EFFICIENT HIGH PERFORMANCE COMPUTING IN THE CLOUD KEYNOTE, VTDC’15 Dr.
































64 Slides3.06 MB
EFFICIENT HIGH PERFORMANCE COMPUTING IN THE CLOUD KEYNOTE, VTDC’15 Dr. Abhishek Gupta PhD, University of Illinois at Urbana Champaign [email protected] 1 06/15/2015
What is HPC? 2
HPC Computationally intensive applications Aggregating computing power HPC traditionally restricted to a niche segment few influential labs. Why? 3
What is Cloud Computing? 4
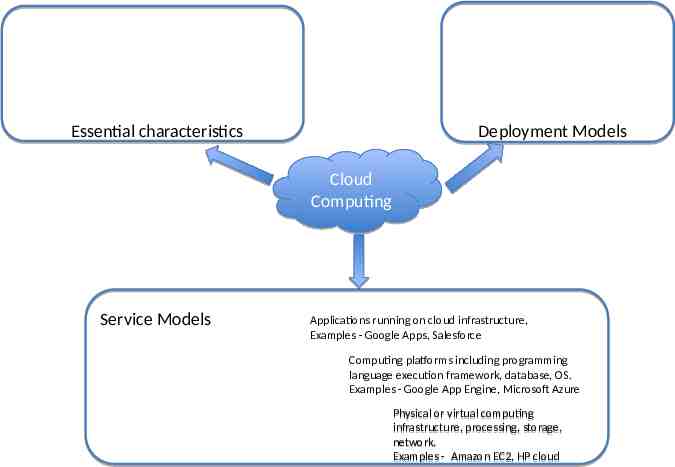
Deployment Models Essential characteristics Cloud Computing Service Models Applications running on cloud infrastructure, Examples - Google Apps, Salesforce Computing platforms including programming language execution framework, database, OS. Examples - Google App Engine, Microsoft Azure Physical or virtual computing infrastructure, processing, storage, network. Examples - Amazon EC2, HP cloud
What do we mean by HPC /in Cloud 6
Marriage of two very different computing paradigm Learn from best known principles and apply to each other 7
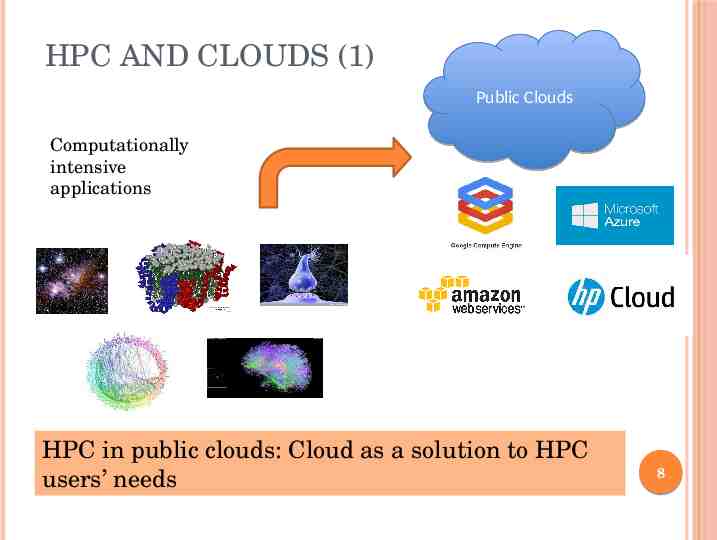
HPC AND CLOUDS (1) Public Clouds Computationally intensive applications HPC in public clouds: Cloud as a solution to HPC users’ needs 8
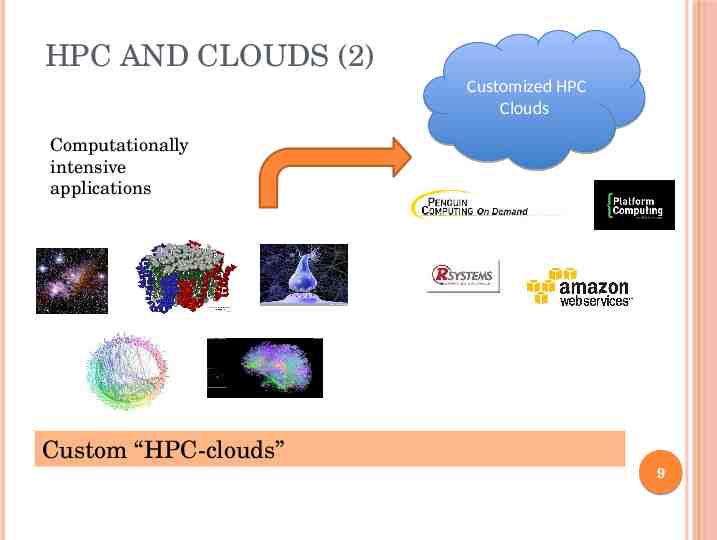
HPC AND CLOUDS (2) Customized HPC Clouds Computationally intensive applications Custom “HPC-clouds” 9
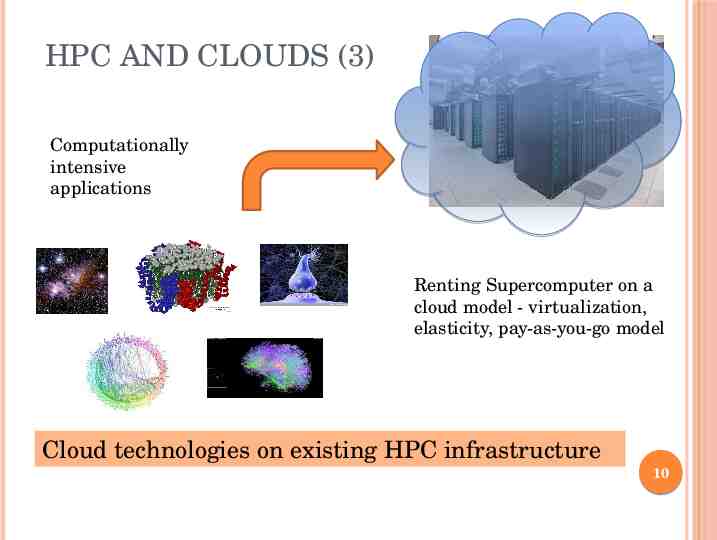
HPC AND CLOUDS (3) Computationally intensive applications Renting Supercomputer on a cloud model - virtualization, elasticity, pay-as-you-go model Cloud technologies on existing HPC infrastructure 10
HPC AND CLOUDS (4) Computationally intensive applications Public Clouds Hybrid HPC cloud infrastructure – bursting to cloud 11
HPC AND CLOUDS HPC in public clouds Cloud as a solution to HPC users’ needs HPC as a service – ubiquity Cloud technologies on existing HPC infrastructure Virtualization, elasticity, pay-as-you-go model Renting Supercomputer on a cloud model Custom “HPC-clouds” Hybrid HPC cloud – bursting to cloud Public cloud very appealing for HPC users, why? 12
MOTIVATION: WHY CLOUDS FOR HPC ? Rent vs. own, pay-as-you-go No startup/maintenance cost, cluster create time Elastic resources No risk e.g. in under-provisioning Prevents underutilization Benefits of virtualization Flexibility and customization Security and isolation Migration and resource control Cloud for HPC: A cost-effective and timely solution? Multiple providers – Infrastructure as a Service 13
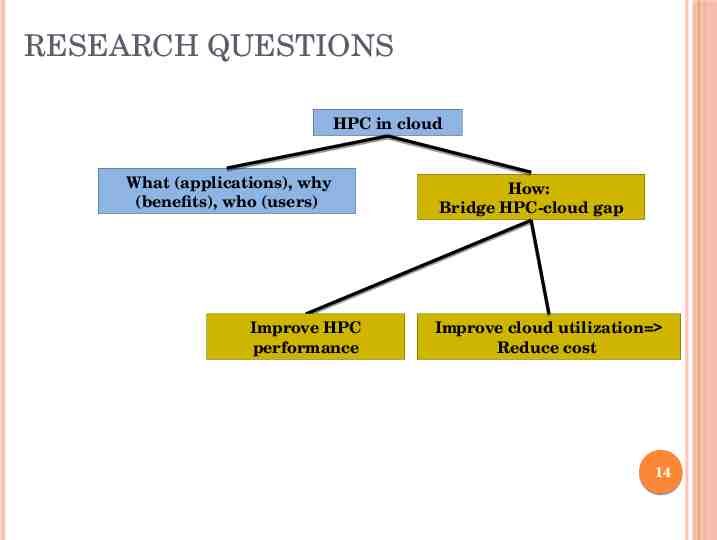
