Distributed Software Engineering Hadoop and Spark David A. Wheeler SWE































34 Slides569.50 KB
Distributed Software Engineering Hadoop and Spark David A. Wheeler SWE 622 George Mason University
outline Apache Hadoop Hadoop Distributed File System (HDFS) MapReduce Apache Spark These are changing rapidly – active area of use and growth. These are big areas today “Silicon Valley investors have poured 2 billion into companies based on the data-collection software known as Hadoop.”– Wall Street Journal, June 15, 2015 IBM to invest few hundred million dollars a year in Spark Not including investments by Facebook, Google, Yahoo!, Baidu, and others SWE 622 – Distributed Software Engineering Wheeler 2
Apache Hadoop: Purpose “Framework that allows distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver highavailability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.” Source: https://hadoop.apache.org/ SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 3
Apache Hadoop – key components Hadoop Common: Common utilities (Storage Component) Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access Many other data storage approaches also in use E.G., Apache Cassandra, Apache Hbase, Apache Accumulo (NSAcontributed) (Scheduling) Hadoop YARN: A framework for job scheduling and cluster resource management (Processing) Hadoop MapReduce (MR2): A YARN-based system for parallel processing of large data sets Other execution engines increasingly in use, e.g., Spark Note: All of these key components are OSS under Apache 2.0 license Related: Ambari, Avro, Cassandra, Chukwa, Hbase, Hive, Mahout, Pig, Tez, Zookeeper SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 4
Hadoop Distributed File System (HDFS) (1) Inspired by “Google File System” Stores large files (typically gigabytes-terabytes) across multiple machines, replicating across multiple hosts Breaks up files into fixed-size blocks (typically 64 MiB), distributes blocks The blocks of a file are replicated for fault tolerance The block size and replication factor are configurable per file Default replication value (3) - data is stored on three nodes: two on the same rack, and one on a different rack File system intentionally not fully POSIX-compliant Write-once-read-many access model for files. A file once created, written, and closed cannot be changed. This assumption simplifies data coherency issues and enables high throughput data access Intend to add support for appending-writes in the future Can rename & remove files “Namenode” tracks names and where the blocks are SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 5
Hadoop Distributed File System (HDFS) (2) Hadoop can work with any distributed file system but this loses locality To reduce network traffic, Hadoop must know which servers are closest to the data; HDFS does this Hadoop job tracker schedules jobs to task trackers with an awareness of the data location For example, if node A contains data (x,y,z) and node B contains data (a,b,c), the job tracker schedules node B to perform tasks on (a,b,c) and node A would be scheduled to perform tasks on (x,y,z) This reduces the amount of traffic that goes over the network and prevents unnecessary data transfer Location awareness can significantly reduce job-completion times when running data-intensive jobs Source: http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 6
Handling structured data Data often more structured Google BigTable (2006 paper) Designed to scale to Petabytes, 1000s of machines Maps two arbitrary string values (row key and column key) and timestamp into an associated arbitrary byte array Tables split into multiple “tablets” along row chosen so tablet will be 200 megabytes in size (compressed when necessary) Data maintained in lexicographic order by row key; clients can exploit this by selecting row keys for good locality (e.g., reversing hostname in URL) Not a relational database; really a sparse, distributed multidimensional sorted map Implementations of approach include: Apache Accumulo (from NSA; cell-level access labels), Apache Cassandra, Apache Hbase, Google Cloud BigTable (released 2005) Sources: https://en.wikipedia.org/wiki/BigTable; “Bigtable ” by Chang SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 7
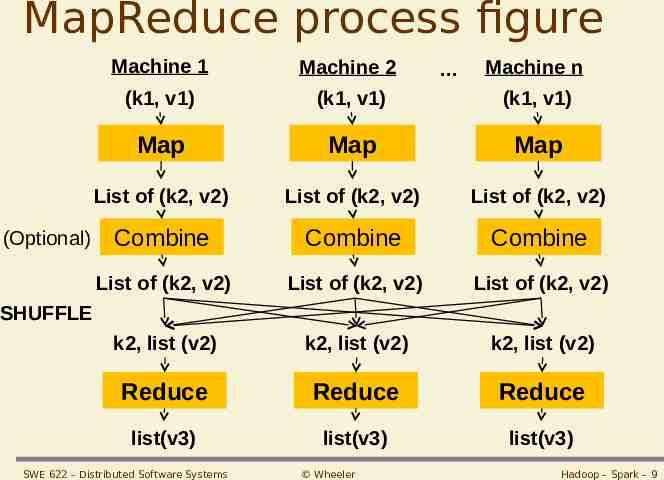
(Parallel) MapReduce MapReduce is a programming model for processing and generating large data sets with a parallel, distributed algorithm on a cluster Programmer defines two functions, map & reduce Map(k1,v1) list(k2,v2). Takes a series of key/value pairs, processes each, generates zero or more output key/value pairs Reduce(k2, list (v2)) list(v3). Executed once for each unique key k2 in the sorted order; iterate through the values associated with that key and produce zero or more outputs System “shuffles” data between map and reduce (so “reduce” function has whole set of data for its given keys) & automatically handles system failures, etc. SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 8
