Introducing Parallel Data Warehouse (The project formerly known as

















30 Slides2.22 MB
Introducing Parallel Data Warehouse (The project formerly known as Madison) Thomas Kejser Senior Program Manager Microsoft Corp.
Agenda The Typical problem with data warehouses MPP vs SMP SQL Server Parallel Data Warehouse Hardware architecture Query Processing Data Loading My email: [email protected] 2
Introducing Parallel Data Warehouse The Typical Problem with Data Warehouses 3
Microsoft DW Solutions Microsoft & Partner Services SSRS SSAS SSIS 11
Symmetric Multi-Processing vs. Massively Parallel SMP Processing MPP OLTP, Transactional, Data Warehousing HW advancements increasing ability to scale-up Data Warehousing (esp. VLDB, complex workloads) HW advancements increasing ability to scale-out But scaling limited by design Scaling to 1 PB High end SMP very expensive Scale out is relatively low cost Extremely high concurrency for simple workloads Relatively high concurrency for complex workloads Less than 1-2 TB of data SMP will almost always be better. 2TB up to 1 PB for DW workloads At higher sizes - depends 12
PDW: No Assembly Required Software Servers Storage arrays Network switches Cables Licenses Power distribution units Racks Comes fully assembled Software is installed at the factory Fully configured 13
Basic Building Blocks Compute Nodes Handles the CPU cycles required to answer queries Storage Nodes Stores data using Fiber Attached Disks. Scaled to support CPU with enough throughput Other nodes More about those later 14
