DNA COMPUTING Deepthi Bollu CSE 497:Computational issues in














































54 Slides1.08 MB
DNA COMPUTING Deepthi Bollu CSE 497:Computational issues in Molecular Biology Professor- Dr. Lopresti April 13, 2004
Outline of Lecture Introduction. Biochemistry basics. Adleman’s Hamiltonian path problem. Danger of errors. Limitations. Deepthi Bollu 2
Introduction Ever wondered where we would find the new material needed to build the next generation of microprocessors? HUMAN BODY (including yours!) .DNA computing. “Computation using DNA” but not “computation on DNA” Initiated in 1994 by an article written by Dr. Adleman on solving HDPP using DNA. Deepthi Bollu 3
Uniqueness of DNA Why is DNA a Unique Computational Element? Extremely dense information storage. Enormous parallelism. Extraordinary energy efficiency. Deepthi Bollu 4
Dense Information Storage This image shows 1 gram of DNA on a CD. The CD can hold 800 MB of data. The 1 gram of DNA can hold about 1x1014 MB of data. The number of CDs required to hold this amount of information, lined up edge to edge, would circle the Earth 375 times, and would take 163,000 centuries to Deepthi Bollu listen to. 5
How Dense is the Information Storage? with bases spaced at 0.35 nm along DNA, data density is over a million Gbits/inch compared to 7 Gbits/inch in typical high performance HDD. Check this out . Deepthi Bollu 6
How enormous is the parallelism? A test tube of DNA can contain trillions of strands. Each operation on a test tube of DNA is carried out on all strands in the tube in parallel ! Check this out . We Typically use Deepthi Bollu 7
How extraordinary is the energy efficiency? Adleman figured his computer was running 2 x 1019 operations per joule. Deepthi Bollu 8
A Little More Basic suite of operations: AND,OR,NOT & NOR in CPU while cutting, linking, pasting, amplifying and many others in DNA. Complementarity makes DNA unique. Ex: in Error correction. Deepthi Bollu 9
Biochemistry Basics
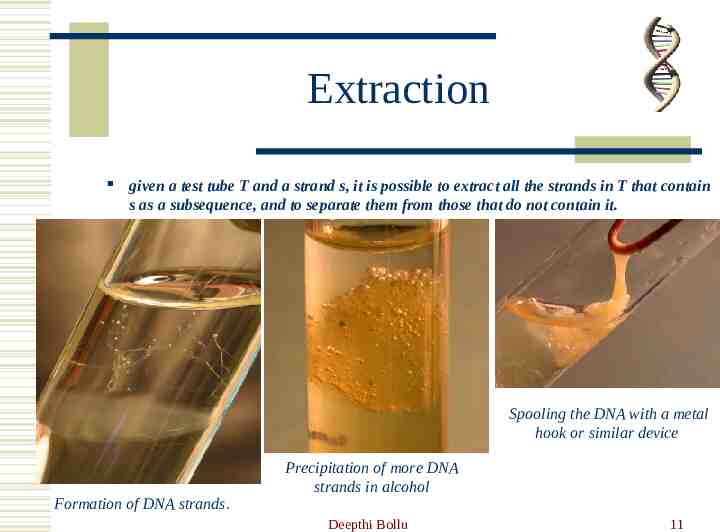
Extraction given a test tube T and a strand s, it is possible to extract all the strands in T that contain s as a subsequence, and to separate them from those that do not contain it. Spooling the DNA with a metal hook or similar device Formation of DNA strands. Precipitation of more DNA strands in alcohol Deepthi Bollu 11
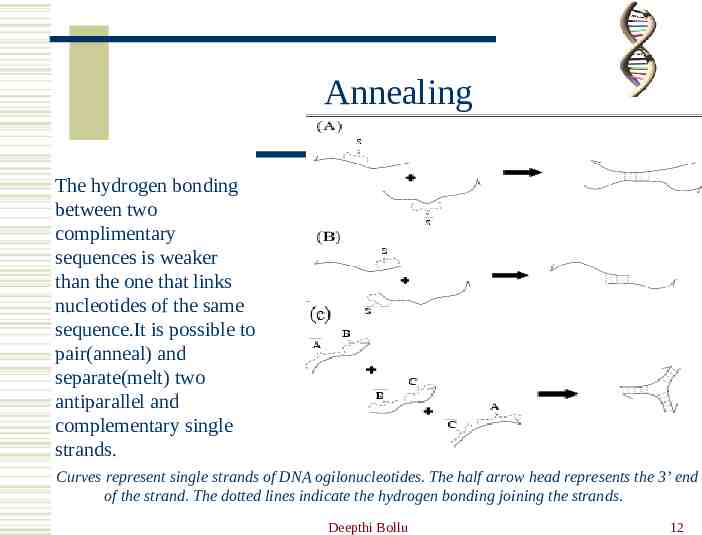
Annealing The hydrogen bonding between two complimentary sequences is weaker than the one that links nucleotides of the same sequence.It is possible to pair(anneal) and separate(melt) two antiparallel and complementary single strands. Curves represent single strands of DNA ogilonucleotides. The half arrow head represents the 3’ end of the strand. The dotted lines indicate the hydrogen bonding joining the strands. Deepthi Bollu 12