MapReduce process figure (Optional) Machine 1 Machine 2 (k1, v1) (k1, v1) (k1, v1) Map Map Map List of (k2, v2) List of (k2, v2) List of (k2, v2) Combine Combine Combine List of (k2, v2) List of (k2, v2) List of (k2, v2) k2, list (v2) k2, list (v2) k2, list (v2) Reduce Reduce Reduce list(v3) list(v3) list(v3) Machine n SHUFFLE SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 9
MapReduce: Word Count Example (Pseudocode) map(String input key, String input value): // input key: document name // input value: document contents for each word w in input value: EmitIntermediate(w, "1"); reduce(String output key, Iterator intermediate values): // output key: a word // output values: a list of counts Any 12 int result 0; Ball 1 for each v in intermediate values: Computer 3 result ParseInt(v); Emit(AsString(result)); http://research.google.com/archive/mapreduce-osdi04-slides/index-auto-0004.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 10
MapReduce Combiner Can also define an option function “Combiner” (to optimize bandwidth) If defined, runs after Mapper & before Reducer on every node that has run a map task Combiner receives as input all data emitted by the Mapper instances on a given node Combiner output sent to the Reducers, instead of the output from the Mappers Is a "mini-reduce" process which operates only on data generated by one machine If a reduce function is both commutative and associative, then it can be used as a Combiner as well Useful for word count – combine local counts Source: https://developer.yahoo.com/hadoop/tutorial/module4.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 11
MapReduce problems & potential solution MapReduce problems: Many problems aren’t easily described as map-reduce Persistence to disk typically slower than in-memory work Alternative: Apache Spark a general-purpose processing engine that can be used instead of MapReduce SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 12
Apache Spark Processing engine; instead of just “map” and “reduce”, defines a large set of operations (transformations & actions) Operations can be arbitrarily combined in any order Open source software Supports Java, Scala and Python Original key construct: Resilient Distributed Dataset (RDD) Original construct, so we’ll focus on that first More recently added: DataFrames & DataSets Different APIs for aggregate data SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 13
Resilient Distributed Dataset (RDD) – key Spark construct RDDs represent data or transformations on data RDDs can be created from Hadoop InputFormats (such as HDFS files), “parallelize()” datasets, or by transforming other RDDs (you can stack RDDs) Actions can be applied to RDDs; actions force calculations and return values Lazy evaluation: Nothing computed until an action requires it RDDs are best suited for applications that apply the same operation to all elements of a dataset Less suitable for applications that make asynchronous finegrained updates to shared state SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 14
Spark example #1 (Scala) // “sc” is a “Spark context” – this transforms the file into an RDD val textFile sc.textFile("README.md") // Return number of items (lines) in this RDD; count() is an action textFile.count() // Demo filtering. Filter is a transform. By itself this does no real work val linesWithSpark textFile.filter(line line.contains("Spark")) // Demo chaining – how many lines contain “Spark”? count() is an action. textFile.filter(line line.contains("Spark")).count() // Length of line with most words. Reduce is an action. textFile.map(line line.split(" ").size).reduce((a, b) if (a b) a else b) // Word count – traditional map-reduce. collect() is an action val wordCounts textFile.flatMap(line line.split(" ")).map(word (word, 1)).reduceByKey((a, b) a b) wordCounts.collect() Source: https://spark.apache.org/docs/latest/quick-start.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 15
Spark example #2 (Python) # Estimate π (compute-intensive task). # Pick random points in the unit square ((0, 0) to (1,1)), # See how many fall in the unit circle. The fraction should be π / 4 # Note that “parallelize” method creates an RDD def sample(p): x, y random(), random() return 1 if x*x y*y 1 else 0 count spark.parallelize(xrange(0, NUM SAMPLES)).map(sample) \ .reduce(lambda a, b: a b) print "Pi is roughly %f" % (4.0 * count / NUM SAMPLES) Source: https://spark.apache.org/docs/latest/quick-start.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 16
