Designing Experimentation Metrics PAVEL DMITRIEV, MICROSOFT ANALYSIS














15 Slides8.48 MB
Designing Experimentation Metrics PAVEL DMITRIEV, MICROSOFT ANALYSIS & EXPERIMENTATION 1
Importance of right metrics In 1902, the French quarter in Hanoi was overrun with rats. A "deratisation" scheme paid citizens for each rat they captured (the proof requested for payment was rat’s tail). Rats Killed per day 1,000/day 4,000/day April, 1902 Week 1 April, 1902 Week 2 20,000/day July, 1902 But they barely made a dent in the problem! Investigation revealed two phenomena: 1. Tailless rats started appearing 2. A thriving rat farming industry emerged in the city https://community.redhat.com/blog/2014/07/when-metrics-go-wrong/ http://www.freakonomics.com/media/vannrathunt.pdf https://en.wikipedia.org/wiki/Cobra effect 2
Experimentation Metrics Taxonomy While analyzing the results of an experiment we compute many of metrics of different type and role. 1. Data Quality metrics 2. OEC (Overall Evaluation Criteria) metric 3. Guardrail metrics 4. Local feature and diagnostic metrics A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments Principles for the design of online metrics Data-Driven Metric Development for Online Controlled Experiments Seven Rules of Thumb for Web Site Experimenters Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 3
Data Quality metrics Are the results trustworthy? Sample Ratio Mismatch (SRM) Data loss Click reliability Cookie churn Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 4
OEC: Overall Evaluation Criteria Was the treatment successful? A single metric or a few key metrics Two key properties: 1. Alignment with long-term company goals (Directionality) 2. Ability to impact (Sensitivity) OEC vs KPIs (Key Performance Indicators) KPIs are lagging metrics reported monthly/quarterly/yearly at the overall product level (DAU, MAU, Revenue, etc.) OEC is a leading metric measured during the experiment (e.g. 2 weeks) at user level, which is indicative of long term increase in KPIs Designing a good OEC is hard o Example: OEC for a search engine Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics http://www.exp-platform.com/Pages/hippo long.aspx http://bit.ly/expUnexpected http://www.exp-platform.com/Pages/PuzzlingOutcomesExplained.aspx http://www.exp-platform.com/Documents/2016CIKM MeasuringMetrics.pdf 5
OEC for Search The two key search engine (Bing, Google) KPIs are Query Share (distinct queries) and Revenue Should OEC be Queries/User and Revenue/User? Example: A ranking bug in an experiment resulted in very poor search results Degraded (algorithmic) search results cause users to search more to complete their task, and ads appear more relevant Distinct queries went up over 10%, and revenue went up over 30% What metrics should be in the OEC for a search engine? http://www.exp-platform.com/Pages/PuzzlingOutcomesExplained.aspx Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 6
OEC for Search Analyzing queries per month, we have where a session begins with a query and ends with 30-minutes of inactivity. (Ideally, we would look at tasks, not sessions). In a controlled experiment, the variants get (approximately) the same number of users by design, so the last term is about equal Key observation: we want users to find answers and complete tasks quickly, so queries/session should be smaller The OEC should therefore be based on the middle term: Sessions/User Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 7
OEC for Search: Sensitivity While Sessions/User has great directionality, it rarely moves in our experiments Both because it is hard to change the pattern of user visits in a short term experiment, and because of its statistical properties More on this later in the tutorial The Search OEC we developed includes Sessions/User, but also adds other more sensitive surrogate metrics that are predictive of Sessions/User movement. Surrogates are based on the concept of search success - how successful were users in their search tasks? http://www.exp-platform.com/Pages/PuzzlingOutcomesExplained.aspx Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 8
