Lecture 5 Smaller Network: CNN We know it is good to learn



28 Slides4.81 MB
Lecture 5 Smaller Network: CNN We know it is good to learn a small model. From this fully connected model, do we really need all the edges? Can some of these be shared?
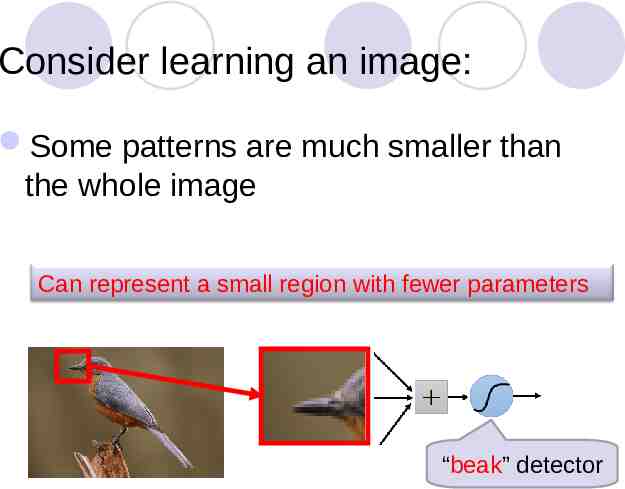
Consider learning an image: Some patterns are much smaller than the whole image Can represent a small region with fewer parameters “beak” detector
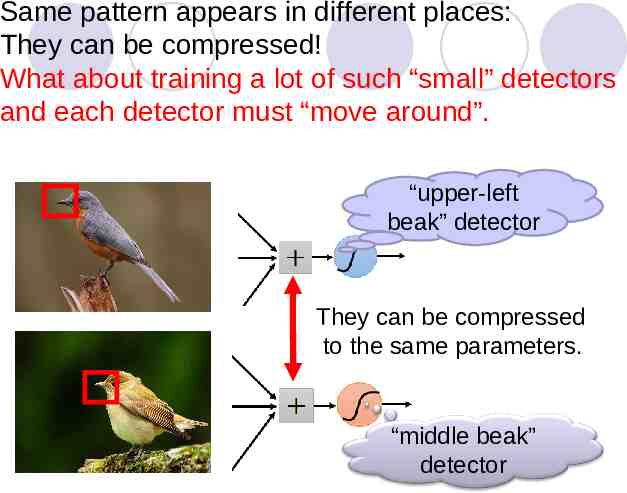
Same pattern appears in different places: They can be compressed! What about training a lot of such “small” detectors and each detector must “move around”. “upper-left beak” detector They can be compressed to the same parameters. “middle beak” detector
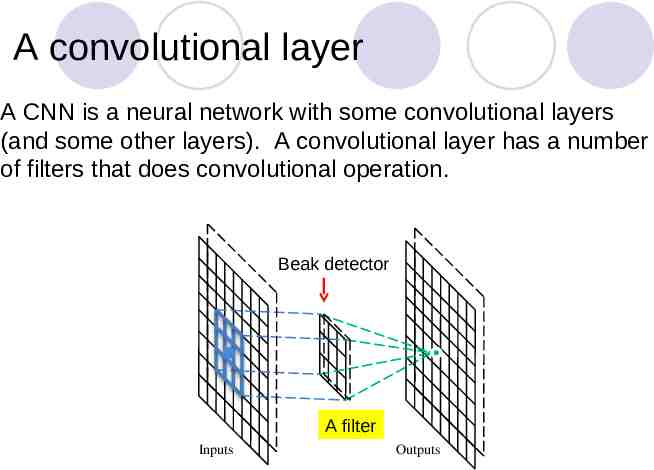
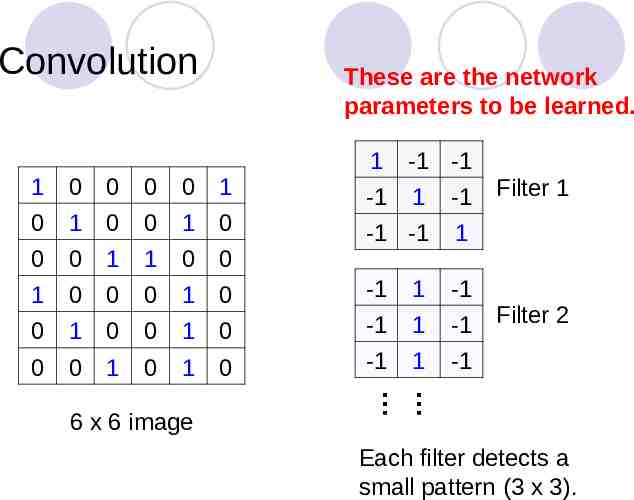