Polymerase Chain Reaction PCR: One way to amplify DNA. PCR alternates between two phases: separate DNA into single strands using heat; convert into double strands using primer and polymerase reaction. PCR rapidly amplifies a single DNA molecule into billions of molecules Deepthi Bollu 13
Gel Electrophoresis Used to measure the length of a DNA molecule. Based on the fact that DNA molecules are –ve ly charged. Gel Electrophoresis Deepthi Bollu 14
How to fish for known molecules? Annealing of complimentary strands can be used for fishing out target molecules. Denature the double stranded molecules. The probe for s molecules would be s. We attach probe to a filter and pour the solution S through it. We get double stranded molecules fixed to filter and the solution S’ resulting from S by removing s molecules. Filter is then denatured and only target molecule remains. Adleman attached probes to magnetic beads. Deepthi Bollu 15
Adleman’s solution of the Hamiltonian Directed Path Problem(HDPP). I believe things like DNA computing will eventually lead the way to a “molecular revolution,” which ultimately will have a very dramatic effect on the world. – L. Adleman
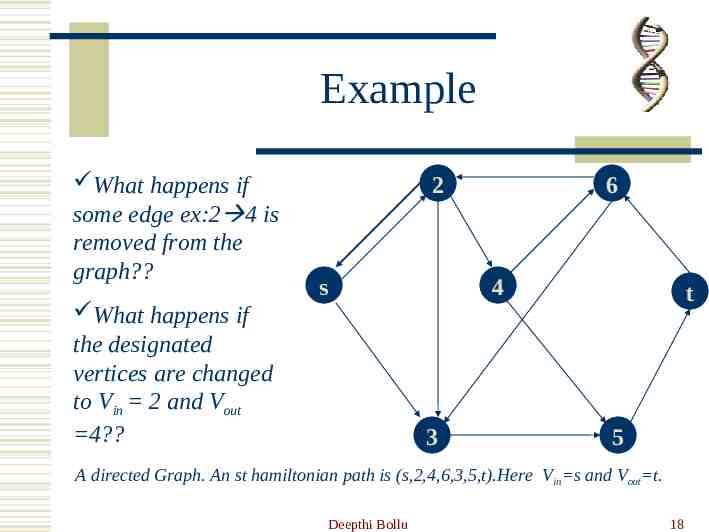
The Problem A directed Graph G (V,E) V n, E m and two distinguished vertices s and Vout t. Verify whether there is a path (s,v1,v2, .,t) Vin which is a sequence of “one-way” edges that begins in Vin and Vout whose length (in no.of edges) is n-1 and (i.e. enters all vertices.) Whose vertices are all distinct (i.e. enters every vertex exactly once.) A CLASSIC NP-COMPLETE PROBLEM!!! Deepthi Bollu 17
Example What happens if some edge ex:2 4 is removed from the graph? 2 s What happens if the designated vertices are changed to Vin 2 and Vout 4? 6 4 3 t 5 A directed Graph. An st hamiltonian path is (s,2,4,6,3,5,t).Here Vin s and Vout t. Deepthi Bollu 18
Why not brute force algorithm? Brute force algorithm is to Generate all possible paths with exactly n-1 edges Verify whether one of them obeys the problem constraints. Problem: How many paths can there be? such paths could be (n-2)! So, what did Dr. Adleman use? ‘Generate and test’ strategy where number of random paths were generated and tested. Deepthi Bollu 19
Adleman’s Experiment makes use of the DNA molecules to solve HDPP. good thing about random path generation-each path can be generated independent of all others bringing into picture-“Parallelism” . On the other hand adding “Probability” too. No. of Lab procedures grows linearly with the no. of vertices in the graph. Linear no. of lab procedures is due to the fact that an exponential no. of operations is done in parallel. At the heart, it is a brute force algorithm executing an exponential number of operations. Deepthi Bollu 20
