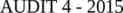Optimizing Program Enrollment with Machine Learning Texas























40 Slides9.38 MB
Optimizing Program Enrollment with Machine Learning Texas Government Data Forum 2018:
Optimizing Program Enrollment with Machine Learning F A R D J D Freeman Data Scientist Digital Solutions Group [email protected] Michael Kennedy Director Public Sector Cloud Strategy [email protected] 2
TXDBC3D Hypothetical Agency F A R D 3
The Mission & Challenge of TXDBC3D TXDBC3D administers programs to “enhance the social good” of Texans Exit rates for enrolled participants vary year-over-year for a variety of reasons We want to maximize favorable exits and minimize detrimental exits Favorable Examples Detrimental Examples An unemployed person finds work A homeless person violates drug use policy and must leave a shelter A foster child is adopted by a suitable family A household rises from poverty A foster child runs away from a custodial placement A trainee in a work skills class just stops attending 4
What Data do we have available?
Mixed Data What do we know about our program participants? F A R D Did they have a favorable or detrimental exit from a program? (binary yes/ no) Level of engagement in our programs (Gaussian) Total time in our programs (Gaussian) High School graduate (binary yes / no) History of Substance Abuse (binary yes / no) Do they feel positive or negative about our programs (Sentiment % Positive) How are those feelings expressed in emotion (Affect – emotion in language) Which District/County are they in (Categorical variable) What is the relative population of that District (Relative percentage of population) What is the Median Household Income (MHI) of that District / County (How packed and how wealthy) 6
Mixed Data Total Favorable Program Exit Engagement Time High School Substance Sentiment Affect Graduate Abuse % Positive Frustration District Median Population Household % Income 1 0 0 0 1 1 0 0 0 0 0 0 1 1 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 1 1 0 7.238636342 0.038068958 0.583452454 1.221749043 1.271220384 16.47343988 0.460240675 0.475551524 0.490029716 0.133465668 0.791085655 6.922111637 16.47343988 9.241723205 16.47343988 0.808575052 1.897590591 1.515059831 0.565137577 0.685122286 0.521871757 0.547867042 0.620649492 0.697534511 0.590633888 0.533905538 0.553067296 0.501555817 0.513745973 0.429873467 0.652967878 0.560936158 0.541760278 0.617387242 0.528067486 0.734443307 0.570744759 0.52446596 F A R D 0.314163312 0.842486702 0.438796124 0.659847571 0.287432525 0.354029295 0.424168913 0.43585778 0.586962169 0.431134087 0.888005206 0.522491972 0.19490414 0.10555925 0.29118416 0.675506645 0.318938098 0.47513635 0.43962555 0 1 1 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 0.7 0.64 0 0.17 0.6 0.72 0.38 0 0.62 0.55 0.56 0 0.49 0.46 0.61 0.64 0.38 0.12 0 0.3 0.32 1 0.85 0.39 0.22 0.68 0.89 0.36 0.61 0.32 0.87 0.57 0.43 0.43 0.32 0.44 0.88 1 Tarrant Franklin Midland Bell Brazoria Harris Grayson Randall Taylor Matagorda Brazos Bexar Harris Dalla Harris Smith Williamson Cameron Ector 55306 45625 54945 48618 65607 51444 46875 56041 42403 43205 37898 47048 51444 47974 51444 46139 68780 31264 45815 7
Free Text Expressions Expressions by the enrolled participant, in their own words from: Surveys Social Media Posts Call Center Transcripts Email Correspondence Homework/Training Exercises 8
Program Survey Feedback F A R D Test Phrase cost for a single track in Corpus Christi at 200 Cannot retrieve appointments at San Antonio workshop with card Beginner materials in the waiting room in Amarillo - horrible it would be easier for me to be on time if the appointments listed start time There should be a proper copy machine , not that horrible one You need to be more flexible in terms of change of appointment advanced materials would be an improvement as opposed to basic service items there was no choice between advanced and basic exercises on the site The program offering is in need of a serious improvement 9
How can we derive insight from this data?