Anatomy of a Compute Node Pre-configured For Each SQL Server Instance On Each Compute Node. Drives Configured As RAID1 To Avoid Appliance Failover for a Single Drive Failure IBM Compute Nodes Will Have 1 Lun (1 RAID1 Pair) Dell Compute Nodes Will Have 2 Lun’s (2 RAID1 Pairs) HP Compute Nodes Will Have 3 Luns’s (3 RAID1 Pairs) TempDB: Sort-work Area For Data Loading Into Clustered Index Tables Work Area for PDW Temporary Work Files Spill Area For Hash Joins Not Fitting Into Memory 15
Anatomy of a Storage Node Pre-configured 4 RAID10 Pairs for Primary User Data 1 RAID10 Pair for Database Logs 2 LUN’s Are Spread Across Each RAID Pair User Databases are Separate Physical SQL Server Databases Staging Database (Optional) Used for Loading & to Minimize Fragmentation 16
More Node Types Backup node: Stores backup files from the appliance Can be logged into by authorized Windows users Can be augmented with 3rd party H/W and S/W Landing Zone: Used as a holding place for data to be loaded Can be logged into by authorized Windows users Can be augmented with 3rd party H/W and S/W Management node: Runs the Windows domain controller (Active Directory) Used for deploying patches to all nodes in the appliance Holds images in case a node needs reimaging 17
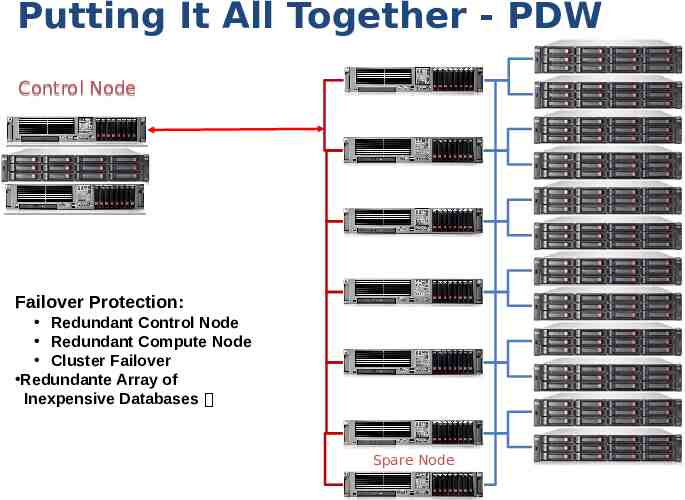
Putting It All Together - PDW Control Node Failover Protection: Redundant Control Node Redundant Compute Node Cluster Failover Redundante Array of Inexpensive Databases Spare Node 18
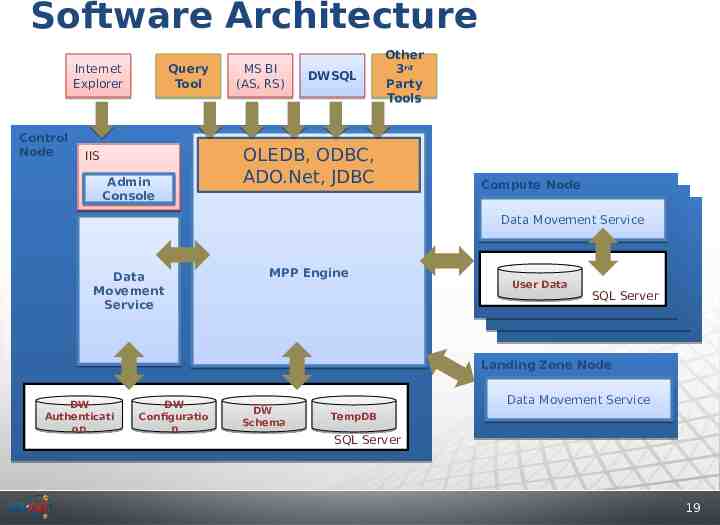
Software Architecture Internet Explorer Control Node Query Tool IIS Admin Console Data Movement Service MS BI (AS, RS) DWSQL Other rd 3rd Party Tools OLEDB, ODBC, ADO.Net, JDBC MPP Engine Compute Node Compute Nodes Compute Nodes Data Movement Service User Data SQL Server Landing Zone Node DW Authenticati on DW Configuratio n DW Schema Data Movement Service TempDB SQL Server 19
