ECE 477 Digital Systems Senior Design Project Module 14 Designing for





























44 Slides3.81 MB
ECE 477 Digital Systems Senior Design Project Module 14 Designing for Reliability, Maintainability, and Safety
Outline Introduction Component Failures and Wear Mean Time To/Before Failure (MTTF/MTBF) Heat Controller Example Failure Rate Calculation Improving System Availability Failure Mode & Effects Analysis (FMEA) Criticality Analysis (FMECA) Fault Tree Analysis (FTA) Software and Watchdogs Maintainability Standards and Compliance Reference: “Designing for Reliability, Maintainability, and Safety – Parts 1, 2, and 3”, Circuit Cellar, December 2000, January 2001, April 2001.
Introduction Reliability, maintainability, and safety integral to product development Tradeoffs between requirements and cost Reducing probability of failure is expensive Given little potential for personal injury, the primary consideration is manufacturing cost vs. potential customer unhappiness There are UL, IEC (to name a few) standards to be met ?
Component Failures Electronic components can most often be modeled by constant failure rate ( ) Leads to exponential failure distribution Same probability of failure in the next hour regardless of whether it is new or used
Component Failures Components do not “age” or “degrade” with use – constant failure rate unrelated to hours of use (under certain conditions) Equivalent info testing 10 units for 10,000 hours vs. testing 1000 units for 100 hours “Impossible” 10-9 failure as likely to happen in the first 5 minutes of operation as 114,000 years from now Infant mortality reduced by robust designs, manufacturing process control, and “shake and bake”
Component Wear* If, based on observation, failure rate does depend on time used, it may be due to wear caused by improper derating Well-derated electronic systems seldom reach the point of wear-out failure Well-derated working at 30-40% of specified ratings Heat is the main reliability killer – even a small reduction will have a significant effect See also “An Odometer for CPUs, IEEE Spectrum,” May 2011
