Mining Sequential Patterns Rakesh Agrawal & Ramakrishnan Srikant






























34 Slides361.00 KB
Mining Sequential Patterns Rakesh Agrawal & Ramakrishnan Srikant Presented By: Saleha Rizvi Sadia Masud
Outline Introduction Terminology Formal Definition of MSP Finding Sequential Patterns 3 Algorithms Performance Evaluation Conclusion
Introduction X- Y i.e. if ‘x’ exists ‘y’ will also follow in future with specified support. (laptop- battery) When things happen over time and in a sequence All transactions have a timestamp
Introduction Assumptions No more than one transaction at same time. Quantity not important, occurrence of an item is. If a customer bought same item in different transaction but in same sequence its counted only once. Properties: Find inter-transaction patterns Patterns consist of ordered list of items (a, b) ! (b ,a) Patterns need not be consecutive/contiguous e.g. T (a, b, c, d) all (a, c, d) , (a, d), (b, d) are valid sequences of T Element of patterns could be a single item or sets of items
Terminology Transaction: set of items bought at a time customer id, time, items bought Itemset : non-empty set of items eg. itemset I: (i1i2 im), each ij an item Sequence : ordered list of itemsets eg. sequence s s1s2 sn , each si an itemset Example For John Time 1: (laptop, battery) Time 2 : (laptop bag) Time 3 : (Norton Antivirus) D – database of transactions ( t2 ) (laptop bag) Sequence for John becomes (laptop, battery) (laptop bag) (Norton Antivirus)
Terminology Sequence containership: a sequence a1a2 an is contained in another sequence b1b2 bm iff each itemset ‘ai’ is a subset of any itemset of ‘bi’ a (4) (7 9 10) (1 3 6) b (8) (4 2 )(2 7 8 9 10) ( 2 1 4 3 7 9 6) c (4 11) (7 9 10) (1 3 6) a contained in b. c !contained in b d (4)(2) 4 and 2 bought in different transactions e (4,2) 4 and 2 bought in same transaction d not contained in e and vice versa
Terminology Maximal Sequence : not contained in other sequence. a (4) (7 9 10) (1 3 6) not maximal -contained in b c (4) (7 9 10) (1 3 6 5) -maximal b (8) (4 2 )(2 7 8 9 10) ( 2 1 4 3 7 9 6) Customer’s support for sequence : customer supports ‘s’ if ‘s’ contained in customer sequence e.g. John supports sequence ‘r’ but not ‘s’ John’s sequence (laptop, battery) (laptop bag) (Norton Antivirus) r (laptop )(laptop bag) s (laptop )(laptop bag) (notebook cam)
Terminology Support for sequence : Number of customers who support that sequence e.g. database - 100 customer 10 customer support sequence ‘r’ Then, support for sequence r is 10% different from ARM where support is in term of occurrences!! Large Sequence: Sequence satisfying minimum support Length of a sequence: No. of itemsets in a sequence i.e. k-sequence sequence with k itemsets.
Formal definition of MSP Given D (Database of transactions) “Find maximal sequences that meet user specified minimum support”. Involves 2 steps Find all maximal sequences Eliminate those which do not meet minimum support .
Finding Sequential Patterns Solution Sort has 5 Phases Phase Litemset phase Transformation phase Sequence Phase Maximal phase
Sort Phase Sort the Database in ascending order customer id - primary key transaction time - secondary key All transactions belonging to one customer in contiguous tuples. Express the database as a set of customer-sequences.
