F5-HD: Fast Flexible FPGA-based Framework for Hyperdimensional






















23 Slides4.19 MB
F5-HD: Fast Flexible FPGA-based Framework for Hyperdimensional Computing Sahand Salamat, Mohsen Imani, Behnam Khaleghi, Tajana Šimunić Rosing System Energy Efficiency Lab University of California San Diego System Energy Efficiency Lab seelab.ucsd.edu
Machine Learning is Changing Our Life Healthcare Self Driving Cars Smart Robots Finance Gaming System Energy Efficiency Lab seelab.ucsd.edu 2
High Dimensional Data Hyperdimensional (HD) Computing Encode Image Classification Activity Recognition HyperDimensional Computing General and scalable Regression . Robust to noise Light weight Clustering System Energy Efficiency seelab.ucsd.edu [1] Kanerva, Pentti. "Hyperdimensional computing: An introduction to computing in distributed representation with high-dimensional random vectors." Cognitive Computation 1.2 (2009): 139-159. Lab[2] Imani, Mohsen, et al. "Exploring hyperdimensional associative memory." 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2017. 3
HD Computing . Training Retraining Cat hypervector Cat hypervector -1 1 -1 -1 1 . . . 1 Encoding Encoding -1 -1 1 -1 -1 . . . 1 Dog hypervector -1 1 -1 -1 1 . . . 1 -1 -1 1 -1 -1 . . . 1 . Dog hypervector Similarity Check Inference Encoding 1 1 1 -1 -1 . . . 1 System Energy Efficiency Lab seelab.ucsd.edu Encoded hypervector 4
HD dataflow Similarity Check Hamming Distance for binary model Cosine similarity for non-binary model Base HV Memory Features (#Div) Permutation Encoder Dhv dimensions Train input @ Class i Encoder Similarity Check Tra in H V Class 1 HV HD Model Class i HV Class C HV Training σ Class 1 Class x HD Model (class HVs) Class C System Energy Efficiency Lab seelab.ucsd.edu Class 0 Inference σ 5
HD Acceleration HD thousands of bit-level additions, multiplication and accumulation These operations can be parallelized in dimension level FPGAs can provide huge parallelism FPGA design requires extensive hardware expertise FPGAs have long design cycles Application-specific template-based design Several template-based FPGA implementation for neural networks [Micro’16] [FCCM’17][FPGA’18] No FPGA implementation framework for HD! [1] Sharma, Hardik, et al. "From high-level deep neural models to FPGAs." The 49th Annual IEEE/ACM International Symposium on Microarchitecture. IEEE Press, 2016 [2] Guan, Yijin, et al. "FP-DNN: An automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates." 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). IEEE, 2017. [3] Shen, Junzhong, et al. "Towards a uniform template-based architecture for accelerating 2d and 3d cnns on fpga." Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, 2018. System Energy Efficiency Lab seelab.ucsd.edu 6
-HD F5 F5-HD: Fast Flexible FPGA-based Framework for Refreshing Hyperdimensional Computing First automated framework for FPGA-based acceleration of HD computing Input : 20 lines of C code Output: 2000 lines of Verilog HDL code Supports training, retraining, and inference of HD Kintex, Virtex, Spartan FPGA families Supports different Precisions Fixed-point Power of two Binary System Energy Efficiency Lab seelab.ucsd.edu 7