Reliability Models for Components Calculated value is p, the predicted number of failures per 106 hours of operation Microelectronic Circuits Examples: Diodes
How long is 106 hours? 41667 days, 114 years Given a failure rate of 1 x 10-6 units/hr Should you be happy if a typical single unit only fails once in 114 years on average? A Yes, B No How long (in hours) between unit failures if you have 1 million in use? A 6m B 1hr C 10hr D 1000hr E 10 6 hr What if the failure causes serious injury? Is this rate acceptable? A Yes, B No Why or why not?
Microelectronic Circuits (see 5.1 p.23ff of Mil-Hdbk 217F) (based on # of gates or transistors or on type of micro, e.g., 8bit, 16bit, etc)
Expectations for Homework Choose hottest and/or most complex components – Which are your hottest/most complex components? Choose most closely related MILHDBK-217F model Give assumptions and reasons for parameter values used Present information as table or list
MTTF/MTBF For irreparable parts, use mean time to failure (MTTF) 1/ for components with an exponential life distribution For assemblies with repairable parts, mean time between failure (MTBF) is appropriate Field returns are always a more powerful statement of performance than statistical predictions Reliability models are conservative – equipment generally outperforms the statistics designed equipment) (well
Heat Controller Example Gas-fired burner to maintain hot-tub water temperature within a specified tolerance Possibility of personal injury if controller malfunctions Performing hazard analysis and modifying the design based on results obtained – important for showing “reasonable care” in court (reduction of liability)
Heat Controller Example Simple hazard analysis 10-9 generally accepted as “never” (50% chance of failure after 79,000 years of continuous operation) BTW: with 1M units in field, never occurs once every 6 weeks
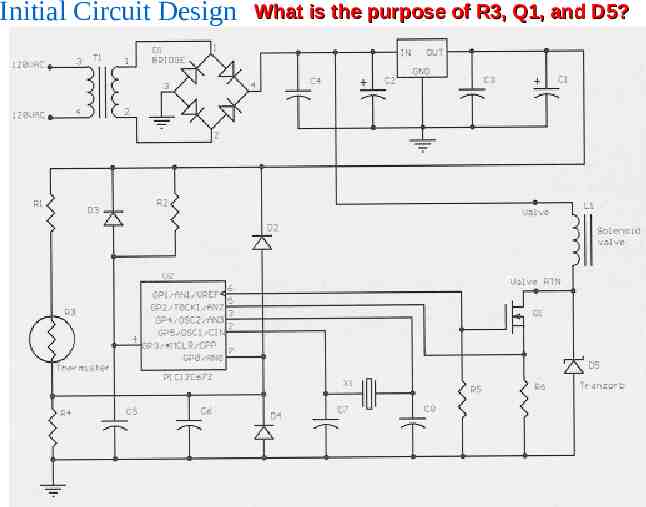
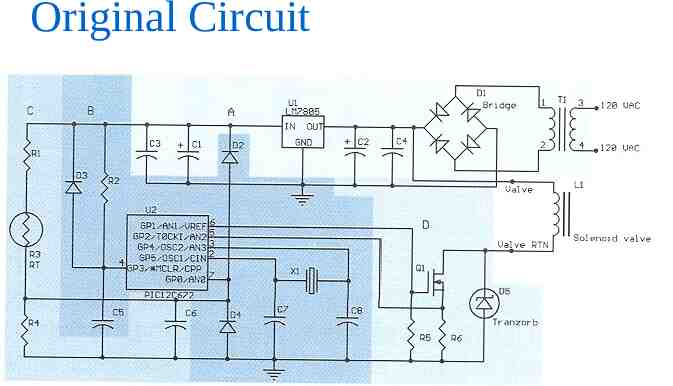
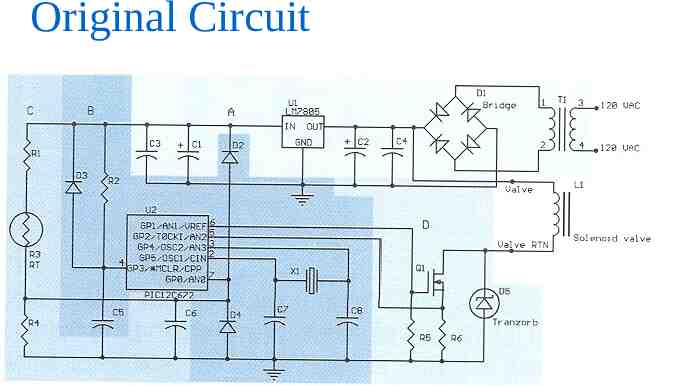
Initial Circuit Design What is the purpose of R3, Q1, and D5?