Algorithm(non-deterministic) 1.Generate Random paths 2.From all paths created in step 1, keep only those that start at s and end at t. 3.From all remaining paths, keep only those that visit exactly n vertices. 4.From all remaining paths, keep only those that visit each vertex at least once. 5.if any path remains, return “yes”;otherwise, return “no”. Deepthi Bollu 21
Step 1.Random Path Generation. Assumptions Random single stranded DNA sequences with 20 nucleotides are available. Generation of astronomical number of copies of short DNA strands is easy to do. Vertex representation Each vertex v in the graph is associated with a random 20-mer sequence of DNA denoted by Sv. For each such sequence obtain its complement Sv. Generate many copies of each Sv sequence in test tube T1. Deepthi Bollu 22
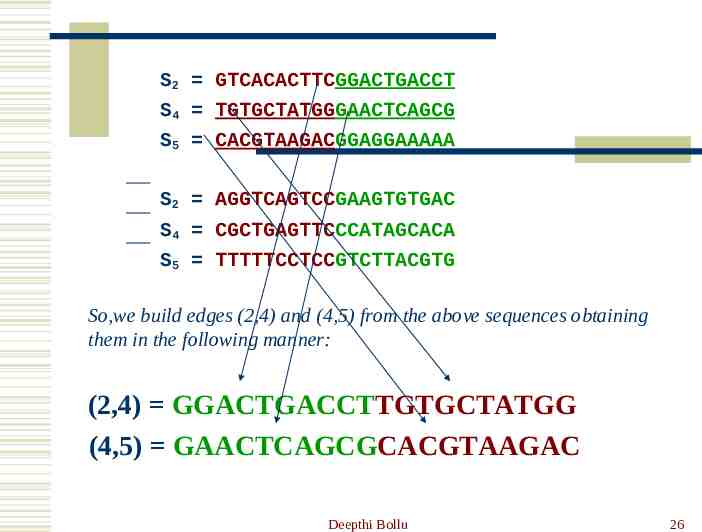
For example, the sequences chosen to represent vertices 2,4 and 5 are the following: S2 GTCACACTTCGGACTGACCT S4 TGTGCTATGGGAACTCAGCG S5 CACGTAAGACGGAGGAAAAA 5’ 20 mer 3’ The reverse complement of these sequences are: S2 AGGTCAGTCCGAAGTGTGAC S4 CGCTGAGTTCCCATAGCACA S5 TTTTTCCTCCGTCTTACGTG Deepthi Bollu 23
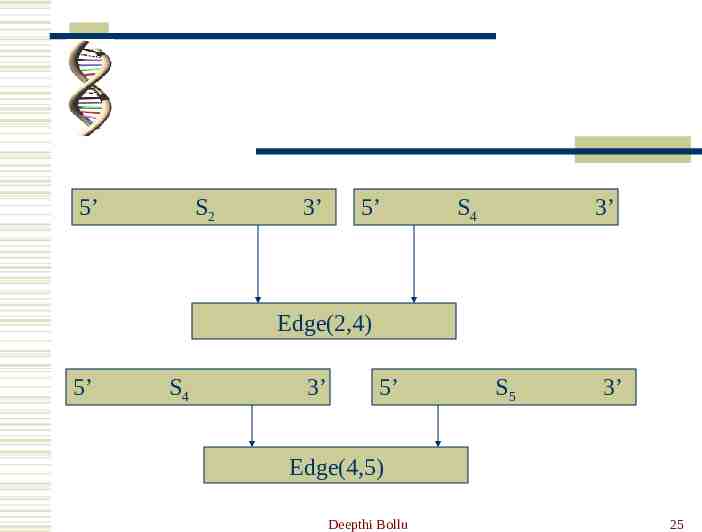
Step1. Random Path Generation. Edge representation For each edge u v in the graph, the oligonucleotide Su v is created that is 3’ 10-mer of Su followed by 5’ 10-mer of Sv If u s then it is all of Su or if v t then it is all of Sv.(i.e.each edge denoted by 20-mer while the edge that involves either s or t is a 30-mer.) With this construction, Suv Svu. (Preservation of Edge Orientation.) Generate many copies of each Suv sequence in test tube T2 Deepthi Bollu 24
5’ S2 3’ 5’ S4 3’ Edge(2,4) 5’ S4 3’ 5’ S5 3’ Edge(4,5) Deepthi Bollu 25
S2 GTCACACTTCGGACTGACCT S4 TGTGCTATGGGAACTCAGCG S5 CACGTAAGACGGAGGAAAAA S2 AGGTCAGTCCGAAGTGTGAC S4 CGCTGAGTTCCCATAGCACA S5 TTTTTCCTCCGTCTTACGTG So,we build edges (2,4) and (4,5) from the above sequences obtaining them in the following manner: (2,4) GGACTGACCTTGTGCTATGG (4,5) GAACTCAGCGCACGTAAGAC Deepthi Bollu 26
Step1.Random Path Generation Path Construction Pour T1 and T2 into T3. In T3 many ligase reactions will take place. (Ligase Reaction or ligation: There is an enzyme called Ligase, that causes concatenation of two sequences in a unique strand.) Deepthi Bollu 27
