MapReduce: Simplified Data Processing on Large Cluster Authors:

















28 Slides3.87 MB
MapReduce: Simplified Data Processing on Large Cluster Authors: Jeffrey Dean and Sanjay Ghemawat Presented by: Yang Liu, University of Michigan EECS 582 – W16 1
About the Authors Jeff Dean Sanjay Ghemawat EECS 582 – W16 2
Motivation Challenge at google Input data too large - distributed computing Most computations are straightforward(log processing, inverted index) - boring work Complexity of distributed computing Machine failure Scheduling EECS 582 – W16 3
Solution: MapReduce MapReduce as the distributed programing infrastructure Simple Programming interface: Map Reduce Distributed implementation that hides all the messy details Fault tolerance I/O scheduling parallelization EECS 582 – W16 4
Programming Model Inspired by map and reduce functions in Lisp and other functional programing languages Lisp: Map #‘length’ (() (a) (ab) (abc)) 0123 Reduce #‘ ’ (0 1 2 3) 6 EECS 582 – W16 5
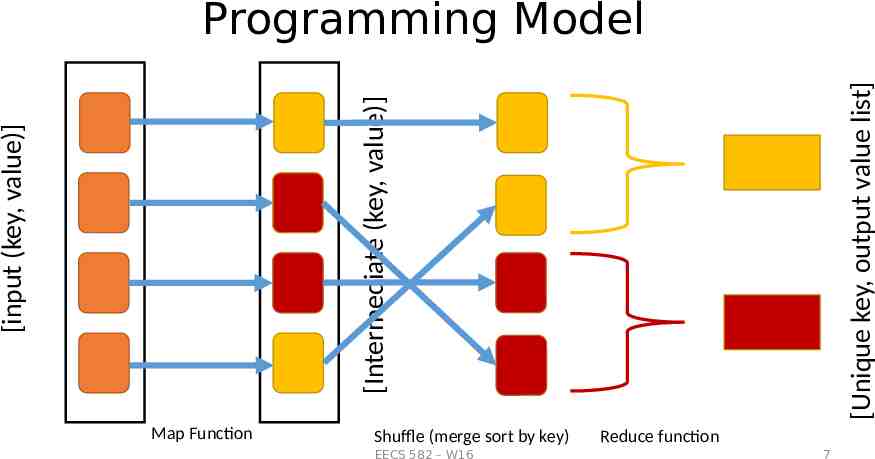
Programing Model Programmer only need to specify two functions: Map Function map (in key, in value) - list(out key, intermediate value) Process input key/value pair Produce set of output key/intermediate value pairs Reduce Function reduce (out key, intermediate value) - list(out value) Process intermediate key/value pairs Combines intermediate values per unique key Produce a set of merged output values(usually just one) EECS 582 – W16 6
[input (key, value)] [Intermediate (key, value)] [Unique key, output value list] Programming Model Map Function Shuffle (merge sort by key) EECS 582 – W16 Reduce function 7