RESEARCH QUESTIONS HPC in cloud What (applications), why (benefits), who (users) Improve HPC performance How: Bridge HPC-cloud gap Improve cloud utilization Reduce cost 14
Quick Philosophical Analogy 15
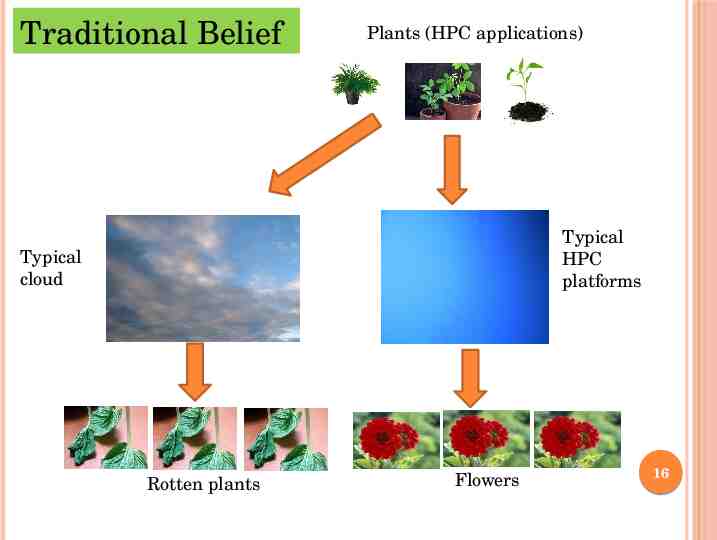
Traditional Belief Plants (HPC applications) Typical HPC platforms Typical cloud Rotten plants Flowers 16
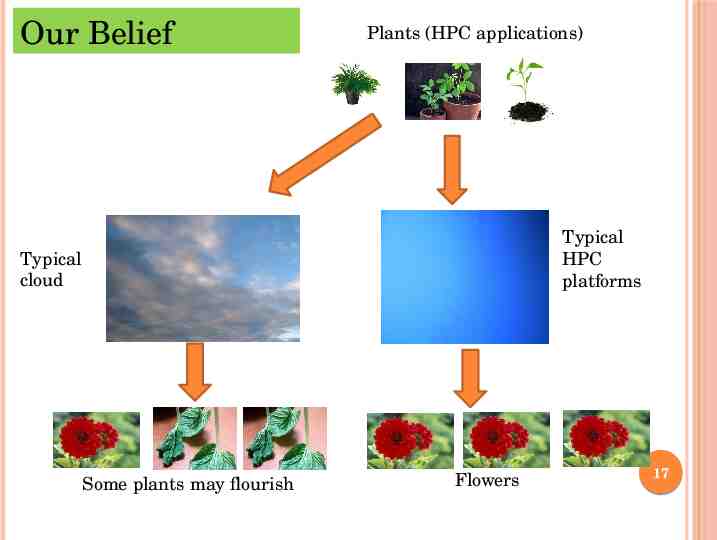
Our Belief Plants (HPC applications) Typical HPC platforms Typical cloud Some plants may flourish Flowers 17
Make HPC Cloud-Aware Plants (HPC applications) Typical HPC platforms Typical cloud 18 Flowers
Plants (HPC applications) Make Clouds HPC-Aware Typical HPC platforms Typical cloud Flowers 19
OUTLINE Performance analysis HPC cloud divide Bridging the gap between HPC and cloud HPC-aware clouds Application-aware cloud scheduler and VM consolidation Cloud-aware HPC Dynamic load balancing: improve HPC performance Parallel runtime for malleable jobs: improve utilization Models, cost analysis and multiple platforms in cloud Lessons, conclusions, impact, and future work 20
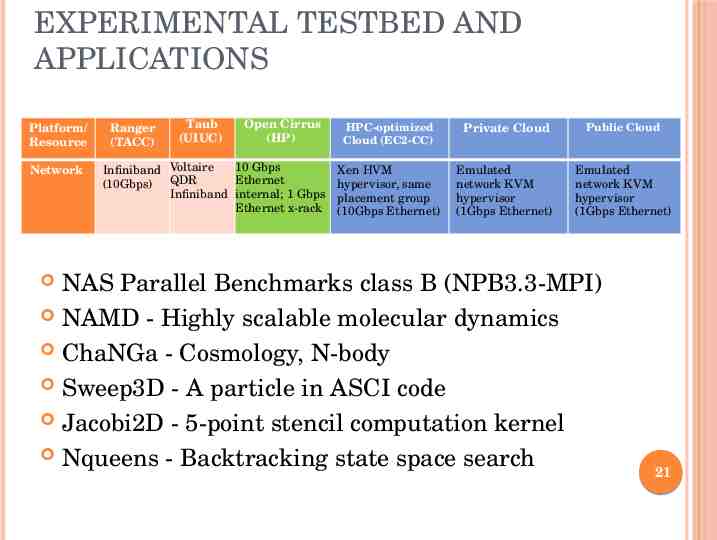
EXPERIMENTAL TESTBED AND APPLICATIONS Platform/ Resource Network Ranger (TACC) Taub (UIUC) Open Cirrus (HP) 10 Gbps Infiniband Voltaire Ethernet (10Gbps) QDR Infiniband internal; 1 Gbps Ethernet x-rack HPC-optimized Cloud (EC2-CC) Private Cloud Public Cloud Xen HVM hypervisor, same placement group (10Gbps Ethernet) Emulated network KVM hypervisor (1Gbps Ethernet) Emulated network KVM hypervisor (1Gbps Ethernet) NAS Parallel Benchmarks class B (NPB3.3-MPI) NAMD - Highly scalable molecular dynamics ChaNGa - Cosmology, N-body Sweep3D - A particle in ASCI code Jacobi2D - 5-point stencil computation kernel Nqueens - Backtracking state space search 21
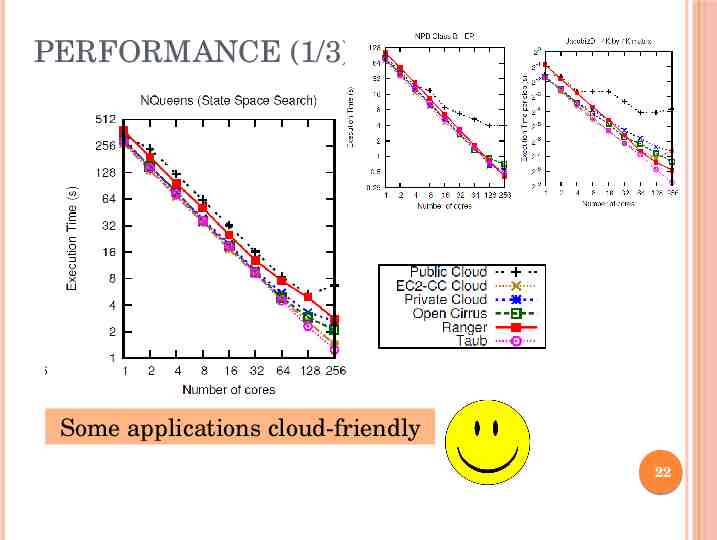
PERFORMANCE (1/3) Some applications cloud-friendly 22
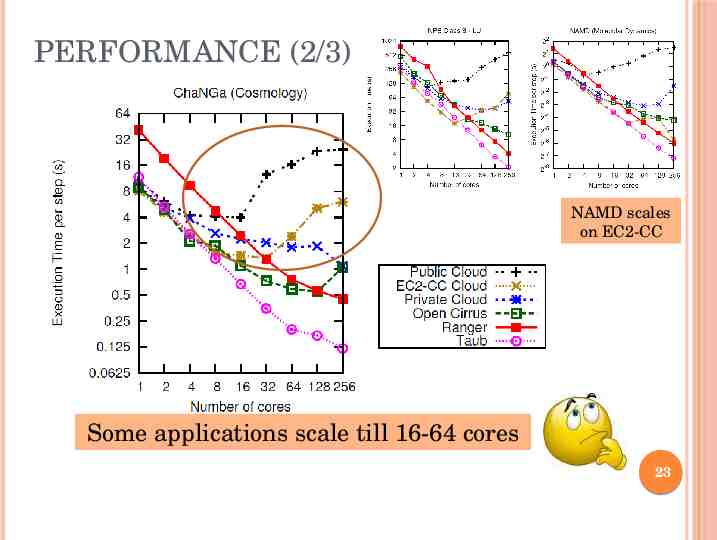
PERFORMANCE (2/3) NAMD scales on EC2-CC Some applications scale till 16-64 cores 23
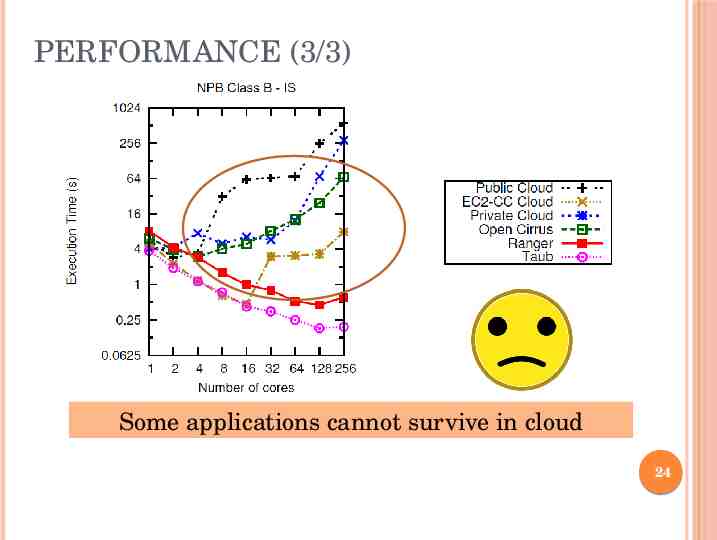
PERFORMANCE (3/3) Some applications cannot survive in cloud 24
PERFORMANCE ANALYSIS Co-relation: communication and performance Communication-intensive applications perform poorly in clouds CC2-EC2: Bandwidth sensitive ok, latency-sensitive not ok Cloud message latencies (150-200μs) vs. supercomputers (4μs) Bandwidths off by 2 orders of magnitude (10Gbps vs. 100Mbps) Except : CC2-EC2 bandwidth comparable to supercomputers Commodity network virtualization overhead (e.g. 100μs latency) Thin VMs, Containers, CPU affinity Grain size control and larger problem sizes Noise and performance variability in cloud Similar network performance for public and private cloud. Then, why does public cloud perform worse? Scheduling policy allowed multi-tenancy Infrastructure was heterogeneous 25
