Data Mining for Social Network Analysis IEEE ICDM 2006, Hong Kong



















































































89 Slides8.80 MB
Data Mining for Social Network Analysis IEEE ICDM 2006, Hong Kong Jaideep Srivastava, Nishith Pathak, Sandeep Mane, Muhammad A. Ahmad University of Minnesota
Fair Use Agreement This agreement covers the use of all slides on this CD-Rom, please read carefully. You may freely use these slides for teaching, if You send me an email telling me the class number/ university in advance. My name and email address appears on the first slide (if you are using all or most of the slides), or on each slide (if you are just taking a few slides). You may freely use these slides for a conference presentation, if You send me an email telling me the conference name in advance. My name appears on each slide you use. You may not use these slides for tutorials, or in a published work (tech report/ conference paper/ thesis/ journal etc). If you wish to do this, email me first, it is highly likely I will grant you permission. (c) Jaideep Srivastava, [email protected] 12/02/06 IEEE ICDM 2006 2
Outline Introduction to Social Network Analysis (SNA) Computer Science and SNA The Enron Email Dataset SNA techniques and tools – – Measures and models for SNA Algorithms for SNA Application of SNA Techniques – – In specific domains In computer science research Data Mining for SNA Case Study – Socio-cognitive analysis from e-mail logs Some Emerging Applications References 12/02/06 IEEE ICDM 2006 3
Introduction to Social Network Analysis
Social Networks A social network is a social structure of people, related (directly or indirectly) to each other through a common relation or interest Social network analysis (SNA) is the study of social networks to understand their structure and behavior (Source: Freeman, 2000) 12/02/06 IEEE ICDM 2006 5
SNA in Popular Science Press Social Networks have captured the public imagination in recent years as evident in the number of popular science treatment of the subject 12/02/06 IEEE ICDM 2006 6
Networks in Social Sciences Types of Networks (Contractor, 2006) – Social Networks “who knows who” – Socio-Cognitive Networks “who thinks who knows who” – Knowledge Networks “who knows what” – Cognitive Knowledge Networks “who thinks who knows what” 12/02/06 IEEE ICDM 2006 7
Types of Social Network Analysis Sociocentric (whole) network analysis – Emerged in sociology – Involves quantification of interaction among a socially welldefined group of people – Focus on identifying global structural patterns – Most SNA research in organizations concentrates on sociometric approach Egocentric (personal) network analysis – Emerged in anthropology and psychology – Involves quantification of interactions between an individual (called ego) and all other persons (called alters) related (directly or indirectly) to ego – Make generalizations of features found in personal networks – Difficult to collect data, so till now studies have been rare 12/02/06 IEEE ICDM 2006 8
Networks Research in Social Sciences Anthropology Organizational Theory Perception Socio-Cognitive Networks Reality Epidemiology Social Networks Acquaintance (links) Social Psychology Cognitive Knowledge Networks Knowledge Networks Knowledge (content) Sociology Social science networks have widespread application in various fields Most of the analyses techniques have come from Sociology, Statistics and Mathematics See (Wasserman and Faust, 1994) for a comprehensive introduction to social network analysis 12/02/06 IEEE ICDM 2006 9
Computer Science and Social Network Analysis
Computer networks as social networks “Computer networks are inherently social networks, linking people, organizations, and knowledge” (Wellman, 2001) Data sources include newsgroups like USENET; instant messenger logs like AIM; e-mail messages; social networks like Orkut and Yahoo groups; weblogs like Blogger; and online gaming communities USENET 12/02/06 IEEE ICDM 2006 11
Key Drivers for CS Research in SNA Computer Science has created the über-cyberinfrastructure for – Social Interaction – Knowledge Exchange – Knowledge Discovery Ability to capture – different about various types of social interactions – at a very fine granularity – with practically no reporting bias Data mining techniques can be used for building descriptive and predictive models of social interactions Fertile research area for data mining research 12/02/06 IEEE ICDM 2006 12
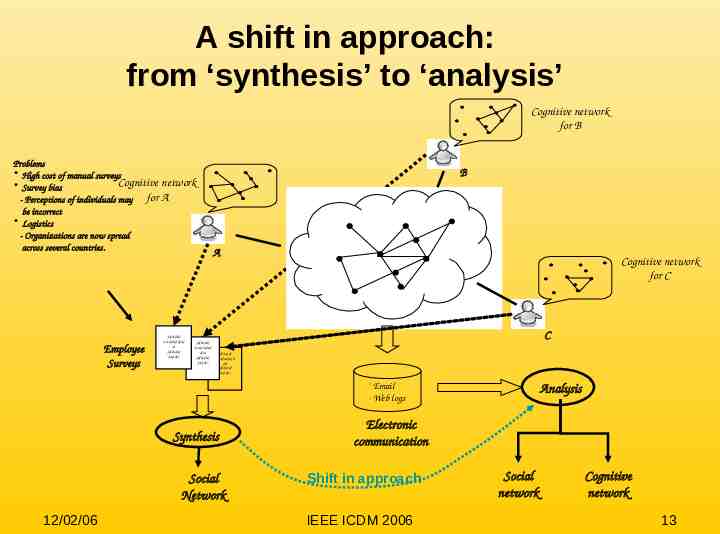
A shift in approach: from ‘synthesis’ to ‘analysis’ Cognitive network for B Problems High cost of manual surveys Cognitive network Survey bias - Perceptions of individuals may for A be incorrect Logistics - Organizations are now spread across several countries. Employee Surveys Sdfdsfsdf Fvsdfsdfsdfdf sd Sdfdsfsdf Sdfsdfs B A Sdfdsfsdf Fvsdfsdfsdf dfsd Sdfdsfsdf Sdfdsfsdf Fvsdfsdfsdfd Sdfsdfs fsd Sdfdsfsdf Sdfsdfs Synthesis Social Network 12/02/06 Cognitive network for C C - Email - Web logs Analysis Electronic communication Shift in approach IEEE ICDM 2006 Social network Cognitive network 13
The Enron Email Dataset
Dataset description Publicly available: http://www.cs.cmu.edu/ enron/ Cleaned version of data – – – – 151 users, mostly senior management of Enron Approximately 200,399 email messages Almost all users use folders to organize their emails The upper bound for number of folders for a user was approximately the log of the number of messages for that user A visualization of Enron email network (Source: Heer, 2005) 12/02/06 IEEE ICDM 2006 15
Spectral and graph theoretic analysis Chapanond et al (2005) – Spectral and graph theoretic analysis of the Enron email dataset – Enron email network follows a power law distribution – A giant component with 62% of nodes – Spectral analysis reveals that the Enron data’s adjacency matrix is approximately of rank 2 – Since most of the structure is captured by first 2 singular values, the paper presents a visual picture of the Enron graph 12/02/06 (Source: Chapanond et al, 2005) IEEE ICDM 2006 16
Other analyses of Enron data Shetty and Adibi (2004) – Introduction to the dataset – Presented basic statistics on e-mail exchange Diesner and Carley (2005) – Compare the social network for the crisis period (Oct, 2001) to that of a normal time period (Oct, 2000) – The network in Oct, 2001 was more dense, connected and centralized compared to that of Oct, 2000 – Half of the key actors in Oct, 2000 remained important in Oct, 2001 – During crisis, the communication among employees did not necessarily follow the organization structure/hierarchy – During the crisis period the top executives formed a tight clique indicating mutual support 12/02/06 IEEE ICDM 2006 17
SNA – History & Key Concepts
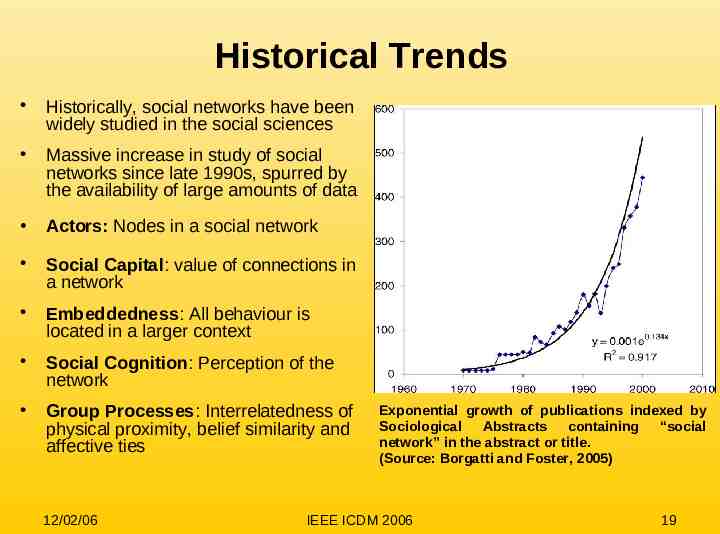