A convolutional layer A CNN is a neural network with some convolutional layers (and some other layers). A convolutional layer has a number of filters that does convolutional operation. Beak detector A filter
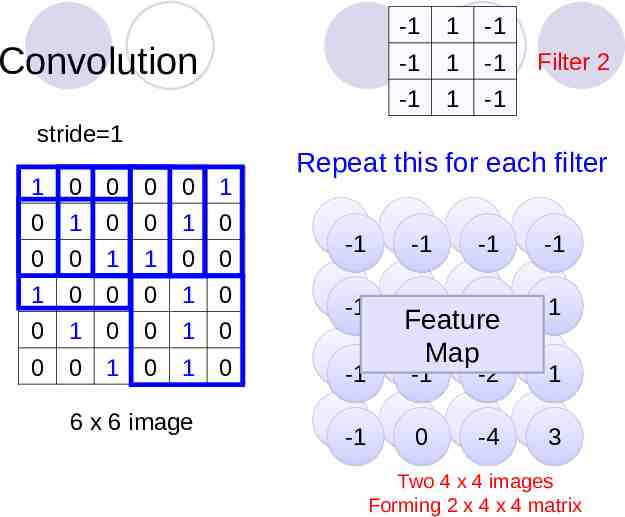
Convolution These are the network parameters to be learned. 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 -1 -1 -1 1 -1 -1 1 0 -1 1 -1 1 -1 Filter 2 1 -1 0 1 0 0 1 0 -1 0 0 1 0 1 0 -1 6 x 6 image -1 Filter 1 Each filter detects a small pattern (3 x 3).
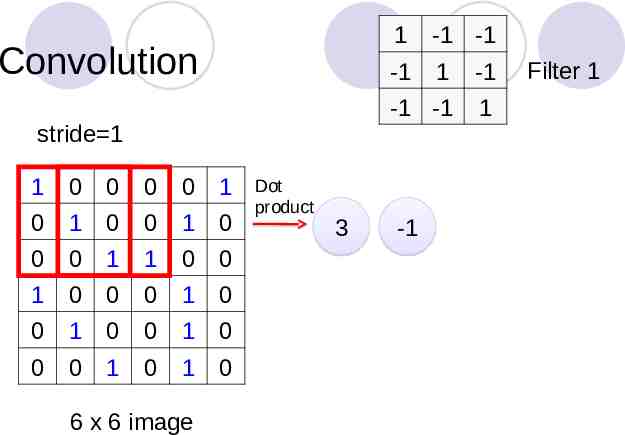
Convolution stride 1 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 6 x 6 image Dot product 3 1 -1 -1 -1 1 -1 -1 -1 1 -1 Filter 1
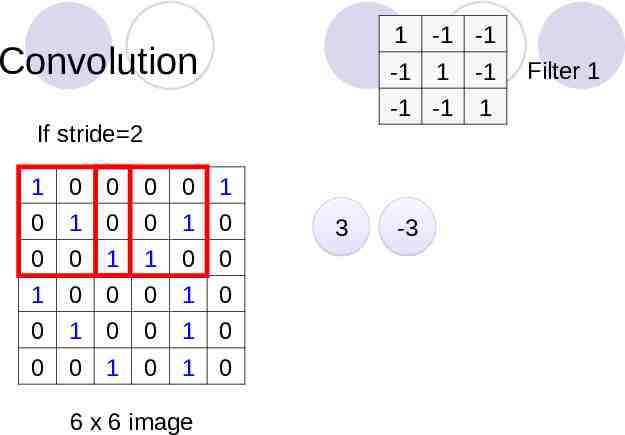
Convolution If stride 2 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 6 x 6 image 3 1 -1 -1 -1 1 -1 -1 -1 1 -3 Filter 1