MULTI-TENANCY AND HETEROGENEITY CHALLENGE Multi-tenancy: Cloud providers run profitable business by improving utilization of underutilized resources Cluster-level by serving large number of users, Server-level by consolidating VMs of complementary nature Heterogeneity: Cloud economics is based on: Creation of a cluster from existing pool of resources and Incremental addition of new resources. Heterogeneity and multi-tenancy intrinsic in clouds, driven by cloud economics but For HPC, one slow processor all underutilized processors 26
HPC-CLOUD DIVIDE SUMMARY HPC Performance Dedicated execution Homogeneity HPC-optimized interconnects, OS Not cloud-aware Cloud Service, cost, utilization Multi-tenancy Heterogeneity Commodity network, virtualization Not HPC-aware Mismatch: HPC requirements and cloud characteristics. How to bridge this gap? A. Gupta et al. “The Who, What, Why and How of High Performance Computing in the Cloud” in IEEE CloudCom 2013 Best Paper 27
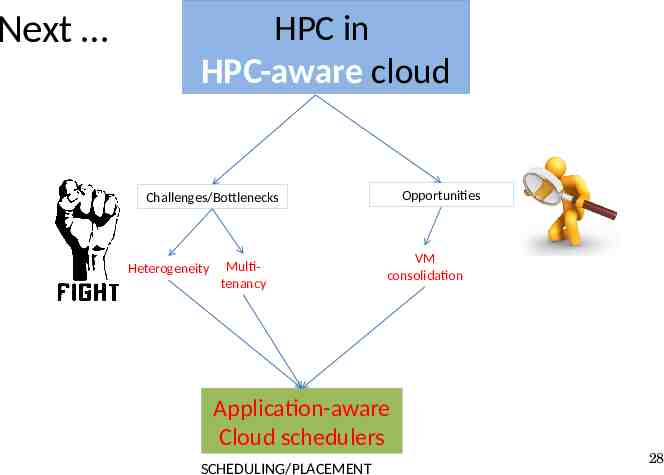
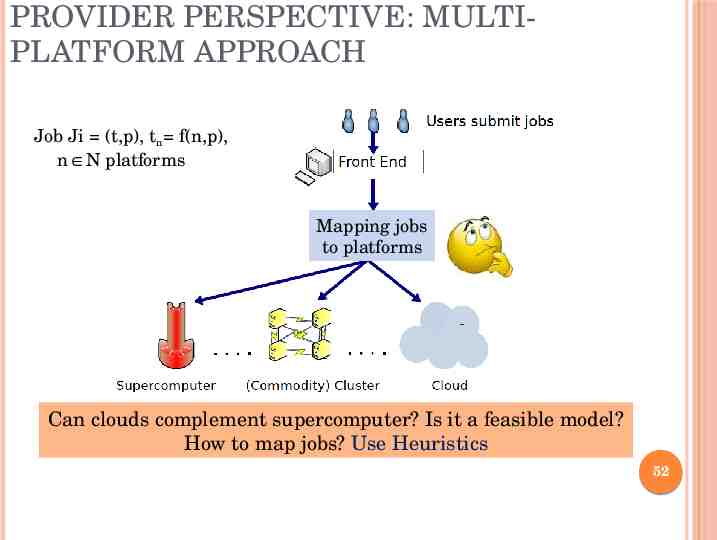
Next HPC in HPC-aware cloud Opportunities Challenges/Bottlenecks Heterogeneity Multitenancy VM consolidation Application-aware Cloud schedulers SCHEDULING/PLACEMENT 28
VM CONSOLIDATION FOR HPC IN CLOUD (1) HPC performance vs. Resource utilization (prefers dedicated execution) (shared usage in cloud)? Up to 23% savings Can we improve utilization with acceptable performance penalty? How much interference? 29
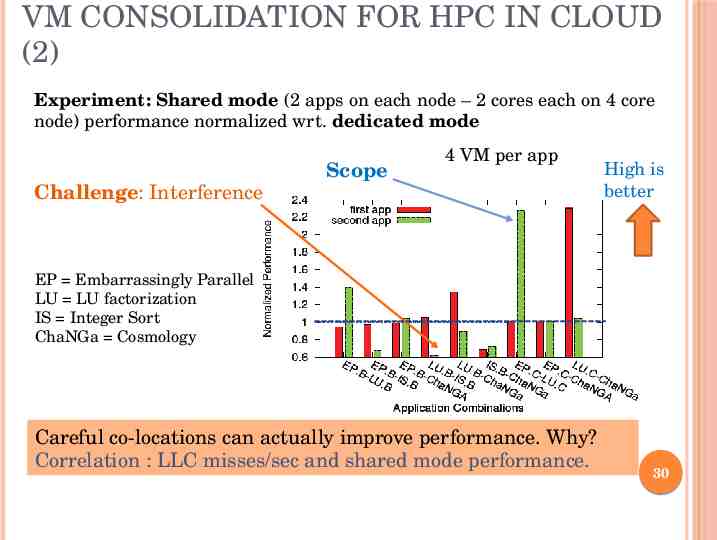
VM CONSOLIDATION FOR HPC IN CLOUD (2) Experiment: Shared mode (2 apps on each node – 2 cores each on 4 core node) performance normalized wrt. dedicated mode Scope 4 VM per app Challenge: Interference High is better EP Embarrassingly Parallel LU LU factorization IS Integer Sort ChaNGa Cosmology Careful co-locations can actually improve performance. Why? Correlation : LLC misses/sec and shared mode performance. 30
HPC-AWARE CLOUD SCHEDULERS 1. Characterize applications along two dimensions Cache intensiveness and network sensitivity 2. Co-locate applications with complementary profiles Dedicated execution, topology- and hardware-awareness for extremely tightly-coupled HPC applications 20% improvement Multi-dimensional Online Bin Packing: Memory, CPU Dimension aware heuristic Cross application interference aware 45% performance improvement, interference 8%, (OpenStack) But, what about resource utilization? Improve throughput by 32.3% (simulation using CloudSim) A. Gupta, L. Kale, D. Milojicic, P. Faraboschi, and S. Balle, “HPC-Aware VM Placement in Infrastructure Clouds ,” at IEEE Intl. Conf. on Cloud Engineering IC2E ’13 31