Historical Trends Historically, social networks have been widely studied in the social sciences Massive increase in study of social networks since late 1990s, spurred by the availability of large amounts of data Actors: Nodes in a social network Social Capital: value of connections in a network Embeddedness: All behaviour is located in a larger context Social Cognition: Perception of the network Group Processes: Interrelatedness of physical proximity, belief similarity and affective ties 12/02/06 Exponential growth of publications indexed by Sociological Abstracts containing “social network” in the abstract or title. (Source: Borgatti and Foster, 2005) IEEE ICDM 2006 19
Key Terms & Concepts Dyad: A pair of actors (connected by a relationship) in the network Triad: A subset of three actors or nodes connected to each other by the social relationship Degree Centrality: Degree of a node normalized to the interval {0 . 1} Clustering Coefficient: If a vertex vi has ki neighbors, ki(ki-1)/2 edges can exist among the vertices within the neighborhood. The clustering coefficient is defined as (M. E. J. Newman 2003, Watts, D. J. and Strogatz 1998) 12/02/06 IEEE ICDM 2006 20
(P. Marsden 2002) (Jon Kleinberg 1999, 2001, D Watts, S Strogatz 1998, D Watts 1999, 2003) Terms & Key Concepts Six-degrees of separation: Seminal experiment by Stanley Milgram Scale Free Networks: Networks that exhibit power law distribution for edge degrees Preferential Attachment: A model of network growth where a new node creates an edge to an extant node with a probability proportional to the current in-degree of the node being connected to Small world phenomenon: Most pairs of nodes in the network are reachable by a short chain of intermediates; usually the average pairwise path length is bound by a polynomial in log n (i) Regular Network 12/02/06 (ii) Small World Network (iii) Random Network IEEE ICDM 2006 21
SNA Techniques and tools: Measures and models for SNA
Measures of network centrality Betweenness Centrality: Measures how many times a node occurs in a shortest path; measure of ‘social brokerage power’ – Most popular measure of centrality – Efficient computation is important, best technique is O(mn) Closeness Centrality: The total graph-theoretic distance of a given node from all other nodes Degree centrality: Degree of a node normalized to the interval {0 . 1} – is in principle identical for egocentric and sociocentric network data Eigenvector centrality: Score assigned to a node based on the principle that a high scoring neighbour contributes more weight to it – Google’s PageRank is a special case of this Other measures – Information centrality All of the above measures have directed counterparts 12/02/06 IEEE ICDM 2006 23
Community Similarity Measures Comparison of measuring similarities between communities L1-Norm: Overlap between the two groups divided by the product of their sizes L2-Norm: Similar to L1-Norm but based on cosine distance Pairwise Mutual Information (positive correlation): An information theoretic measure that focuses on how membership in one group is predictive of membership in another Pairwise Mutual Information (positive and negative correlation): Similar to the previous measure but with negative correlations also included TF-IDF: Measure based on inverse document frequency Log-odds: The standard log-odds function gives the exact same ranking as L1-Norm and thus a modified form of log-odds function is used (E Spertus et al. 2005) 12/02/06 IEEE ICDM 2006 24
SNA for Macroeconomics (Jackson, 2004) Modelling approach Players and their relationships represented as a network Value function associated with network structure Represents productivity/utility of society of players Allocation rule that distributes network value among players Game can be cooperative, non-cooperative, zero-sum, non zero-sum, etc. Example: connection model Other models Spatial Connection Model: Spatial costs associated with connections Free-Trade Networks: Treat links as free-trade channels Market Sharing Networks: Nodes are firms and the links as agreements between firms Other Models: Labor Market Networks, Co-author Networks, Buyer-Seller Networks 12/02/06 IEEE ICDM 2006 25
SNA Survey: Link Mining (Getoor & Diehl, 2005) Link Mining: Data Mining techniques that take into account the links between objects and entities while building predictive or descriptive models Link based object ranking, Group Detection, Entity Resolution, Link Prediction Applications: Hyperlink Mining, Relational Learning, Inductive Logic Programming, Graph Mining Hubs and Authorities (Kleinberg, 1997) Being Authority depends upon in-edges; an authority has a large number of edges pointing towards it Being a Hub depends upon out-edges; a hub links to a large number of nodes Notice that the definition of hubs and authorities is circular Nodes can be both hubs and authorities at the same time 12/02/06 IEEE ICDM 2006 26
Models for Small World Phenomenon Watts-Strogatz Network Model (1998) Starts with a set V of n points spaced uniformly on a circle Join each vertex by an edge to each of its k nearest neighbors (''local contacts'') Add small number of edges such that vertices are chosen randomly from V with probability p (''long-range contacts'‘) Different values of p yield different types of networks Kleinberg (2001) generalized the Watts-Strogatz Network Model Start with two-dimensional grid and allow for edges to be directed A node u has a directed edge to every other node within lattice distance p -these are its local contacts For a universal constant p 1, the node u has a directed edge to every other node within lattice distance p (local contacts) Using independent random trials, for universal constants q 0, r 0, construct directed edges from u to q other nodes (long-range contacts) 12/02/06 IEEE ICDM 2006 27
Evolution Models of Social Networks Reka and Barbasi’s model (Reka & Barabasi, 2000) – Networks evolve because of local processes – Addition of new nodes, new links or rewiring of old links – The relative frequency of these factors determine whether the network topology has a power-law tail or is exponential – A phase transition in the topology was also determined Characteristics of Collaboration Networks (Newman, 2001, 2003, 2004) – Degree distribution follows a power-law – Average separation decreases in time – Clustering coefficient decays with time – Relative size of the largest cluster increases – Average degree increases – Node selection is governed by preferential attachment 12/02/06 IEEE ICDM 2006 (Source: Barabasi & Laszlo, 2000) 28