Methods of Analysis Natural Language Processing Sentiment Analysis Affective Computing Unsupervised Machine Learning Clustering Supervised Machine Learning Ensemble Methods Gradient Boosting Prescriptive Analytics 11
Natural Language Processing: Sentiment Analysis & Affective Computing
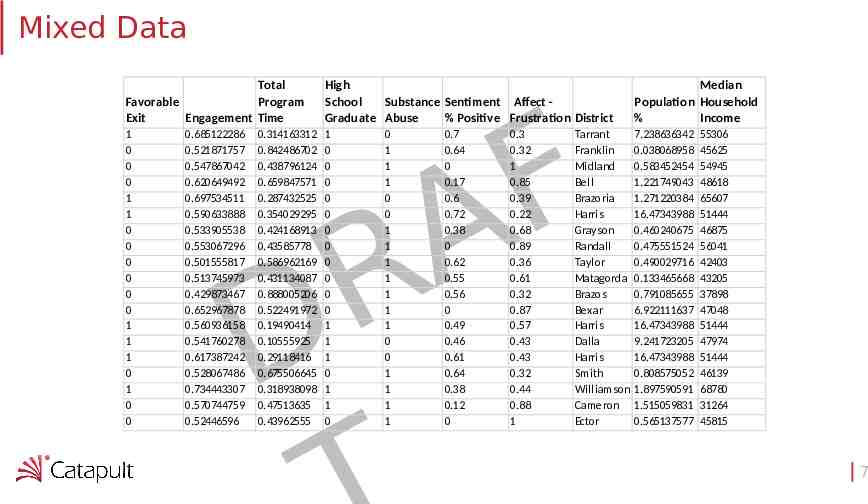
L.I.W.C.“Luke” F A R D Linguistic Inquiry & Word Count 13
LIWC Lexical Categories F A R D 14
V.A.D.E.R. Sentiment Valence Aware Dictionar y And SEntimen t Reasoner F A R D 15