Next Cloud-Aware HPC in Cloud Challenges/Bottlenecks Heterogeneity Multitenancy Cloud-aware HPC Load Balancer Opportunities Elasticity Malleable Jobs (Runtime Shrink/Expand) 32
HETEROGENEITY AND MULTITENANCY Multi-tenancy Dynamic heterogeneity Interference random and unpredictable Challenge: Running in VMs makes it difficult to determine if (and how much of) the load imbalance is Application-intrinsic or Caused by extraneous factors such as interference Idle times CPU/VM Time VMs sharing CPU: application functions appear to be taking longer time Existing HPC load balancers ignore effect of extraneous factors 33
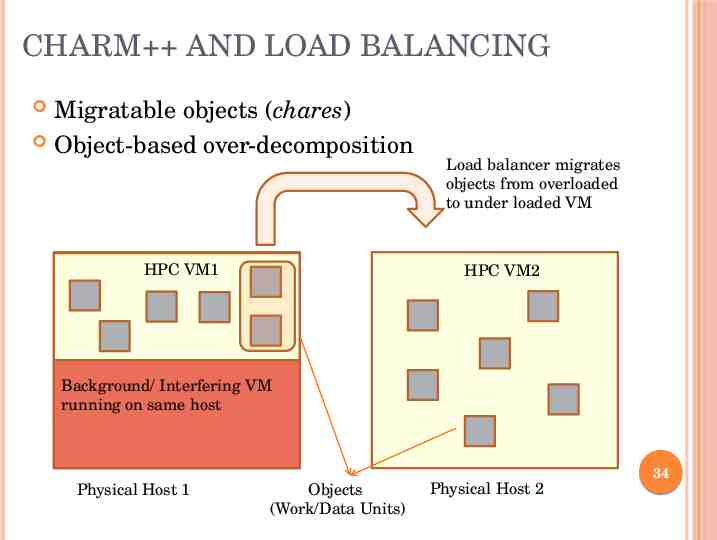
CHARM AND LOAD BALANCING Migratable objects (chares) Object-based over-decomposition HPC VM1 Load balancer migrates objects from overloaded to under loaded VM HPC VM2 Background/ Interfering VM running on same host 34 Physical Host 1 Objects (Work/Data Units) Physical Host 2
CLOUD-AWARE LOAD BALANCER CPU frequency estimation Periodic instrumentation of task times and interference Periodic task redistribution 35
To get a processor-independent LOAD BALANCING APPROACH measure of task loads, normalize the execution times to number of ticks All processors should have load close to average load Average load depends on task execution time and overhead Overhead is the time processor is not executing tasks and not in idle mode. Tlb: wall clock time between two load balancing steps, Ti: CPU time consumed by task i on VCPU p Charm LB database from /proc/stat file 36
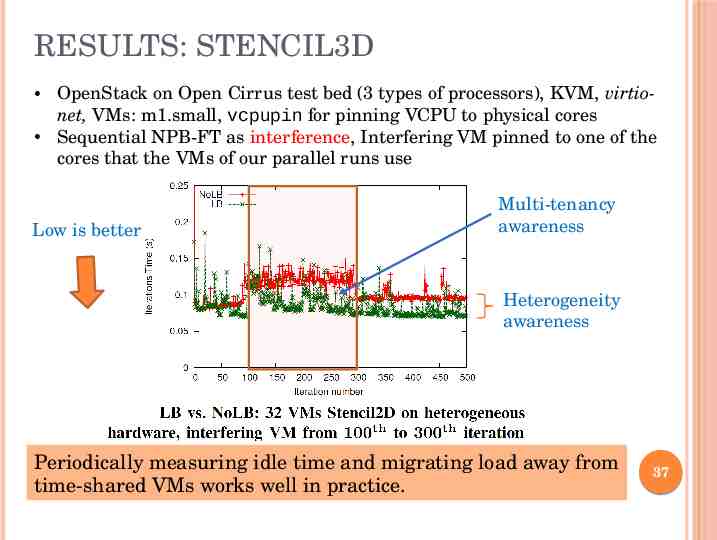
RESULTS: STENCIL3D OpenStack on Open Cirrus test bed (3 types of processors), KVM, virtionet, VMs: m1.small, vcpupin for pinning VCPU to physical cores Sequential NPB-FT as interference, Interfering VM pinned to one of the cores that the VMs of our parallel runs use Low is better Multi-tenancy awareness Heterogeneity awareness Periodically measuring idle time and migrating load away from time-shared VMs works well in practice. 37
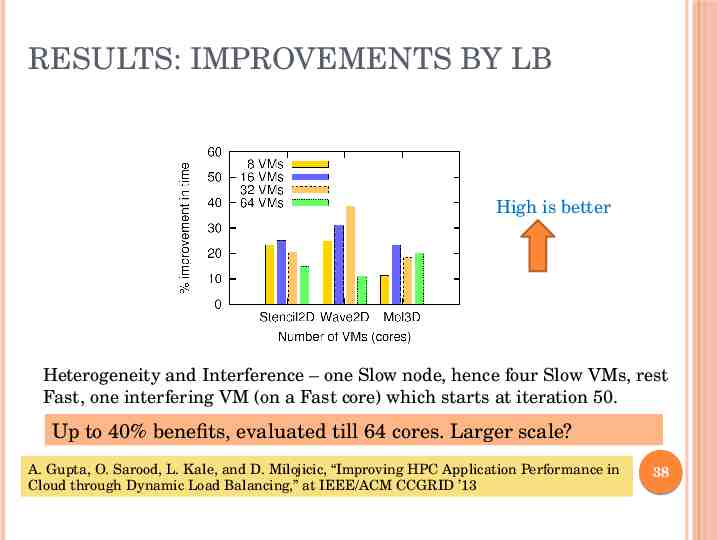
RESULTS: IMPROVEMENTS BY LB High is better Heterogeneity and Interference – one Slow node, hence four Slow VMs, rest Fast, one interfering VM (on a Fast core) which starts at iteration 50. Up to 40% benefits, evaluated till 64 cores. Larger scale? A. Gupta, O. Sarood, L. Kale, and D. Milojicic, “Improving HPC Application Performance in Cloud through Dynamic Load Balancing,” at IEEE/ACM CCGRID ’13 38