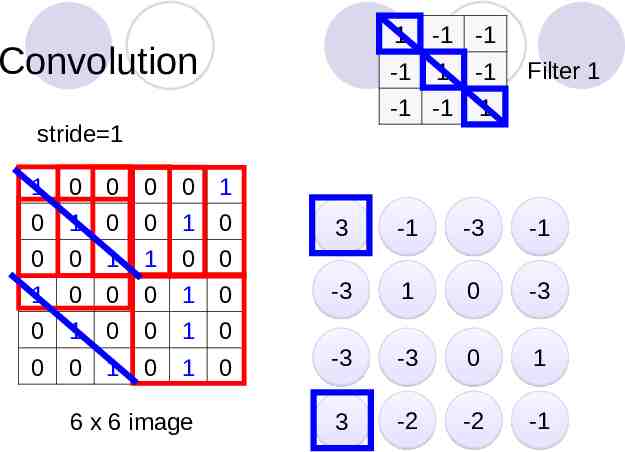
Convolution stride 1 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 6 x 6 image 1 -1 -1 -1 1 -1 -1 -1 1 Filter 1 3 -1 -3 -1 -3 1 0 -3 -3 -3 0 1 3 -2 -2 -1
Convolution stride 1 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 6 x 6 image -1 1 -1 -1 1 -1 -1 1 -1 Filter 2 Repeat this for each filter 3 -1 -1 -1 -3 -1 -1 -1 -3 -1 1 -1 0 -2 -3 1 -3 -1 3 -1 Feature -3 Map 0 -1 -2 -2 0 -2 -4 1 1 -1 3 Two 4 x 4 images Forming 2 x 4 x 4 matrix
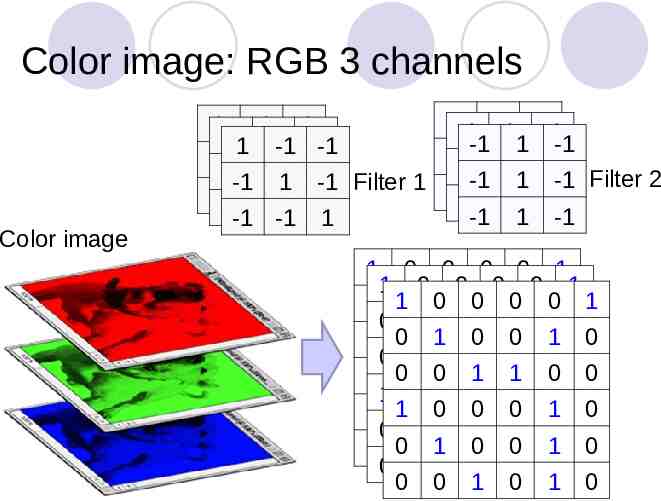
Color image: RGB 3 channels Color image -1-1 11 -1-1 11 -1-1 -1-1 -1 1 -1 1 -1 -1 -1 -1-1 11 -1-1 -1-1 111 -1-1-1 Filter 2 -1 1 -1 Filter 1 -1 1 -1 -1-1 -1-1 11 -1 1 -1 -1 1 -1 -1 -1 1 1 0 0 0 0 1 1 0 0 0 0 1 0 11 00 00 01 00 1 0 1 0 0 1 0 0 00 11 01 00 10 0 0 0 1 1 0 0 1 00 00 10 11 00 0 1 0 0 0 1 0 0 11 00 00 01 10 0 0 1 0 0 1 0 0 00 11 00 01 10 0 0 0 1 0 1 0 0 0 1 0 1 0