Step1.Random Path Generation By executing these 3 operations,we get many random paths for the following reasons: Consider Su,Sv,Sw,Suv,Svw for u,v,w distinct vertices. 10 base suffix of one Su sequence will bind to the 10 base prefix of one Suv sequence. (one is complement of the other.) At the same time 10-base suffix of same sequence Suv binds to the 10-base prefix of one Sv sequence Sv 10-base suffix binds to the 10-base prefix of one Svw sequence. The final double strand thus obtained encodes (u,v,w) in G. Deepthi Bollu 28
Examples of random paths formed S2 S4 S6 S2 E2 4 E4 6 E6 2 S6 S3 S5 E6 3 E3 5 s S2 s E2 s S3 Es 3 t E5 t Es 2 Deepthi Bollu 29
Formation of Paths from Edges and compliments of vertices Edge u v Su Sv Deepthi Bollu Edge v w Sw 30
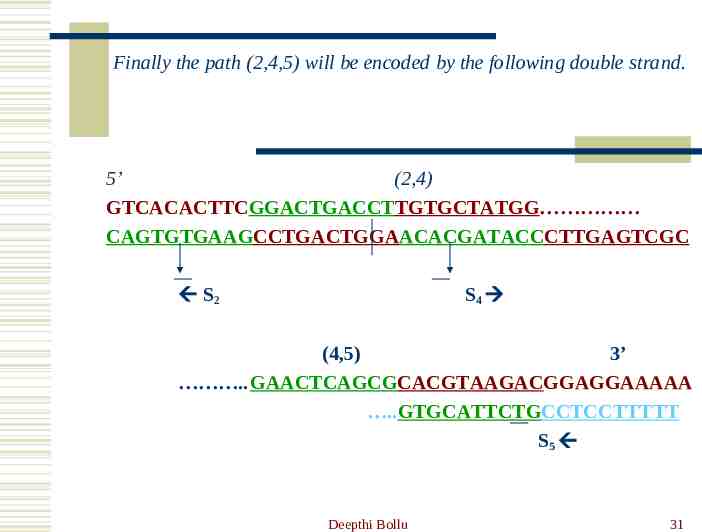
Finally the path (2,4,5) will be encoded by the following double strand. 5’ (2,4) GTCACACTTCGGACTGACCTTGTGCTATGG CAGTGTGAAGCCTGACTGGAACACGATACCCTTGAGTCGC S2 S4 (4,5) 3’ .GAACTCAGCGCACGTAAGACGGAGGAAAAA .GTGCATTCTGCCTCCTTTTT S5 Deepthi Bollu 31
Step 2 “keep only those that start at s and end at t.” Product of step 1 was amplified by PCR using primers Ss and St. By this, only those molecules encoding paths that begin with vertex s and end with vertex t were amplified. Deepthi Bollu 32
Step 3 “keep only those that visit exactly n vertices” Product of step 2 is run on agarose gel and the 140bp (since 7 vertices) band was excised and soaked in doubly distilled H 2O to extract DNA. This product is PCR amplified and gel purified several times to enhance its purity. Deepthi Bollu 33
Step 3 “keep only those that visit exactly n vertices” DNA is negatively charged. Place DNA in a gel matrix at the negative end. (Gel Electrophoresis) Longer strands will not go as far as the shorter strands. In our example we want DNA that is 7 vertice times 20 base pairs, or 140 base pairs long. Deepthi Bollu 34
Step 4 “keep only those that visit each vertex at least once” From the double stranded DNA product of step3, generate single stranded DNA. Incubate the single stranded DNA with S2 conjugated to the magnetic beads. Only single stranded DNA molecules that contained the sequence S2 annealed to the bound S2 and were retained Process is repeated successively with S4,S6,S3,S5 Deepthi Bollu 35
Step 4 “keep only those that visit each vertex at least once” Filter the DNA searching for one vertex at a time. Do this by using a technique called Affinity Purification. (think magnetic beads) s 2 4 6 3 5 t 5 compliment Deepthi Bollu Magnetic bead 36
Step 5:Obtaining the Answer Conduct a “graduated PCR” using a series of PCR amplifications. Use primers for the start, s and the nth item in the path. So to find where vertex 4 lies in the path you would conduct a PCR using the primers from vertex s and vertex 4. You would get a length of 60 base pairs. 60 / 20 nucleotides in the path 3rd vertex. Deepthi Bollu 37
