data MPMD: multiple programs multiple data 8
Programming Model SPMD: Single program multiple data Usual parallel programming model All processors execute same program, on multiple data sets (domain decomposition) Processor knows its own ID if(my cpu id N){} else {} 9
Programming Model MPMD: Multiple programs multiple data Different processors execute different programs, on different data Usually a master-slave model is used. Master CPU spawns and dispatches computations to slave CPUs running a different program. Can be converted into SPMD model if(my cpu id 0) run function containing program 1; else run function containing program 2; 10
Classification of Parallel Computers Flynn’s MIMD computers contain a wide variety of parallel computers Based on memory organization (address space): Shared-memory parallel computers Processors can access all memories Distributed-memory parallel computers Processor can only access local memory Remote memory access through explicit communication 11
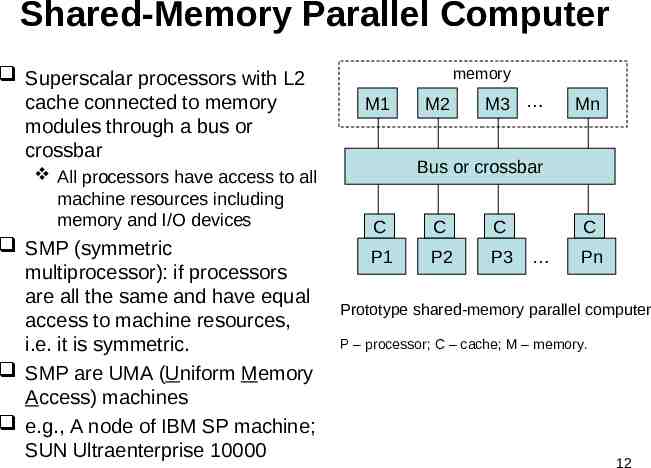
Shared-Memory Parallel Computer Superscalar processors with L2 cache connected to memory modules through a bus or crossbar All processors have access to all machine resources including memory and I/O devices SMP (symmetric multiprocessor): if processors are all the same and have equal access to machine resources, i.e. it is symmetric. SMP are UMA (Uniform Memory Access) machines e.g., A node of IBM SP machine; SUN Ultraenterprise 10000 memory M1 M2 M3 Mn Bus or crossbar C C C P1 P2 P3 C Pn Prototype shared-memory parallel computer P – processor; C – cache; M – memory. 12
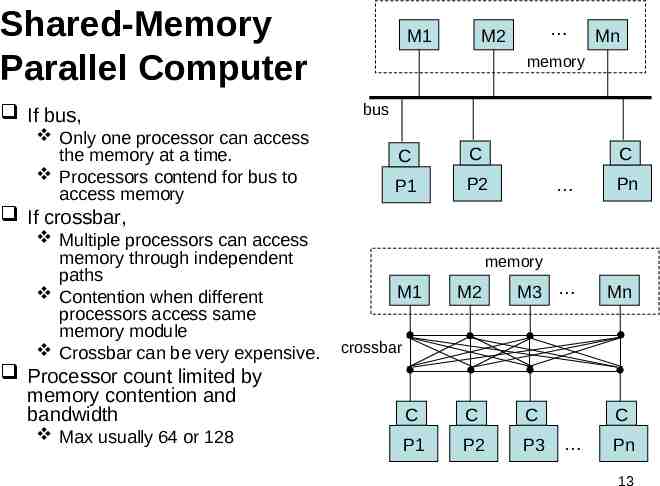
Shared-Memory Parallel Computer If bus, Only one processor can access the memory at a time. Processors contend for bus to access memory M1 M2 Mn memory bus C C C P1 P2 Pn If crossbar, Multiple processors can access memory through independent paths Contention when different processors access same memory module Crossbar can be very expensive. memory M1 M2 M3 Mn crossbar Processor count limited by memory contention and bandwidth C C C Max usually 64 or 128 P1 P2 P3 C Pn 13