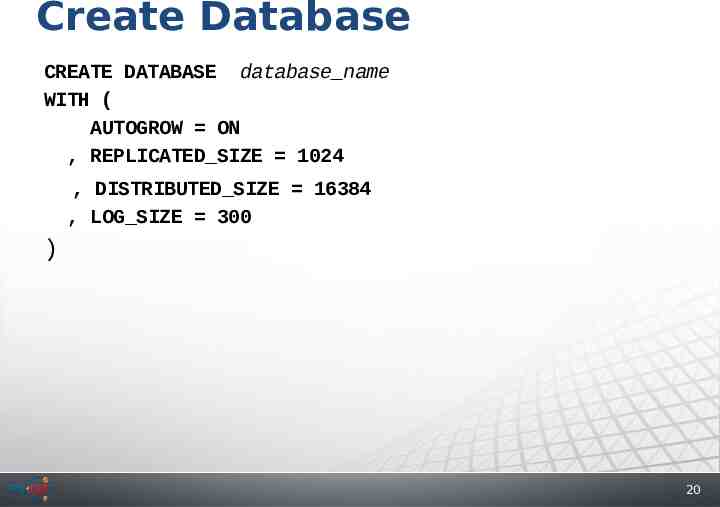
Create Database CREATE DATABASE database name WITH ( AUTOGROW ON , REPLICATED SIZE 1024 , DISTRIBUTED SIZE 16384 , LOG SIZE 300 ) 20
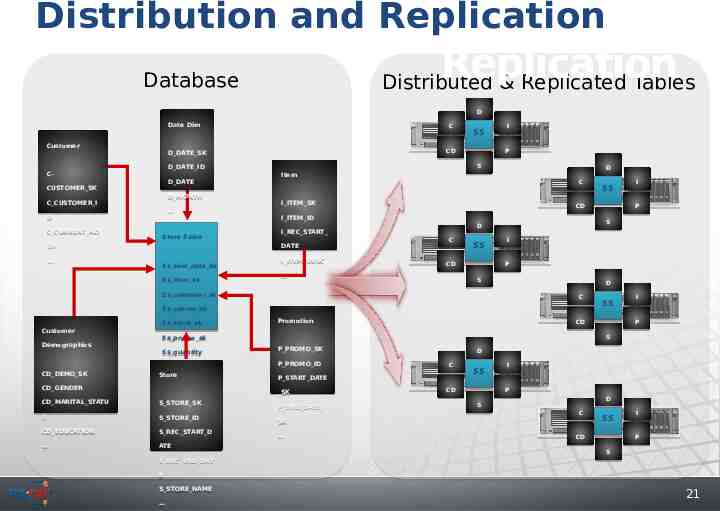
Distribution and Replicationwith Data Distribution Replication Database Distributed & Replicated Tables D D Date Date Dim Dim Customer Customer D DATE ID D DATE ID D DATE D DATE CUSTOMER SK CUSTOMER SK D MONTH D MONTH C CUSTOMER I C CUSTOMER I D D DR DR Store Store Sales Sales Ss sold date sk Ss sold date sk Ss item sk Ss item sk SS SS CD CD D DATE SK D DATE SK CC- C CURRENT AD C CURRENT AD C C II P P S S Item Item D D C C I ITEM SK I ITEM SK CD CD I ITEM ID I ITEM ID I REC START I REC START DATE DATE I ITEM DESC I ITEM DESC C C SS SS CD CD Demographics Demographics P P S S D D C C CD DEMO SK CD DEMO SK Store Store CD GENDER CD GENDER CD MARITAL STATU CD MARITAL STATU Promotion Promotion S S S STORE ID S STORE ID CD EDUCATION CD EDUCATION S REC START D S REC START D ATE ATE S REC END DAT S REC END DAT II P P S S P PROMO SK P PROMO SK P PROMO ID P PROMO ID D D C C P START DATE P START DATE SK SK S STORE SK S STORE SK SS SS CD CD Ss promo sk Ss promo sk Ss quantity Ss quantity P P II Ss cdemo sk Ss cdemo sk Ss store sk Ss store sk II S S D D Ss customer sk Ss customer sk Customer Customer SS SS P END DATE P END DATE SK SK SS SS CD CD II P P S S D D C C SS SS CD CD II P P S S E E S STORE NAME S STORE NAME 21