An Example Customer ID Transactio n time Items 1 1 June 25 ’93 June 30 ’93 30 90 2 2 2 June 10 ’93 June 15 ’93 June 20 ‘93 10,20 30 40,60,70 3 June 25 ’93 30, 50, 70 4 4 4 June 25 ’93 June 30 ’93 June 25 ‘93 30 40,70 90 5 June 12 ’93 90
Example: Customer Sequence Customer ID Customer Sequence 1 2 3 4 5 (30)(90) (10 20 ) (30)(40 60 70) (30 50 70) (30)(40 70)(90) (90) Minimum support 40% 2 customers (30)(90) and (30)(40 70) have min support & maximal Desired Sequential Patterns (30) , (30) (40) , (40)(70) , etc. have min support but not maximal customer sequences with no minimum support : (10 20 )(30) , (30 50 70)
Litemset Phase Some Definitions: Support for an itemset: fraction of customers who bought the items in that itemset in a single transaction; litemset or large itemset: An itemset with minimum support Note: A large sequence must be a list of litemsets (i.e., each itemset inset a of large Find the all litemsets sequence must have minimum support) L (I.e., all large 1-sequences) Large Mapped To Itemsets (30) (40) (70) (40 70) (90) 1 2 3 4 5 Using Apriori Algorithm Note: support count should be incremented only once per customer Map the set of litemsets to a set of contiguous integers (Optimizes time)
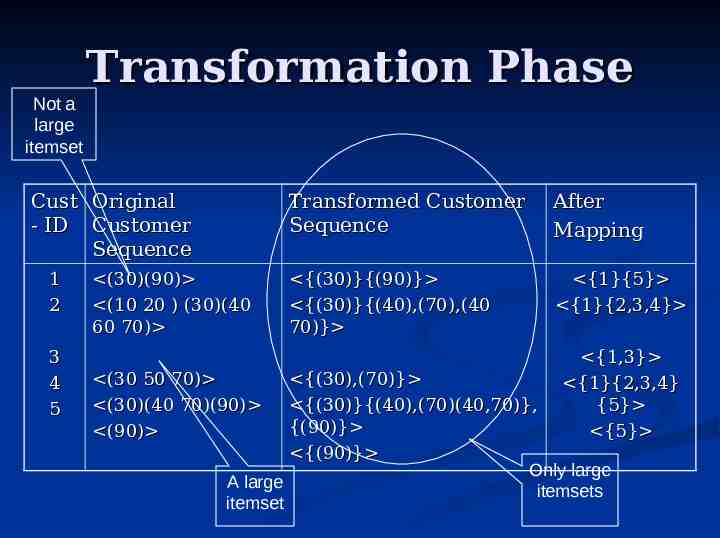
Transformation Phase Each transaction is replaced by the set of all litemsets in that transaction. If no litemsets in a transaction delete transaction. If a customer sequence does not contain any large itemset delete Note: it still counts towards total number of customers. Each litemset is then replaced by its mapped integer from litemset phase
Not a large itemset Transformation Phase Cust Original - ID Customer Sequence 1 2 3 4 5 (30)(90) (10 20 ) (30)(40 60 70) (30 50 70) (30)(40 70)(90) (90) Transformed Customer Sequence After Mapping {(30)}{(90)} {(30)}{(40),(70),(40 70)} {1}{5} {1}{2,3,4} {1,3} {1}{2,3,4} {5} {5} {(30),(70)} {(30)}{(40),(70)(40,70)}, {(90)} {(90)} Only large A large itemsets itemset
Sequence Phase Use the litemsets from transformed DB to find the desired sequences To achieve this: Multiple passes over data In each pass use the large sequences from the previous pass to generate new potentially large sequences/candidate sequences (like ARM). Find support count for candidate sequences End of pass find which of these candidate sequences are actually large/meet minimum support.
Maximal Phase Find the maximal sequences among the set of large sequences Often combined with the Sequence Phase S set of all large sequences, n length of the longest sequence Algorithm to find maximal sequences:
Sequence Phase: Detailed Two Approaches Count All : Includes Counting of non-maximal sequences Pruned out in Maximal Phase Count Some : Count Only maximal sequences; avoid counting nonmaximal sequences. (No Maximal Phase).
