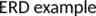Introduction to Hadoop Owen O’Malley Yahoo!, Grid Team owen@yahoo-inc


















22 Slides1,009.50 KB
Introduction to Hadoop Owen O’Malley Yahoo!, Grid Team [email protected]
Problem How do you scale up applications? – Run jobs processing 100’s of terabytes of data – Takes 11 days to read on 1 computer Need lots of cheap computers – Fixes speed problem (15 minutes on 1000 computers), but – Reliability problems In large clusters, computers fail every day Cluster size is not fixed Need common infrastructure – Must be efficient and reliable CCA – Oct 2008
Solution Open Source Apache Project Hadoop Core includes: – Distributed File System - distributes data – Map/Reduce - distributes application Written in Java Runs on – Linux, Mac OS/X, Windows, and Solaris – Commodity hardware CCA – Oct 2008
Commodity Hardware Cluster Typically in 2 level architecture – Nodes are commodity PCs – 40 nodes/rack – Uplink from rack is 8 gigabit – Rack-internal is 1 gigabit CCA – Oct 2008
Distributed File System Single namespace for entire cluster – Managed by a single namenode. – Files are single-writer and append-only. – Optimized for streaming reads of large files. Files are broken in to large blocks. – Typically 128 MB – Replicated to several datanodes, for reliability Client talks to both namenode and datanodes – Data is not sent through the namenode. – Throughput of file system scales nearly linearly with the number of nodes. Access from Java, C, or command line. CCA – Oct 2008
Block Placement Default is 3 replicas, but settable Blocks are placed (writes are pipelined): – On same node – On different rack – On the other rack Clients read from closest replica If the replication for a block drops below target, it is automatically re-replicated. CCA – Oct 2008
Data Correctness Data is checked with CRC32 File Creation – Client computes checksum per 512 byte – DataNode stores the checksum File access – Client retrieves the data and checksum from DataNode – If Validation fails, Client tries other replicas Periodic Validation CCA – Oct 2008
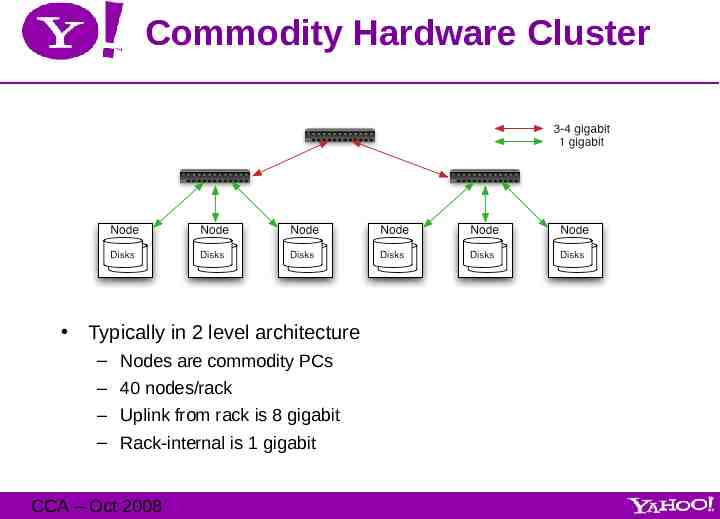
Map/Reduce Map/Reduce is a programming model for efficient distributed computing It works like a Unix pipeline: – cat input grep sort uniq -c cat output – Input Map Shuffle & Sort Reduce Output Efficiency from – Streaming through data, reducing seeks – Pipelining A good fit for a lot of applications – Log processing – Web index building CCA – Oct 2008
Map/Reduce Dataflow CCA – Oct 2008
Map/Reduce features Java and C APIs – In Java use Objects, while in C bytes Each task can process data sets larger than RAM Automatic re-execution on failure – In a large cluster, some nodes are always slow or flaky – Framework re-executes failed tasks Locality optimizations – Map-Reduce queries HDFS for locations of input data – Map tasks are scheduled close to the inputs when possible CCA – Oct 2008