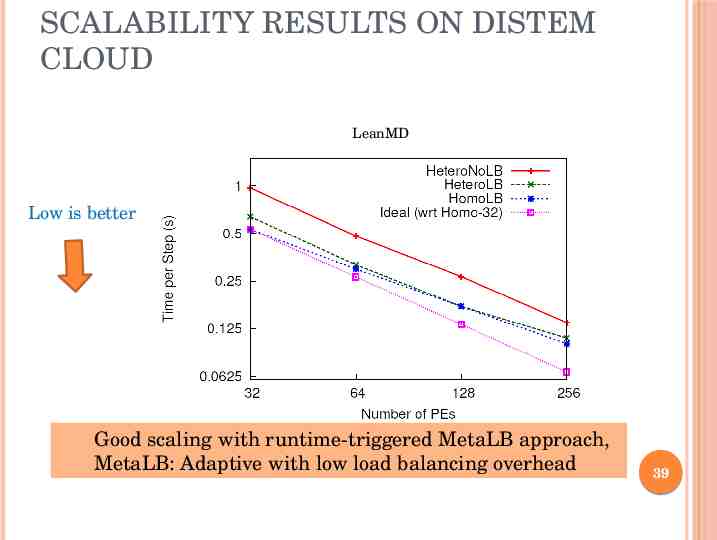
SCALABILITY RESULTS ON DISTEM CLOUD LeanMD Low is better Good scaling with runtime-triggered MetaLB approach, MetaLB: Adaptive with low load balancing overhead 39
OUTLINE Performance analysis HPC cloud divide Bridging the gap between HPC and cloud HPC-aware clouds Application-aware cloud scheduler and VM consolidation Cloud-aware HPC Dynamic load balancing: improve HPC performance Parallel runtime for malleable jobs: improve utilization Models, cost analysis and multiple platforms in cloud Lessons, conclusions, impact, and future work 40
MALLEABLE PARALLEL JOBS Dynamic shrink/expand number of processors Twofold merit in the context of cloud computing. Cloud provider perspective Better system utilization, response time, and throughput Honor job priorities Cloud user perspective: Dynamic pricing offered by cloud providers, such as Amazon EC2 Better value for the money spent based on priorities and deadlines Applicable beyond clouds Malleable jobs have tremendous but unrealized potential, What do we need to enable malleable HPC jobs? 41
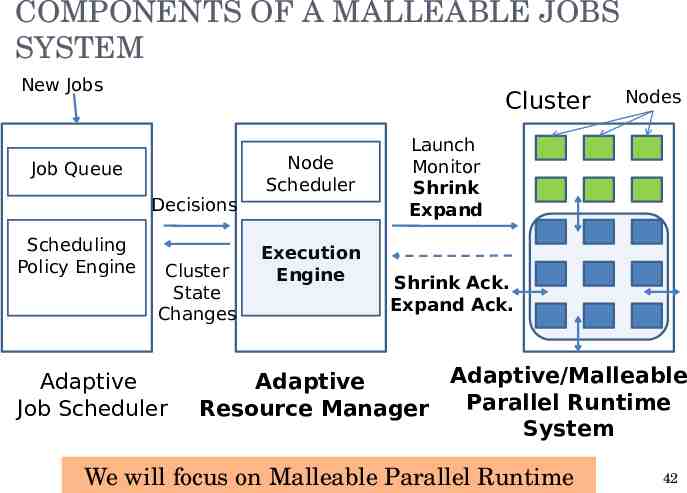
COMPONENTS OF A MALLEABLE JOBS SYSTEM New Jobs Cluster Job Queue Decisions Scheduling Policy Engine Cluster State Changes Adaptive Job Scheduler Node Scheduler Execution Engine Nodes Launch Monitor Shrink Expand Shrink Ack. Expand Ack. Adaptive/Malleable Adaptive Parallel Runtime Resource Manager System We will focus on Malleable Parallel Runtime 42
MALLEABLE RTS SUMMARY Object migration, checkpoint-restart, Linux shared memory, load balancing, implemented atop Charm Adapts load distribution well on rescale (Efficient) 2k- 1k in 13s, 1k- 2k in 40s (Fast) Scales well with core count and problem size (Scalable) Little application programmer effort (Low-effort) 4 mini-applications: Stencil2D, LeanMD, Wave2D, Lulesh 15-37 SLOC, For Lulesh, 0.4% of original SLOC Can be used in most systems (Practical) What are the benefits for HPC in cloud? A. Gupta, B. Acun, O. Sarood, and L. Kale “Towards Realizing the Potential of Malleable Parallel Jobs,” IEEE HiPC ’14 43
APPLICABILITY TO HPC IN CLOUD Provider perspective Improve utilization: malleable jobs adaptive job scheduling Stampede interactive mode as cluster for demonstration User Perspective Price-sensitive rescale in spot markets 44
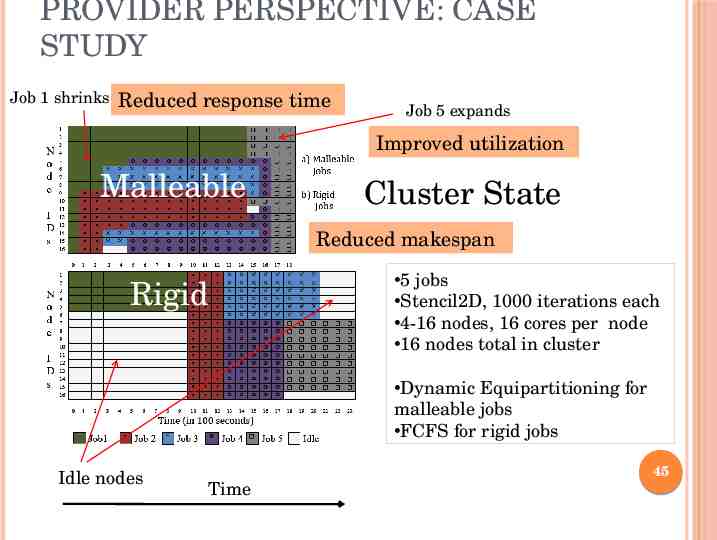
PROVIDER PERSPECTIVE: CASE STUDY Job 1 shrinks Reduced response time Job 5 expands Improved utilization Malleable Cluster State Reduced makespan Rigid 5 jobs Stencil2D, 1000 iterations each 4-16 nodes, 16 cores per node 16 nodes total in cluster Dynamic Equipartitioning for malleable jobs FCFS for rigid jobs Idle nodes 45 Time