Shared-Memory Parallel Computer Data flows from memory to cache, to processors Performance depends dramatically on reuse of data in cache Fetching data from memory with potential memory contention can be expensive L2 cache plays of the role of local fast memory; Shared memory is analogous to extended memory accessed in blocks 14
Cache Coherency If a piece of data in one processor’s cache is modified, then all other processors’ cache that contain that data must be updated. Cache coherency: the state that is achieved by maintaining consistent values of same data in all processors’ caches. Usually hardware maintains cache coherency; System software can also do this, but more difficult. 15
Programming Shared-Memory Parallel Computers All memory modules have the same global address space. Closest to single-processor computer Relatively easy to program. Multi-threaded programming: Auto-parallelizing compilers can extract fine-grain (loop-level) parallelism automatically; Or use OpenMP; Or use explicit POSIX (portable operating system interface) threads or other thread libraries. Message passing: MPI (Message Passing Interface). 16
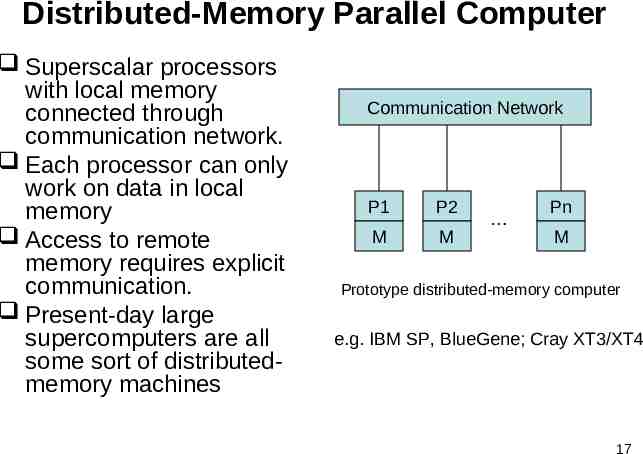
Distributed-Memory Parallel Computer Superscalar processors with local memory connected through communication network. Each processor can only work on data in local memory Access to remote memory requires explicit communication. Present-day large supercomputers are all some sort of distributedmemory machines Communication Network P1 P2 M M Pn M Prototype distributed-memory computer e.g. IBM SP, BlueGene; Cray XT3/XT4 17
Distributed-Memory Parallel Computer High scalability No memory contention such as those in shared-memory machines Now scaled to 100,000 processors. Performance of network connection crucial to performance of applications. Ideal: low latency, high bandwidth Communication much slower than local memory read/write Data locality is important. Frequently used data local memory 18