F5-HD Overview 1. 2. 3. 4. Model Specification Design Analyzer Model Generator Scheduler Hand-optimized Templates Enc. Model PU PE Verilog module PE() ; . . . endmodule Design Analyzer System Energy Efficiency Lab seelab.ucsd.edu Model Generator Verilog code generation Memory interface generation F5-HD Scheduler Accelerator Controller HD Scheduler 1. Training 2. Retraining 3. Inference Interface Training data Inference data Off-Chip Memory 8
Baseline Encoding HV0 : b 999 b 998 b 997 b2 HV1 : b 999 b 998 b 997 b2 HV0 P (HV1) F 4 P 2 (HV0) P 3 (HV0) {b2,b1,b0} Encoded HV b1 b0 Base Hypervectors b1 b0 b 999 b 998 b 997 b2 S 3 b1 b 999 b 998 b 997 b2 b1 b0 b 999 b 998 b 997 b2 b1 b0 b 999 b 998 b 997 b2 b1 b0 b0 b2HV0 b1HV1 b0HV0 b999HV0b1HV0 b0HV1 b999HV0 b998HV b00HV0 b999HV1 b998HV0 b997HV0 b997,b998,b999,b0,b1,b2 of base HVs are needed System Energy Efficiency Lab seelab.ucsd.edu 9
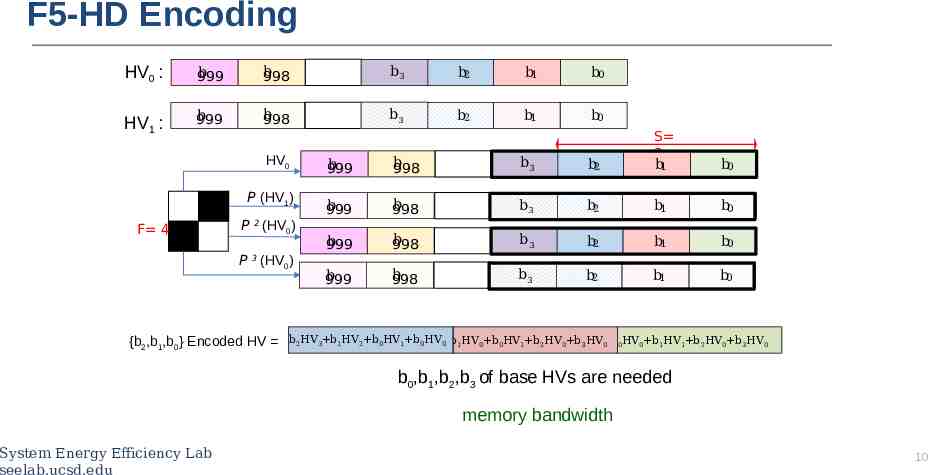
F5-HD Encoding HV0 : b 999 b 998 b3 b2 b1 b0 HV1 : b 999 b 998 b3 b2 b1 b0 HV0 P (HV1) F 4 P 2 (HV0) P (HV0) b 999 b 998 b3 b2 S 3 b1 b 999 b 998 b3 b2 b1 b0 b 999 b 998 b3 b2 b1 b0 b 999 b 998 b3 b2 b1 b0 b0 3 {b2,b1,b0} Encoded HV b2HV3 b1HV2 b0HV1 b0HV0 b1HV0 b0HV1 b2HV0 b3HV0 b0HV0 b1HV1 b2HV0 b3HV0 b0,b1,b2,b3 of base HVs are needed memory bandwidth System Energy Efficiency Lab seelab.ucsd.edu 10
F5-HD Encoder Architecture Hand-optimized Templates Encoding HD Model PU #Features b 999 b 999 b 998 b 997 b2 b 997 b2 b1 b1 b0 b0 PE b 999 Design Analyzer b 998 b 998 b 997 b2 b1 b1 b0 b0 Instead of using adders F5-HD uses LUTs Model Generator Scheduler 36 bits System Energy Efficiency Lab seelab.ucsd.edu 11
F5-HD Architecture dD-1 dD-2 Encoded HV d2 d1 d0 Hand-optimized Templates PE Design Analyzer Model Generator PU0 HV0 HV1 Scheduler HVC-1 System Energy Efficiency Lab seelab.ucsd.edu Controller HD Model PU1 PUP-1 Comparator PU Controller Scheduler HD Model Training/ Retraining Encoding Model Update Associative Search 12
F5-HD Processing Unit/Engine Hand-optimized Templates Encoding HD Model PU PE Processing Unit Finding similarity between input and a class Processing Engine Multiplication and Accumulation Design Analyzer Model Generator Scheduler X X X Class HV Pre-fetch Mem d1 d0 dPE-1 PU Controller PE PE PE PE System Energy Efficiency Lab seelab.ucsd.edu 13
F5-HD Steps: Design Analyzer Hand-optimized Templates Encoding Design Analyzer Selects the model precision Create a power model as a function of parallelization maximize the resource utilization with respect to the HD Model PU PE Design Analyzer user’s power budget Model Generator Scheduler System Energy Efficiency Lab seelab.ucsd.edu Calculating the parallelization factor 14
F5-HD steps Model Generator Hand-optimized Templates Encoding HD Model PU PE Instantiates hand-optimized template modules Generates memory interface and Verilog HDL code Scheduler HD.v Adds scheduling and controlling signals module HD (clk, rst, out); HD.cpp Design Analyzer Model Generator Void main () { //Application NumInFeatures 700; NumClasses 5; NumTrainingData 50000; Scheduler //User Spec. PowerBudget 5; HDModel “binary”; //FPGA Spec FPGA “XC7k325T ”; FPGAPowerModel “p.model”; System Energy Efficiency Lab seelab.ucsd.edu } F5-HD MemInterface ( ); InputBuffer ( ); HDEncoder ( ); Training Retraining ( ); HDModel ( ); AssociativeSearch ( ); Scheduler ( ); Controller ( ); endmodule module PU( ); endmodule 15