USER PERSPECTIVE: PRICE-SENSITIVE RESCALE IN SPOT MARKETS Spot markets Bidding based Dynamic price Amazon EC2 spot price variation: cc2.8xlarge instance Jan 7, 2013 Set high bid to avoid termination (e.g. 1.25) Pay whatever the spot price or no progress Can I control the price I pay, and still make progress? Our solution: keep two pools Static: certain minimum number of reserved instances Dynamic: price-sensitive rescale over the spot instance pool Expand when the spot price falls below a threshold Shrink when it exceeds the threshold. 46
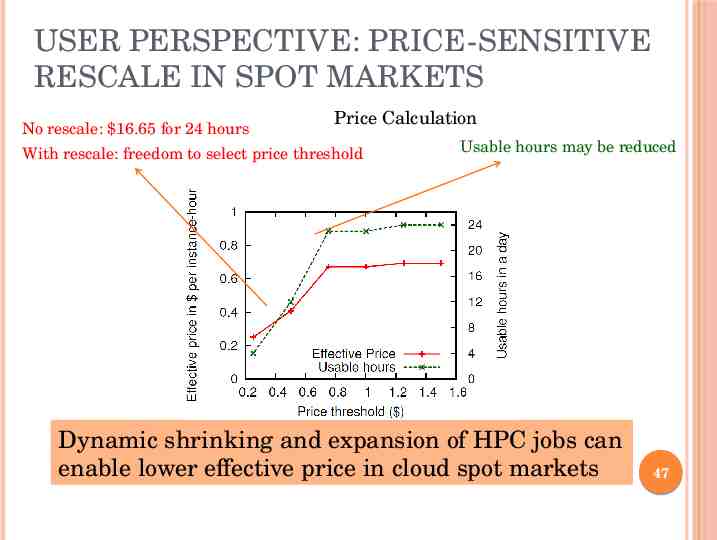
USER PERSPECTIVE: PRICE-SENSITIVE RESCALE IN SPOT MARKETS No rescale: 16.65 for 24 hours Price Calculation With rescale: freedom to select price threshold Usable hours may be reduced Dynamic shrinking and expansion of HPC jobs can enable lower effective price in cloud spot markets 47
OUTLINE Performance analysis HPC cloud divide Bridging the gap between HPC and cloud HPC-aware clouds Application-aware cloud scheduler and VM consolidation Cloud-aware HPC Dynamic load balancing: improve HPC performance Parallel runtime for malleable jobs: improve utilization Models, cost analysis and multiple platforms in cloud Lessons, conclusions, impact, and future work 48
MODELS FOR HPC IN CLOUD Cloud as substitute for supercomputers for all HPC applications? (Past work) Supercomputers defeat cloud in raw performance Some HPC applications just do not scale in cloud Cloud complement supercomputers? (Our position) User perspective Lower cost of running in cloud vs. supercomputer? For some applications? Provider perspective Hybrid cloud supercomputer approach Use underutilized resource “good enough” for a job Reduce wait time and improve throughput 49
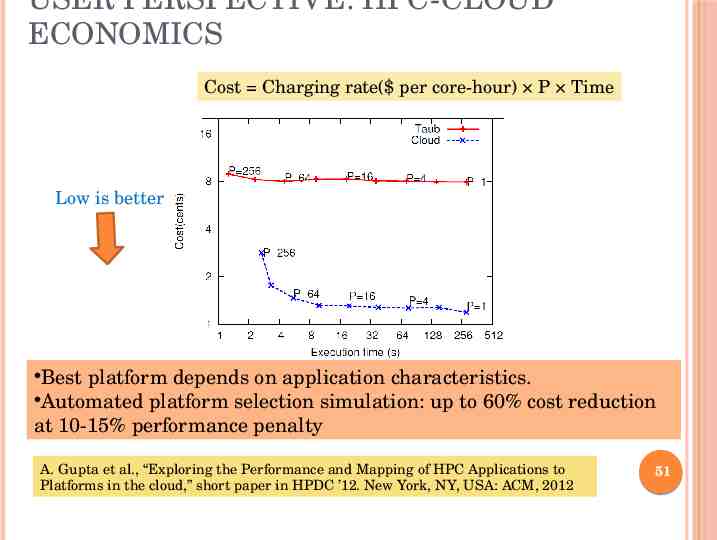
USER PERSPECTIVE: HPC-CLOUD ECONOMICS Cost instance price ( per core-hour) P Time NAMD Scaling Right to left Time constraint Choose this Low is better Cost constraint Low is better Choose this Interesting cross-over points when considering cost. Best platform depends on scale, budget. 50
USER PERSPECTIVE: HPC-CLOUD ECONOMICS Cost Charging rate( per core-hour) P Time Low is better Best platform depends on application characteristics. Automated platform selection simulation: up to 60% cost reduction at 10-15% performance penalty 51 A. Gupta et al., “Exploring the Performance and Mapping of HPC Applications to Platforms in the cloud,” short paper in HPDC ’12. New York, NY, USA: ACM, 2012 51