Table Creation CREATE TABLE table name [ ( { column definition } [ ,.n ] ) [ AS SELECT select criteria ] [ WITH ( table option ) ] [;] column definition :: column name data type [ NULL NOT NULL ] data type :: type name [ ( precision [ , scale ] ) ] table option :: { [ CLUSTER ON ( column name [ ,.n ] ) ] , [ DISTRIBUTE ON ( column name ) ] [ REPLICATE ] , [ PARTITION ON column name ( RANGE { LEFT RIGHT } FOR VALUES { [ boundary value [,.n] ] ) ) ] } Type Class Types Supported Integers tinyint, smallint, int, bigint Floating point float, real Character char, varchar, nchar, nvarchar Date & time date, time, datetime, dateime2, datetimeoffset, timestamp, smalldatetime Fixed point decimal, money, smallmoney Binary binary, varbinary (8192) Other uniqueidentifier (?) 22
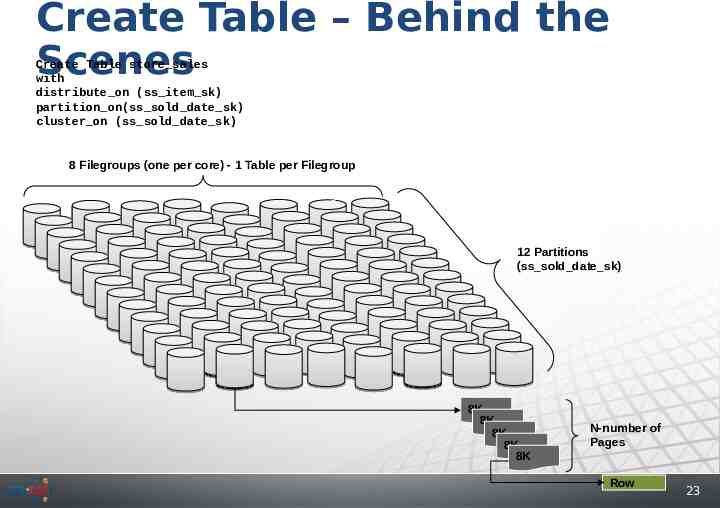
Create Table – Behind the Scenes Create Table store sales with distribute on (ss item sk) partition on(ss sold date sk) cluster on (ss sold date sk) 8 Filegroups (one per core) - 1 Table per Filegroup 12 Partitions (ss sold date sk) 8K 8K 8K 8K 8K N-number of Pages Row 23
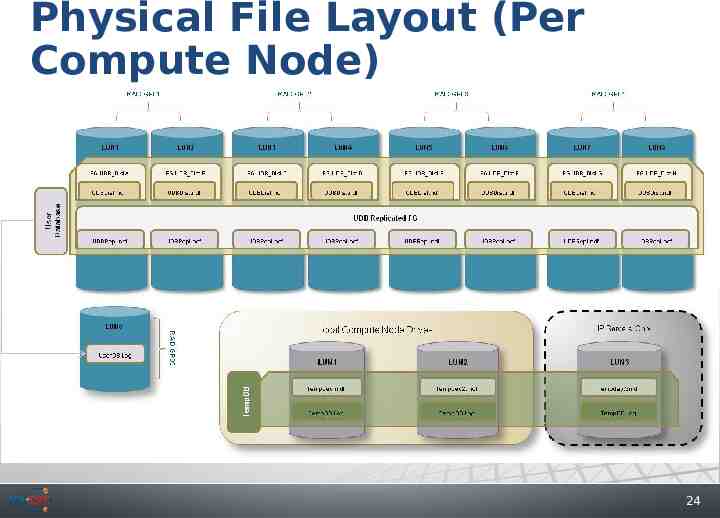
Physical File Layout (Per Compute Node) 24
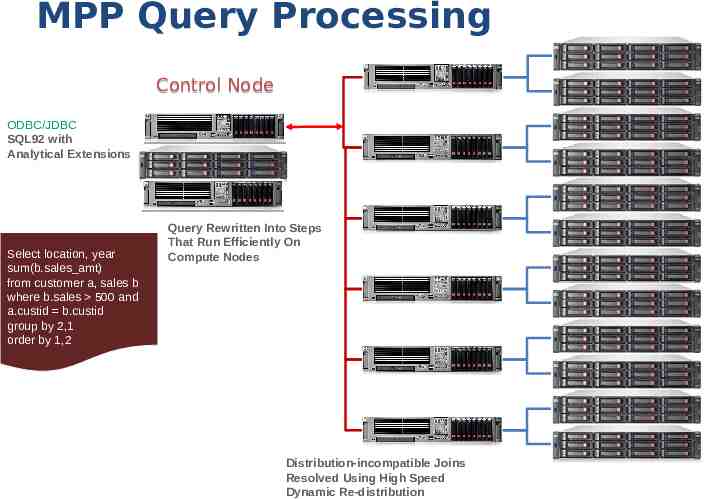
MPP Query Processing Control Node ODBC/JDBC SQL92 with Analytical Extensions Select location, year sum(b.sales amt) from customer a, sales b where b.sales 500 and a.custid b.custid group by 2,1 order by 1,2 Query Rewritten Into Steps That Run Efficiently On Compute Nodes Distribution-incompatible Joins Resolved Using High Speed Dynamic Re-distribution 25
MPP Execution Plans The MPP engine creates parallel execution plans from client SQL The plans can include the following types of operations: SQL operations: used to pass SQL directly to SQL Server on 1 or more nodes. DMS operations: used to move data among the nodes in an appliance for