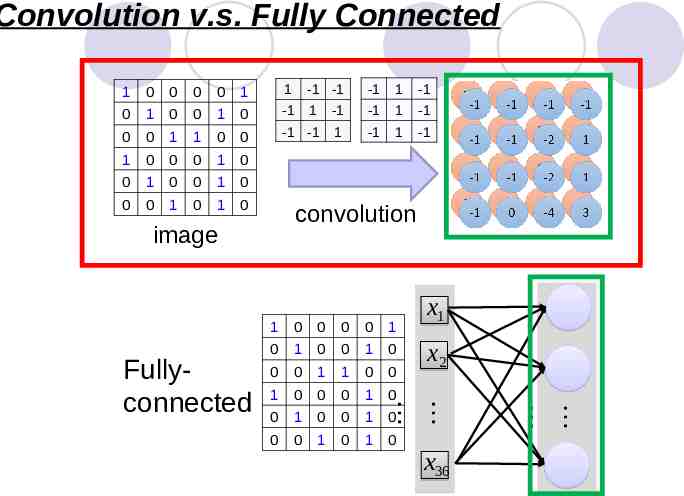
Convolution v.s. Fully Connected -1 1 -1 0 1 -1 -1 -1 1 -1 -1 1 -1 0 0 -1 -1 -1 1 -1 0 1 0 0 0 1 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 1 0 0 1 1 1 0 0 0 1 0 0 convolution image 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 x2 x36 1 x1 Fullyconnected 1
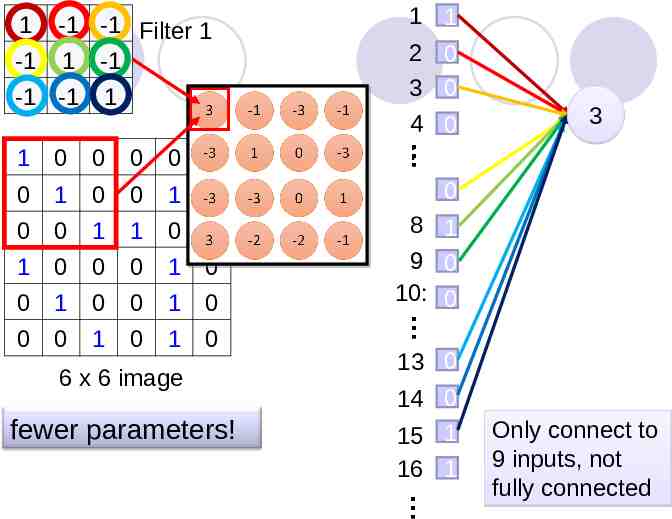
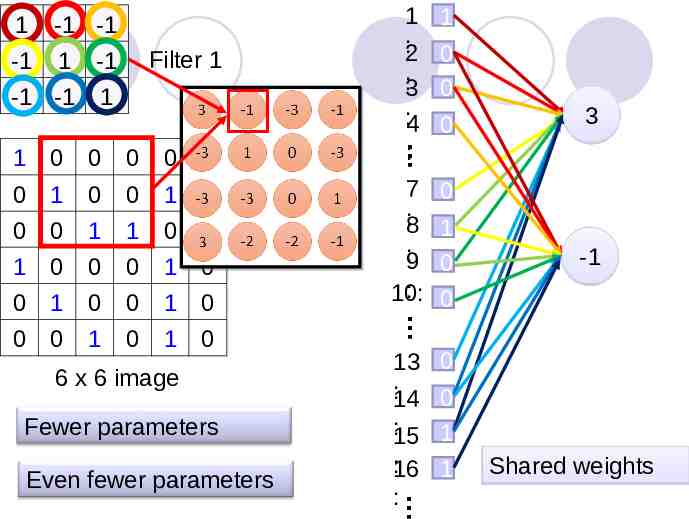
1 1 -1 -1 2 0 3 0 4 0 : -1 -1 Filter 1 -1 1 -1 1 0 0 0 0 1 0 1 0 0 1 0 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 8 1 9 0 10: 0 0 0 1 0 1 0 fewer parameters! 1 6 x 6 image 3 1 13 0 14 0 15 1 16 1 Only connect to 9 inputs, not fully connected