Sequence Phase (Contd.) Three Algorithms: AprioriAll (Count All) AprioriSome (Count Some) DynamicSome (Count Some)
Algorithm AprioriAll In the first pass, output of litemset phase is used to initialize the set of large 1-sequences
AprioriAll Candidate Generation Apriori-generate function: Join step: join Lk-1 with Lk-1 Prune step: delete all sequences c in Ck such that some (k-1)subsequence of c is not in Lk-1 Eg. 1 2 4 3 is pruned because 2 4 3 is not in L3
Another Example Minimum support 40% (i.e., 2 customer sequences) Get L1, L2, L3, L4 from Sequence Phase Maximal Phase: Get the maximal large sequences: 1 2 3 4 , 1 3 5 and 4 5 Seq. Patterns
AprioriSome Two Phases Forward Count candidate sequences of certain length Backward Delete non-maximal sequences Count candidates of lengths not in forward phase Delete non-maximal sequences from forward phase
DynamicSome Three Phases Forward Intermediate Phase Count candidate sequences of certain length Generate candidates from large sequences and database (customer sequences) –On the fly candidate generation Backward Delete non-maximal candidates from forward phase Count candidate sequences of lengths not used in forward phase. Delete non-maximal candidate sequences from backward phase
Candidate Generation Difference in Candidate Generation AprioriAll- counts all length candidates/sequences (non-maximal too) AprioriSome- counts some length sequences based on previous large ones. Prunes non-maximal sequences DynamicSome-generate candidates using large sequences and database (customer sequences). Doesn’t prune the nonmaximal sequences
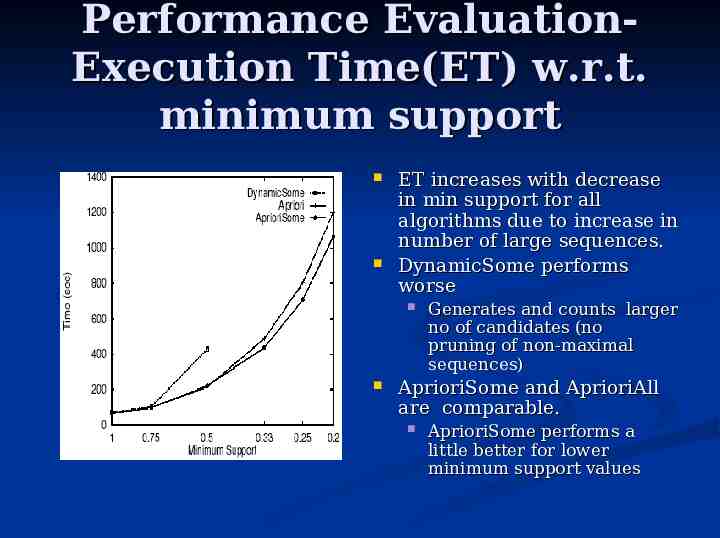
Performance EvaluationExecution Time(ET) w.r.t. minimum support ET increases with decrease in min support for all algorithms due to increase in number of large sequences. DynamicSome performs worse Generates and counts larger no of candidates (no pruning of non-maximal sequences) AprioriSome and AprioriAll are comparable. AprioriSome performs a little better for lower minimum support values
Performance Evaluation Contd. AprioriAll counts all large sequences,including non-maximal sequences (which are later pruned out); AprioriSome avoids counting many nonmaximal sequences by counting longer sequences first (major advantage over AprioriAll)
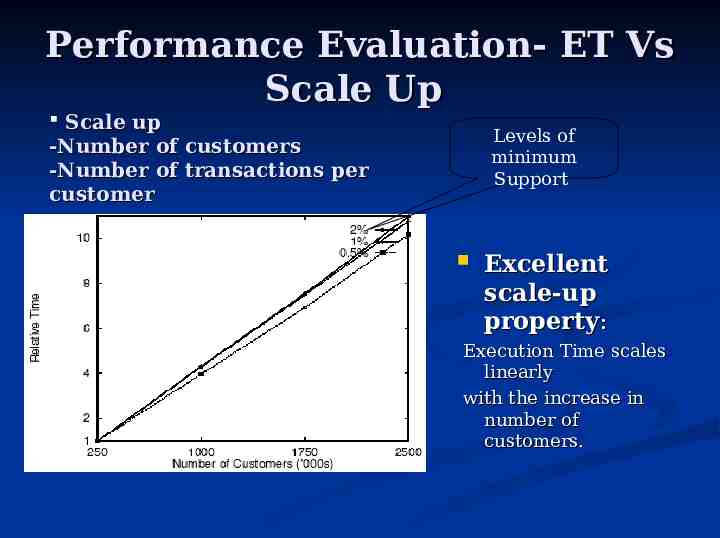
Performance Evaluation- ET Vs Scale Up Scale up -Number of customers -Number of transactions per customer Levels of minimum Support Excellent scale-up property: Execution Time scales linearly with the increase in number of customers.
