Instruction Scheduling Increasing Parallelism Basic-Block






































48 Slides124.50 KB
Instruction Scheduling Increasing Parallelism Basic-Block Scheduling Data-Dependency Graphs 1
The Model A very-long-instruction-word machine allows several operations to be performed at once. Given: a list of “resources” (e.g., ALU) and delay required for each instruction. Schedule the intermediate code instructions of a basic block to minimize the number of machine instructions. 2
Register/Parallelism Tradeoff The more registers you use, the more parallelism you can get. For a basic block, SSA form maximal parallelism. 3
Example Assume 2 arithmetic operations per instruction a e a f b c a d b-c a d ALU1 a b c e a d f a d Don’t reuse a ALU2 a b-c a1 b c e a1 d a2 b-c f a2 d ALU1 a1 b c e a1 d ALU2 a2 b-c f a2 d 4
More Extreme Example for (i 0; i N; i ) { t a[i] 1; b[i] t*t; } /* no parallelism */ for (i 0; i N; i ) { t[i] a[i] 1; b[i] t[i]*t[i]; } /* All iterations can be executed in parallel */ 5
Rules for Instruction Scheduling 1. Don’t change the set of operations performed (on any computation path). 2. Make sure interfering operations are performed in the same order. Data dependence. 6
Kinds of Data Dependence 1. Write-read (true dependence ): A read of x must continue to follow the previous write of x. 2. Read-write (antidependence ): A write of x must continue to follow previous reads of x. 3. Write-write (output dependence ): Writes of x must stay in order. 7
Eliminating Data Dependences Only true dependences cannot be eliminated. Eliminate output or antidependences by writing into different variables. 8