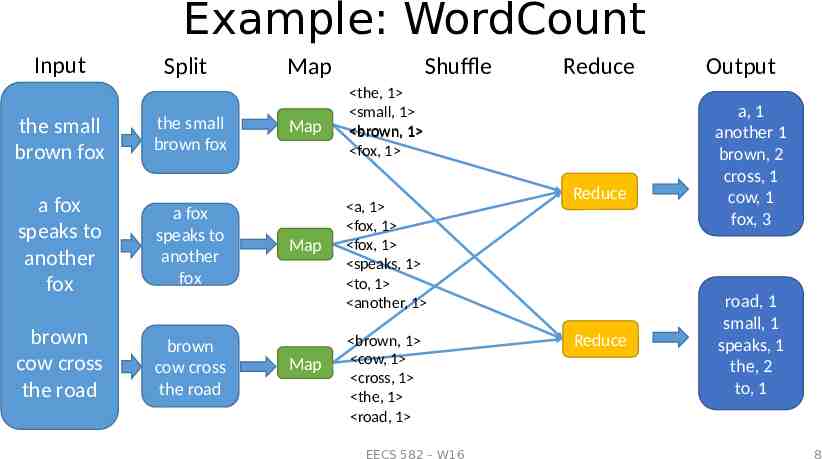
Example: WordCount Input the small brown fox Split the small brown fox a fox speaks to another fox a fox speaks to another fox brown cow cross the road brown cow cross the road Shuffle Map Map Map Map Reduce the, 1 small, 1 brown, 1 fox, 1 a, 1 fox, 1 fox, 1 speaks, 1 to, 1 another, 1 brown, 1 cow, 1 cross, 1 the, 1 road, 1 EECS 582 – W16 Reduce Reduce Output a, 1 another 1 brown, 2 cross, 1 cow, 1 fox, 3 road, 1 small, 1 speaks, 1 the, 2 to, 1 8
More Programs based on MR Inverted Index Distributed Sort Distributed Grep URL Frequency MapReduce Program in Google source tree EECS 582 – W16 9
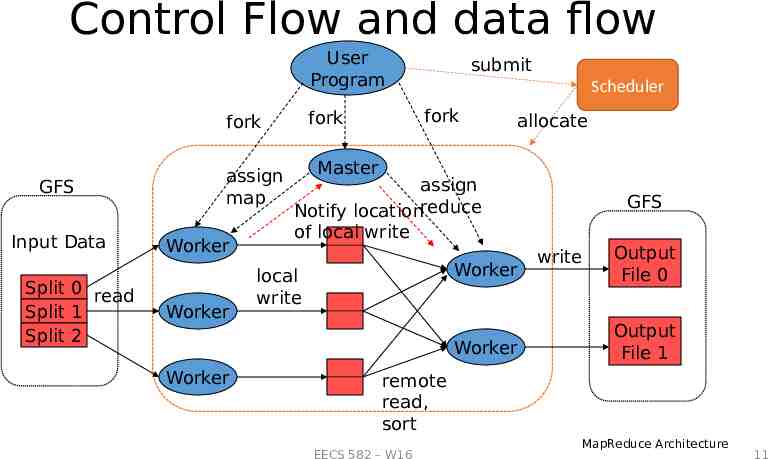
System Implementation: Overview Cluster Characteristic 100s/1000s of 2-CPU x86 machines, 2-4 GB of memory Limited bisection bandwidth Storage is on local IDE disks Infrastructure GFS: distributed file system manages data (SOSP'03) Job scheduling system: jobs made up of tasks, scheduler assigns tasks to machines (Borg?) EECS 582 – W16 10
Control Flow and data flow User Program GFS Input Data Split 0 read Split 1 Split 2 assign map Worker Worker Scheduler fork fork fork submit allocate Master assign Notify locationreduce of local write Worker local write Worker Worker GFS write Output File 0 Output File 1 remote read, sort EECS 582 – W16 MapReduce Architecture 11
Coordinate Master data structures Task status: (idle, in-progress, completed) Idle tasks get scheduled as workers become available When a map task completes, it sends the master the location and sizes of its R intermediate files, one for each reducer Master incrementally pushes this info to reducers Master pings workers periodically to detect failures EECS 582 – W16 14
