Foundations of Machine Learning (CS725) Autumn 2011 Instructor:


















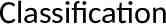



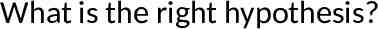











56 Slides5.67 MB
Foundations of Machine Learning (CS725) Autumn 2011 Instructor: Prof. Ganesh Ramakrishnan TAs: Ajay Nagesh, Amrita Saha, Kedharnath Narahari
The grand goal From the movie 2001: A Space Odyssey (1968)
Outline Introduction to Machine Learning – What is machine learning? – Why machine learning – How machine learning relates to other fields Real world applications Machine Learning : Models and methods – – – – Supervised Unsupervised Semi-supervised Active learning Course Information – Tools and software – Pre-requisites
INTRODUCTION TO MACHINE LEARNING
Intelligence Ability for abstract thought, understanding, communication, reasoning, planning, emotional intelligence, problem solving, learning The ability to learn and/or adapt is generally considered a hallmark of intelligence
Learning and Machine Learning Learning denotes changes in the system that are adaptive in the sense that they enable the system to do the task(s) drawn from the same population more efficiently and more effectively the next time.''--Herbert Simon Machine Learning is concerned with the development of algorithms and techniques that allow computers to learn.
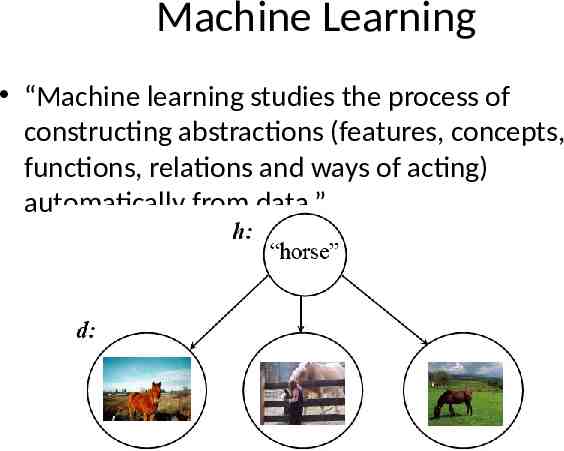
Machine Learning “Machine learning studies the process of constructing abstractions (features, concepts, functions, relations and ways of acting) automatically from data.”
E.g.: Learning concepts and words “tufa” “tufa” “tufa” Can you pick out the tufas? Source: Josh Tenenbaum
Why Machine Learning ? Human expertise does not exist (e.g. Martian exploration) Humans cannot explain their expertise or reduce it to a rule set, or their explanation is incomplete and needs tuning (e.g. speech recognition) Situation changing in time (e.g. spam/junk email) Humans are expensive to train up (e.g. zipcode recognition) There are large amounts of data (e.g. discover astronomical objects)
APPLICATIONS OF MACHINE LEARNING
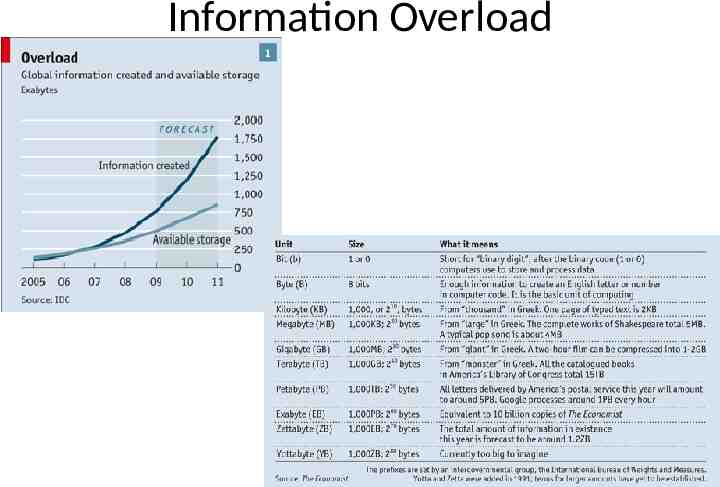
Data Data Everywhere Library of Congress text database of 20 TB AT&T 323 TB, 1.9 trillion phone call records. World of Warcraft utilizes 1.3 PB of storage to maintain its game. Avatar movie reported to have taken over 1 PB of local storage at WetaDigital for the rendering of the 3D CGI effects. Google processes 24 PB of data per day. YouTube: 24 hours of video uploaded every minute. More video is uploaded in 60 days than all 3 major US networks created in 60 years. According to Cisco, internet video will generate over 18 EB of traffic per month in 2013.