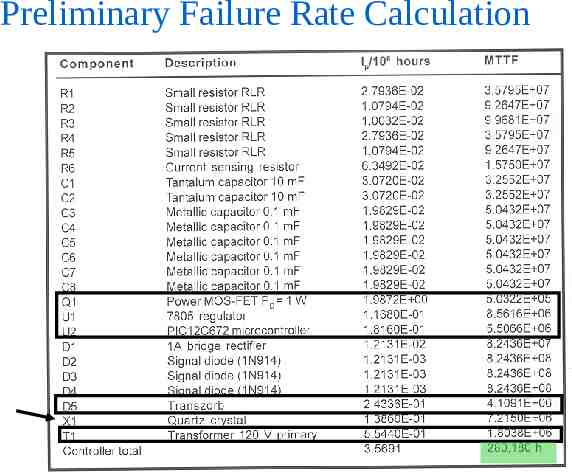
Preliminary Failure Rate Calculation
Improving System Availability Components with greater failure rates than the rest (Q1, U1, U2, D5, T1, X1) Q1, U1, U2 work at conservatively estimated junction temperature of 100 C – efficient heat sinking can reduce junction temperature to 50ºC ( T Pdiss x Rth) T Tambient T Transzorb D5 & diodes D2, D3 conduct during infrequent transients only – reduce their contribution by applying a duty cycle Design T1 to run at a lower temperature to improve its reliability
Improving System Availability Implementing these steps – Increase MTBF from 280,000 hours to 714,000 hr. p 1.4 [failures/106 hours] For the remaining analysis (Part 2), the results of these calculations will be used to evaluate and improve product safety
Introduction Designing a functional product represents about 30% of the design effort Making sure a product always fails in a safe, predictable manner takes the remaining 70% Law of diminishing returns: exercise good judgment in adding safety features Keep in balance: safety features and possibility of “nuisance alarms” (failures resulting from added complexity) Utilize built-in self-test (BIST)
FMEA Bottom-up review of a system Examine components for failure modes Note how failures propagate through system Study effects on system behavior Leads to design review and possibly changes to eliminate weaknesses
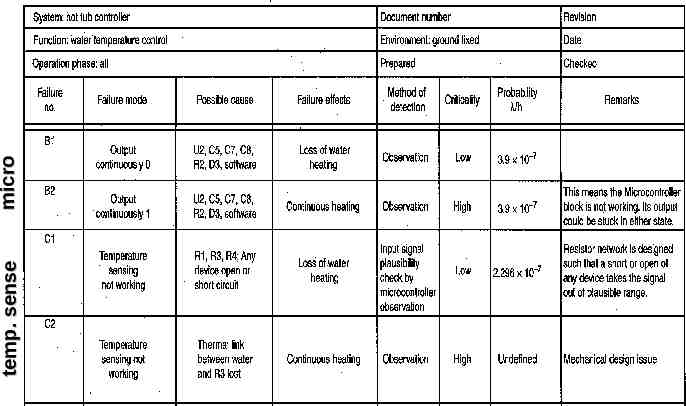
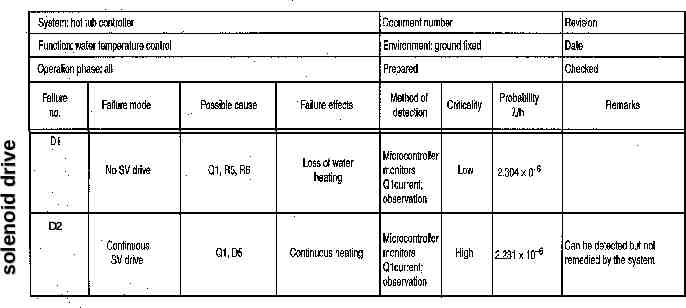
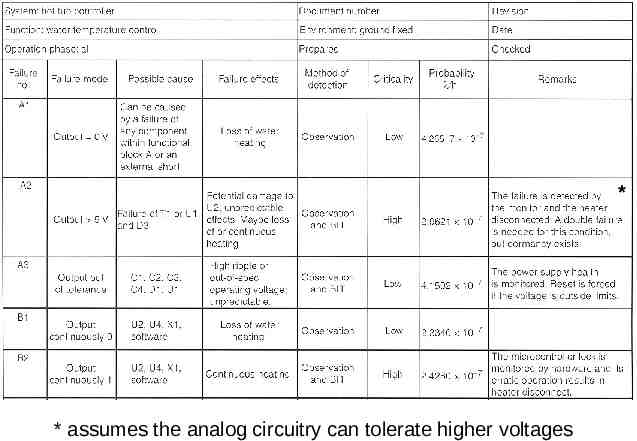
FMECA Addition of criticality analysis Not necessary to examine every component – Multiple components may have same failure effect Rearrange design into functional blocks – consider component failures within those blocks that may be critical Create chart listing possible failures – block, failure mode, possible cause, failure effects, method of detection, criticality, and probability* * probability not required for homework
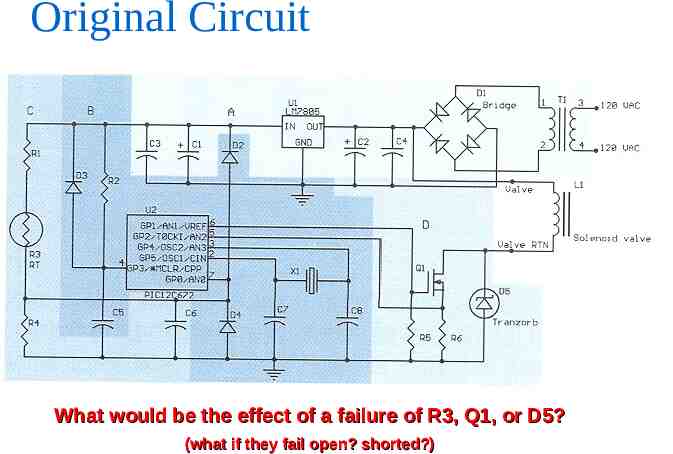
Original Circuit What would be the effect of a failure of R3, Q1, or D5? (what if they fail open? shorted?)