Programming Distributed-Memory Parallel Computer “Owner computes” rule Problem needs to be broken up into independent tasks with independent memory Each task assigned to a processor Naturally matches data based decomposition such as a domain decomposition Message passing: tasks explicitly exchange data by message passing. Transfers all data using explicit send/receive instructions User must optimize communications Usually MPI (used to be PVM), portable, high performance Parallelization mostly at large granularity level controlled by user Difficult for compilers/auto-parallelization tools 19
Programming Distributed-Memory Parallel Computer A global address space is provided on some distributedmemory machine Memory physically distributed, but globally addressable; can be treated as “shared-memory” machine; so-called distributed shared-memory. Cray T3E; SGI Altix, Origin. Multi-threaded programs (OpenMP, POSIX threads) can also be used on such machines User accesses remote memory as if it were local; OS/compilers translate such accesses to fetch/store over the communication network. But difficult to control data locality; performance may suffer. NUMA (non-uniform memory access); ccNUMA (cache coherent non-uniform memory access); overhead 20
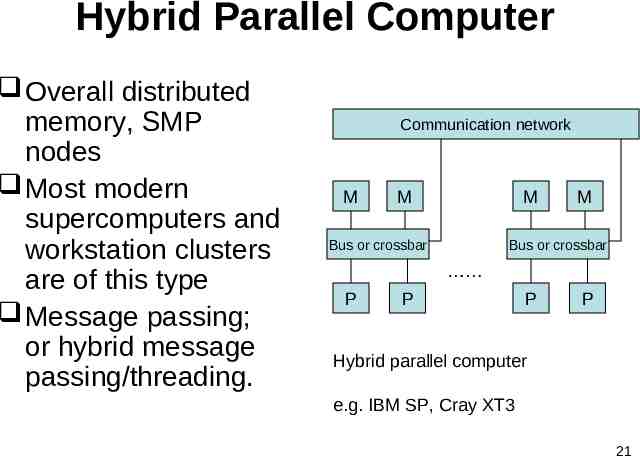
Hybrid Parallel Computer Overall distributed memory, SMP nodes Most modern supercomputers and workstation clusters are of this type Message passing; or hybrid message passing/threading. Communication network M M M Bus or crossbar M Bus or crossbar P P P P Hybrid parallel computer e.g. IBM SP, Cray XT3 21
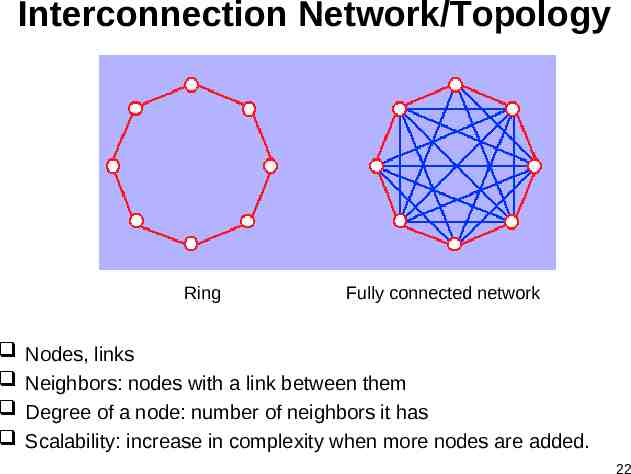
Interconnection Network/Topology Ring Fully connected network Nodes, links Neighbors: nodes with a link between them Degree of a node: number of neighbors it has Scalability: increase in complexity when more nodes are added. 22
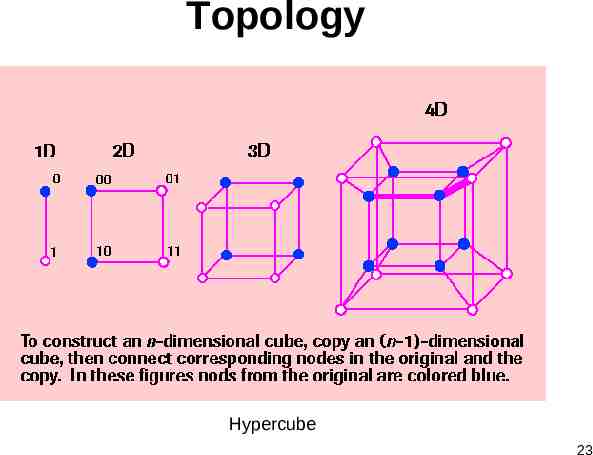
Topology Hypercube 23
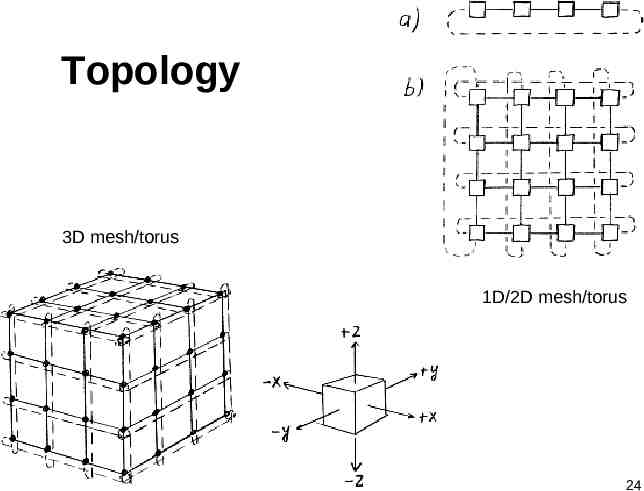
Topology 3D mesh/torus 1D/2D mesh/torus 24
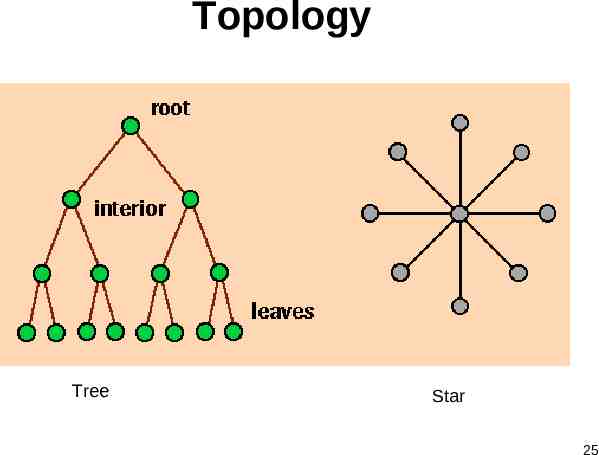
Topology Tree Star 25
Topology Bisection width: minimum number of links that must be cut in order to divide the topology into two independent networks of the same size (plus/minus one node) Bisection bandwidth: communication bandwidth across the links that are cut in defining bisection width Larger bisection bandwidth better 26