Information Overload
Machine Learning to the rescue Machine Learning is one of the front-line technologies to handle Information Overload Business – Mining correlations, trends, spatio-temporal predictions. – Efficient supply chain management. – Opinion mining and sentiment analysis. – Recommender systems.
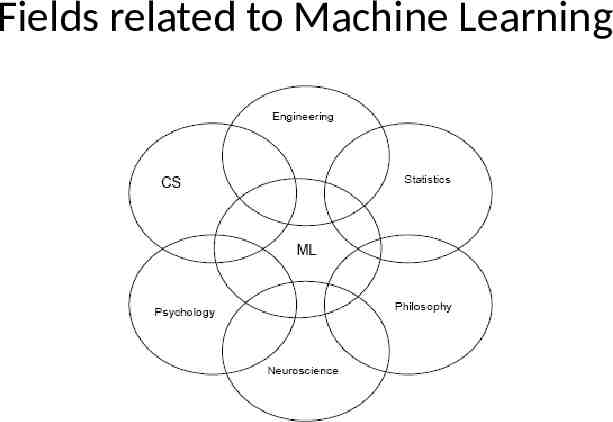
Fields related to Machine Learning
Fields related to Machine Learning Artificial Intelligence: computational intelligence Data Mining: searching through large volumes of data Neural Networks: neural/brain inspired methods Signal Processing: signals, video, speech, image Pattern Recognition: labeling data Robotics: building autonomous robots
Application of Machine Learning Deep Blue and the chess Challenge RoboCup Online Poker
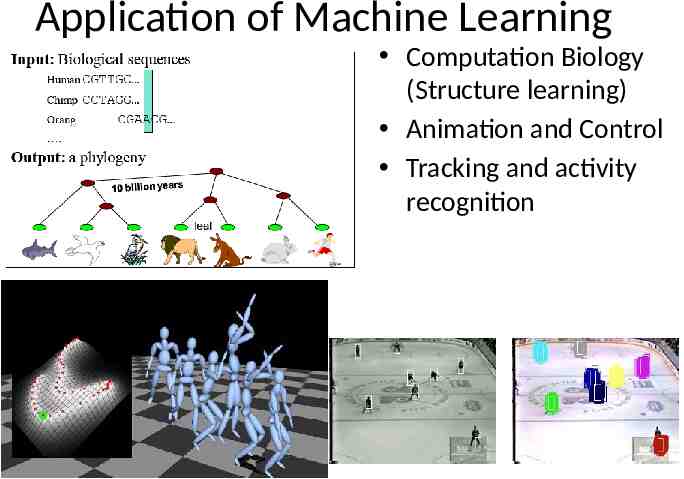
Application of Machine Learning Computation Biology (Structure learning) Animation and Control Tracking and activity recognition
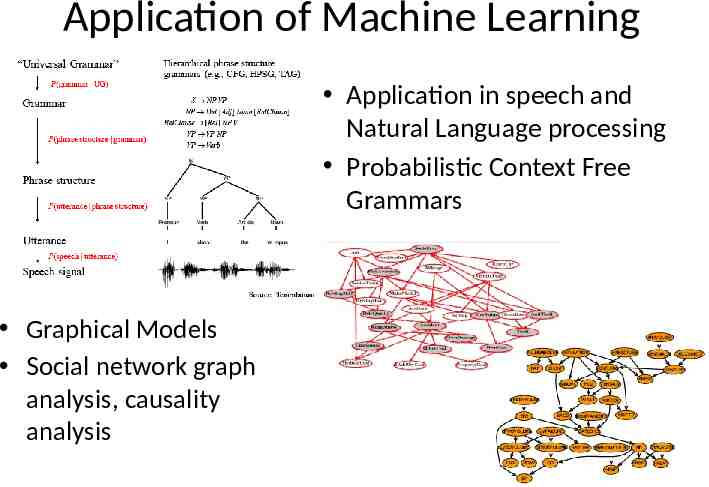
Application of Machine Learning Application in speech and Natural Language processing Probabilistic Context Free Grammars Graphical Models Social network graph analysis, causality analysis
Deep Q and A: IBM Watson Deep Question and Answering : Jeopardy challenge Watson emerged winner when pitted against all time best rated players in the history of Jeopardy Source: IBM Research
MACHINE LEARNING MODELS AND METHODS
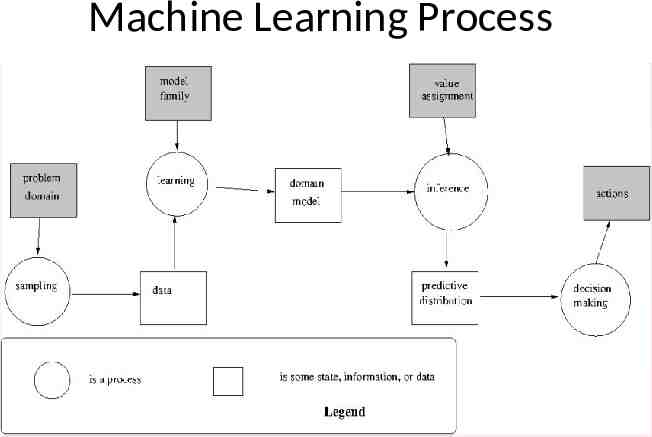
Machine Learning Process How to do the learning actually?