1 -1 -1 -1 1 -1 -1 -1 1 Filter 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 7 0 :8 1 :9 0 : 0 10: 0 0 1 0 1 0 6 x 6 image Fewer parameters Even fewer parameters 3 -1 1 1 1 :2 0 :3 0 :4 0 : 13 0 : 0 14 :15 1 : 16 1 : Shared weights
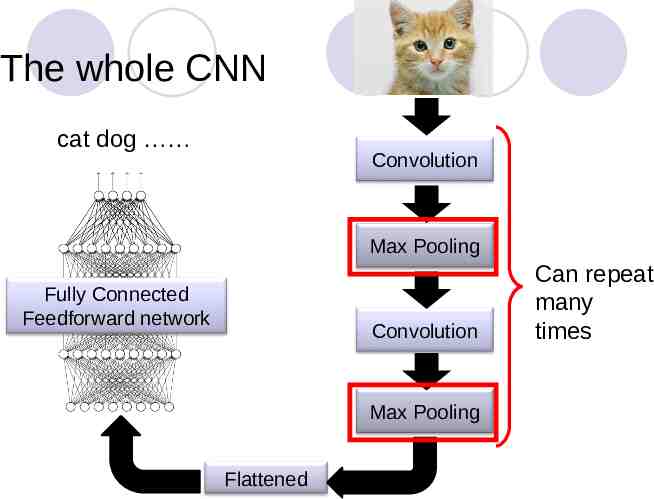
The whole CNN cat dog Convolution Max Pooling Fully Connected Feedforward network Convolution Max Pooling Flattened Can repeat many times
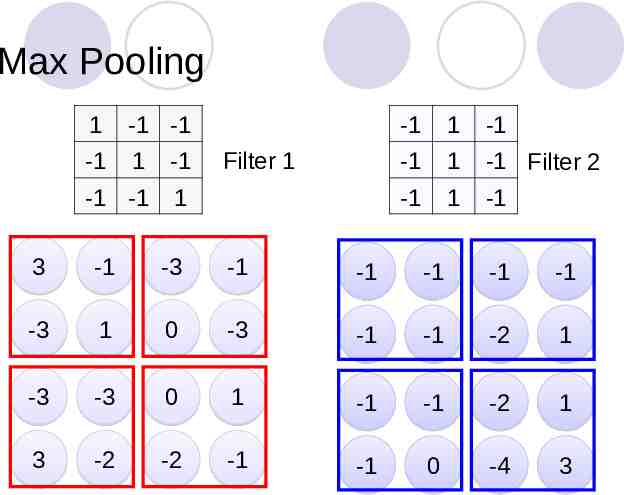
Max Pooling 1 -1 -1 -1 1 -1 -1 -1 1 Filter 1 -1 1 -1 -1 1 -1 1 -1 Filter 2 -1 3 -1 -3 -1 -1 -1 -1 -1 -3 1 0 -3 -1 -1 -2 1 -3 -3 0 1 -1 -1 -2 1 3 -2 -2 -1 -1 0 -4 3
Why Pooling Subsampling pixels will not change the object bird bird Subsampling We can subsample the pixels to make image smaller fewer parameters to characterize the image
A CNN compresses a fully connected network in two ways: Reducing number of connections Shared weights on the edges Max pooling further reduces the complexity