A Machine Model Arithmetic is register*register - register. Requires one unit of ALU. Loads (LD) and Stores (ST). Requires one unit of MEM (memory buffer). 9
Timing in Our Machine Model Arithmetic requires one clock cycle (“clock ”). Store requires 1 clock. Load requires 2 clocks to complete . But we can store into the same memory location at the next clock. And one LD can be issued at each clock. 10
Data-Dependence Graphs Nodes machine instructions. Edge i - j if instruction (j) has a data dependence on instruction (i). Label an edge with the minimum delay interval between when (i) may initiate and when (j) may initiate. Delay measured in clock cycles. 11
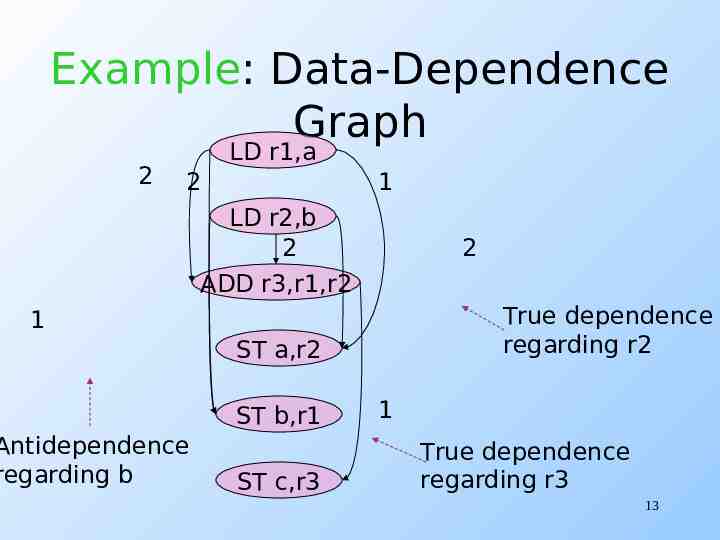
Example Resource LD r1, a MEM LD r2, b MEM ADD r3, r1, r2 ALU ST a r2 MEM ST b r1 MEM ST c r3 MEM 12
Example: Data-Dependence Graph 2 LD r1,a 2 1 LD r2,b 2 ADD r3,r1,r2 2 True dependence regarding r2 1 Antidependence regarding b ST a,r2 ST b,r1 ST c,r3 1 True dependence regarding r3 13
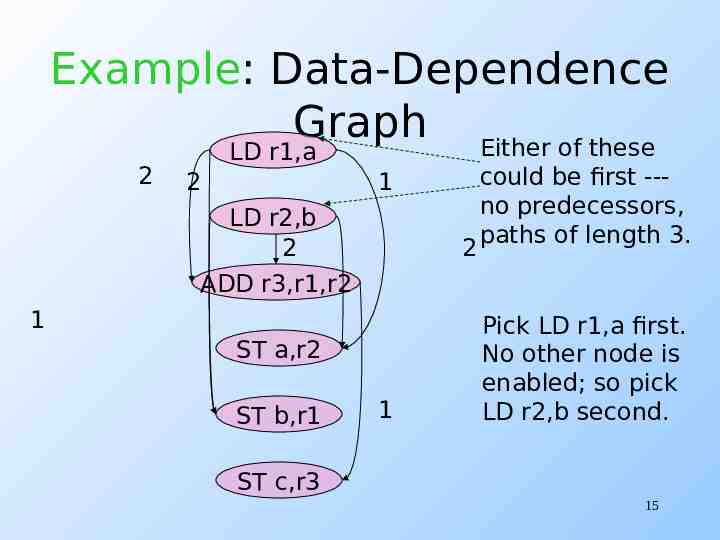
Scheduling a Basic Block List scheduling is a simple heuristic. Choose a prioritized topological order. 1. Respects the edges in the datadependence graph (“topological”). 2. Heuristic choice among options, e.g., pick first the node with the longest path extending from that node (“prioritized”). 14
Example: Data-Dependence Graph Either of these 2 LD r1,a 2 1 LD r2,b 2 ADD r3,r1,r2 2 1 ST a,r2 ST b,r1 1 could be first --no predecessors, paths of length 3. Pick LD r1,a first. No other node is enabled; so pick LD r2,b second. ST c,r3 15
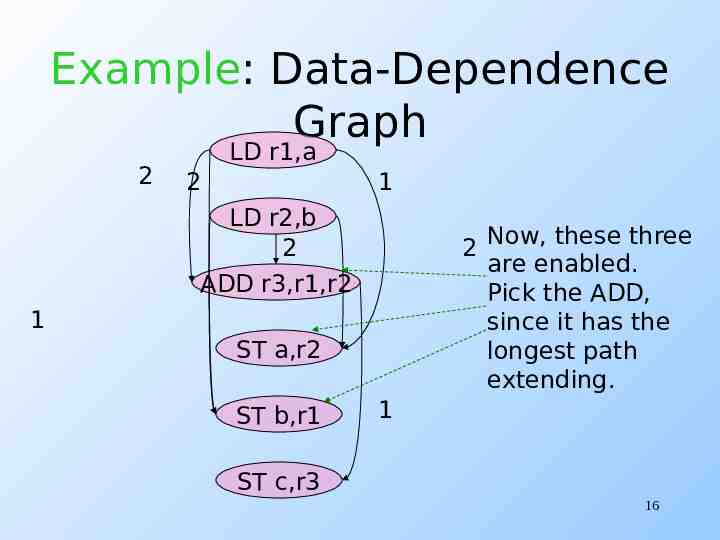
Example: Data-Dependence Graph 2 LD r1,a 2 1 LD r2,b 2 ADD r3,r1,r2 2 1 ST a,r2 ST b,r1 Now, these three are enabled. Pick the ADD, since it has the longest path extending. 1 ST c,r3 16