Learning (Formally) Task To apply some machine learning method to the data obtained from a given domain (Training Data) The domain has some characteristics, which we are trying to learn (Model) Objective To minimise the error in prediction Types of Learning Supervised Learning Unsupervised Learning Semi-Supervised Learning Active Learning
Supervised Learning Classification / Regression problem Where some samples of data (Training data) with the correct class labels are provided. Using knowledge from training data, the classifier/ regressor model is learnt i.e. Some correspondence between input (X) & output (Y) given i.e. Learn some function f : f(X) Y f may be probabilistic/deterministic Learning the model Fitting the parameters of model to minimise prediction error Model can then be tested on test-data
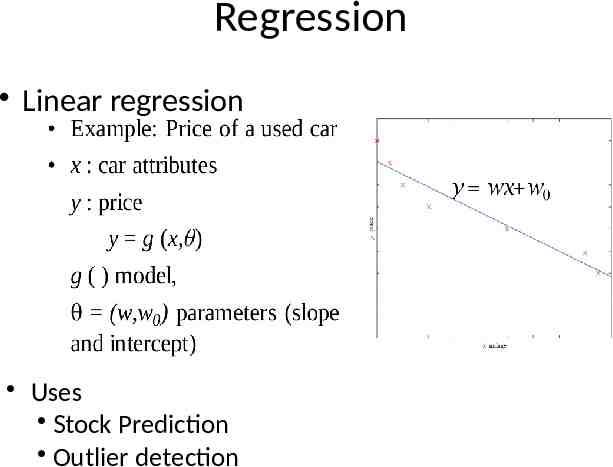
Regression Linear regression Uses Stock Prediction Outlier detection
Regression
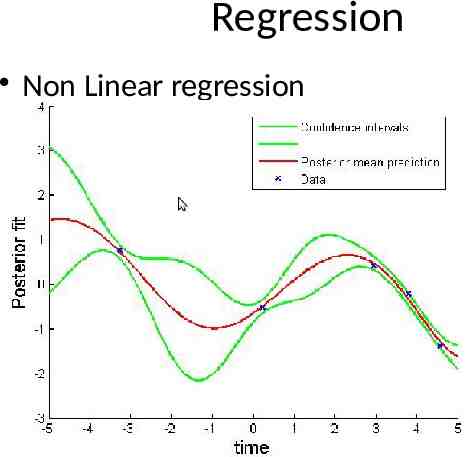
Regression Non Linear regression
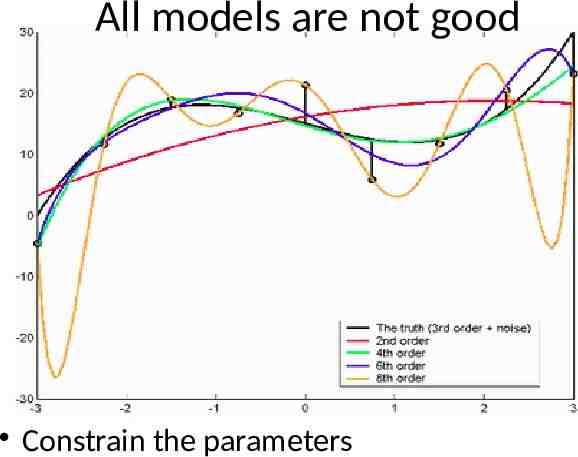
All models are not good Constrain the parameters
Classification
Supervised Classification example Class label f1 f2 f3 f4 d1 BearHead d2 ? d3 DuckHead LionHead Source: LHI Animal Faces Dataset