further processing. Temp tables operations: used to stage data for further processing. Return operations: push data back to the client. Simple plans may include just one type of operation. Complex plans may include all of these operations. Plans are executed serially, one step at a time. 26
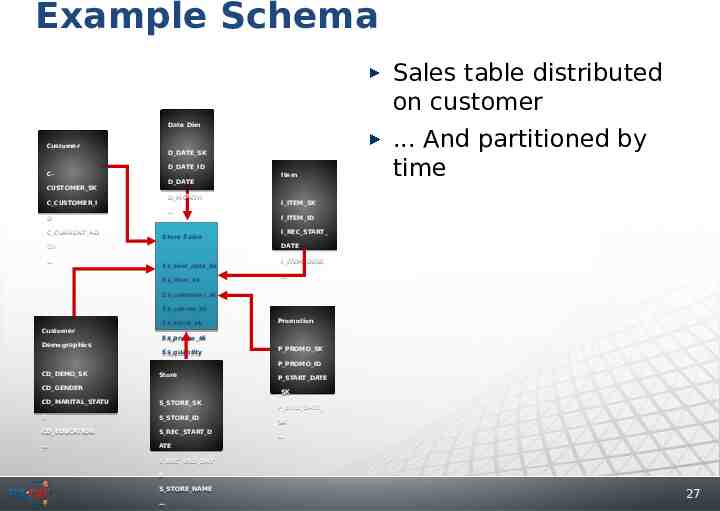
Example Data Schema Distribution with Replication Sales table distributed on customer Date Date Dim Dim Customer Customer D DATE SK D DATE SK D DATE ID D DATE ID CC- D DATE D DATE CUSTOMER SK CUSTOMER SK D MONTH D MONTH C CUSTOMER I C CUSTOMER I D D C CURRENT AD C CURRENT AD DR DR Store Store Sales Sales Ss sold date sk Ss sold date sk Ss item sk Ss item sk Item Item . And partitioned by time I ITEM SK I ITEM SK I ITEM ID I ITEM ID I REC START I REC START DATE DATE I ITEM DESC I ITEM DESC Ss customer sk Ss customer sk Ss cdemo sk Ss cdemo sk Customer Customer Demographics Demographics CD DEMO SK CD DEMO SK Ss store sk Ss store sk Promotion Promotion Ss promo sk Ss promo sk Ss quantity Ss quantity Store Store CD GENDER CD GENDER P PROMO SK P PROMO SK P PROMO ID P PROMO ID P START DATE P START DATE SK SK CD MARITAL STATU CD MARITAL STATU S STORE SK S STORE SK S S S STORE ID S STORE ID CD EDUCATION CD EDUCATION S REC START D S REC START D ATE ATE P END DATE P END DATE SK SK S REC END DAT S REC END DAT E E S STORE NAME S STORE NAME 27
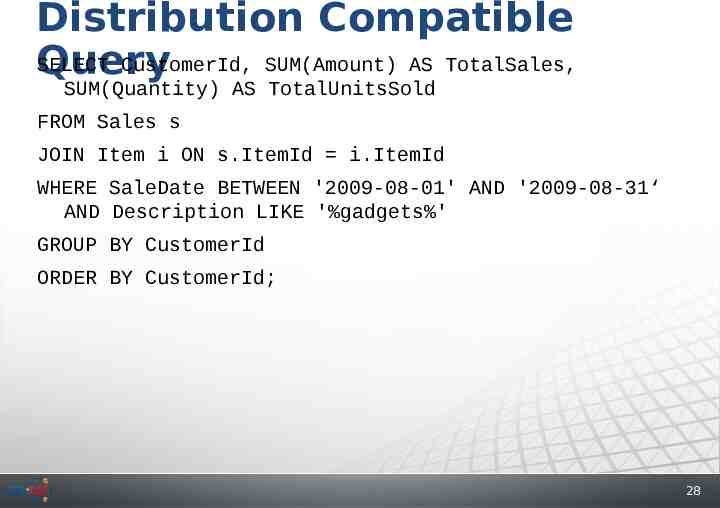
Distribution Compatible SELECT CustomerId, SUM(Amount) AS TotalSales, Query SUM(Quantity) AS TotalUnitsSold FROM Sales s JOIN Item i ON s.ItemId i.ItemId WHERE SaleDate BETWEEN '2009-08-01' AND '2009-08-31‘ AND Description LIKE '%gadgets%' GROUP BY CustomerId ORDER BY CustomerId; 28