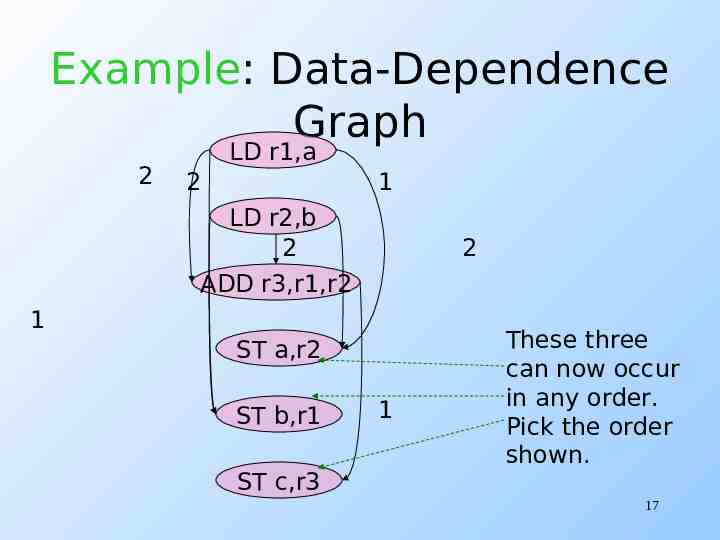
Example: Data-Dependence Graph 2 LD r1,a 2 1 LD r2,b 2 ADD r3,r1,r2 2 1 ST a,r2 ST b,r1 ST c,r3 1 These three can now occur in any order. Pick the order shown. 17
Using the List to Schedule For each instruction in list order, find the earliest clock cycle at which it can be scheduled. Consider first when predecessors in the dependence graph were scheduled; that is a lower bound. Then, if necessary, delay further until the necessary resources are available. 18
Example: Making the Schedule LD r1,a LD r1,a: clock 1 earliest. MEM available. 19
Example: Making the Schedule LD r1,a LD r2,b LD r2,b: clock 1 earliest. MEM not available. Delay to clock 2. 20
Example: Making the Schedule LD r1,a LD r2,b ADD r3,r1,r2 ADD r3,r1,r2: clock 4 earliest. ALU available. 21
Example: Making the Schedule LD r1,a LD r2,b ADD r3,r1,r2 ST a,r2: clock 4 earliest. MEM available. ST a,r2 22
Example: Making the Schedule LD r1,a LD r2,b ST b,r1 ADD r3,r1,r2 ST b,r1: clock 3 earliest. MEM available. ST a,r2 23
Example: Making the Schedule LD r1,a LD r2,b ST b,r1 ADD r3,r1,r2 ST c,r3 ST c,r3: clock 5 earliest. MEM available. ST a,r2 24
New Topic: Global Code Motion We can move code from one basic block to another, to increase parallelism. Must obey all dependencies. Speculative execution (execute code needed in only one branch) OK if operation has no side effects. Example: LD into an unused register. 25
Upwards Code Motion Can move code to a dominator if: 1. Dependencies satisfied. 2. No side effects unless source and destination nodes are control equivalent : Destination dominates source. Source postdominates destination. Can move to a nondominator if compensation code is inserted. 26