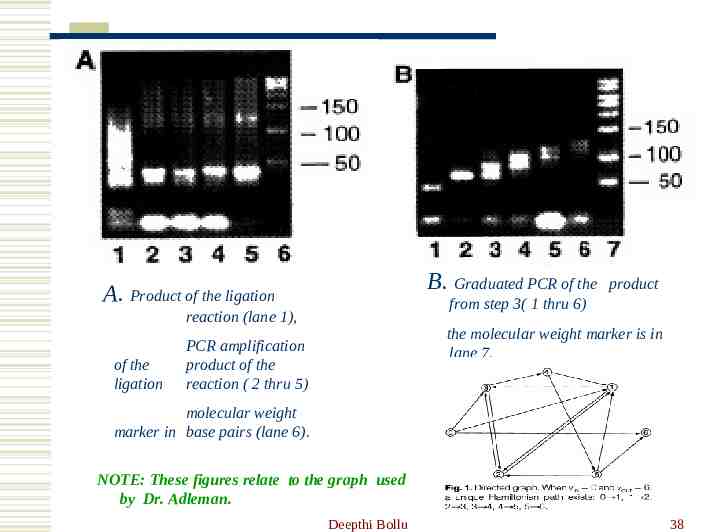
B. Graduated PCR of the A. Product of the ligation from step 3( 1 thru 6) reaction (lane 1), of the ligation product the molecular weight marker is in lane 7. PCR amplification product of the reaction ( 2 thru 5) molecular weight marker in base pairs (lane 6). NOTE: These figures relate to the graph used by Dr. Adleman. Deepthi Bollu 38
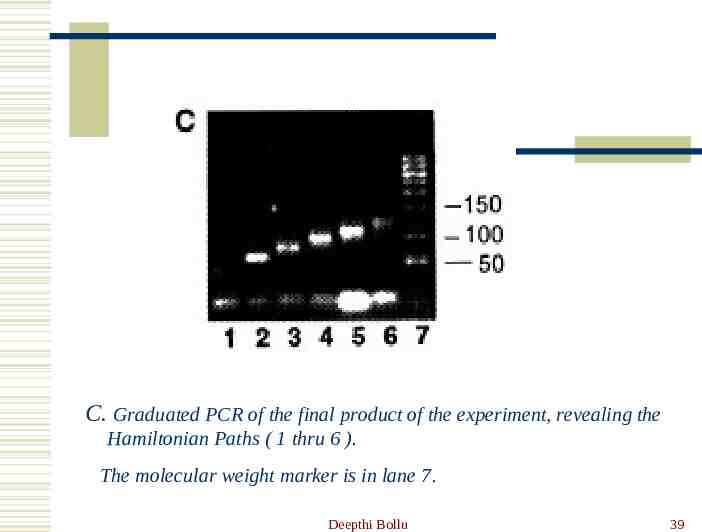
C. Graduated PCR of the final product of the experiment, revealing the Hamiltonian Paths ( 1 thru 6 ). The molecular weight marker is in lane 7. Deepthi Bollu 39
Discover magazine published an article in comic strip format about Leonard Adleman's discovery of DNA computation. Not only entertaining, but also the most understandable explanation of molecular computation I have Ever seen. Deepthi Bollu 40
Recap of HDPP 1. Generate random paths through graph G. (Annealing and Ligation) 2. Select paths that begin with V in and terminate with Vout. (PCR with selected primers) 3. From step 2, select those paths with exactly n vertices. (Gel purification) 4. From step 3, select those paths that contain every vertex. (Magnetic bead purification) 5. If any paths exist from step 4, then there exists a Hamiltonian path. (PCR) Deepthi Bollu 41
DANGEROUS ERRORS
Danger of Errors possible Assuming that the operations used by Adleman model are perfect is not true. Biological Operations performed during the algorithm are susceptible to error Only that which happens within the boundaries of 3 dimensional world are counted lot of probability involved! Errors take place during the manipulation of DNA strands. Most dangerous operations: The operation of Extraction Undesired annealings. Deepthi Bollu 43
The operation of Extraction What would happen if a ‘good’ path were lost during one of the extraction operations in step4? -FALSE NEGATIVE! -Adleman’s suggestion: to amplify the content of the test tube. What if a ‘bad’ path is taken as if it were ‘good’? -FALSE POSITIVE!! -Less dangerous,because the solution could be verified at the end of the computation. Deepthi Bollu 44
Undesired Annealings Types of Undesired annealings Partial Matches:A strand u could anneal with one that’s similar to ū, but it is not the right one. Undesired matches between two shifted strands: Ex:A strand vu could partially anneal with ūw. Finally,a strand could anneal with itself, losing its linear structure. How can the probability of all these undesired annealings be decreased? with an opportune choice of strands used to encode the data of the problem. Deepthi Bollu 45
LIMITATIONS