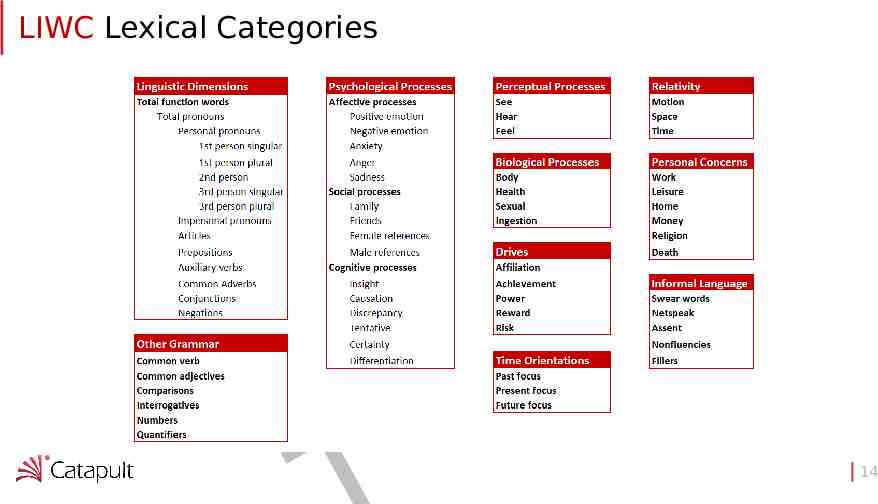
Microsoft Text Analytics API Evaluate how participants feel and what they want F A R D 16
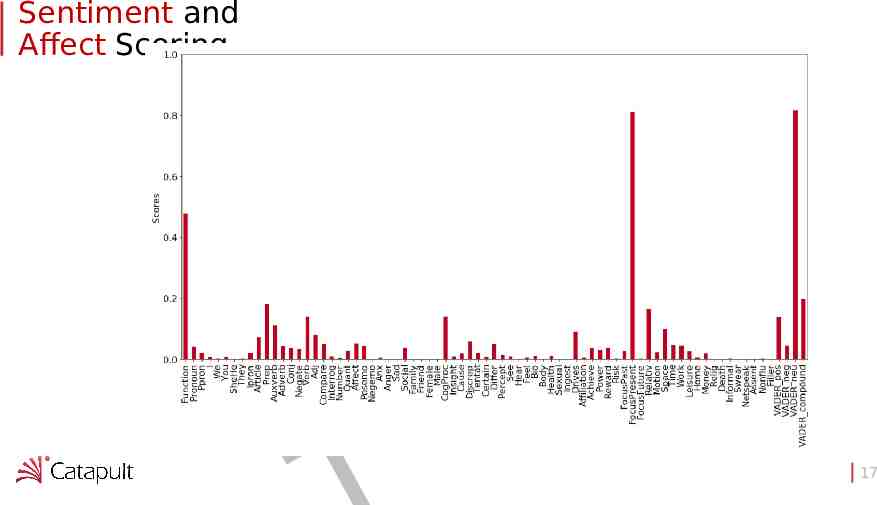
Sentiment and Affect Scoring F A R D 17
Unsupervised Machine Learning (Clustering)
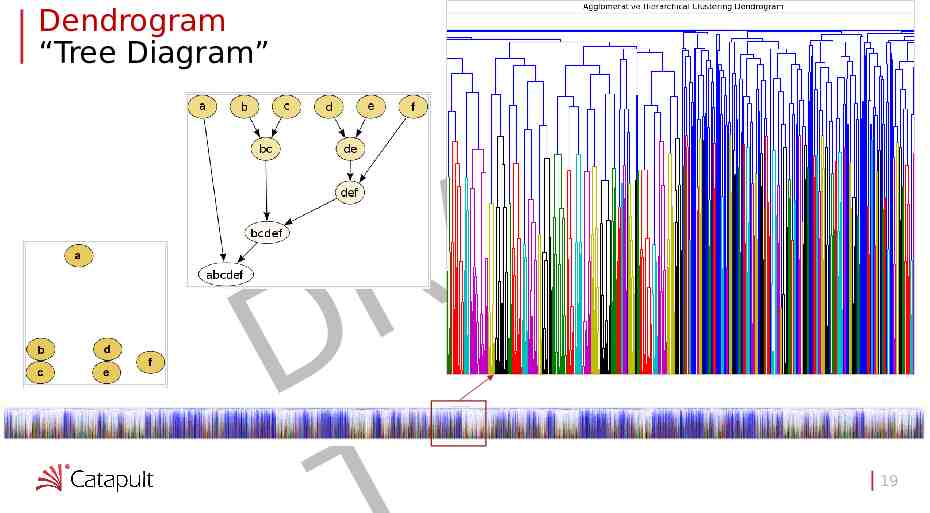
Dendrogram “Tree Diagram” F A R D 19
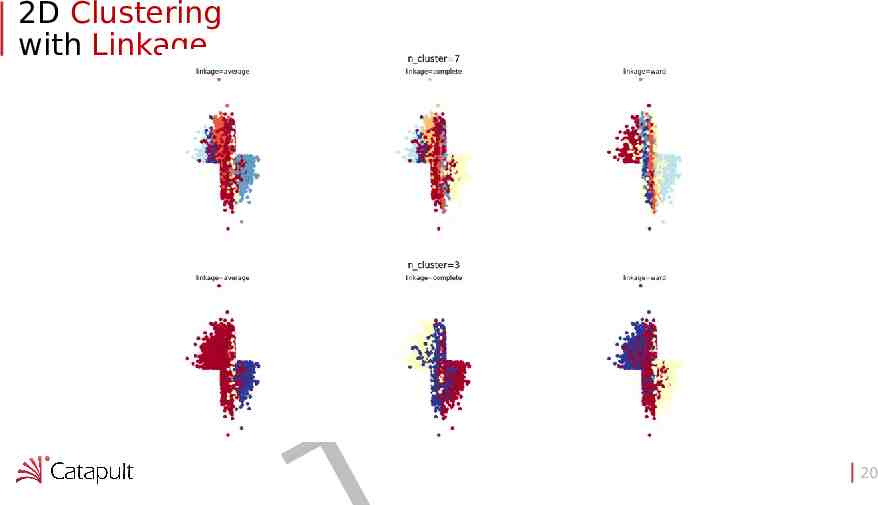
2D Clustering with Linkage F A R D 20
Demo: Interactive 3D Clustering
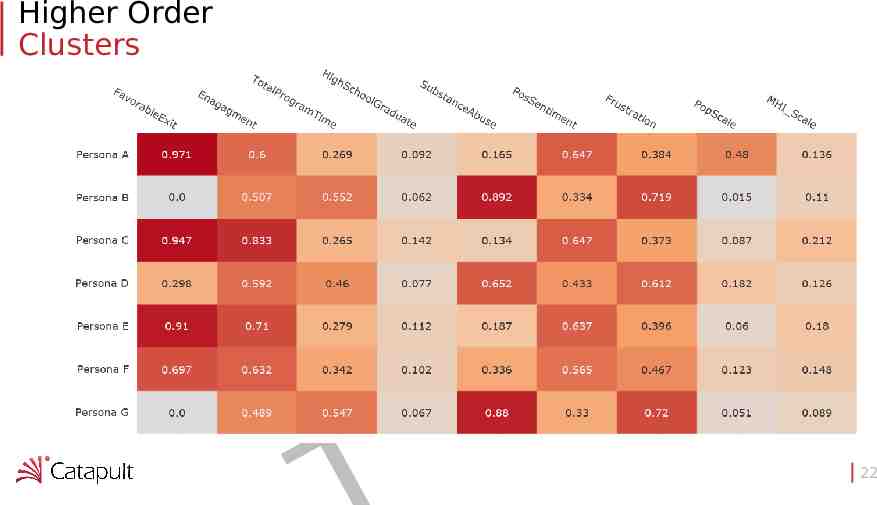
Higher Order Clusters F A R D 22