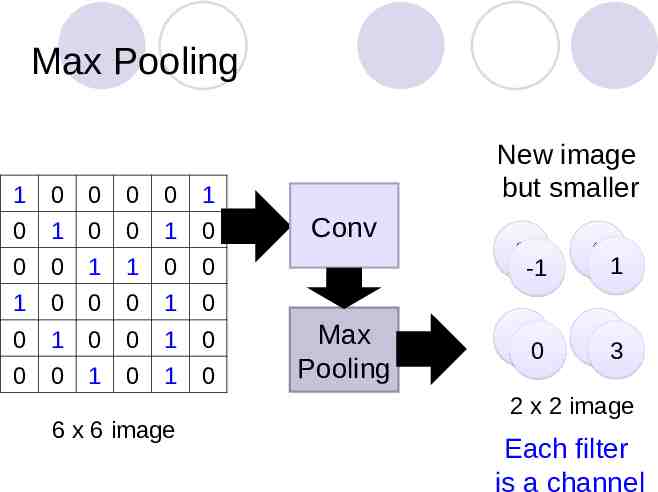
Max Pooling 1 0 0 0 0 1 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 1 0 6 x 6 image New image but smaller Conv Max Pooling 3 -1 0 30 13 1 2 x 2 image Each filter is a channel
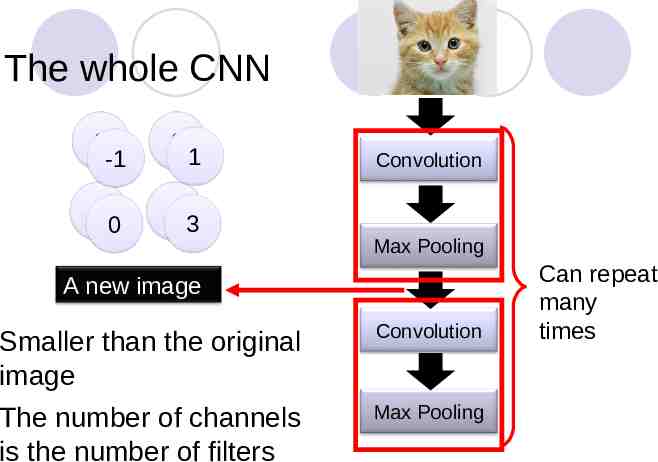
The whole CNN 3 -1 0 3 0 1 3 1 Convolution Max Pooling A new image Smaller than the original image The number of channels is the number of filters Convolution Max Pooling Can repeat many times
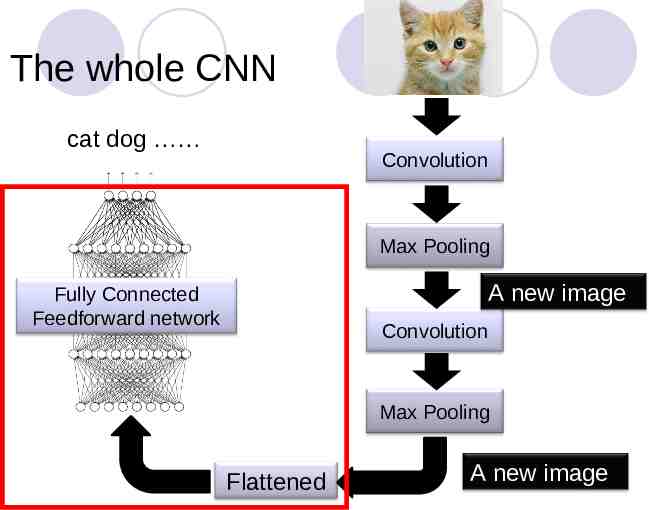
The whole CNN cat dog Convolution Max Pooling A new image Fully Connected Feedforward network Convolution Max Pooling Flattened A new image
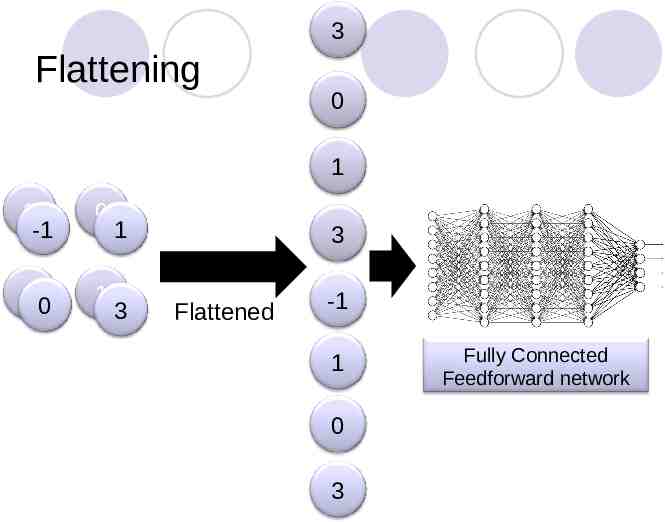
3 Flattening 0 1 3 -1 0 30 1 1 3 3 Flattened -1 1 0 3 Fully Connected Feedforward network