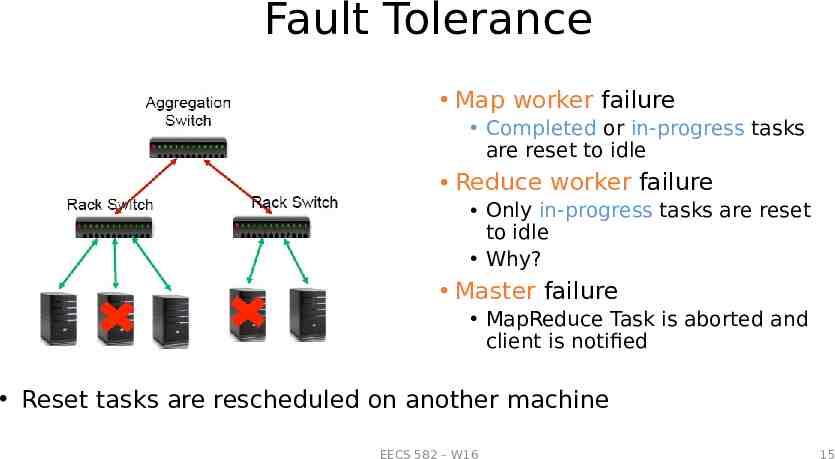
Fault Tolerance Map worker failure Completed or in-progress tasks are reset to idle Reduce worker failure Only in-progress tasks are reset to idle Why? Master failure MapReduce Task is aborted and client is notified Reset tasks are rescheduled on another machine EECS 582 – W16 15
Disk Locality Map tasks are scheduled close to data on nodes that have input data if not, on nodes that are nearer to input data Ex. Same network switch Conserves network bandwidth Leverage the Google File System EECS 582 – W16 18
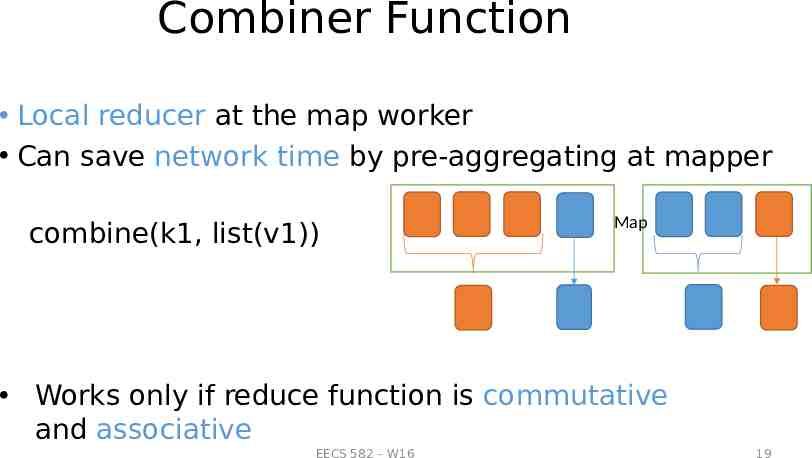
Combiner Function Local reducer at the map worker Can save network time by pre-aggregating at mapper combine(k1, list(v1)) Map Works only if reduce function is commutative and associative EECS 582 – W16 19
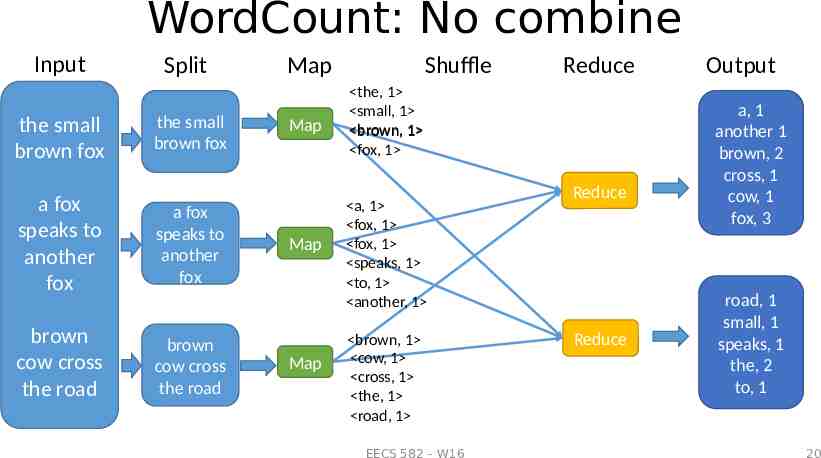
WordCount: No combine Input the small brown fox Split the small brown fox a fox speaks to another fox a fox speaks to another fox brown cow cross the road brown cow cross the road Shuffle Map Map Map Map Reduce the, 1 small, 1 brown, 1 fox, 1 a, 1 fox, 1 fox, 1 speaks, 1 to, 1 another, 1 brown, 1 cow, 1 cross, 1 the, 1 road, 1 EECS 582 – W16 Reduce Reduce Output a, 1 another 1 brown, 2 cross, 1 cow, 1 fox, 3 road, 1 small, 1 speaks, 1 the, 2 to, 1 20
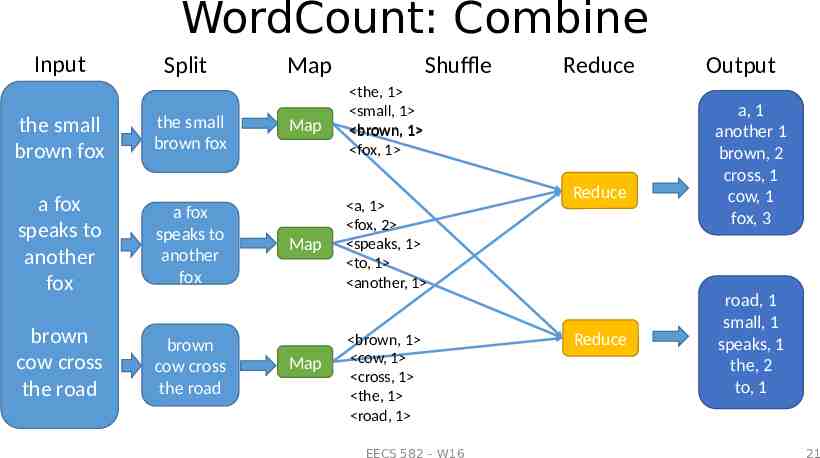