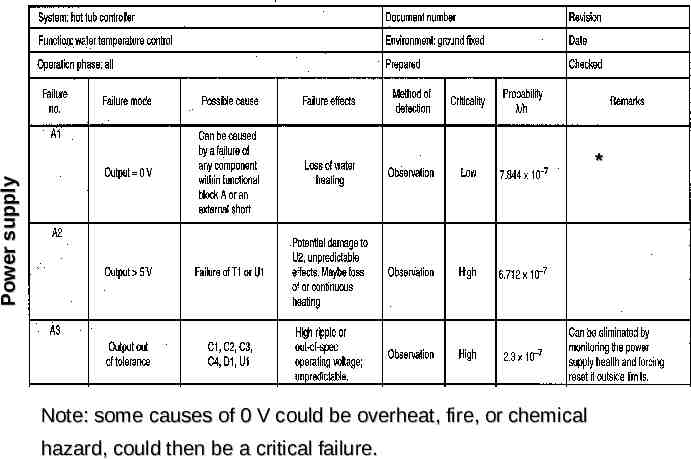
Power supply * Note: some causes of 0 V could be overheat, fire, or chemical hazard, could then be a critical failure.
Failure Cause/Mode/Effect/Criticality (use Circuit Cellar article for examples, but these are my definitions) Cause – failure of a device – open circuit, short circuit, or change in device behavior. – for complex devices, could be failure of a particular feature – List all components that could produce this failure mode Mode – related to method of diagnosis – observable or measurable behavior of component or subcircuit resulting from a device failure. – Something you might observe when probing internals of the system with a multimeter, scope, or logic analyzer. Effect – external behavior of entire system – For hot tub, it either overheats or underheats the water – For most systems – possibility of fire or damage to other components external or internal Criticality – how serious are the consequences – High: involves injury, requires rate 10-9 – Medium (optional): renders system unrepairable – Low: inconvenience to user, required rate typically 10-6
Original Circuit
temp. sense micro
Original Circuit
solenoid drive D2
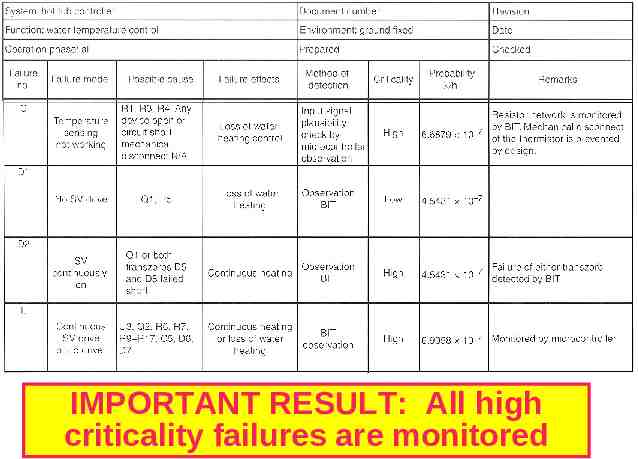
High Criticality Failures A2 – power supply over-voltage A3 – power supply out of tolerance (high or low) B2 – micro failure or software malfunction C2 – temperature sensor D2 – solenoid drive
In class team exercise: For your project: Identify one high criticality failure mode: Identify a cause – one or more part failures that could cause this failure mode Describe the failure mode, i.e., a descriptive name for the ill behavior of the circuit itself in event of this failure Describe the effect – an externally observable effect on system behavior, noticeable to the end user AND/OR damage to other parts of the system not involved in the original failure mode If you don’t have a high criticality failure mode other than power supply overheat, identify a low or medium criticality failure do the same analysis as above Put all this information on the provided exercise sheet