Experimental Setup F5-HD Results are compared to Including user interface and code generation has been implemented in C on CPU Hand-optimized templates implemented in Verilog HDL Generates synthesizable Verilog implementation Supports Kintex, Virtex, and Spartan FPGA families Intel i7 7600 CPU and AMD R9 390 GPU Datasets: Speech Recognition (ISOLET) [31] Activity Recognition (UCIHAR) [32] Physical Activity Monitoring (PAMAP) [33] Face Detection [34] System Energy Efficiency Lab seelab.ucsd.edu 16
Experimental Results F5-HD reduces the design time significantly Writing FPGA implementation takes 100 days ( 2000 lines of code) [FPL’16] Preparing F5-HD input takes 1 hour ( 20 lines of code) F5-HD is 5.1x faster than HLS implemented hardware 5000*10 3 Throughput Classification/sec 4500 4000 HLS 3500 F5-HD 3000 2500 2000 1500 1000 500 0 Face UCIHAR PAMAP ISOLET Kapre, Nachiket, and Samuel Bayliss. "Survey of domain-specific languages for FPGA computing." 2016 26th International Conference on Field Programmable Logic and System Energy Efficiency Lab Applications (FPL). IEEE, 2016. seelab.ucsd.edu 17
Experimental Results: Encoding F5-HD encoder For 64 features: 1.5 higher throughput For 512 features: 1.9 higher throughput 1600 Maximum encoding capacity (dimensions/cycle) 1400 Dimensions/cycle 1200 Baseline F5-HD Encoder 1000 800 600 400 200 System Energy Efficiency Lab seelab.ucsd.edu 0 64 128 #features 256 512 18
Experimental Results: Training F5-HD vs GPU: 87 more energy efficient 8 faster F5-HD vs CPU: 548x more energy efficient 148x faster System Energy Efficiency Lab seelab.ucsd.edu 19
Experimental Results: Retraining F5-HD vs GPU: 7.6 more energy efficient 1.6 faster F5-HD vs CPU: 70x more energy efficient 10x faster System Energy Efficiency Lab seelab.ucsd.edu 20
Experimental Results: Inference Energy and execution time improvement during inference 2X, 260X faster than GPU, and CPU 12X, 620X more energy efficient than GPU and CPU System Energy Efficiency Lab seelab.ucsd.edu 21
Experimental Results: HD precision Binary HD is 4.3x faster but 20.4% less accurate than fixed-point model Power of two model is 3.1x faster but 5.8% less accurate than fixed point model System Energy Efficiency Lab seelab.ucsd.edu Accuracy ISOLET UCIHAR PAMAP FACE Binary HD 88.1% 77.4% 85.7% 48.5% Power-of-two HD 90.3% 88.0% 90.8% 89.6% Fixed-point HD 95.5% 94.6% 94.5% 96.9% 22
Conclusion F5-HD: an automated framework for FPGA-based acceleration of HD computing F5-HD reduces the design time from 3 months to less than an hour F5-HD supports: Fixed-point, power of two and binary models Training, retraining, and inference of HD Xilinx FPGAs F5-HD is: 5x faster than HLS tool implementation 87x more energy efficient and 8x faster during training than GPU 12x more energy efficient and 2x faster during inference than GPU System Energy Efficiency Lab seelab.ucsd.edu 23