Downwards Code Motion Can move to a postdominator if: 1. Dependencies satisfied. 2. No side effects unless control equivalent. Can move to a nonpostdominator if compensation code added. 27
Machine Model for Example Same timing as before. LD 2 clocks, others 1 clock. Machine can execute any two instructions in parallel. 28
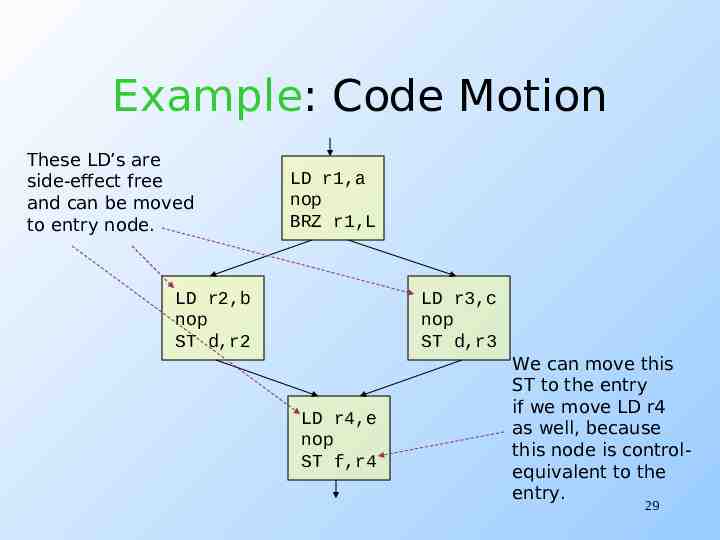
Example: Code Motion These LD’s are side-effect free and can be moved to entry node. LD r1,a nop BRZ r1,L LD r2,b nop ST d,r2 LD r3,c nop ST d,r3 LD r4,e nop ST f,r4 We can move this ST to the entry if we move LD r4 as well, because this node is controlequivalent to the entry. 29
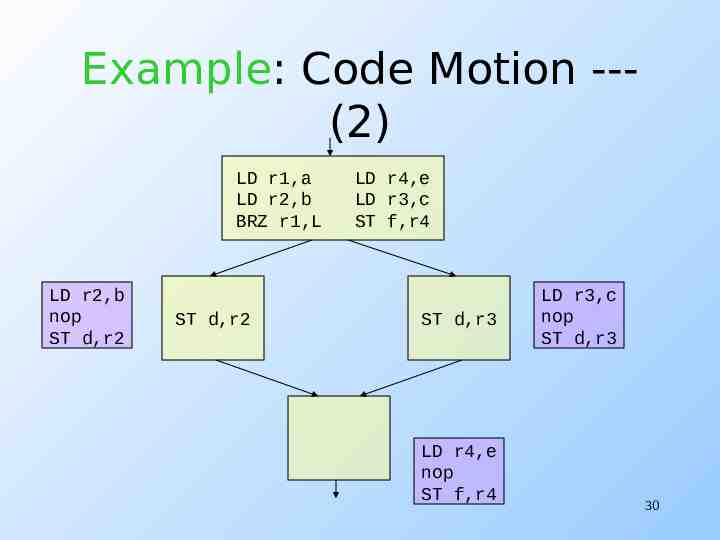
Example: Code Motion --(2) LD r1,a LD r2,b BRZ r1,L LD r2,b nop ST d,r2 ST d,r2 LD r4,e LD r3,c ST f,r4 ST d,r3 LD r4,e nop ST f,r4 LD r3,c nop ST d,r3 30
Software Pipelining Obtain parallelism by executing iterations of a loop in an overlapping way. We’ll focus on simplest case: the do-all loop, where iterations are independent. Goal: Initiate iterations as frequently as possible. Limitation: Use same schedule and delay for each iteration. 31
Machine Model Same timing as before (LD 2, others 1 clock). Machine can execute one LD or ST and one arithmetic operation (including branch) at any one clock. I.e., we’re back to one ALU resource and one MEM resource. 32
Example for (i 0; i N; i ) B[i] A[i]; r9 holds 4N; r8 holds 4*i. L: LD r1, a(r8) Notice: data dependences nop force this schedule. No ST b(r8), r1 parallelism is possible. ADD r8, r8, #4 BLT r8, r9, L 33
Let’s Run 2 Iterations in Parallel Focus on operations; worry about registers later. LD nop LD ST nop Oops --- violates ADD ST ALU resource constraint. BLT ADD BLT 34