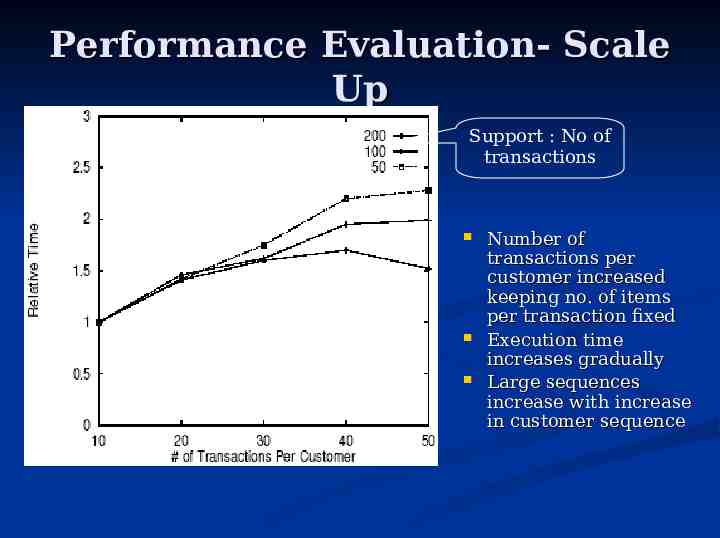
Performance Evaluation- Scale Up Support : No of transactions Number of transactions per customer increased keeping no. of items per transaction fixed Execution time increases gradually Large sequences increase with increase in customer sequence
MSP vs ARM Similarities In both the cases we mine patterns of the form X- Y which means if X exists Y also exists with certain support Dissimilarities Order is important in MSP but not in ARM ARM intra transaction MSP inter transaction (over a period) ARM no timestamp
Application of MSP Discovering frequent buying patterns Large Retail Organizations, Catalog Companies, etc. Analysis of patients medical records /predict sequential symptoms of a disease Web-access pattern
Conclusion Advantage Complete: finds ALL sequential patterns Scaling: can handle very large databases with millions of customer sequences Disadvantage Can’t find patterns related to items of interest (i.e. CAR) Future Extensions Sequential Patterns across item categories Transposition of constraints into the discovery item constraints: sequential patterns with specific items Time constraints: minimum and maximum gap between adjacent elements of the patterns
References R.Agrawal and R.Srikant. Mining Sequential Patterns.In Proc. Of thr 11th Int’l Conference on Data Engineering, Taipei, Taiwan, March 1995. R.Agrawal and R.Srikant .Mining Sequential Patterns: Generalizations and Performance Improvement Proceedings of the 5th International Conference on Extending Database Technology: Advances in Database Technology, ,Avignon, France, March 25-29, 1996 M Wojciechowski . Discovering and Processing Sequential Patterns in Databases.VII Conference on Extending Database Technology - PhD Workshop, Konstanz, Germany, 2000.