WordCount: Combine Input the small brown fox Split the small brown fox a fox speaks to another fox a fox speaks to another fox brown cow cross the road brown cow cross the road Shuffle Map Map Map Map Reduce the, 1 small, 1 brown, 1 fox, 1 a, 1 fox, 2 speaks, 1 to, 1 another, 1 brown, 1 cow, 1 cross, 1 the, 1 road, 1 EECS 582 – W16 Reduce Reduce Output a, 1 another 1 brown, 2 cross, 1 cow, 1 fox, 3 road, 1 small, 1 speaks, 1 the, 2 to, 1 21
More Features Skipping Bad Records Input and Output Types Local Execution Status Information Counters etc. EECS 582 – W16 23
Conclusion Inexpensive commodity machines can be the basis of a large scale reliable system MapReduce hides all the messy details of distributed computing MapReduce provides a simple parallel programming interface EECS 582 – W16 27
Lessons learn General Design General Abstraction - Solve many problems - Success Simple Interface - Fast Adaption - Success Distributed System design Network is a scarce resource Locality matters Pre-aggregate whenever possible Master-Worker architecture is simple yet powerful EECS 582 – W16 28
Influence MapReduce is one of the MOST cited system paper : 16648 as for 03/08/2016 Together with Google File System, Bigtable, it inspires the Big Data Era What happen after MapReduce? EECS 582 – W16 29
In Open source world: Hadoop 2005: Doug Cutting and Michael J. Cafarella developed Hadoop to support distribution for the Nutch search engine project(invert index) Now: EECS 582 – W16 30
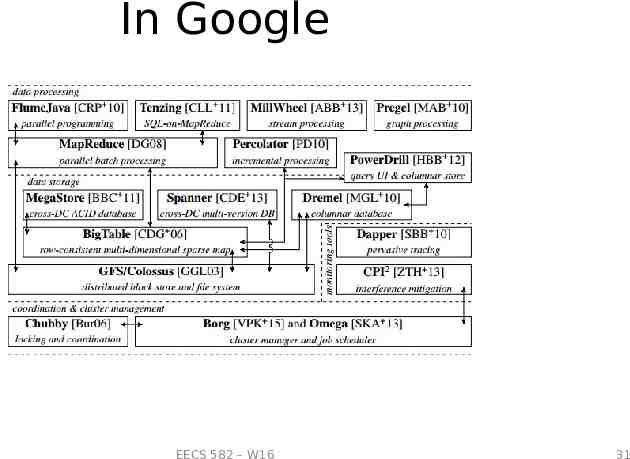
In Google EECS 582 – W16 31
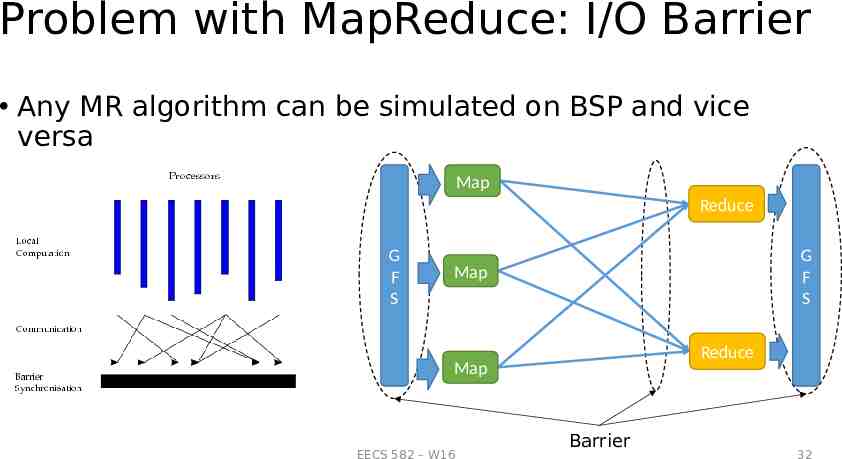
Problem with MapReduce: I/O Barrier Any MR algorithm can be simulated on BSP and vice versa Map Reduce G F S G F S Map Reduce Map EECS 582 – W16 Barrier 32