Classification Example: Credit Scoring Goal: Differentiating between high-risk and lowrisk customers based on their income and savings Discriminant: IF income θ1 AND savings θ2 THEN low-risk ELSE high-risk Discriminant is called 'hypothesis' Input attribute space is called 'Feature Space' Here Input data is 2-dimensional and the output is binary
Other applications
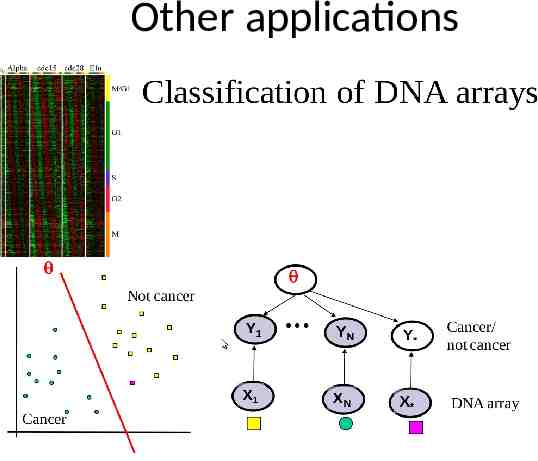
Building non-linear classifiers Curse of dimensionality
Application
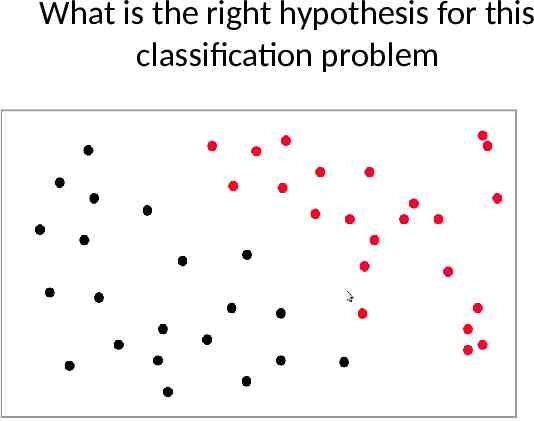
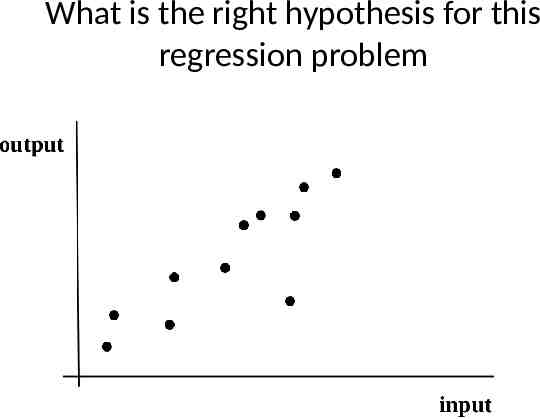
What is the right hypothesis?
What is the right hypothesis for this classification problem
What is the right hypothesis for this regression problem
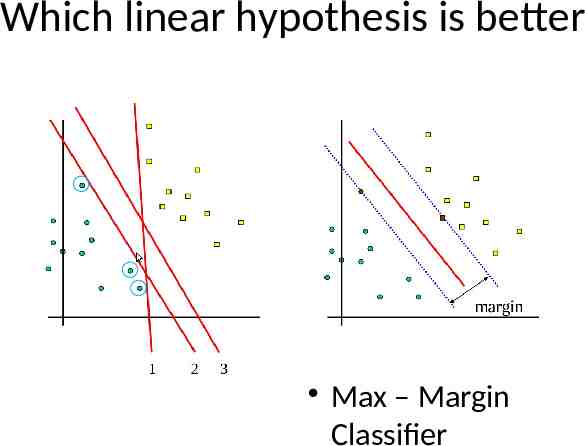
Which linear hypothesis is better Max – Margin Classifier
Other considerations Feature extraction: which are the good features that characterise the data Model selection: picking the right model using some scoring/fitting function: It is important not only to provide a good predictor, but also to assess accurately how “good” the model is on unseen test data So a good performance estimator is needed to rank the model Model averaging: Instead of picking a single model, it might be better to do a weighted average over the bestfit models
Which hypothesis is better? Unless you know something about the distribution of problems your learning algorithm will encounter, any hypothesis that agrees with all your data is as good as any other. You have to make assumptions about the underlying features. Hence learning is inductive, not deductive.