Statistical Models of Social Networks Latent Space Models (Hoff, Raftery and Handcock, 2002) Probability of a relation between actors depends upon the position of individuals in an unobserved “social space” Inference for social space is developed within a maximum likelihood and Bayesian framework. Inferences on latent positions is done via Marknov Chain Monto Carlo procedures Groups are not pre-specified. Ties between a set of actors are conditionally independent given the latent class membership of each actor Actors within the same latent class are treated as stochastically equivalent P* Models (Wasserman and Pattison, 1996) Exponentially parametrized random graph models Given a set of n nodes, and X a random graph on these nodes and let x be a particular graph on these nodes Fitting the model refers to estimating the parameter θ given the observed graph. Gibbs sampling and other algorithms are used for estimation The likelihood of l(θ) – l(θ’) converges to the true value as the size of the MCMC sample increases 12/02/06 IEEE ICDM 2006 30
Cascading Models Model of Diffusion of Innovation (Young, 2000) – A group is close-knit if its members have a relatively large fraction of their interactions amongst each other as compared to with others – Interactions between the agents are weighted – Directed edges represent influence of one agent on the other – Agents have to choose between outcomes The choice is based on a utility function which has an individual and a social component – The social component depends upon the choices made by the neighbours – The diffusion of innovation can be treated as a n-person spatial game – Unraveling Problem: Even after a new innovation has emerged in the network, if a sufficiently large enclave does not last long enough then the innovation will be lost Related work: Schelling (1978), Granovetter (1978), Domingos (2005), Watts (2004) 12/02/06 IEEE ICDM 2006 31
SNA and Epidemiology SIR Model (Morris, 2004) Population is divided into three groups Susceptible (S): Individuals who are not infected but can be infected if exposed Infected (I): Individuals who are infected and can also infect others Recovered (R): Individuals who were infected but are now recovered and have immunity Models can be mapped onto bond percolation on the network SEIR Model: Similar to the SIR model with the difference that there is a period of time during which the individual has been infected but is not yet infectious himself SIS Model: Used to model diseases where long lasting immunity is not present Variations of small world and scale-free networks are mainly used as base models 12/02/06 IEEE ICDM 2006 32
SNA Techniques and tools: Algorithms for SNA
SNA Techniques Prominent problems – – – – Social network extraction/construction Link prediction Approximating large social networks Identifying prominent/trusted/expert actors in social networks – Search in social networks – Discovering communities in social networks – Knowledge discovery from social networks 12/02/06 IEEE ICDM 2006 34
Social Network Extraction Mining a social network from data sources Hope et al (2006) identify three sources of social network data on the web – Content available on web pages (e.g. user homepages, message threads etc.) – User interaction logs (e.g. email and messenger chat logs) – Social interaction information provided by users (e.g. social network service websites such as Orkut, Friendster and MySpace) Profile 1 Profile 3 Web Documents Profile 5 Communication Logs 12/02/06 IEEE ICDM 2006 Profile 2 Profile 4 Actor profiles on a Social Network Service 35
Social Network Extraction IR based extraction from web documents: Adamic and Ader (2003), Makrehchi and Kamel (2005), Matsumura et al, (2005) – Construct an “actor-by-term” matrix – The terms associated with an actor come from web pages/documents created by or associated with that actor – IR techniques such as tf-idf, LSI and cosine matching or other intuitive heuristic measures are used to quantify similarity between two actors’ term vectors – The similarity scores are the edge label in the network Thresholds on the similarity measure can be used in order to work with binary or categorical edge labels Include edges between an actor and its k-nearest neighbors Co-occurrence based extraction from web documents Matsuo et al (2006), Kautz et al (1997), Mika (2005) – For each pair of actors X and Y, issue queries of the form “X and Y”, “X or Y”, “X” and “Y” using a search engine (such as Google) and record corresponding number of hits – Use the number of hits to quantify strength of social relation between X and Y Jaccard Coefficient – J(x,y) (hitsX and Y) / (hitsX or Y) Overlap Coefficient – OC(x,y) (hitsX and Y) / min{hitsX,hitsY} See (Matsuo 2006) for a discussion on other measures – Expand the social network by iteratively adding more actors Query known actor X and extract unknown actors from first k hits 12/02/06 IEEE ICDM 2006 36
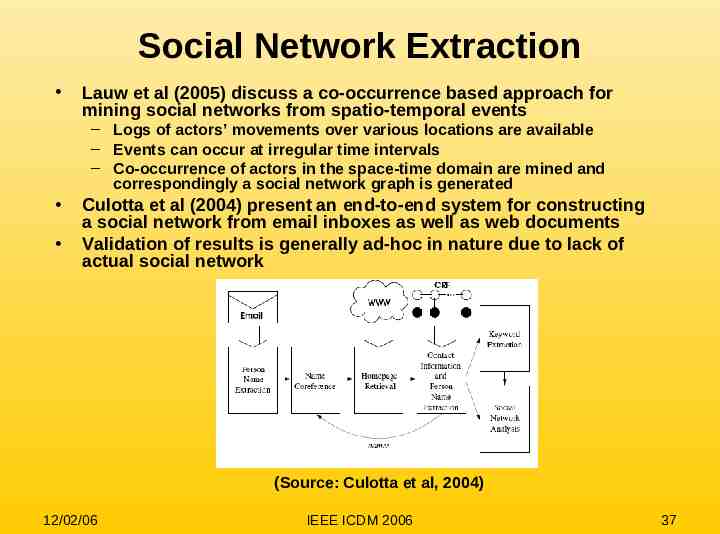
Social Network Extraction Lauw et al (2005) discuss a co-occurrence based approach for mining social networks from spatio-temporal events – Logs of actors’ movements over various locations are available – Events can occur at irregular time intervals – Co-occurrence of actors in the space-time domain are mined and correspondingly a social network graph is generated Culotta et al (2004) present an end-to-end system for constructing a social network from email inboxes as well as web documents Validation of results is generally ad-hoc in nature due to lack of actual social network (Source: Culotta et al, 2004) 12/02/06 IEEE ICDM 2006 37
Link Prediction Different versions – Given a social network at time ti predict the social link between actors at time ti 1 – Given a social network with an incomplete set of social links between a complete set of actors, predict the unobserved social links – Given information about actors, predict the social link between them (this is quite similar to social network extraction) The main approaches for link prediction fit the social network on a model and then use the model for prediction – Latent Space model (Hoff et al, 2002), Dynamic Latent Space model (Sarkar and Moore, 2005), p* model (Wasserman and Pattison, 1996) Other approaches specifically targets the link prediction problem (thus making minimal assumptions about the modeling aspect) Link Prediction of websites using Markov Chains (Sarukkai 2000) Probabilistic Relational Models (PRMs) for relational learning (Getoor 2002) prediction techniques (e.g. Adamic and Ader, 2003) In some cases, social network extraction techniques can be used as link prediction techniques (Adamic and Ader, 2003) 12/02/06 IEEE ICDM 2006 38
Link Prediction Predictive powers of the various proximity features for predicting links between authors in the future (Liben-Nowell and Kleinberg, 2003) – Link prediction as a means to gauge the usefulness of a model – Proximity Features: Common Neighbors, Katz, Jaccard, etc – No single predictor consistently outperforms the others However all perform better than random Link Prediction using supervised learning (Hasan et al, 2006) – Citation Network (BIOBASE, DBLP) – Use machine learning algorithms to predict future co-authorship (decision tree, k-NN, multilayer perceptron, SVM, RBF network) – Identify a group of features that are most helpful in prediction – Best Predictor Features: Keyword Match count, Sum of neighbors, Sum of Papers, Shortest Distance Z. Huang et al (2005) – Link prediction has been applied to recommendation systems 12/02/06 IEEE ICDM 2006 39