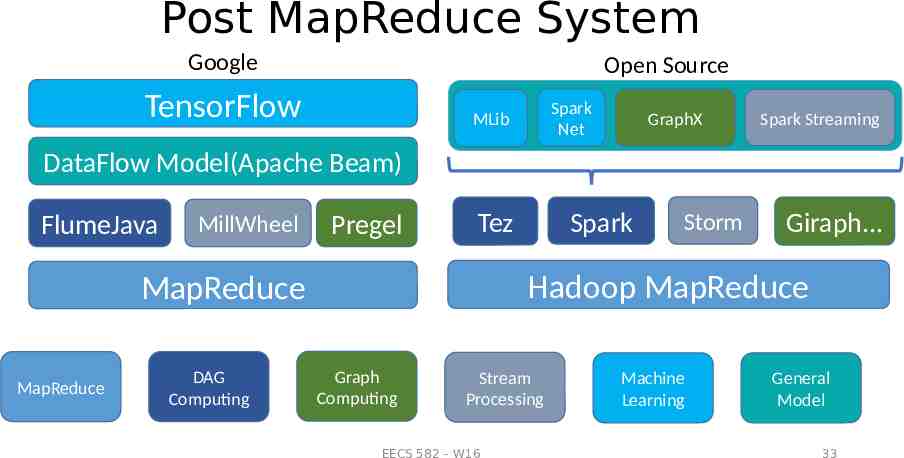
Post MapReduce System Google Open Source TensorFlow Spark Net MLib GraphX Spark Streaming DataFlow Model(Apache Beam) FlumeJava MillWheel Pregel DAG Computing Storm Giraph. Hadoop MapReduce MapReduce MapReduce Spark Tez Graph Computing Stream Processing EECS 582 – W16 Machine Learning General Model 33
Questions? EECS 582 – W16 34
References MapReduce Architecture: http://cecs.wright.edu/ tkprasad/courses/cs707/L06MapReduce.ppt/ MapReduce Presentation: http://research.google.com/archive/mapreduce-osdi04-slides/ MapReduce Presentation: http://web.eecs.umich.edu/ mozafari/fall2015/eecs584/presentations/lecture15-a.pdf/ Operating system support for warehouse-scale computing: https://www.cl.cam.ac.uk/ ms705/pub/thesis-submitted.pdf/ Apache Ecosystem Pic: http://blog.agroknow.com/?cat 1 MapReduce: http://static.googleusercontent.com/media/research.google.com/en// archive/mapreduce-osdi04.pdf/ FlumeJava: http://pages.cs.wisc.edu/ akella/CS838/F12/838-CloudPapers/FlumeJava.pdf/ MillWheel: http://www.vldb.org/pvldb/vol6/p1033-akidau.pdf/ Pregel: http://web.stanford.edu/class/cs347/reading/pregel.pdf/ EECS 582 – W16 35
References Giraph: http://giraph.apache.org/ Spark: http://spark.apache.org/ Tez: https://tez.apache.org/ DataFlow: http://www.vldb.org/pvldb/vol8/p1792-Akidau.pdf/ Tensorflow: https://www.tensorflow.org/ Apache Beam: http://incubator.apache.org/projects/beam.html SparkNet: https://github.com/amplab/SparkNet Caffe on Spark: http:// yahoohadoop.tumblr.com/post/129872361846/large-scale-distributed-deep-lea rning-on-hadoop EECS 582 – W16 36