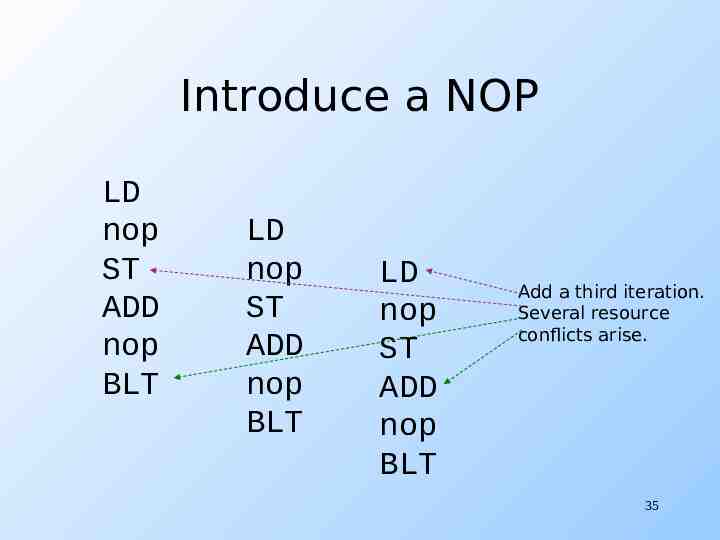
Introduce a NOP LD nop ST ADD nop BLT LD nop ST ADD nop BLT LD nop ST ADD nop BLT Add a third iteration. Several resource conflicts arise. 35
Is It Possible to Have an Iteration Start at Every Clock? Hint: No. Why? An iteration injects 2 MEM and 2 ALU resource requirements. If injected every clock, the machine cannot possibly satisfy all requests. Minimum delay 2. 36
LD nop nop ST ADD BLT A Schedule With Delay 2 Initialization LD nop nop ST ADD BLT LD nop nop ST ADD BLT Identical iterations of the loop LD nop nop ST ADD BLT Coda 37
Assigning Registers We don’t need an infinite number of registers. We can reuse registers for iterations that do not overlap in time. But we can’t just use the same old registers for every iteration. 38
Assigning Registers --- (2) The inner loop may have to involve more than one copy of the smallest repeating pattern. Enough so that registers may be reused at each iteration of the expanded inner loop. Our example: 3 iterations coexist, so we need 3 sets of registers and 3 copies of the pattern. 39
Example: Assigning Registers Our original loop used registers: r9 to hold a constant 4N. r8 to count iterations and index the arrays. r1 to copy a[i] into b[i]. The expanded loop needs: r9 holds 4N. r6, r7, r8 to count iterations and index. r1, r2, r3 to copy certain array elements. 40
The Loop Body Each register handles every third element of the arrays. To break the loop early Iteration i L: ADD BGE LD nop nop ST r8,r8,#12 r8,r9,L’ r1,a(r8) b(r8),r1 Iteration i 3 Iteration i 1 nop ST ADD BGE LD nop b(r7),r2 r7,r7,#12 r7,r9,L’’ r2,a(r7) Iteration i 2 LD nop nop ST ADD BLT r3,a(r6) b(r6),r3 r6,r6,#12 r6,r9,L Iteration i 4 L’ and L’’ are places for appropriate codas. 41