Approximating Large Social Networks Approximating a large social network allows for easier analyses, visualization and pattern detection Faloutsos et al (2004) – Extracting a “connection subgraph” from a large graph – A connection subgraph is a small subgraph that best captures the relation between two given nodes in the graph using at most k nodes – Used to focus on and summarize the relation between any two nodes in the network – The node “budget” k is specified by the user – Optimize a goodness function based on an ‘electrical circuit’ model The goodness function is the quantity of current flowing between the two given nodes Edge weights between nodes are used as conductance values A universal sink is attached to every node in order to penalize high degree nodes and longer paths Node budget k 2 12/02/06 IEEE ICDM 2006 40
Approximating Large Social Networks Leskovic and Faloutsos (2006) compare various strategies for sampling a small representative graph from a large graph – Strategies: Random Node, Random Edge, Random Degree Node, Forest Fire, etc. – Global graph properties are computed on sample graph and scaled up to get corresponding metric values for original graph Wu et al (2004) presents an approach for summarizing scale-free networks based on shortest paths between vertices – Determine k number of “median” vertices such that the average shortest path from any vertex to its closest median vertex is minimized – Length of shortest path p between any two vertices is approximated by the sum of shortest distance between median vertices for the clusters of the two vertices sum of shortest distance between the vertices and their respective medians – In case of scale free networks this approximation yields reasonable results – Further efficiency can be achieved by recursively clustering a graph and working with a hierarchy of simplified graphs 12/02/06 IEEE ICDM 2006 41
Identifying Prominent Actors in a Social Network A common approach is to compute scores/rankings over the set (or a subset) of actors in the social network which indicate degree of importance/expertise/influence – E.g. Pagerank, HITS, centrality measures Various algorithms from the link analysis domain – PageRank and its many variants – HITS algorithm for determining authoritative sources Kleinberg (1999) – Discusses different prominence measures in the social science, citation analysis and computer science domains Shetty and Adibi (2005) – Provide an information theory based technique for discovering important nodes in a graph. Centrality measures exist in the social science domain for measuring importance of actors in a social network 12/02/06 IEEE ICDM 2006 42
Identifying Prominent Actors in a Social Network Brandes, (2001) – Prominence high betweenness value – An efficient algorithm for computing for betweenness cetrality – Betweenness centrality requires computation of number of shortest paths passing through each node – Compute shortest paths between all pairs of vertices – Trivial solution of counting all shortest paths for all nodes takes O(n3) time – A recursive formula is derived for the total number of shortest paths originating from source s and passing through a node v s(v) {wi} [1 s(wi)] ( sv / sw) ij is the number of shortest paths between i and j wi is a node which has node v preceding itself on some shortest path from s to itself Nodes s, v and {wi} Source: (Brandes, 2001) – The time complexity reduces to O(mn) for unweighted graphs and O(mn log2n) for weighted graphs – The space complexity decreases from O(n2) to O(n m) 12/02/06 IEEE ICDM 2006 43
Identifying Experts in a Social Network Apart from link analysis there are other approaches for expert identification – Steyvers et al (2004) propose a Bayesian model to assign topic distributions to users which can be used for ranking them w.r.t. to the topics – Harada et al (2004) use a search engine to retrieve top k pages for a particular topic query and then extract the users present in them Assumption: existence implies knowledge (Source: Steyvers et al, 2004) 12/02/06 IEEE ICDM 2006 44
Trust in Social Networks Trust propagation: An approach for inferring trust values in a network – A user trusts some of his friends, his/her friends trust their friends and so on – Given trust and/or distrust values between a handful of pairs of users, can one predict unknown trust/distrust values between any two users Golbeck et al (2003) discusses trust propagation and its usefulness for the semantic web TrustMail – Consider research groups X and Y headed by two professors such that each professor knows the students in their respective group – If a student from group X sends a mail to the professor of group Y then how will the student be rated? – Use the rating of professor from group X who is in professor Y's list of trusted list and propagate the rating Example of a real life trust model – www.ebay.com 12/02/06 IEEE ICDM 2006 45
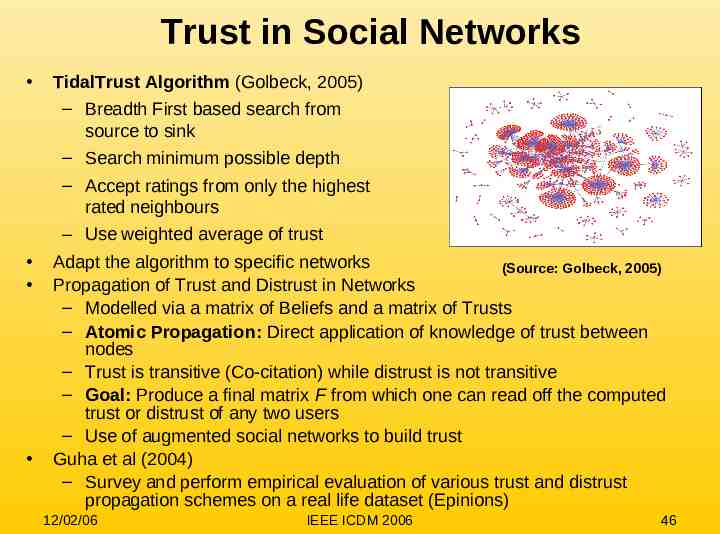
Trust in Social Networks TidalTrust Algorithm (Golbeck, 2005) – Breadth First based search from source to sink – Search minimum possible depth – Accept ratings from only the highest rated neighbours – Use weighted average of trust Adapt the algorithm to specific networks (Source: Golbeck, 2005) Propagation of Trust and Distrust in Networks – Modelled via a matrix of Beliefs and a matrix of Trusts – Atomic Propagation: Direct application of knowledge of trust between nodes – Trust is transitive (Co-citation) while distrust is not transitive – Goal: Produce a final matrix F from which one can read off the computed trust or distrust of any two users – Use of augmented social networks to build trust Guha et al (2004) – Survey and perform empirical evaluation of various trust and distrust propagation schemes on a real life dataset (Epinions) 12/02/06 IEEE ICDM 2006 46
Search in Social Networks Searching/Querying for information in a social network Query routing in a network – A user can send out queries to its neighbors – If the neighbor knows the answer then he/she replies else forward it to their neighbors. Thus a query propagates through a network – Develop schemes for efficient routing through a network Adamic et al (2001) – Present a greedy traversal algorithm for search in power law graphs – At each step the query is passed to the neighbor with the most number of neighbors – A large portion of the graph is examined in a small number of hops Kleinberg and Raghavan (2005) present a game theoretic model for routing queries in a network along with incentives for people who provide answers to the queries Forums can be seen as “broadcast” style techniques for querying in a social network 12/02/06 IEEE ICDM 2006 47
