Elements of Reinforcement Learning Hongning Wang CS@UVA















17 Slides1.70 MB
Elements of Reinforcement Learning Hongning Wang CS@UVA
Outline Action vs. reward State vs. value Policy Model CS@UVA RL2022-Fall 2
Action taking in reinforcement learning Making a choice out of presented options Out of agent’s control! Discrete actions Move left or right in Atari Breakout game Recommend an item to a target useris learning what to do — how Reinforcement learning to map situations to actions — so as to maximize a Continuous actions numerical reward signal. Drone/robotics control - Sutton & Barto, 2018 Model selection/optimization with a black box function Zeroth order optimization CS@UVA RL2022-Fall 3
Reward in reinforcement learning A scalar feedback signal about the taken action Suggest good/bad immediate consequence of the action Score in Atari game User clicks/purchase in a recommender system Change of black-box function value Delayed feedback GO game Generate a sentence in chat-bot Goal of learning – maximize cumulative rewards Reward hypothesis: “All goals can be described by the maximization of expected cumulative reward.” CS@UVA RL2022-Fall 4
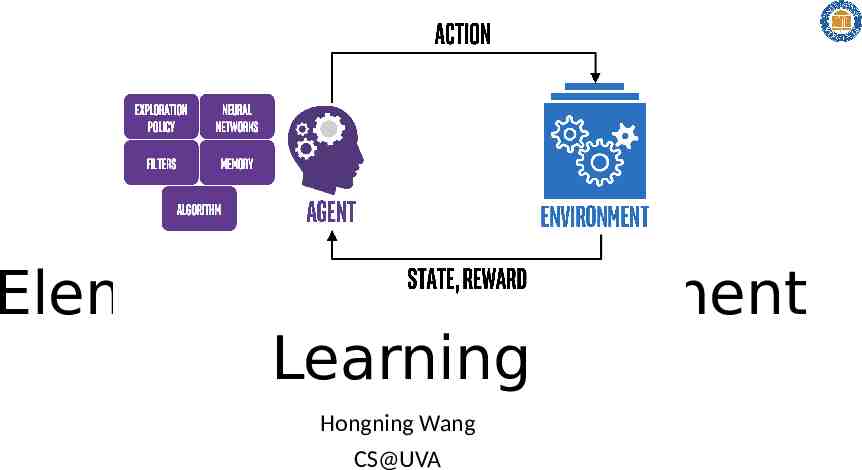
How to take an action With respect to the current observation Observation Action Reward CS@UVA RL2022-Fall 5
How to take an action With respect to history How did we reach the current observation 𝑜1 , 𝑎 1 ,𝑟 1 , 𝑜2 ,𝑎 2 ,𝑟 2 , , 𝑜𝑡 , 𝑎𝑡 History Current observation Why do we care about history? In case this has happened before Generalize from history State – a function of history How to construct states? CS@UVA RL2022-Fall 6
How to take an action To maximize cumulative reward in future 𝑜1 , 𝑎1 ,𝑟 1 , 𝑜2 ,𝑎2 ,𝑟 2 , , 𝑜𝑡 ,𝑎𝑡 ,𝑟 𝑡 , 𝑜𝑡 1 , 𝑎𝑡 1 ,𝑟 𝑡 1 , ,𝑜𝑇 , 𝑎𝑇 ,𝑟 𝑇 History Value function State-action value 𝑣 𝜋 ( 𝑠 𝑡 , 𝑎 𝑡 ) 𝑬 𝜋 With respect to a particular policy! Future [ 𝑇 𝑖 𝑡 𝛾 𝑟 𝑖 𝑡 1 𝑖 𝑡 ] Oftentimes approximation is needed Why do we need this? State value Goal: choose an action that leads to a highest value state CS@UVA RL2022-Fall 7
Action taking by value function Shortest path as an example State: current node Action: take an outgoing edge Reward: (negative) edge weight Value: shortest distance to the target node 4 𝑣 ( 𝑎 ) 9 a 2 Now how should we act? 𝑣 ( 𝑔 ) 2 𝑣 ( 𝑑 ) 4 2 1 b d 𝑣 ( 𝑏 ) 5 9 4 e c 3 𝑣 ( 𝑒 ) 7 𝑣 ( 𝑐 ) 8 2 g 4 5 𝑣 (𝑡 ) 0 t 2 f 𝑣 ( 𝑓 ) 2 W.r.t. optimal policy CS@UVA RL2022-Fall 8
Action taking by value function Shortest path as an example State: current node Action: take an outgoing edge Now how should we act? Reward: (negative) edge weight 𝑣 ( 𝑔 ) 2 Value: expected shortest distance to the target node 𝑣 ( 𝑏 ) 5 4 𝑣 ( 𝑒 ) 5 0.5 𝑣 ( 𝑡 ) 0.5 𝑣 ( 𝑓 ) 6 a 1 b 𝑣 ( 𝑑 ) 4 2 0 .2 P 4 c 𝑣 ( 𝑐 ) 8 CS@UVA RL2022-Fall t d P 0.5 e 3 2 4 9 P 0 .8 2 9.2 g 𝑣 (𝑡 ) 0 2 𝑣 ( 𝑒 ) 6 5 f P 0.5 𝑣 ( 𝑓 ) 2 Example credit: Jiang, UIUC CS-498 W.r.t. optimal policy 9