Ensemble Methods in Supervised Machine Learning For Predictive Analytics (Classification)
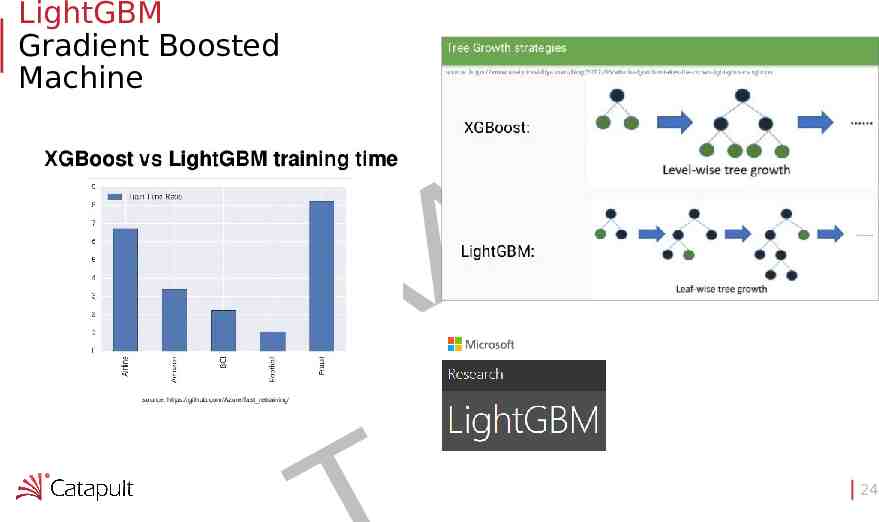
LightGBM Gradient Boosted Machine F A R D 24
Parameter Tuning F A R D 25
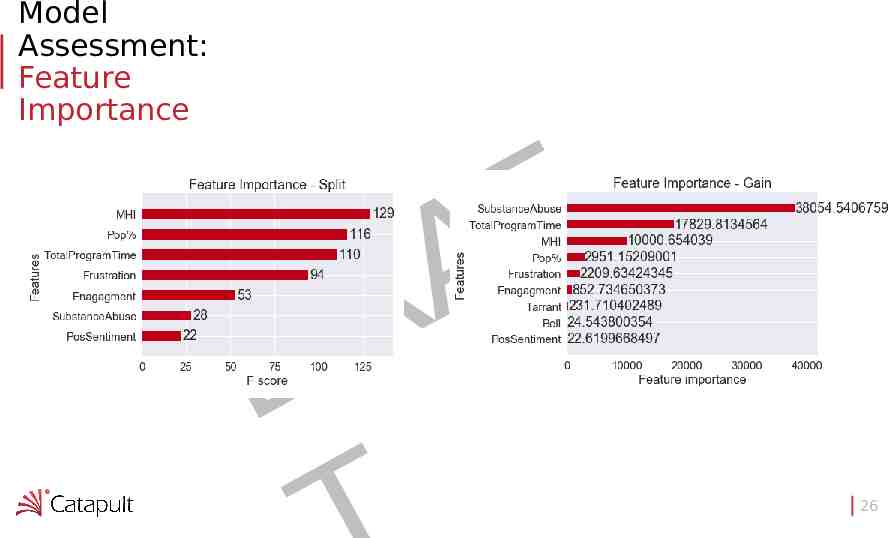
Model Assessment: Feature Importance F A R D 26
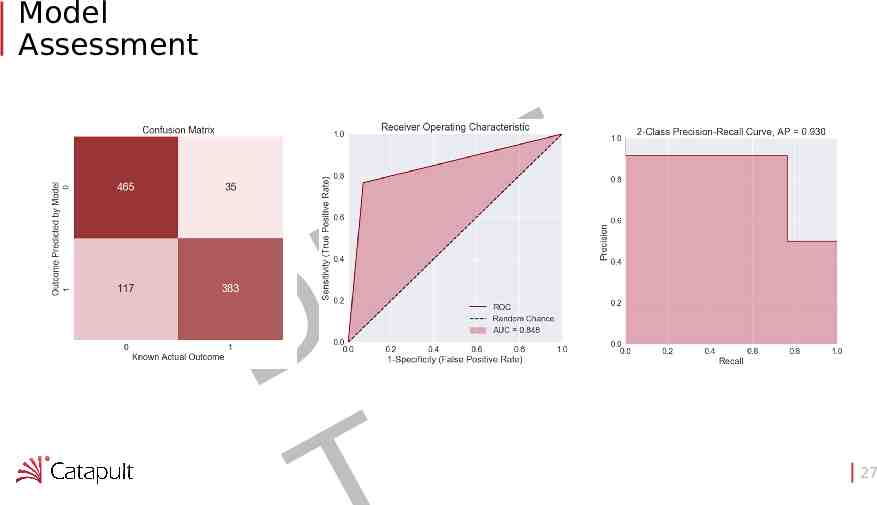
Model Assessment F A R D 27
Prescriptive Analytics How can we change the future?
Prescriptive Analytics F A R D Empirical Controls A/B Testing Cost/Benefit Analysis 29
Demo: Data Visualization for Consumers of Insight