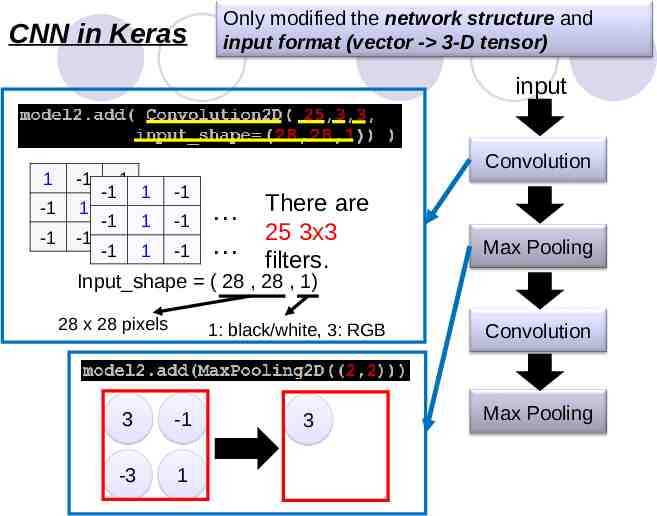
CNN in Keras Only modified the network structure and input format (vector - 3-D tensor) input 1 -1 -1 -1 -1 -1 1 1 -1 -1 1 -1 1 -1 1 Convolution -1 -1 -1 There are 25 3x3 filters. Max Pooling Input shape ( 28 , 28 , 1) 28 x 28 pixels 1: black/white, 3: RGB 3 -1 -3 1 3 Convolution Max Pooling
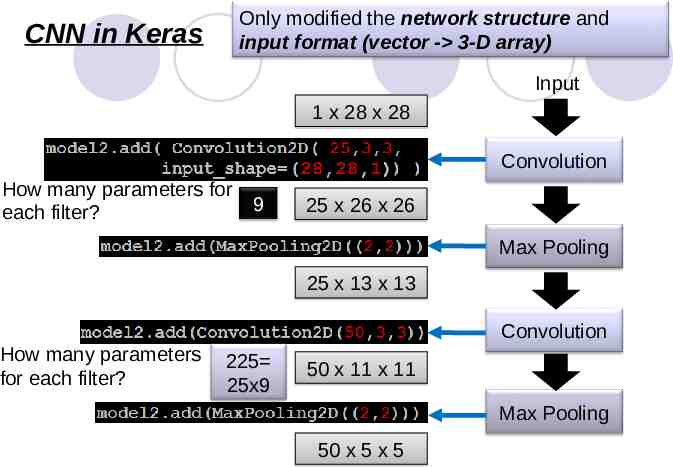
Only modified the network structure and input format (vector - 3-D array) CNN in Keras Input 1 x 28 x 28 Convolution How many parameters for each filter? 9 25 x 26 x 26 Max Pooling 25 x 13 x 13 Convolution How many parameters for each filter? 225 25x9 50 x 11 x 11 Max Pooling 50 x 5 x 5
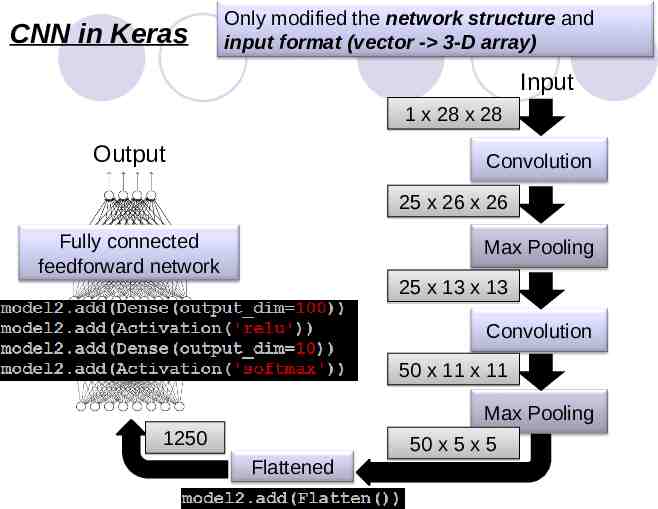