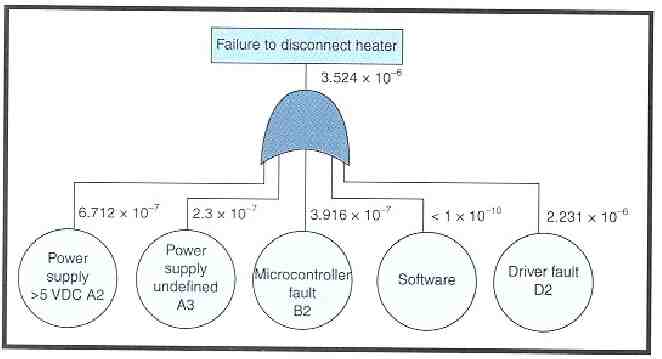
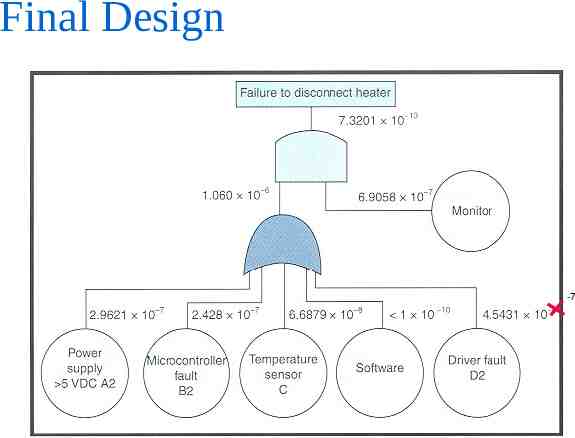
Fault Tree Analysis (FTA) Purpose: estimate probability of a particular failure mode or set of failure modes Top-down graphical analysis Starts with top event of interest Builds fault tree using Boolean logic and symbols Incorporating known failure probabilities (same as used in FMECA) yields probability of event of interest – OR probabilities added (accurate only for small probabilities) – AND probabilities multiplied
Probability of Failure PF 1 - e - t note: for small t, PF λ For PF 0.5 (50% chance of uncontrolled heating), it takes 22 years of operation given 3.5424 X 10-6 NOT GOOD ENOUGH FOR A SYSTEM THAT CAN POTENTIALLY CAUSE INJURY – NEED 10-9 (78,767 years for PF 50%)
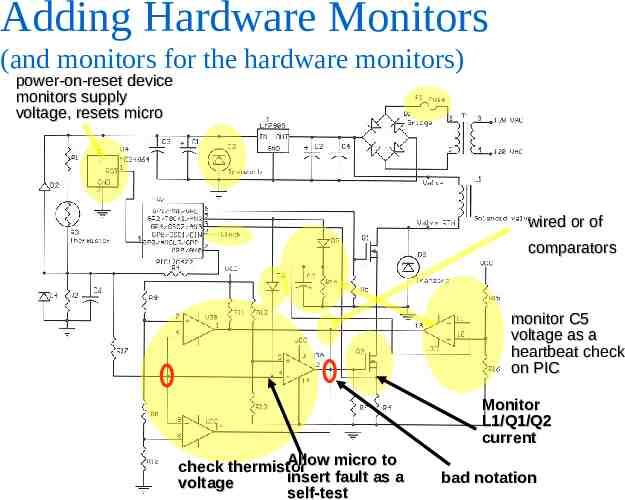
Adding Hardware Monitors (and monitors for the hardware monitors) power-on-reset device monitors supply voltage, resets micro wired or of comparators monitor C5 voltage as a heartbeat check on PIC Monitor L1/Q1/Q2 current Allow micro to check thermistor insert fault as a voltage self-test bad notation
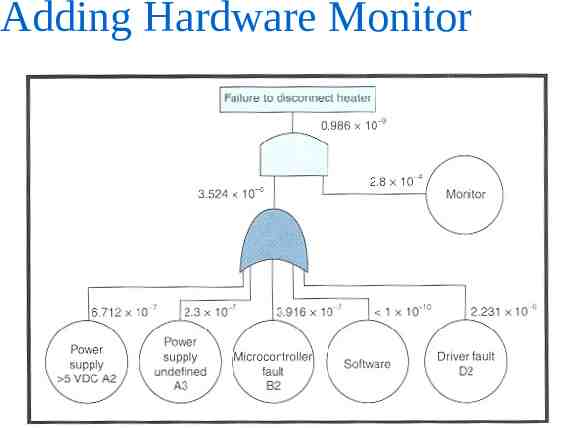
Adding Hardware Monitor
Added Redundancy Microcontroller – performs sanity check on thermistor output – short/open would cause voltage to move out of plausible range – abrupt change in temperature would indicate fault Comparators (monitor circuit) – turn off Q2 if temperature exceeds upper limit – provide window for plausibility testing of temperature sensor Difficult part: eliminating dormant failures (all faults must be detected)
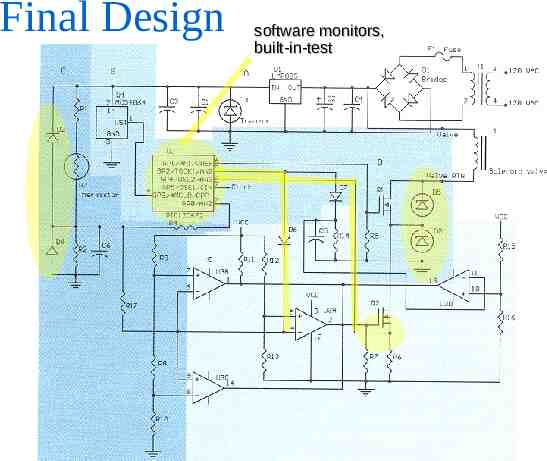
Final Design software monitors, built-in-test
* * assumes the analog circuitry can tolerate higher voltages
IMPORTANT RESULT: All high criticality failures are monitored
Final Design -7