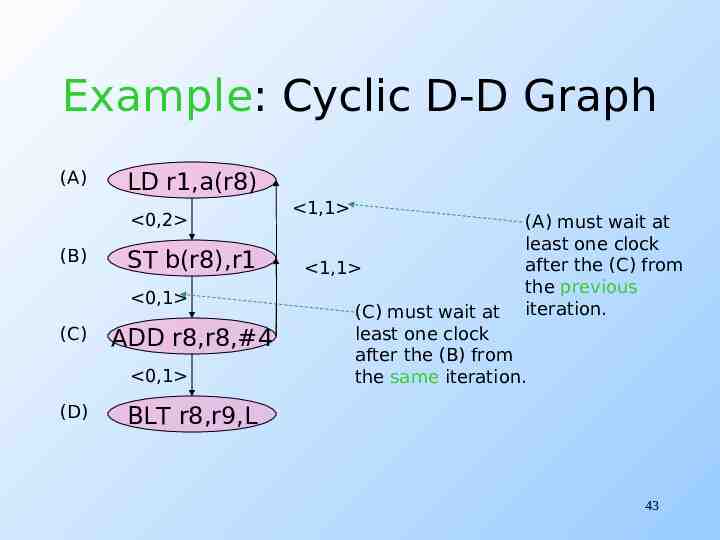
Cyclic Data-Dependence Graphs We assumed that data at an iteration depends only on data computed at the same iteration. Not even true for our example. r8 computed from its previous iteration. But it doesn’t matter in this example. Fixup: edge labels have two components: (iteration change, delay). 42
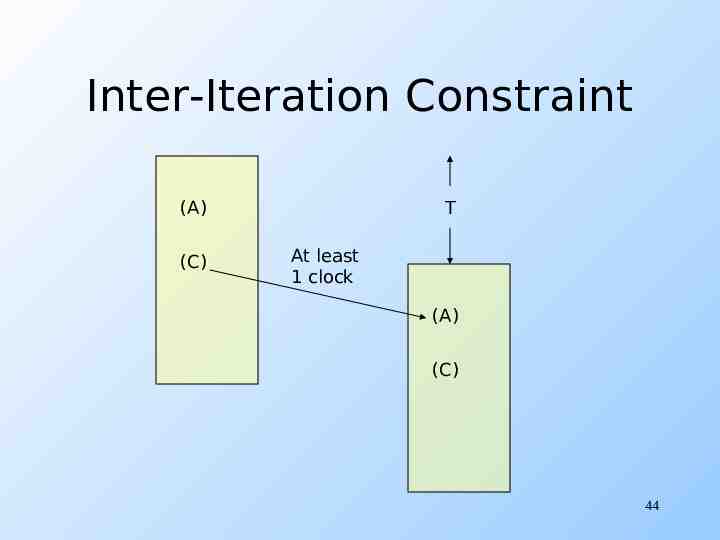
Example: Cyclic D-D Graph (A) LD r1,a(r8) 0,2 (B) ST b(r8),r1 0,1 (C) ADD r8,r8,#4 0,1 (D) 1,1 1,1 (A) must wait at least one clock after the (C) from the previous iteration. (C) must wait at least one clock after the (B) from the same iteration. BLT r8,r9,L 43
Inter-Iteration Constraint (A) (C) T At least 1 clock (A) (C) 44
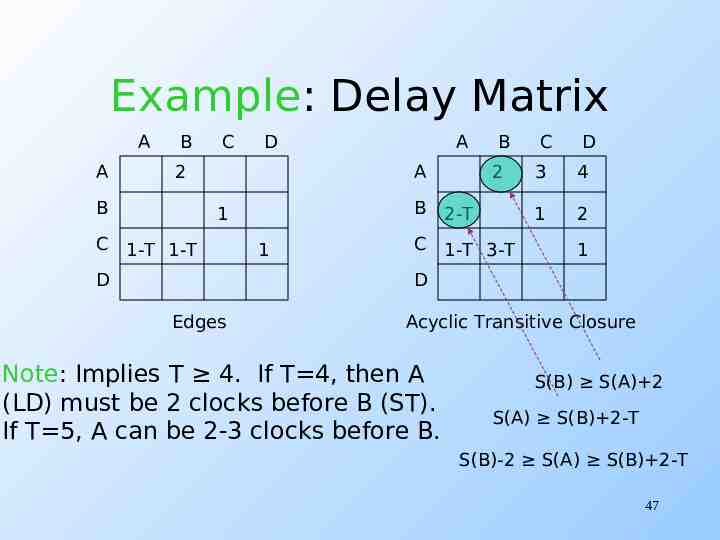
Matrix of Delays Let T be the delay between the start times of one iteration and the next. Replace edge label i,j by delay j-iT. Compute, for each pair of nodes n and m the total delay along the longest acyclic path from n to m. Gives upper and lower bounds relating the times to schedule n and m. 45
The Schedule Iterations commence at times 0, T, 2T, A statement corresponding to node n is scheduled S(n) clocks after the commencement of its iteration. 46
Example: Delay Matrix A A B C D 2 B A A D 2 B 2-T 1 C 1-T 1-T B 1 C 1-T 3-T C D 3 4 1 2 1 D Edges Acyclic Transitive Closure Note: Implies T 4. If T 4, then A (LD) must be 2 clocks before B (ST). If T 5, A can be 2-3 clocks before B. S(B) S(A) 2 S(A) S(B) 2-T S(B)-2 S(A) S(B) 2-T 47
A Query When we considered software pipelining, we found that it was possible to initiate an iteration every 2 clocks. Now, we’ve concluded that T 4. What’s going on? 48