PROVIDER PERSPECTIVE: MULTIPLATFORM APPROACH Job Ji (t,p), tn f(n,p), n N platforms Mapping jobs to platforms Can clouds complement supercomputer? Is it a feasible model? How to map jobs? Use Heuristics 52
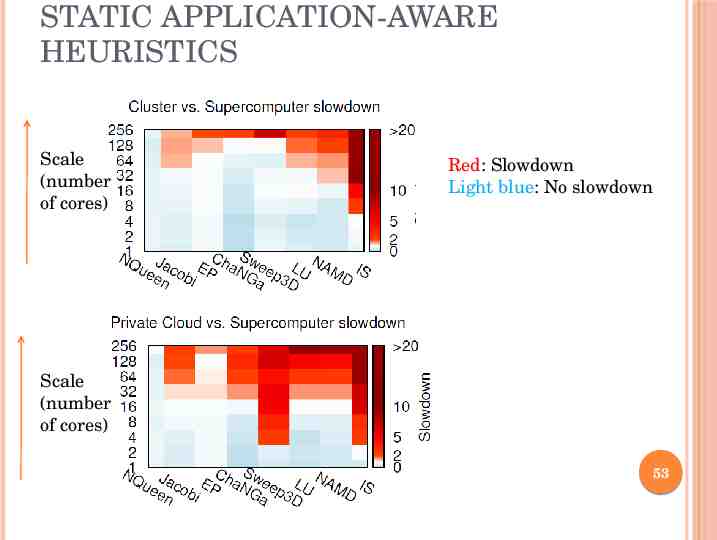
STATIC APPLICATION-AWARE HEURISTICS Scale (number of cores) Red: Slowdown Light blue: No slowdown Scale (number of cores) 53
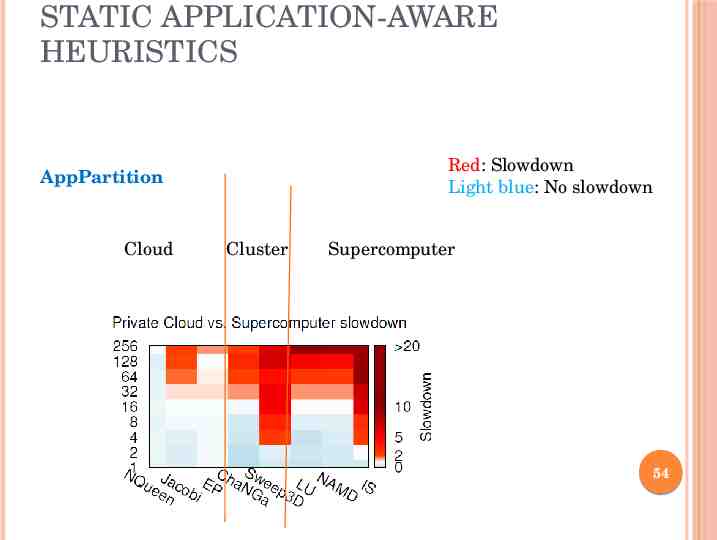
STATIC APPLICATION-AWARE HEURISTICS Red: Slowdown Light blue: No slowdown AppPartition Cloud Cluster Supercomputer 54
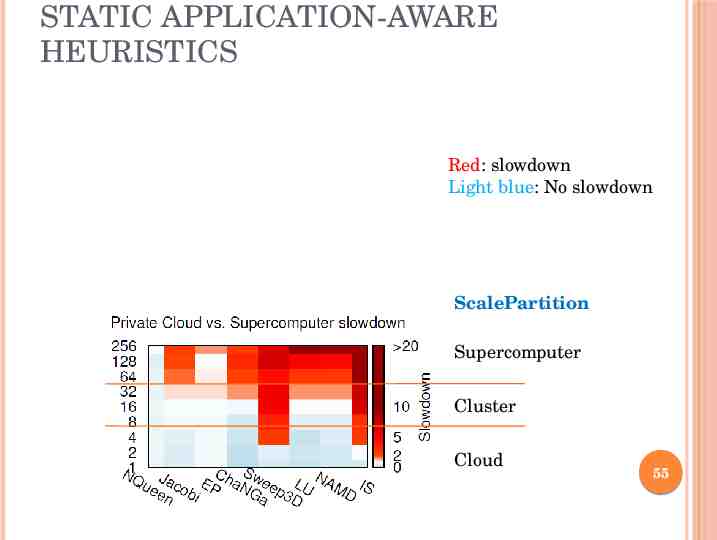
STATIC APPLICATION-AWARE HEURISTICS Red: slowdown Light blue: No slowdown ScalePartition Supercomputer Cluster Cloud 55
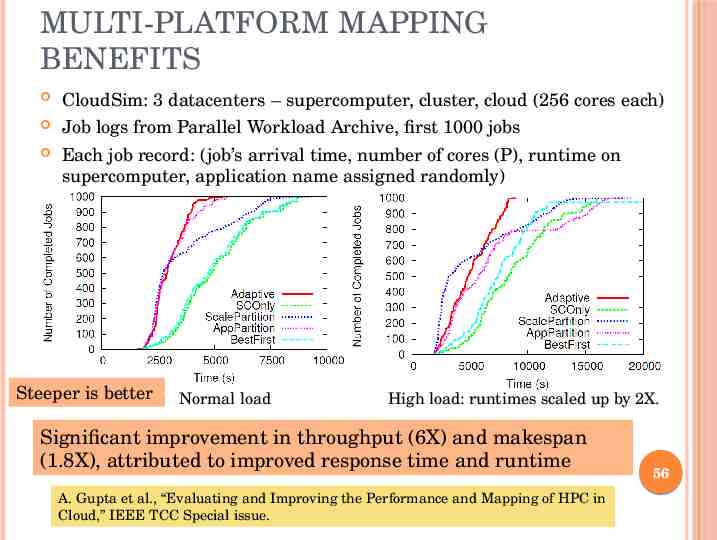
MULTI-PLATFORM MAPPING BENEFITS CloudSim: 3 datacenters – supercomputer, cluster, cloud (256 cores each) Job logs from Parallel Workload Archive, first 1000 jobs Each job record: (job’s arrival time, number of cores (P), runtime on supercomputer, application name assigned randomly) Steeper is better Normal load High load: runtimes scaled up by 2X. Significant improvement in throughput (6X) and makespan (1.8X), attributed to improved response time and runtime A. Gupta et al., “Evaluating and Improving the Performance and Mapping of HPC in Cloud,” IEEE TCC Special issue. 56
KEY TAKEAWAYS Evaluation and Mapping Lightweight virtualization necessary to remove overheads Characterization for complex applications non-trivial but economic benefits are substantial (e.g. multi-platforms) HPC-aware clouds Although counterintuitive, HPC users and cloud providers can achieve win-win by consolidating VMs using smart co-locations Cloud schedulers need knowledge of application characteristics Cache, communication, HPC vs. non-HPC Cloud-aware HPC Heterogeneity and multi-tenancy challenge for HPC Dynamic environment in clouds necessitate adaptive HPC RTS 57
CONCLUSIONS (1) Computationally intensive applications Public Clouds HPC in current clouds is suitable for some but not all applications – needs characterization and mapping 58
CONCLUSIONS (2) Public Clouds Feasible to bridge the gap between HPC and cloud – HPC-aware clouds and cloud-aware HPC 59
CONCLUSIONS HPC in current clouds is suitable for some but not all applications and can be made more efficient using intelligent mapping of applications to platforms, HPC-aware cloud scheduling, and cloud-aware HPC execution. HPC in the cloud for some applications not all Application characteristics and scale, performance-cost tradeoffs Intelligent mapping of applications to platforms Bridge the gap between HPC and cloud HPC-aware cloud scheduling Cloud-aware HPC execution Application-aware scheduling Characterization and interference-aware consolidation Heterogeneity and Multi-tenancy aware load balancing Malleable jobs Challenges and opportunities, cloud provider vs. cloud user 60