MPP Query Plan Step 1 – On each compute node: SELECT s.[customerid], sum(s.[amount]) AS totalsales, sum(s. [quantity]) AS totalunitssold FROM [tpch 3].[dbo].[h sales 34] s JOIN [tpch 3]. [dbo].item 37 I ON (s.[itemid] i.[itemid]) WHERE (s.[saledate] BETWEEN '2009-08-01' AND '2009-08-31' and i.[description] like '%gadgets%') GROUP BY s.[customerid] ORDER BY s.[customerid]; 29
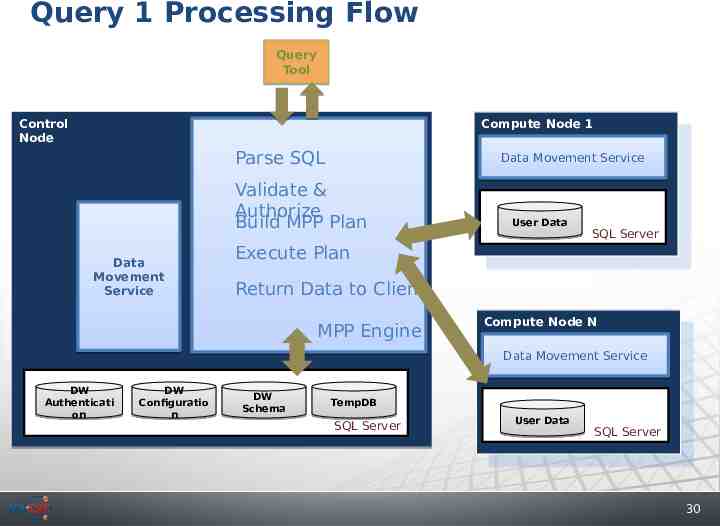
Query 1 Processing Flow Query Tool Control Node Compute Node 1 Compute Node 1 Parse SQL Data Movement Service Validate & Authorize Build MPP Plan Data Movement Service User Data SQL Server Execute Plan Return Data to Client MPP Engine Compute Node N Compute Node N Data Movement Service DW Authenticati on DW Configuratio n DW Schema TempDB SQL Server User Data SQL Server 30
Reshuffling the data SELECT SaleDate, SUM(Amount) AS TotalSales, SUM(Quantity) AS TotalUnitsSold FROM Sales s JOIN Item i ON s.ItemId i.ItemId WHERE SaleDate BETWEEN '2009-08-01' AND '2009-08-31' AND Description LIKE '%gadgets%‘ GROUP BY SaleDate ORDER BY SaleDate; 31
MPP Query Plan Step 1 – Create temp table on control node CREATE TABLE [tempdb].[dbo].Q [TEMP ID 6760] ( saledate DATE, totalsales DECIMAL(38, 2), totalunitssold INTEGER ) WITH (DATA COMPRESSION PAGE); Step 2 – Run on each compute node SELECT s.[saledate], sum(s.[amount]) AS totalsales, sum(s. [quantity]) AS totalunitssold FROM [tpch 3].[dbo].[h sales 34] s JOIN [tpch 3]. [dbo].item 37 i ON (s.[itemid] i.[itemid]) WHERE (s.[saledate] BETWEEN '2009-08-01' AND '2009-08-31' and i.[description] like '%gadgets%’) GROUP BY s.[saledate] 32
