Hadoop HDFS Install Hadoop HDFS 2.5.2 with Ubuntu 14.04 1
















18 Slides264.50 KB
Hadoop HDFS Install Hadoop HDFS 2.5.2 with Ubuntu 14.04 1
Introduction We can use Hadoop HDFS to build a distribution file system. Save the files in different nodes , provide an environment with fault tolerance and high efficiency. Three Parts of this report Environment prepare Install Hadoop hdfs Hdfs shell input and output command 2
Environment prepare We use VMware Workstation 10 with OS Ubuntu 14.04 version to install our hadoop. And we create 3 virtual machine to Implement HDFS Master-Slave structure. During install the OS, please remember user account. Use command mode to prepare environment. sudo apt-get update sudo apt-get install default-jdk sudo apt-get install ssh Update Ubuntu and Java, and install ssh. 3
Environment prepare Chang hostname from “ubuntu” to you wants in every node. And add the hostname after “127.0.1.1” in the “hosts”. sudo nano /etc/hostname sudo nano /etc/hosts In the “hosts” need input “127.0.0.1 all HDFS devices name with IP. localhost”, and input Ex: 127.0.0.1 localhost 127.0.1.1 (hostname) ubuntu 192.168.213.129 Master 192.168.213.130 Slave1 192.168.213.131 Slave2 4
Environment prepare Set ssh let easy to login to Slave node. ssh-keygen -t rsa -P "" scp /.ssh/id rsa.pub (account)@Slave1:/home/ (account)/ cat /.ssh/id rsa.pub /.ssh/authorized keys Use “scp” to copy rsa to Slave1 and Slave2. And also need “cat” the rsa onMaster too. 5
Install Hadoop Check out your java folder location. ls /usr/lib/jvm/ It will be “java-7-openjdk-i386 “ or “java-7-openjdk-amd64 “ , remember It. Download hadoop package , decompress it , and place it. tar xvzf hadoop-2.5.2.tar.gz sudo mv hadoop-2.5.2 /usr/local/hadoop cd /usr/local sudo chown -R (Your account):root hadoop Use the lastest command to set the folder owner. We can use GUI to edit hadoop config. 6
Install Hadoop Set the command enviroment. sudo nano /.bashrc And add config at lastest.Notice the java path. export JAVA HOME /usr/lib/jvm/java-7-openjdk-i386 export HADOOP INSTALL /usr/local/hadoop export PATH PATH: HADOOP INSTALL/bin export PATH PATH: HADOOP INSTALL/sbin export HADOOP MAPRED HOME HADOOP INSTALL export HADOOP COMMON HOME HADOOP INSTALL export HADOOP HDFS HOME HADOOP INSTALL export YARN HOME HADOOP INSTALL export HADOOP COMMON LIB NATIVE DIR HADOOP INSTALL/lib/native export HADOOP OPTS "-Djava.library.path HADOOP INSTALL/lib" 7
Install Hadoop Set the hadoop config.We first to build some folder. cd /usr/local/hadoop mkdir tmp dfs dfs/name dfs/data And then edit this file. sudo nano etc/hadoop/hadoop-env.sh Add this line. Still notice the JAVA path. export JAVA HOME /usr/lib/jvm/java-7-openjdk-i386 And we need to edit other file in /usr/local/hadoop/etc/hadoop/ nano slaves Delete the “localhost” and write slave node’s name. EX: Slave1 Slave2 8
Install Hadoop Set the core-site.xml file. Write them between the configuration . nano core-site.xml property name fs.defaultFS /name value hdfs://Master:9000 /value /property property name io.file.buffer.size /name value 131072 /value /property property name hadoop.tmp.dir /name value file:/usr/local/hadoop/tmp /value description Abase for other temporary directories. /description /property property name hadoop.proxyuser.hduser.hosts /name value * /value /property property name hadoop.proxyuser.hduser.groups /name value * /value /property 9