Search in Social Networks Watts-Dodds-Newman's Model (WattsDodds, 2002 Newman, 2003) Individuals in a social network are marked by distinguishing characteristics Groups of individuals can be grouped under groups of groups Group membership is the primary basis for social interaction Individuals hierarchically cluster the social world in multiple ways Perceived similarity between individuals determine 'social distance' between them Message routing in a network is based only on local information Results Searchability is a generic property of real-world social networks 12/02/06 IEEE ICDM 2006 48
Search in Social Networks Yu and Singh (2003) – Each actor has a vector over all terms and every actor stores the vectors and immediate neighborhoods of his/her neighbors – Individual vector entries indicate actor’s familiarity/knowledge about the various terms – Each neighbor is assigned a relevance score – The score is a weighted linear combination of the similarity between query and term vectors (cosine similarity based measure) and the sociability of that neighbor – Sociability is a measure of that neighbor knowing other people who might know the answer – The expert and sociability ratings maintained by a user are updated based on answers provided by various users in the network 12/02/06 IEEE ICDM 2006 49
Query Incentive Networks Kleinberg and Raghavan (2005) Setting: Need for something say T e.g., information, goods etc. Initiate a request for T with a corresponding reward, to some person X X can – Answer the query – Do nothing – Forward the query to another person Problem: How much should X “skim off” from the reward, before propagating the request? A Game Theoretic Model of Networks – query routing in the social network is described as a game Nodes can use strategies for deciding amongst offers All nodes are assumed to be rational A node will receive the incentive after the answer has been found Thus maximize one's incentive offering part of the incentive to others Convex Strategy Space: Nash Equilibrium exists 12/02/06 IEEE ICDM 2006 50
Extracting Communities Discovering communities of users in a social network Possible to use popular link analysis techniques – HITS algorithm However the semantic meaning link analysis techniques associate with links can be different from those of the underlying social network Community structure in networks (Source: Newman, 2006) 12/02/06 IEEE ICDM 2006 51
Extracting Communities Tyler et al (2003) – A graph theoretic algorithm for discovering communities – The graph is broken into connected components and each component is checked to see if it is a community – If a component is not a community then iteratively remove edges with highest betweenness till component splits Betweenness is recomputed each time an edge is removed – The order of in which edges are removed affects the final community structure – Since ties are broken arbitrarily, this affects the final community structure – In order to ensure stability of results, the entire procedure is repeated i times and the results from each iteration are aggregated to produce the final set of communities Girvan and Newman (2002) use a similar algorithm to analyze community structure in social and biological networks 12/02/06 IEEE ICDM 2006 52
Extracting Communities Newman (2004) – Efficient algorithm for community extraction from large graphs – The algorithm is agglomerative hierarchical in nature – The two communities whose amalgamation produces the largest change in modularity are merged – Modularity for a given division of nodes into communities C1 to Ck is defined as Q i(eii-ai2) Where eii is the fraction of edges that join a vertex in Ci to another vertex in Ci and ai is the fraction of edges that are attached to a vertex in Ci Clauset et al (2004) provide an efficient implementation for the above algorithm based on Max Heaps – The algorithm has O(mdlog n) where m, n and d are the number of edges, number of nodes and the depth of the dendrogram respectively 12/02/06 IEEE ICDM 2006 53
Extracting Communities c C U c T u C z w T Nw,e Ne CUT1 Model U z u w Nw,e Ne CUT2 Model Zhou et al (2006) present Bayesian models for discovering communities in email networks – Takes into account the topics of discussion along with the social links while discovering communities 12/02/06 IEEE ICDM 2006 54
Knowledge Discovery from Social Network Data Traditional graph based knowledge discovery techniques can be used (Wenyuan Li, et al, 2005) – – – – – – – – Traditional SNA Methods Spectral analysis of adjacency matrices Mining Frequent Structures and substructures Link Analysis Graph theoretic measures Using visualization if social networks are small enough Kernel Function based analysis Mining customer network value Time series analysis of social network graphs recorded over various time intervals Bader (2006) presents an algebraic tensor decomposition technique for extracting latent structures in social network graphs collected over time – A SVD style decomposition on a 3-dimensional tensor (user x user x time) – An efficient algorithm is provided for large sparse graphs 12/02/06 IEEE ICDM 2006 55
Visualization Semantic web and social network analysis – Paolillo and Wright (2005) provide an approach to visualizing FOAF data that employs techniques of quantitative Social Network Analysis to reveal the workings of a large-scale blogging site, LiveJournal Plot of nine interest clusters along the first two principal clusters (Paolillo and Wright, 2005) 12/02/06 Relation of interest clusters to groups of actors with shared interests (Paolillo and Wright, 2005) IEEE ICDM 2006 56
Applications of SNA Techniques: To specific domains
Application to organization theory Krackhardt and Hanson (1993) – Informal (social) networks present in an enterprise are different from formal networks – Different patterns exist in such networks like imploded relationships, irregular communication patterns, fragile structures, holes in network and bow ties Lonier and Matthews (2004) – Survey as well as study the impact of informal networks on an enterprise (Source: Krackhardt and Hanson,1993) 12/02/06 IEEE ICDM 2006 58
Application to semantic web community Ding et al (2005) – Semantic web enables explicit, online representation of social information while social networks provide a new paradigm for knowledge management e.g. Friend-of-a-friend (FOAF) project ( http://www.foaf-project.org) – Applied SNA techniques to study this FOAF data (DS-FOAF) Preliminary analysis of DS-FOAF data (Ding et al, 2005) Degree distribution Connected components Trust across multiple sources (Ding et al, 2005) 12/02/06 IEEE ICDM 2006 59