Policy A mapping from state to action By the agent! Deterministic or stochastic Notation-wise: v.s., 𝑣 ( 𝑔 ) 2 Optimal policy maximizes value 𝑣 ( 𝑑 ) 4 2 1 b d 𝑣 ( 𝑏 ) 5 9 4 Value function gives us optimal policy? 4 𝑣 ( 𝑎 ) 9 𝜋 ( 𝑎 ) 𝑏 a 2 e c 3 𝑣 ( 𝑒 ) 7 𝑣 ( 𝑐 ) 8 2 g 4 5 𝑣 (𝑡 ) 0 t 2 f 𝑣 ( 𝑓 ) 2 𝜋 ( 𝑓 ) 𝑡 𝜋 ( 𝑐 ) 𝑑 CS@UVA RL2022-Fall 10
Prediction vs. Control Prediction Evaluate value function given a policy Sort of E-step vs., M-step? Control Optimize policy 𝑣 ( 𝑔 ) 2 𝑣 ( 𝑑 ) 4 2 1 b d 𝑣 ( 𝑏 ) 5 9 4 4 𝑣 ( 𝑎 ) 10.6 a 𝑣 (𝑡 ) 0 2 g t 2 4 Found a way to improve current policy f Recall genetic programming or simulated annealing, how would they optimize the current policy? 2 e 3 𝑣 ( 𝑒 ) 9 𝑣 ( 𝑐 ) 10.3 c 5 𝑣 ( 𝑓 ) 0.5 ( 2 ) 0.5 ( 4 2 ) 4 W.r.t. a random policy CS@UVA RL2022-Fall 11
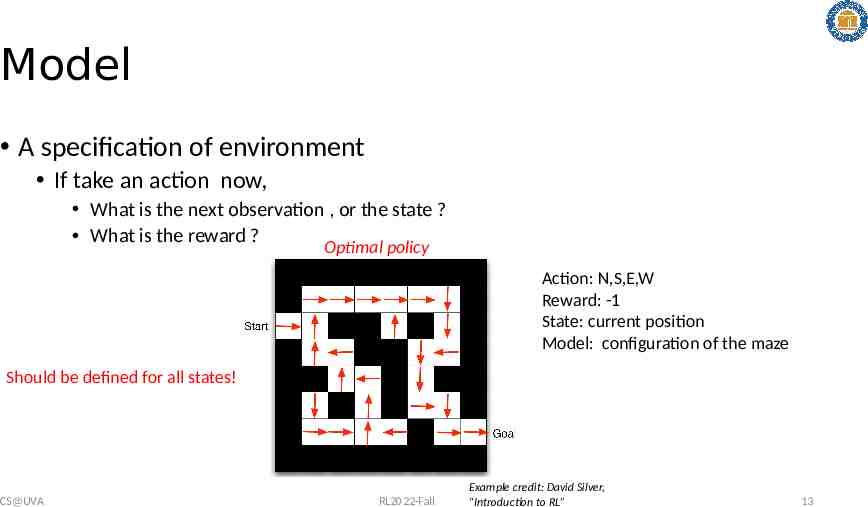
Model A specification of environment If take an action now, What is the next observation , or the state ? What is the reward ? Action: N,S,E,W Reward: -1 State: current position Model: configuration of the maze E CS@UVA RL2022-Fall Example credit: David Silver, “Introduction to RL” 12
Model A specification of environment If take an action now, What is the next observation , or the state ? What is the reward ? Optimal policy Action: N,S,E,W Reward: -1 State: current position Model: configuration of the maze Should be defined for all states! CS@UVA RL2022-Fall Example credit: David Silver, “Introduction to RL” 13
Model A specification of environment If take an action now, What is the next observation , or the state ? What is the reward ? Value under optimal policy Action: N,S,E,W Reward: -1 State: current position Model: configuration of the maze CS@UVA RL2022-Fall Example credit: David Silver, “Introduction to RL” 14
(Estimated) Model An agent’s perspective of the environment Estimated from history – the learning part If I take an action now, What might be the next observation , or the state ? What might be the reward ? CS@UVA RL2022-Fall Action: N,S,E,W Reward: -1 for visited states so far State: current position Model: estimated configuration of the maze 15
Models Environment model Estimated environment model Ground-truth construction Might be given sometimes CS@UVA Agent’s belief Might not be truthful RL2022-Fall Agent’s model The mathematical/ statistical formulation used by the agent for estimation 16
Takeaways RL agents take actions with respect to history/state Their goal is to find highest value states Model is about the environment, and can be estimated by the agent CS@UVA RL2022-Fall 17