MPP Query Plan continued Step 3: SELECT [saledate], sum([totalsales]) AS totalsales, sum([totalunitssold]) AS totalunitssold FROM [tempdb].[dbo].Q [TEMP ID 6760] GROUP BY [saledate] ORDER BY [saledate] Step 4: DROP TABLE [tempdb].[dbo].Q [TEMP ID 6760]; 33
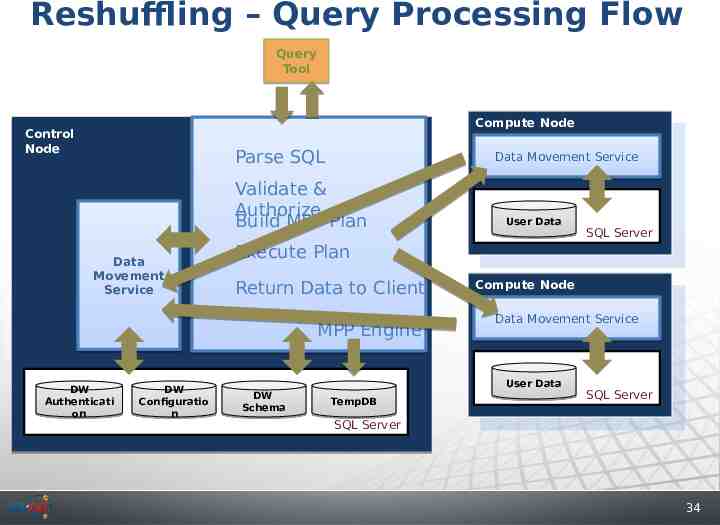
Reshuffling – Query Processing Flow Query Tool Compute Node Compute Node Control Node Parse SQL Data Movement Service Validate & Authorize Build MPP Plan Data Movement Service DW Configuratio n SQL Server Execute Plan Return Data to Client MPP Engine DW Authenticati on User Data DW Schema Compute Node Compute Node Data Movement Service User Data TempDB SQL Server SQL Server 34
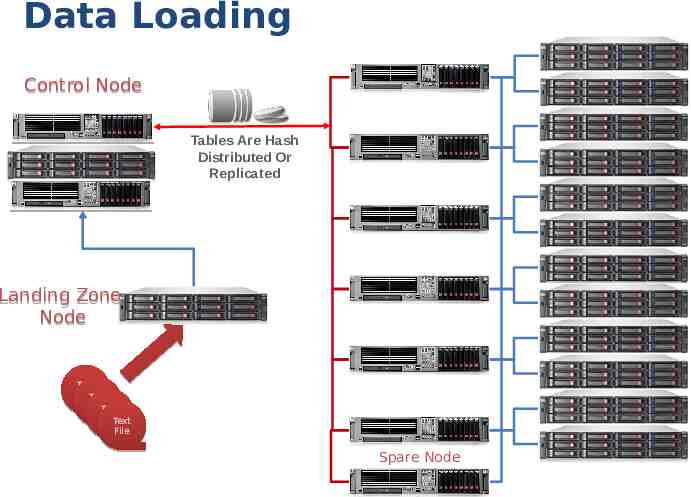
Data Loading Control Node Tables Are Hash Distributed Or Replicated Landing Zone Node Text File Text File Text Text File Text File File Spare Node 35
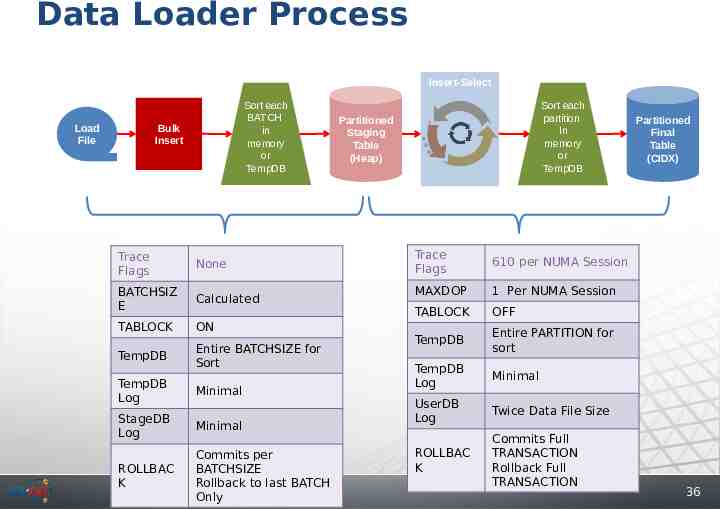
Data Loader Process Insert-Select Sort each BATCH in memory or TempDB Bulk Insert Load File Bulk Insert Phase Trace Flags None BATCHSIZ E Calculated TABLOCK ON TempDB Entire BATCHSIZE for Sort TempDB Log Minimal StageDB Log Minimal ROLLBAC K Commits per BATCHSIZE Rollback to last BATCH Only Sort each partition In memory or TempDB Partitioned Staging Table (Heap) Partitioned Final Table (CIDX) Insert-Select Phase Trace Flags 610 per NUMA Session MAXDOP 1 Per NUMA Session TABLOCK OFF TempDB Entire PARTITION for sort TempDB Log Minimal UserDB Log Twice Data File Size ROLLBAC K Commits Full TRANSACTION Rollback Full TRANSACTION 36
2008 Microsoft Corporation. All rights reserved. Microsoft, Windows, Windows Vista and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries. The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION. 37