Application to marketing Domingos and Richardson (2001, 2002) – Network value of a customer is the expected profit from marketing a product to a customer, taking into account the customer’s influence on the buying decisions of other customers – Applied a probabilistic model to the customers’ social network (Source: Leskovec et al, 2006) High network value Low network value Domingos (2005) – Information extracted from social networks data (Epinions data) on the Web was combined with a recommendation system (EachMovie) – Used for viral (word-of-mouth) marketing 12/02/06 IEEE ICDM 2006 60
Application to criminal network analysis Knowledge gained by applying SNA to criminal network aids law enforcement agencies to fight crime proactively Criminal networks are large, dynamic and characterized by uncertainty. Need to integrate information from multiple sources (criminal incidents) to discover regular patterns of structure, operation and information flow (Xu and Chen, 2005) Computing SNA measures like centrality is NP-hard – Approximation techniques (Carpenter et al 2002) Visualization techniques for such criminal networks are needed Figure: Terrorist network of 9/11 hijackers (Krebs, 2001/ Xu and Chen, 2005) Example of 1st generation visualization tool. 12/02/06 Example of 2nd generation visualization tool IEEE ICDM 2006 61
Application to criminal network analysis Example (Qin et al, 2005) – Information collected on social relations between members of Global Salafi Jihad (GSJ) network from multiple sources (e.g. reports of court proceedings) – Applied social network analysis as well as Web structural mining to this network – Authority derivation graph (ADG) captures (directed) authority in the criminal network Terrorists with top centrality ranks in each clump 12/02/06 1-hop network of 9/11 attack IEEE ICDM 2006 ADG of GSJ network 62
Semantic Web and SNA The friend of a friend (FOAF) project has enabled collection of machine readable data on online social interactions between individuals. http://www.foaf-project.org Mika (2005) illustrates Flink system (http://flink.semanticweb.org/) for extraction, aggregation and visualization of online social network. The Sun never sets under the Semantic Web: the network of semantic web researchers across globe (Mika, 2005) 12/02/06 IEEE ICDM 2006 Snapshot of clusters (http://flink.semanticweb.org/) 63
Application of SNA Techniques: In Computer Science research
Link mining Availability of rich data on link structure between objects Link Mining - new emerging field encompassing a range of tasks including descriptive and predictive modeling (Getoor, 2003) Extending classical data mining tasks – Link-based classification – predict an object’s category based not only on its attributes but also the links it participates in – Link-based clustering – techniques grouping objects (or linked objects) Special cases of link-based classification/clustering – – – – Identifying link type Predicting link strength Link cardinality Record linkage Getoor et al (2002) – Two mechanisms to represent probabilistic distributions over link structures – Apply resulting model to predict link structure 12/02/06 IEEE ICDM 2006 65
Alias detection Alias detection (or identity resolution) – Online users assume multiple aliases (e.g. email addresses) – Problem is to map multiple aliases to same entity – Important but difficult problem, having legitimate as well as illegitimate applications Approaches can leverage information about communication in a social network to determine such aliases (Source: Malin, 2005) Hill (2003) – Propose a classifier approach based on relational networks Malin (2005) – Unsupervised learning approach Holzer et al (2005) – Overview of previous related research – A social network and graph ranking based unsupervised approach 12/02/06 IEEE ICDM 2006 66
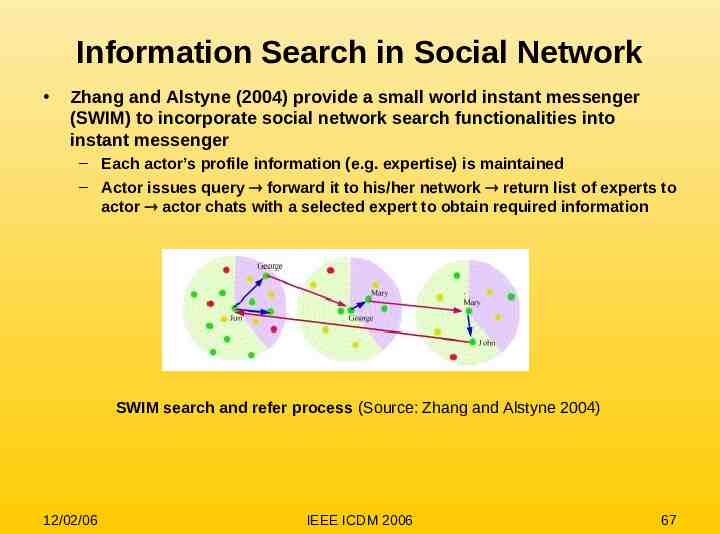
Information Search in Social Network Zhang and Alstyne (2004) provide a small world instant messenger (SWIM) to incorporate social network search functionalities into instant messenger – Each actor’s profile information (e.g. expertise) is maintained – Actor issues query forward it to his/her network return list of experts to actor actor chats with a selected expert to obtain required information SWIM search and refer process (Source: Zhang and Alstyne 2004) 12/02/06 IEEE ICDM 2006 67
Social networks for recommendation systems Initial approaches – – Kautz et al (1997) – – Analyzes the use of social networks in recommendation systems Highlights the need to balance between purely social match vs. expert match Aggregate social networks may not work best for individuals Palau et al, (2004) – Incorporate information of social networks into recommendation systems Enables more focused and effective search McDonald (2003) – – – Anonymous recommendations: treat individuals preferences as independent of each other Failure to account for influence of individual’s social network on his/her preferences Apply social network analysis techniques to represent & analyze collaboration in recommender systems Lam (2004) – – 12/02/06 SNACK - an automated collaborative system that incorporates social information for recommendations Mitigates the problem of cold-start, i.e. recommending to a user who not yet specified preferences IEEE ICDM 2006 68
Data Mining for SNA Case Study Socio-Cognitive Analysis from E-mail Logs
Example of E-mail Communication A sends an e-mail to B – With Cc to C – And Bcc to D C forwards this e-mail to E From analyzing the header, we can infer – A and D know that A, B, C and D know about this e-mail – B and C know that A, B and C know about this e-mail – C also knows that E knows about this e-mail – D also knows that B and C do not know that it knows about this e-mail; and that A knows this fact – E knows that A, B and C exchanged this e-mail; and that neither A nor B know that it knows about it – and so on and so forth 12/02/06 IEEE ICDM 2006 70
Modeling Pair-wise Communication Modeling pair-wise communication between actors – Consider the pair of actors (Ax,Ay) – Communication from Ax to Ay is modeled using the Bernoulli distribution L(x,y) [p,1-p] – Where, p (# of emails from Ax with Ay as recipient)/(total # of emails exchanged in the network) For N actors there are N(N-1) such pairs and therefore N(N-1) Bernoulli distributions Every email is a Bernoulli trial where success for L(x,y) is realized if Ax is the sender and Ay is a recipient Modeling an agent’s belief about global communication Based on its observations, each actor entertains certain beliefs about the communication strength between all actors in the network A belief about the communication expressed by L(x,y) is modeled as the Beta distribution, J(x,y), over the parameter of L(x,y) Thus, belief is a probability distribution over all possible communication strengths for a given ordered pair of actors (Ax,Ay) 12/02/06 IEEE ICDM 2006 71