DNA Vs Electronic computers At Present,NOT competitive with the state-ofthe-art algorithms on electronic computers Only small instances of HDPP can be solved.Reason?.for n vertices, we require 2 n molecules. Time consuming laboratory procedures. Good computer programs that can solve TSP for 100 vertices in a matter of minutes. No universal method of data representation. Deepthi Bollu 47
Size restrictions Adleman’s process to solve the traveling salesman problem for 200 cities would require an amount of DNA that weighed more than the Earth. The computation time required to solve problems with a DNA computer does not grow exponentially, but amount of DNA required DOES. Deepthi Bollu 48
Error Restrictions DNA computing involves a relatively large amount of error. As size of problem grows, probability of receiving incorrect answer eventually becomes greater than probability of receiving correct answer Deepthi Bollu 49
Hidden factors affecting complexity There may be hidden factors that affect the time and space complexity of DNA algorithms with underestimating complexity by as much as a polynomial factor because: they allow arbitrary number of test tubes to be poured together in a single operation. Unrealistic assessment of how reactant concentrations scale with problem size. Deepthi Bollu 50
Some more . Different problems need different approaches. requires human assistance! DNA in vitro decays through time,so lab procedures should not take too long. No efficient implementation has been produced for testing, verification and general experimentation. Deepthi Bollu 51
THE FUTURE! Algorithm used by Adleman for the traveling salesman problem was simple. As technology becomes more refined, more efficient algorithms may be discovered. DNA Manipulation technology has rapidly improved in recent years, and future advances may make DNA computers more efficient. The University of Wisconsin is experimenting with chip-based DNA computers. DNA computers are unlikely to feature word processing, emailing and solitaire programs. Instead, their powerful computing power will be used for areas of encryption, genetic programming, language systems, and algorithms or by airlines wanting to map more efficient routes. Hence better applicable in only some promising areas. Deepthi Bollu 52
THANK YOU! It will take years to develop a practical, workable DNA computer. But Let’s all hope that this DREAM comes true!!! Deepthi Bollu 53
References “Molecular computation of solutions to combinatorial problems”- Leonard .M. Adleman “Introduction to computational molecular biology” by joao setubal and joao meidans -Sections 9.1 and 9.3 “DNA computing, new computing paradigms” by G.Paun, G.Rozenberg, A.Salomaa-chapter 2 Deepthi Bollu 54