Unsupervised Learning Labels may be too expensive to generate or may be completely unknown There is lots of training data but with no class labels assigned to it
? Source: LHI Animal Faces Dataset
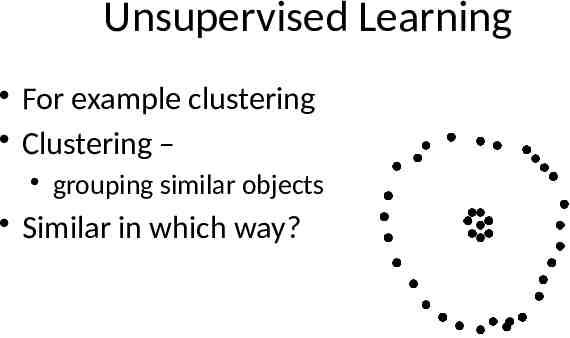
Unsupervised Learning For example clustering Clustering – grouping similar objects Similar in which way?
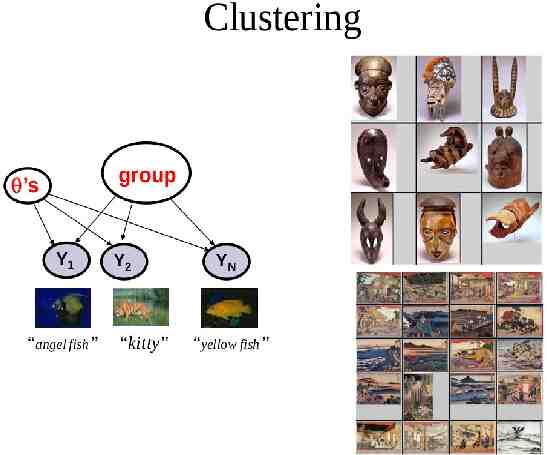
Clustering
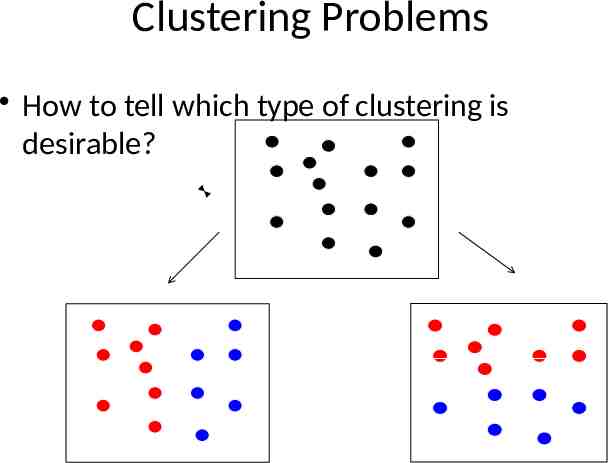
Clustering Problems How to tell which type of clustering is desirable?
Semi-Supervised Learning Supervised learning Additional unlabeled data Unsupervised learning Additional labeled data Learning Algorithm: Start from the labeled data to build an initial classifier Use the unlabeled data to enhance the model Some Techniques: Co-Training: two or more learners can be trained using an independent set of different features Or to model joint probability distribution of the features and labels
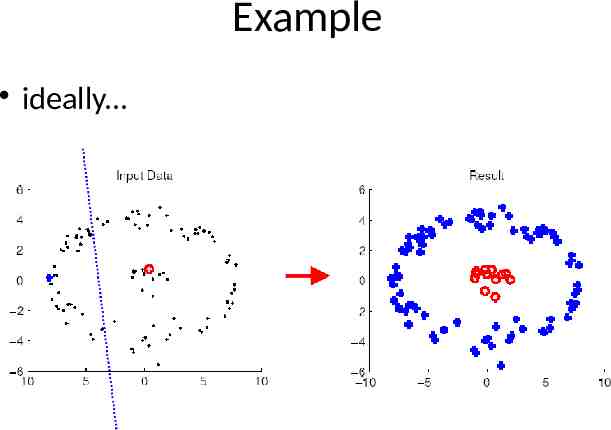
Example ideally.