Measures for Perceptual Closeness We analyze the following aspects – Closeness between an actor’s belief and reality, i.e. “true knowledge” of an actor – Closeness between the beliefs of two actors, i.e. the “agreement” between two actors We define two measures, r-closeness and a-closeness for measuring the closeness to reality and closeness in the belief states of two actors respectively 12/02/06 IEEE ICDM 2006 72
Perceptual Closeness Measures The a-closeness measure is defined as the level of agreement between two given actors Ax and Ay with belief states Bx,t and By,t respectively, at a given time t and is given by, The r-closeness measure is defined as the closeness of the given actor Ak’s belief state Bk,t to reality at a given time t and it is given by, Where BS,t is the belief state of the super-actor AS at time t 12/02/06 IEEE ICDM 2006 73
Interpretation of the measures The r-closeness measure – An actor who has accurate beliefs regarding only few communications is closer to reality than some other actor who has a relatively large number of less accurate beliefs – Thus, accuracy of knowledge is important The a-closeness measure between actor pairs – Consider three actors Ax, Ay and Az – Suppose we want to determine how divergent are Ay’s and Az’s belief states from that of Ax’s – If Ay and Ax have few beliefs in common, but low divergence for each of these few common beliefs, then their belief states may be closer than those of Az and Ax, who have a relatively larger number of common beliefs with greater divergence across them a-closeness measure can be used to construct an “agreement graph” (or a who agrees with whom graph) – Actors are represented as nodes and an edge exists between two actors only if the agreement or the a-closeness between them exceeds some threshold t 12/02/06 IEEE ICDM 2006 74
Testing ‘conventional wisdom’ using r-closeness Conventional wisdom 1: As an actor moves higher up the organizational hierarchy, it has a better perception of the social network – It was observed that majority of the top positions were occupied by employees Conventional wisdom 2: The more communication an actor observes, the better will be its perception of reality – Even though some actors observed a lot of communication, they were still ranked low in terms of r-closeness. – These actors focus on a certain subset of all communications and so their perceptions regarding the social network were skewed towards these “favored” communications – Executive management actors who were communicatively active exhibited this “skewed perception” behavior which explains why they were not ranked higher in the rcloseness measure rankings as expected in 1 12/02/06 IEEE ICDM 2006 75
Some Emerging Applications
Idea 1 - My Web: Me, My Interests and My People Key Idea: What does MyWeb represent? Approach: {tags} Tag Aware PageRank PageRank What does creator think about a page? What do I think about the page? What do others think about the page? P2 {tags} P1 What can be inferred? Who are the community of people who are “voted” as good resources on a topic? What are the community of pages which are “voted” as good resources on a topic? Who are people/pages authoritative on a topic. Key Benefits {tags} {tags} {tags} P3 {tags} {tags} Status and Future Work Improve Webpage ranking Current Ranking Schemes: Discovering communities of people and Webpages based on what users think Creator Based Ranking. Future Work: Discovering expert Webpages and people on given topics Personalized Web and Community Community Aware PageRank Use of User Votes to improve ranking Determining a most resourceful person. Excellent source for personalized ads. 12/02/06 IEEE ICDM 2006 77
Idea 2 - Yahoo! Answers: Identifying the Experts Key Idea: Approach: - Identifying the true experts among Yahoo Answers participants - Keep track of users who consistently provide good answers for particular topics - Provide incentives for experts to stay on Yahoo! Answers in order to improve service Question User 1 Answer 1 User 2 Answer 2 User n Answer n User Votes User x User y User z Key Benefits Status and Future Work - The study of trends among questions answers posted by the users esp. comparing behavior of the experts and non-experts - Develop a PageRank style scoring scheme for ranking experts for various topics - The above study as well as retaining the experts can help improve the service provided by Yahoo! Answers 12/02/06 - Develop efficient algorithms for the same - Do we penalize users for possible ‘bad’ answers? If so how do we identify bad answers? IEEE ICDM 2006 78
Idea 3 - Influence of Social Networks on Product Recommendations Key Idea: Approach: Social Network - Current recommendation models assume all users’ opinions to be independent, i.e. the i.i.d assumption - Can we make use of the social network data of actors to relax this i.i.d assumption Product Opinion A1 A2 . . . AN P1 P2 P3 PM A1 A2 . . . AN A1 A2 A3 AN Recommendation System Key Benefits Status (Research Issues) - Understanding the impact of social networks on market behavior - Statistical Techniques exist for relaxing the i.i.d assumption. Eg. Multilevel modeling and Random mixed effects models - Improved recommendation systems - Research effort needs to be directed towards extending or integrating the ideas presented in these techniques with existing recommendation systems - Alternatively, one can also work towards designing complex graphical models for the proposed problem 12/02/06 IEEE ICDM 2006 79
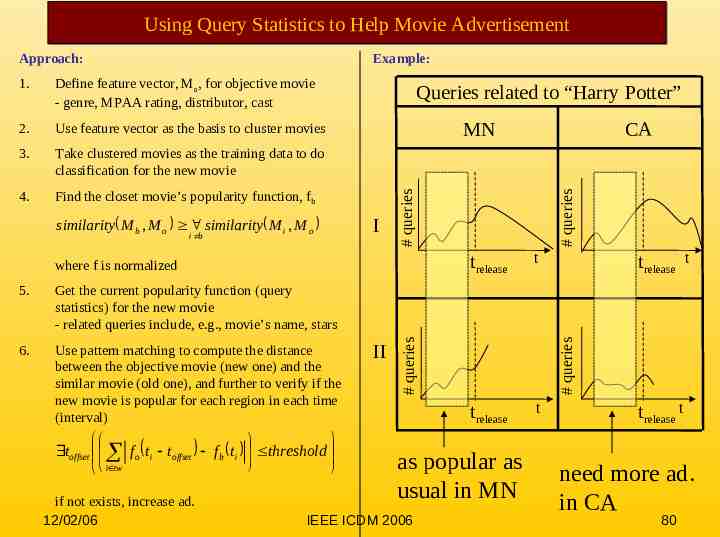
Using Query Statistics to Help Movie Advertisement Example: 2. Use feature vector as the basis to cluster movies 3. Take clustered movies as the training data to do classification for the new movie 4. Find the closet movie’s popularity function, fb similarity M b , M o similarity M i , M o i b Queries related to “Harry Potter” MN I Get the current popularity function (query statistics) for the new movie - related queries include, e.g., movie’s name, stars 6. Use pattern matching to compute the distance between the objective movie (new one) and the similar movie (old one), and further to verify if the new movie is popular for each region in each time (interval) toffset f o ti toffset f b ti threshold i tw if not exists, increase ad. 12/02/06 II trelease t trelease t # queries where f is normalized 5. CA # queries Define feature vector, Mo, for objective movie - genre, MPAA rating, distributor, cast as popular as usual in MN IEEE ICDM 2006 trelease t # queries 1. # queries Approach: trelease t need more ad. in CA 80