CNN in Keras Only modified the network structure and input format (vector - 3-D array) Input 1 x 28 x 28 Output Convolution 25 x 26 x 26 Fully connected feedforward network Max Pooling 25 x 13 x 13 Convolution 50 x 11 x 11 Max Pooling 1250 Flattened 50 x 5 x 5
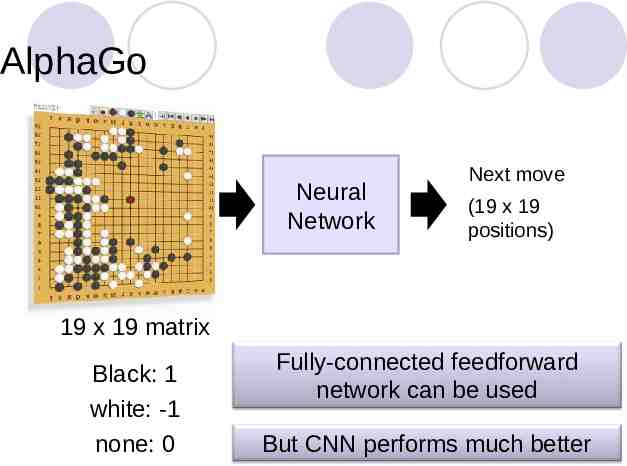
AlphaGo Neural Network Next move (19 x 19 positions) 19 x 19 matrix Black: 1 white: -1 none: 0 Fully-connected feedforward network can be used But CNN performs much better
AlphaGo’s policy network The following is quotation from their Nature article: Note: AlphaGo does not use Max Pooling.
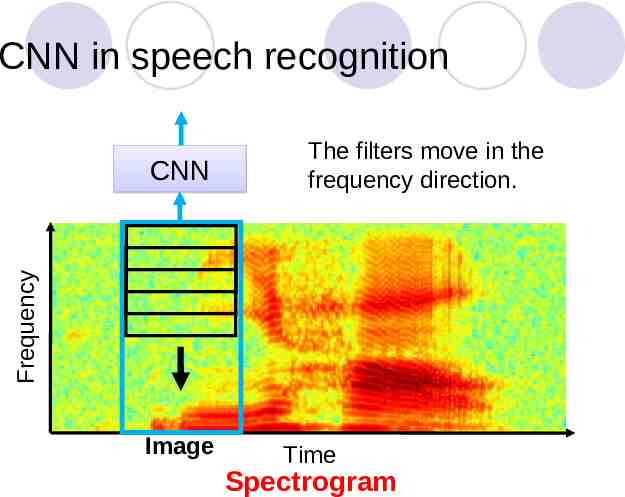
CNN in speech recognition Frequency CNN The filters move in the frequency direction. Image Time Spectrogram
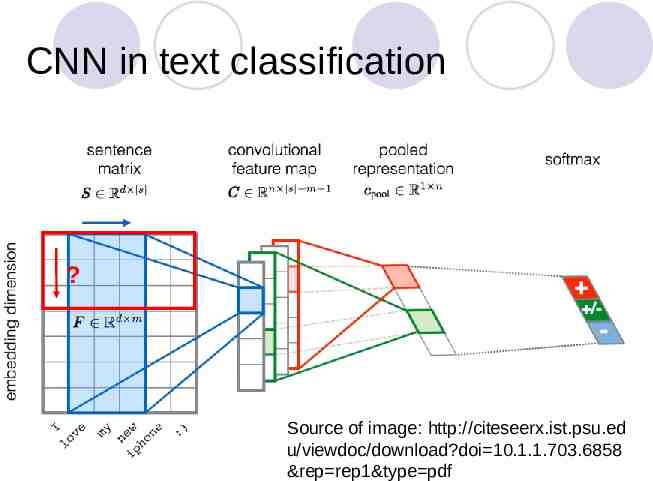
CNN in text classification ? Source of image: http://citeseerx.ist.psu.ed u/viewdoc/download?doi 10.1.1.703.6858 &rep rep1&type pdf