Install Hadoop Set the hdfs-site.xml file. The value of “dfs.replication ” is amount of slaves. nano hdfs-site.xml property name dfs.namenode.secondary.http-address /name value Master:9001 /value /property property name dfs.namenode.name.dir /name value file:/usr/local/hadoop/dfs/name /value /property property name dfs.datanode.data.dir /name value file:/usr/local/hadoop/dfs/data /value /property property name dfs.replication /name value 2 /value /property property name dfs.webhdfs.enabled /name value true /value /property 10
Install Hadoop Rename the “mapred-site.xml.template” to “mapred-site.xml” and edit it. . mv mapred-site.xml.template mapred-site.xml nano mapred-site.xml property name mapreduce.framework.name /name value yarn /value /property property name mapreduce.jobhistory.address /name value Master:10020 /value /property property name mapreduce.jobhistory.webapp.address /name value Master:19888 /value /property 11
Install Hadoop Set the yarn-site.xml file. nano yarn-site.xml property name yarn.nodemanager.aux-services /name value mapreduce shuffle /value /property property name yarn.nodemanager.aux-services.mapreduce.shuffle.class /name value org.apache.hadoop.mapred.ShuffleHandler /value /property property name yarn.resourcemanager.address /name value Master:8032 /value /property property name yarn.resourcemanager.scheduler.address /name value Master:8030 /value /property property name yarn.resourcemanager.resource-tracker.address /name value Master:8031 /value /property 12
Install Hadoop Set the yarn-site.xml file. Continue property name yarn.resourcemanager.admin.address /name value Master:8033 /value /property property name yarn.resourcemanager.webapp.address /name value Master:8088 /value /property After set up hadoop. Compress them and copy to slave. cd /usr/local sudo tar -zcf ./hadoop.tar.gz ./hadoop scp ./hadoop.tar.gz Slave1:/home/(account) ssh Slave1 sudo tar -zxf /hadoop.tar.gz -C /usr/local sudo chown -R (account):root /usr/local/hadoop exit 13
Install Hadoop Start the hadoop on the Master. The first time need to format the file system. cd /usr/local/hadoop/ bin/hdfs namemode –format Use “sbin/start-dfs.sh” and “sbin/start-yarn.sh” to start the file system. It’s can use “sbin/start-all.sh” to replace. sbin/start-dfs.sh sbin/start-yarn.sh After all, use “jps” to check the hadoop progress. In the Master: ResourceManager SecondaryNameNode NameNode In the Slave: DataNode NodeManager 14
Input and output command The hdfs like linux have a root folder. User can use command like linux to control hdfs. For example: ls,cd,mkdir etc The command “hadoop fs” is the important command to control hdfs. Example: hadoop fs -ls hadoop fs -cp hadoop fs -mkdir hadoop fs -mv hadoop fs -rm And user can use “put” or “copyFromLocal” to put the file to hdfs. hadoop fs -mkdir -p /user/(account)/ input sample hadoop fs -put /home/hsin/txt sample input sample User can use “get” or “copyToLocal” to get the file from hdfs. hadoop fs -get input sample/txt sample /home/hsin 15
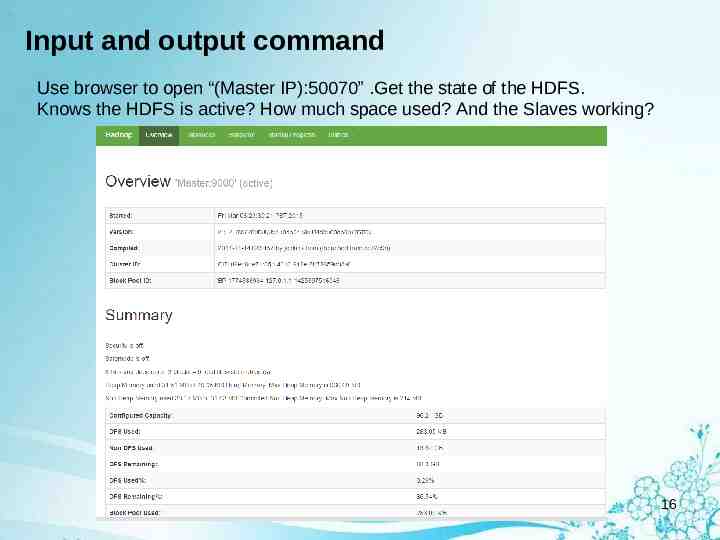
Input and output command Use browser to open “(Master IP):50070” .Get the state of the HDFS. Knows the HDFS is active? How much space used? And the Slaves working? 16
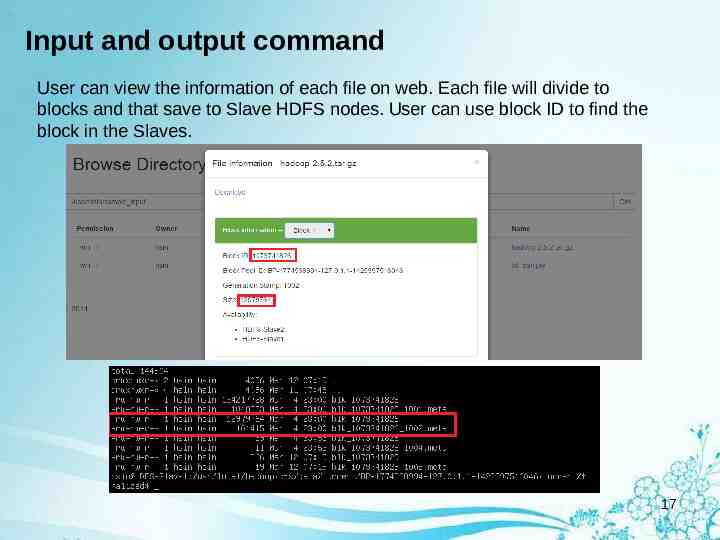
Input and output command User can view the information of each file on web. Each file will divide to blocks and that save to Slave HDFS nodes. User can use block ID to find the block in the Slaves. 17
Q&A 18