Sample Spark transformations map(func): Return a new distributed dataset formed by passing each element of the source through a function func. filter(func): Return a new dataset formed by selecting those elements of the source on which func returns true union(otherDataset): Return a new dataset that contains the union of the elements in the source dataset and the argument. intersection(otherDataset): Return a new RDD that contains the intersection of elements in the source dataset and the argument. distinct([numTasks])): Return a new dataset that contains the distinct elements of the source dataset join(otherDataset, [numTasks]): When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. Source: https://spark.apache.org/docs/latest/programming-guide.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 17
Sample Spark Actions reduce(func): Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. collect(): Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. count(): Return the number of elements in the dataset. Remember: Actions cause calculations to be performed; transformations just set things up (lazy evaluation) Source: https://spark.apache.org/docs/latest/programming-guide.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 18
Spark – RDD Persistence You can persist (cache) an RDD When you persist an RDD, each node stores any partitions of it that it computes in memory and reuses them in other actions on that dataset (or datasets derived from it) Allows future actions to be much faster (often 10x). Mark RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it Can choose storage level (MEMORY ONLY, DISK ONLY, MEMORY AND DISK, etc.) Can manually call unpersist() SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 19
Spark Example #3 (Python) # # # # # Logistic Regression - iterative machine learning algorithm Find best hyperplane that separates two sets of points in a multi-dimensional feature space. Applies MapReduce operation repeatedly to the same dataset, so it benefits greatly from caching the input in RAM points spark.textFile(.).map(parsePoint).cache() w numpy.random.ranf(size D) # current separating plane for i in range(ITERATIONS): gradient points.map( lambda p: (1 / (1 exp(-p.y*(w.dot(p.x)))) - 1) * p.y * p.x ).reduce(lambda a, b: a b) w - gradient print "Final separating plane: %s" % w Source: https://spark.apache.org/docs/latest/quick-start.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 20
Spark Example #3 (Scala) // Same thing in Scala val points spark.textFile(.).map(parsePoint).cache() var w Vector.random(D) // current separating plane for (i - 1 to ITERATIONS) { val gradient points.map(p (1 / (1 exp(-p.y*(w dot p.x))) - 1) * p.y * p.x ).reduce( ) w - gradient } println("Final separating plane: " w) Source: https://spark.apache.org/docs/latest/quick-start.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 21
Spark Example #3 (Java) // Same thing in Java class ComputeGradient extends Function DataPoint, Vector { private Vector w; ComputeGradient(Vector w) { this.w w; } public Vector call(DataPoint p) { return p.x.times(p.y * (1 / (1 Math.exp(w.dot(p.x))) - 1)); } } JavaRDD DataPoint points spark.textFile(.).map(new ParsePoint()).cache(); Vector w Vector.random(D); // current separating plane for (int i 0; i ITERATIONS; i ) { Vector gradient points.map(new ComputeGradient(w)).reduce(new AddVectors()); w w.subtract(gradient); } System.out.println("Final separating plane: " w); Source: https://spark.apache.org/docs/latest/quick-start.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 22
A tale of multiple APIs For simplicity I’ve emphasized a single API set – the original one, RDD Spark now has three sets of APIs— RDDs, DataFrames, and Datasets RDD – In Spark 1.0 release, “lower level” DataFrames – Introduced in Spark 1.3 release Dataset – Introduced in Spark 1.6 release Each with pros/cons/limitations SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 23
DataFrame & Dataset DataFrame: Unlike an RDD, data organized into named columns, e.g. a table in a relational database. Imposes a structure onto a distributed collection of data, allowing higher-level abstraction Dataset: Extension of DataFrame API which provides typesafe, object-oriented programming interface (compile-time error detection) Both built on Spark SQL engine & use Catalyst to generate optimized logical and physical query plan; both can be converted to an RDD https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/ https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 24
API distinction: typing Python & R don’t have compile-time type safety checks, so only support DataFrame Error detection only at runtime Java & Scala support compile-time type safety checks, so support both DataSet and DataFrame Dataset APIs are all expressed as lambda functions and JVM typed objects any mismatch of typed-parameters will be detected at compile time. https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 25