Software and Watchdogs Role of watchdog timer is to reset processor if “strobe timeout” occurs Problem: watchdogs integral to microcontroller are no more reliable than microcontroller itself External watchdogs “better”, but have to make sure that it is prevented from being strobed in the event of failures/bugs Possible solution: make watchdog respond to a “key” (that would be difficult for failed software/bug to generate)
Maintainability Reliability predication indicates that after 10,000 units shipped, will need to service two problems per day Keep customers happy with quick repair turnaround time (TAT) Repair will most likely be by replacement (“line replaceable units” – LRU) Maintainability analysis generates data showing the time needed to identify the faulty LRU, the time to replace it, and the time to re-test the system Mean-time-to-repair (MTTR)
Standards & Compliance Many categories in consumer electronics: Arcade, Amusement and Gaming Machines -- Bowling and Billiard Equipment -- Cable and Satellite Communication Equipment -- Circuit Components for Use in Audio/Video Equipment -- Commercial Audio and Radio Equipment, Systems and Accessories -- Low Voltage Portable Electronics; Household Audio and Video Equipment -- Musical Instruments -- Professional, Commercial and Household Use Equipment. Example of a category relevant to ECE477 IEC 62368-1Audio/Video, Information and Communication Technology Equipment – Safety Requirements. Published Jan. 2010, UL & CSA versions, Feb. 2011
From electronicdesign.com The ABCs of IEC 62368-1, An Emerging Safety Standard Date Posted: October 22, 2010 1 Hazard Based Safety Engineering Energy sources: electrical, thermal, kinetic, and radiated To prevent pain or injury, either the energy source can be designed to levels incapable of causing pain or injury, or safeguards such as insulation can be designed into the product to prevent the energy transfer to the body part.
What was the muddiest point in this lecture? A. B. C. D. E. F. G. Definition of failure rate Reliability calculation MTTF/MTBF definition Failure Modes/Effects Analysis Failure mitigation Expectations for homework Other?