Thank you. Please visit our booth!
Appendices
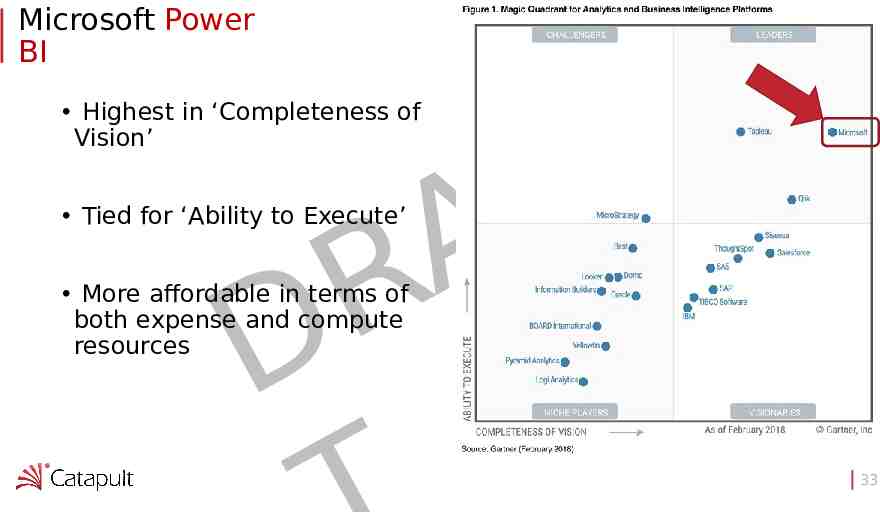
Microsoft Power BI Highest in ‘Completeness of Vision’ F A R D Tied for ‘Ability to Execute’ More affordable in terms of both expense and compute resources 33
How did we do it? Jupyter and Azure Notebooks F A R D 34
Azure Machine Learning F A R D 35
Contact F A R D J D Freeman Data Scientist Digital Solutions Group JDFreeman@catapultsystems .com 512.551.4087 36
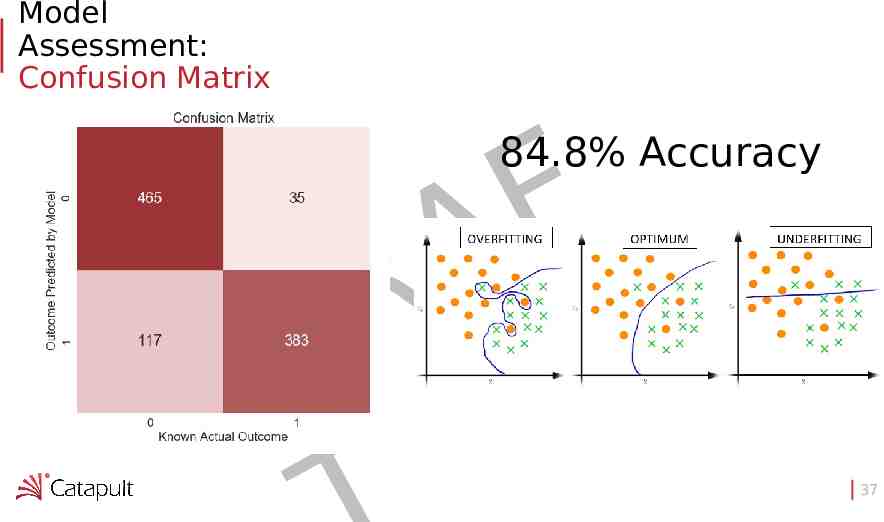