OPEN PROBLEMS AND DIRECTIONS Linux containers, Docker for packaging HPC applications Multi-platforms, mapping, and models Application characterization HPC-as-a-Service and multi-level cloud scheduling system Supercomputer using a cloud model HPC-aware clouds Interaction between application and resource manager Job interference categorization Security for HPC in cloud Cloud-aware HPC Communication optimizations in HPC runtime Adaptive communication-aware load balancing 61
RESOURCES Amazon EC2, Microsoft Azure, Grid 5000, Docker, Openstack MPI, Charm http://charm.cs.uiuc.edu/research/cloud [email protected] , LinkedIn 62
THANKS VTDC Organizers Dr. Laxmikant V. Kale, UIUC Dr. Dejan Milojicic, HP Labs. 63
REFERENCES A. Gupta et al., “Evaluating and Improving the Performance and Mapping of HPC in Cloud,” IEEE TCC Special issue A. Gupta et al., “The Who, What, Why and How of High Performance Computing Applications in the Cloud,” Best paper at IEEE CloudCom 2013 A. Gupta, O. Sarood, L. Kale, and D. Milojicic, “Improving HPC Application Performance in Cloud through Dynamic Load Balancing,” accepted at IEEE/ACM CCGRID ’13 A. Gupta, L. Kale, D. Milojicic, P. Faraboschi, and S. Balle, “HPC-Aware VM Placement in Infrastructure Clouds ,” at IEEE Intl. Conf. on Cloud Engineering IC2E ’13 A. Gupta et al., “Exploring the Performance and Mapping of HPC Applications to Platforms in the cloud,” short paper in HPDC ’12. New York, NY, USA: ACM, 2012 A. Gupta et al., “Realizing the Potential of Malleable Parallel Jobs,” HiPC 2014 A. Gupta and D. Milojicic, “Evaluation of HPC Applications on Cloud,” in Open Cirrus Summit Best Student Paper, Atlanta, GA, Oct. 2011 A. Gupta, D. Milojicic, and L. Kale, “Optimizing VM Placement for HPC in Cloud,” in Workshop on Cloud Services, Federation and the 8th Open Cirrus Summit, San Jose, CA, 2012 A. Gupta and L. V. Kale, “Towards Efficient Mapping, Scheduling, and Execution of HPC Applications on Platforms in Cloud,” short paper and poster at 27th International Parallel and Distributed Processing Symposium(IPDPS) Ph.D Forum’13 Best PhD Forum award O. Sarood, A. Gupta, and L. V. Kale, “Cloud Friendly Load Balancing for HPC Applications: Preliminary Work,” in 41st Intl. Conf. on Parallel Processing Workshops 64 (ICPPW), 2012