Active Learning Unlabeled data is easy to obtain; but labels may be very expensive For e.g. Speech recognizer Active Learning Initially all data labels are hidden There is some charge for revealing every label Active Learner will interactively query the user for labels By intelligent querying, a lot less number of labels will be required than in usual supervised training But a bad algorithm might focus on unimportant or invalid examples
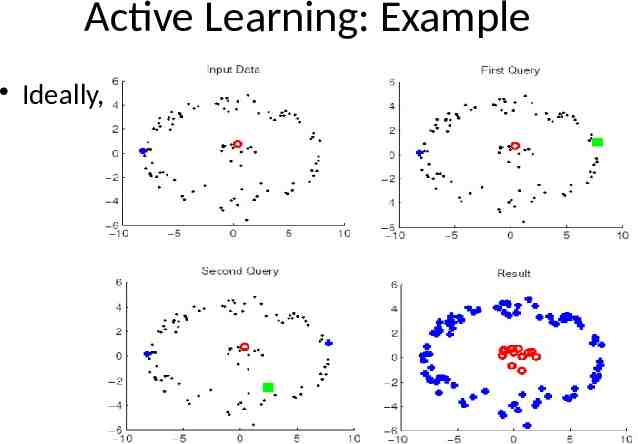
Active Learning: Example Ideally,
Active Learning: Example Suppose data lies on a real line and the classifier discriminant looks like Theoretically we can prove that if the actual data distribution P can be classified using some hypothesis hw in H H {hw}: hw(x) 1 if x w, 0 otherwise Then to get a classifier with error 'e', we just need O(1/e) random labeled samples from P Now labels are sequences of 0s and 1s Goal is to discover the pt 'w' where transition occurs Find that using binary search So only log (1/e) samples queried Exponential improvement in terms of number of samples required
Active Learning and survelliance
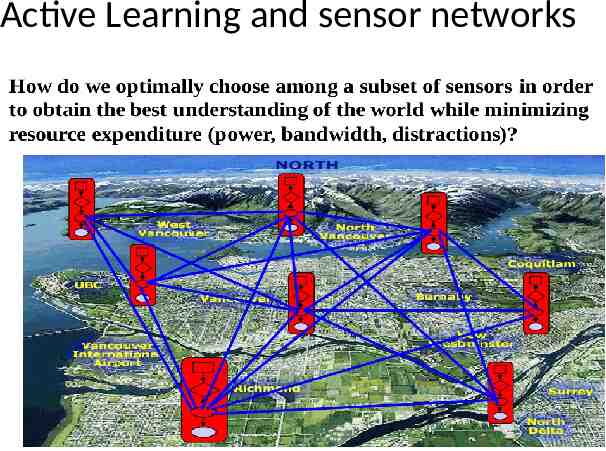
Active Learning and sensor networks
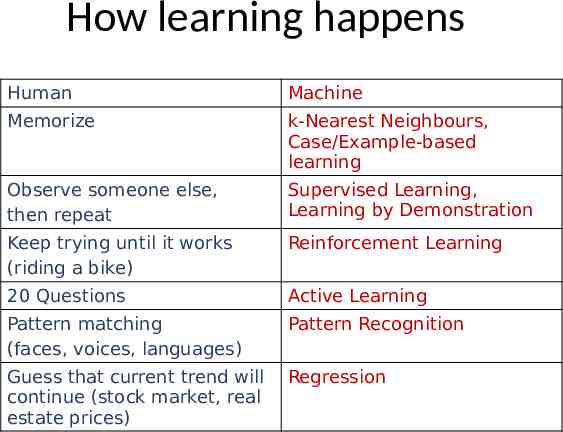
How learning happens Human Machine Memorize k-Nearest Neighbours, Case/Example-based learning Observe someone else, then repeat Supervised Learning, Learning by Demonstration Keep trying until it works (riding a bike) Reinforcement Learning 20 Questions Active Learning Pattern matching (faces, voices, languages) Pattern Recognition Guess that current trend will continue (stock market, real estate prices) Regression
COURSE INFORMATION
Tools and Resources Weka: http://www.cs.waikato.ac.nz/ml/weka Scilab: http://www.scilab.org/ R-software: http://www.r-project.org/ RapidMiner: http://rapid-i.com/content/view/181/190/ Orange: http://orange.biolab.si/ KNIME: http://www.knime.org/ SVM Light: http://svmlight.joachims.org ShogunToolbox: http://www.shogun-toolbox.org/ Elefant: http://elefant.developer.nicta.com.au Google prediction API: http://code.google.com/apis/predict/
Course Info Pre-requisites for course Probability & Statistics Basics of convex optimization Basics of linear algebra Online Materials Online class-notes : http://www.cse.iitb.ac.in/ cs725/notes/classNotes/ Username: cs717 Password: cs717 student Andrew Ng. Notes http://www.stanford.edu/class/cs229/materials.html and video lecture series http://videolectures.net/andrew ng/ Main Text Book: Pattern Recognition and Machine Learning – Christopher Bishop Reference: Hastie, Tibshirani, Friedman The elements of Statistical Learning Springer Verlag