More OEC Examples Netflix: Subscription business KPI: Retention (i.e. the fraction of users who return month over month) OEC: Viewing Hours. Strong correlation between viewing hours and retention Coursera: Care about course completion, make money by users pay for certifications KPIs: Course completions, # Certificates sold, Revenue OEC: Test completion and Course engagement. Predictive of course completion and certificates sold Examples are from “Designing with Data: Improving the User Experience with A/B Testing” 9
How to come up with the right OEC? In the beginning: Start simple: frequency of user visits can be a good indicator of user happiness Evaluate and improve based on “learning experiments”: o An obviously positive change: that will clearly increase user happiness like removing ads o An obviously negative change: like adding latency or decreasing relevance of search results Continue to improve directionality and sensitivity over time: Setup a metric evaluation framework: curate a diverse set of labeled experiments agreed to be positive, negative or neutral with respect to long-term value. Test changes to the OEC on this set. http://www.exp-platform.com/Documents/2016CIKM MeasuringMetrics.pdf Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 10
Experimentation Metrics Taxonomy While analyzing the results of an experiment we usually compute 1000’s of metrics of different type and role. 1. Data Quality metrics Are the results trustworthy? e.g. Sample Ratio Mismatch 2. OEC (Overall Evaluation Criteria) Metric Was the treatment successful? e.g. Sessions/User 3. Guardrail metrics Did the treatment cause an unacceptable harm to key metrics? e.g. KPI metrics, Performance metrics, short-term Revenue 4. Local feature and diagnostic metrics Why the OEC and guardrail metrics moved or did not move? e.g. number of impressions and clicks on a feature/button/link Data Quality metrics OEC metrics Guard rail metrics Local feature/Diagnostic metrics 11
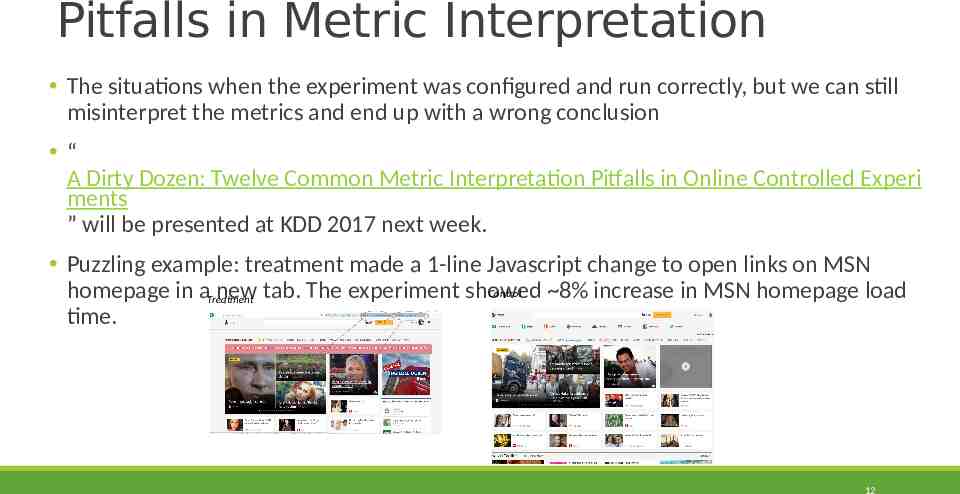
Pitfalls in Metric Interpretation The situations when the experiment was configured and run correctly, but we can still misinterpret the metrics and end up with a wrong conclusion “ A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experi ments ” will be presented at KDD 2017 next week. Puzzling example: treatment made a 1-line Javascript change to open links on MSN Control homepage in aTreatment new tab. The experiment showed 8% increase in MSN homepage load time. 12
Pitfalls in Metric Interpretation The situations when the experiment was configured and run correctly, but we can still misinterpret the metrics and end up with a wrong conclusion “A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments” will be presented at KDD 2017 next week. Puzzling example: treatment made a 1-line Javascript change to open links on MSN homepage in a new tab. The experiment showed a large increase in MSN homepage load time. Metric-level SRM. The treatment has fewer repeated homepage loads which are usually faster than the first homepage load due to caching. The comparison between the treatment and control population for time to load is not fair & no causal inference can be drawn. Lessons: alert on metric-level SRMs 13
Summary Having good metrics is critical “You get what you measure” Metrics have different types and roles in the analysis of an experiment Data Quality metrics, OEC metric, Guardrail metrics, Local feature/Diagnostic metrics Designing a good OEC is hard A leading metric measured in a 2 week period but indicative of long term goals Start simple and continuously improve over time Prevent metric interpretation pitfalls 16
Questions? http://exp-platform.com 20