Model Assessment: Confusion Matrix F A R D 84.8% Accuracy 37
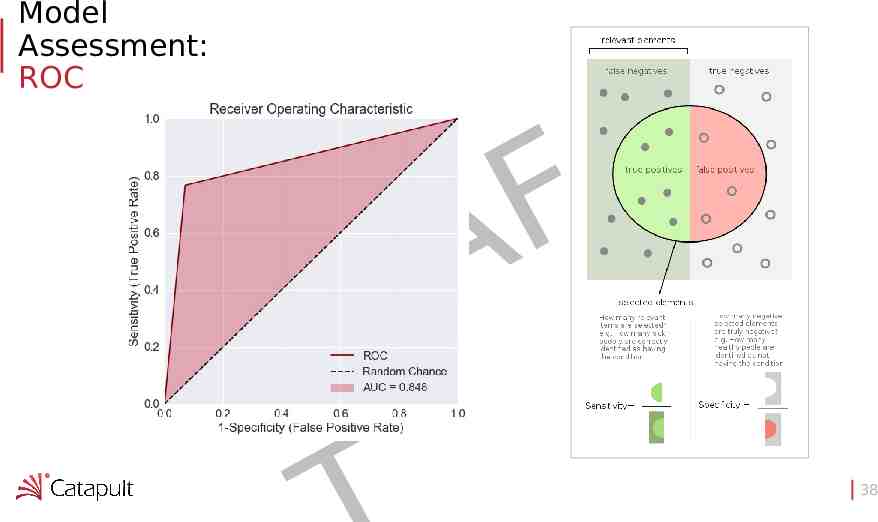
Model Assessment: ROC F A R D 38
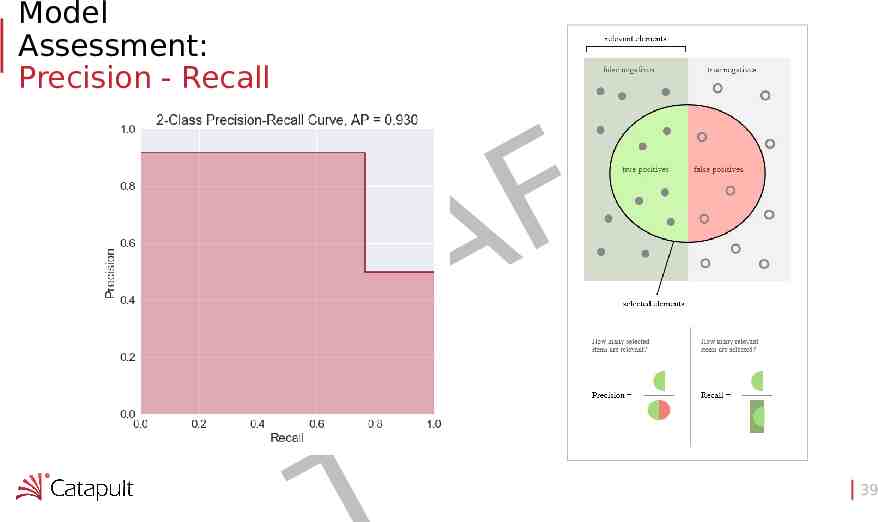
Model Assessment: Precision - Recall F A R D 39
Gradient Boosting F A R D Machine learning technique for regression and classification problems Prediction model in the form of an ensemble of weak prediction models, typically decision trees Builds the model in a stage-wise fashion Generalizes them by allowing optimization of an arbitrary differentiable loss function. 40