How is Yahoo using Hadoop? We started with building better applications – Scale up web scale batch applications (search, ads, ) – Factor out common code from existing systems, so new applications will be easier to write – Manage the many clusters we have more easily The mission now includes research support – Build a huge data warehouse with many Yahoo! data sets – Couple it with a huge compute cluster and programming models to make using the data easy – Provide this as a service to our researchers – We are seeing great results! Experiments can be run much more quickly in this environment CCA – Oct 2008
Running Production WebMap Search needs a graph of the “known” web – Invert edges, compute link text, whole graph heuristics Periodic batch job using Map/Reduce – Uses a chain of 100 map/reduce jobs Scale – 1 trillion edges in graph – Largest shuffle is 450 TB – Final output is 300 TB compressed – Runs on 10,000 cores – Raw disk used 5 PB Written mostly using Hadoop’s C interface CCA – Oct 2008
Research Clusters The grid team runs the research clusters as a service to Yahoo researchers Mostly data mining/machine learning jobs Most research jobs are *not* Java: – 42% Streaming Uses Unix text processing to define map and reduce – 28% Pig Higher level dataflow scripting language – 28% Java – 2% C CCA – Oct 2008
NY Times Needed offline conversion of public domain articles from 1851-1922. Used Hadoop to convert scanned images to PDF Ran 100 Amazon EC2 instances for around 24 hours 4 TB of input 1.5 TB of output Published 1892, copyright New York Times CCA – Oct 2008
Terabyte Sort Benchmark Started by Jim Gray at Microsoft in 1998 Sorting 10 billion 100 byte records Hadoop won the general category in 209 seconds – 910 nodes – 2 quad-core Xeons @ 2.0Ghz / node – 4 SATA disks / node – 8 GB ram / node – 1 gb ethernet / node – 40 nodes / rack – 8 gb ethernet uplink / rack Previous records was 297 seconds Only hard parts were: – Getting a total order – Converting the data generator to map/reduce CCA – Oct 2008
Hadoop clusters We have 20,000 machines running Hadoop Our largest clusters are currently 2000 nodes Several petabytes of user data (compressed, unreplicated) We run hundreds of thousands of jobs every month CCA – Oct 2008
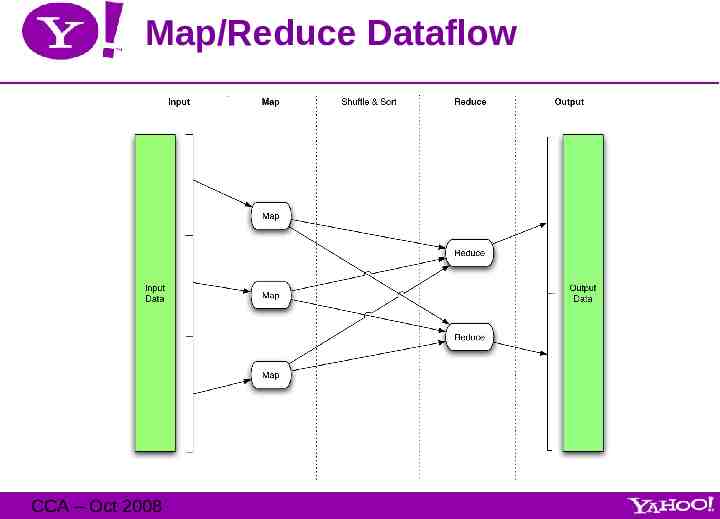
Research Cluster Usage CCA – Oct 2008
Hadoop Community Apache is focused on project communities – Users – Contributors write patches – Committers can commit patches too – Project Management Committee vote on new committers and releases too Apache is a meritocracy Use, contribution, and diversity is growing – But we need and want more! CCA – Oct 2008
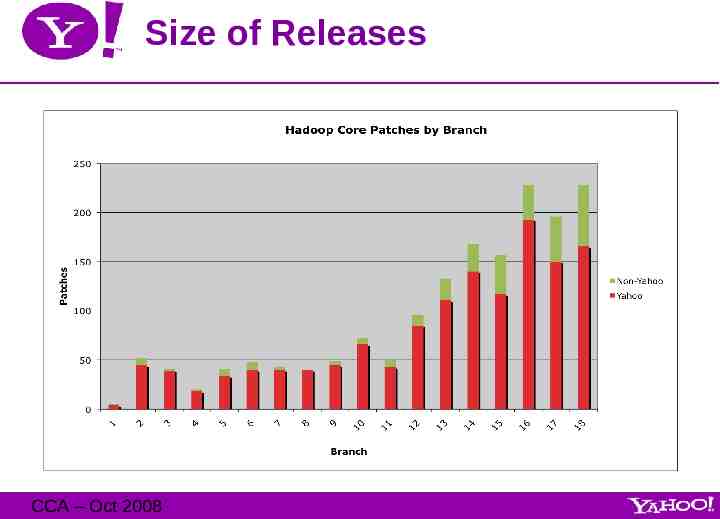
Size of Releases CCA – Oct 2008
Who Uses Hadoop? Amazon/A9 AOL Facebook Fox interactive media Google / IBM New York Times PowerSet (now Microsoft) Quantcast Rackspace/Mailtrust Veoh Yahoo! More at http://wiki.apache.org/hadoop/PoweredBy CCA – Oct 2008
What’s Next? Better scheduling – Pluggable scheduler – Queues for controlling resource allocation between groups Splitting Core into sub-projects – HDFS, Map/Reduce, Hive Total Order Sampler and Partitioner Table store library HDFS and Map/Reduce security High Availability via Zookeeper Get ready for Hadoop 1.0 CCA – Oct 2008
Q&A For more information: – Website: http://hadoop.apache.org/core – Mailing lists: [email protected] [email protected] – IRC: #hadoop on irc.freenode.org CCA – Oct 2008