Apache Spark: Libraries “on top” of core that come with it Spark SQL Spark Streaming – stream processing of live datastreams MLlib - machine learning GraphX – graph manipulation extends Spark RDD with Graph abstraction: a directed multigraph with properties attached to each vertex and edge. SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 26
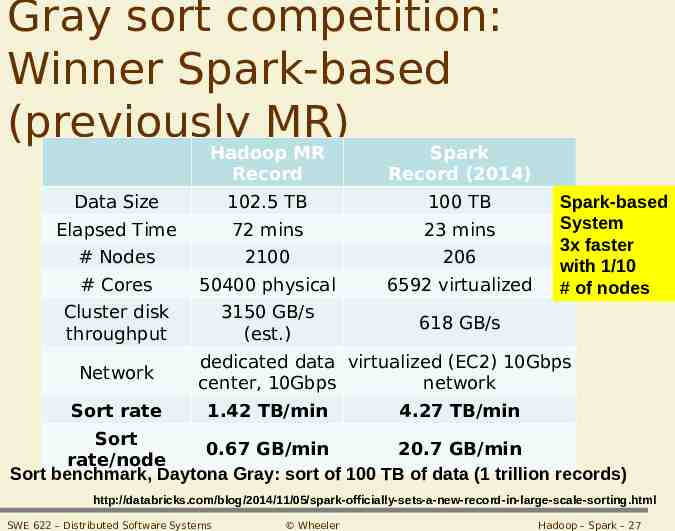
Gray sort competition: Winner Spark-based (previously MR) Hadoop MR Spark Record Record (2014) Data Size 102.5 TB 100 TB Elapsed Time 72 mins 23 mins # Nodes 2100 206 # Cores 50400 physical 6592 virtualized Cluster disk throughput 3150 GB/s (est.) 618 GB/s Network Sort rate Spark-based System 3x faster with 1/10 # of nodes dedicated data virtualized (EC2) 10Gbps center, 10Gbps network 1.42 TB/min 4.27 TB/min Sort 0.67 GB/min 20.7 GB/min rate/node Sort benchmark, Daytona Gray: sort of 100 TB of data (1 trillion records) http://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 27
Spark vs. Hadoop MapReduce Performance: Spark normally faster but with caveats Spark can process data in-memory; Hadoop MapReduce persists back to the disk after a map or reduce action Spark generally outperforms MapReduce, but it often needs lots of memory to do well; if there are other resourcedemanding services or can’t fit in memory, Spark degrades MapReduce easily runs alongside other services with minor performance differences, & works well with the 1-pass jobs it was designed for Ease of use: Spark is easier to program Data processing: Spark more general Maturity: Spark maturing, Hadoop MapReduce mature “Spark vs. Hadoop MapReduce” by Saggi Neumann (November 24, 2014) https://www.xplenty.com/blog/2014/11/apache-spark-vs-hadoop-mapreduce/ SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 28
AMPLab’s Berkeley Data Analytics Stack (BDAS) Don’t need to memorize this figure – the point is to know that components can be combined to solve big data problems Source: https://amplab.cs.berkeley.edu/software/ SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 29
Mr. Penumbra's 24-Hour Bookstore Mr. Penumbra's 24-Hour Bookstore is a 2012 fictional novel by Robin Sloan (American writer) Widely praised In best 100 books of 2012 by the San Francisco Chronicle New York Times Editor's Choice New York Times Hardcover Fiction Best Seller list NPR Hardcover Fiction Bestseller List Hadoop features prominently in its plot SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 30
Closing caveat: choose the right tool for the job (1 of 3) Solving human problems using limited resources is engineering Necessarily involves trade-offs Trade-off decisions should be made wisely Cargo cult engineering is unwise “You Are Not Google” by Oz Nova, 2017-0607: “if you're using a technology that originated at a large company, but your use case is very different, it's unlikely that you arrived there deliberately. what's important is that you actually use the right tool for the job.” [Nova2017] https://blog.bradfieldcs.com/you-are-not-google-84912cf44afb SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 31
Closing caveat: choose the right tool for the job (2 of 3) “Why we decided to go for the Big Rewrite” by Robert Kreuzer, 2019-10-04 “We used to be heavily invested into Apache Spark - but we have been Spark-free for six months now one of our original mistakes [was] we had tried to “futureproof” our system by trying to predict our future requirements. One of our main reasons for choosing Apache Spark had been its ability to handle very large datasets [but] we did not have any datasets that were this large. In fact, 5 years later, we still do not. Prematurely designing systems “for scale” is just another instance of premature optimization We do not need a distributed file system, Postgres will do. We do not need a distributed compute cluster, a horizontally sharded compute system will do.” https://tech.channable.com/posts/2019-10-04-why-we-decided-to-go-for-the-big-rewrite.html SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 32
Closing caveat: choose right tool for the job (3 of 3) Spark really is awesome for certain kinds of problems However, beware of the siren call Do not choose a technology because it’s the “newest/latest thing” (fad-based engineering) or “this will scale far beyond my needs” (overengineering) Know what tools exist, & choose the best one for the circumstance In some cases that could be Spark SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 33
For more information Spark tutorials http://spark-summit.org/2014/training “Resilient Distributed Datasets: A Fault-Tolerant Abstraction for InMemory Cluster Computing” by Matei Zaharia et al https://www.cs.berkeley.edu/ matei/pap ers/2012/nsdi spark.pdf SWE 622 – Distributed Software Systems Wheeler Hadoop – Spark – 34