Conclusion Research in Social Network Analysis has significant history – Social sciences: Sociology, Psychology, Anthropology, Epidemiology, – Physical and mathematical sciences: Physics, Mathematics, Statistics, Late 1990s: computer networks provided a mechanism to study social networks at a granular level – Computer scientists joined the fray 2000 onwards: Explosion in infrastructure, tools, and applications to enable social networking, and capture data about the interactions – Opens up exciting areas of data mining research 12/02/06 IEEE ICDM 2006 81
References
References 1. L. Adamic, R.M.Lukose, A.R.Puniyani and B.A.Huberman. Search in power law networks. Phys. Rev. E 64, 046135(2001). 2. L. Adamic and E. Ader. Friends and Neighbors on the web. Social Netowrks, 25(3), pp 211-230, 2003. 3. Réka Albert; Albert-László Barabási, Topology of Evolving Networks: Local Events and Universality Physical Review Letters, Volume 85, Issue 24, December 11, 2000, pp.52345237 4. B.W.Bader, R. Harshman and T. G. Kolda. Temporal Analysis of social networks using three way DEDICOM. (Technical Report), SAND2006-2161, Sandia National Laboratories, 2006. 5. S.P. Borgatti, and P. Foster., P. 2003. The network paradigm in organizational research: A review and typology. Journal of Management. 29(6): 991-1013 6. U. Brandes. A Faster Algorithm for Betweenness Centrality. Journal of Mathematical Sociology 25(2):163-177, 2001. 7. G.G. Van De Bunt, M.A.J. Van Duijn, T.A.B Snijders Friendship Networks Through Time: An Actor-Oriented Dynamic Statistical Network Organization Theory, Volume 5, Number 2, July 1999, pp. 167-192(26). 8. T. Carpenter, G. Karakostas and D. Shallcross. Practical issues and algorithms for analyzing terrorist networks. Invited paper at WMC 2002. 9. Cassi, Lorenzo. Information, Knowledge and Social Networks: Is a New Buzzword coming up? DRUID Academy Winter 2003 PhD Conference. 10. A. Clauset, M.E.J.Newman and C.Moore. Finding community structure in very large networks. Phys. Rev. E 70, 0066111(2004). 11. A. Culotta, R.Bekkerman and A.McCallum. Extracting social networks and contact information from email and the web. Conference on Email and Spam (CEAS), 2004. 12/02/06 IEEE ICDM 2006 83
References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. J. Diesner and K.M. Carley. Exploration of Communication Networks from the Enron Email Corpus. Workshop on Link Analysis, Counterterrorism and Security , In SIAM International Conference on Data Mining, 2005. Li Ding, Tim Finin and Anupam Joshi. Analyzing Social Networks on the Semantic Web. IEEE Intelligent Systems, 2005. Pedro Domingos and Matthew Richardson. Mining the Network Value of Customers. Proceedings of the Seventh International Conference on Knowledge Discovery and Data Mining (pp. 57-66), 2001. San Francisco, CA: ACM Press. Pedro Domingos. Mining Social Networks for Viral Marketing (short paper). IEEE Intelligent Systems, 20(1), 80-82, 2005. C. Faloutsos, K.S. McCurley and A. Tomkins. Fast discovery of connection subgraphs. ACM SIGKDD 2004: 118-127. L.C. Freeman, Visualizing Social Networks. Journal of Social Structure, 2000. L. Getoor, N. Friedman, D. Koller and B. Taskar. Learning Probabilistic Models of Link Structure. Journal of Machine Learning Research, 2002. L. Getoor. Link mining: a new data mining challenge. SIGKDD Explorations, 5(1):84– 89, 2003. M.Girvan and M.E.J.Newman. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 99, 7821-7826, 2002. J. Golbeck, B. Parsia, J. Hendler. Trust Networks on the Semantic Web. In Proceedings of Cooperative Intelligent Agents 2003, Helsinki, Finland, August 2729. M Granovetter. Threshold models of collective behaviour. American Journal ofSociology, 83 (6): 1420-1443, 1978. R. Guha, R. Kumar, P. Raghavan and A. Tomkins. Propagation of Trust and Distrust. In Proceedings of 13th International World Wide Web Conference, 2004. 12/02/06 IEEE ICDM 2006 84
References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. M. Harada, S. Sato and K. Kazama. Finding authoritative people from the web. In proceedings of the 4th ACM/IEEE-CS joint conference on digital libraries. pp 306-313, 2004. M.A.Hasan, V.Chaoji, S.Salem and M.Zaki. Link prediction using supervised learning. In Workshop on Link Analysis, Counterterrorism and Security at SIAM International Conference on Data Mining, 2006. Heer, J. Exploring Enron: Visual Data Mining. http://www.cs.berkeley.edu/ jheer/anlp/final/, 2005. S. Hill. Social network relational vectors for anonymous identity matching. In Proceedings of the IJCAI Workshop on Learning Statistical Models from Relational Data, Acapulco,Mexico, 2003. P. D. Hoff, A. E. Raftery, and M. S. Handcock. Latent space approaches to social network analysis. Journal of the American Statistical Association, 97:1090--1098, 2002. Holzer R, Malin B, and Sweeney L.Email Alias Detection Using Network Analysis. In Proceedings of the ACM SIGKDD Workshop on Link Discovery: Issues, Approaches, and Applications. Chicago, IL. August 2005. T.Hope, T. Nishimura and H.Takeda. An integrated method for social network extraction. In WWW'06: Proceedings of 15th international conference on World Wide Web, pp 845-846, New York, NY, USA, 2006, ACM Press. Matthew O. Jackson, 2003. "A survey of models of network formation: Stability and efficiency," Working Papers 1161, California Institute of Technology, Division of the Humanities and Social Sciences. Kautz, H., Selman, B., and Shah, M. 1997. Referral Web: combining social networks and collaborative filtering. Commun. ACM 40, 3 (Mar. 1997), 63-65. Jon M. Kleinberg. "Authoritative Sources in a Hyperlinked Environment" in Proceedings of ACM-SIAM Symposium on Discrete Algorithms, 668-677, January 1998. 12/02/06 IEEE ICDM 2006 85
References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. Jon Kleinberg. The small-world phenomenon: An algorithmic perspective. Cornell Computer Science Technical Report 99-1776, October 1999 J.Kleinberg. Hubs, Authorities and Communities. ACM Computing Surveys, 31(4), December 1999. Jon Kleinberg. Small-World Phenomena and the Dynamics of Information. Advances in Neural Information Processing Systems (NIPS) 14, 2001. J. Kleinberg and P. Raghavan. Query Incentive Networks. In FOCS '05: 46th Annual IEEE Symposium on Foundations of Computer Science. Pittsburgh, PA, 132--141, 2005. David Krackhardt and Jeffrey R. Hanson. Informal Networks: The Company Behind the Chart. Harvard Business Review, 1993. Krebs, V. E. Mapping networks of terrorist cells. Connections 24, 3 (2001), 43–52. Lam, C. 2004. SNACK: incorporating social network information in automated collaborative filtering. In Proceedings of the 5th ACM Conference on Electronic Commerce (New York, NY, USA, May 17 - 20, 2004). EC '04. H.Lauw, E-P.Lim, T.T.Tan and H.H. Pang. Mining social network from spatio-temporal events. In Workshop on Link Analysis, Counterterrorism and Security at SIAM International Conference on Data Mining, 2005. Jure Leskovec, Lada Adamic, and Bernardo Huberman. The Dynamics of Viral Marketing. EC'06. J.Leskovic and C.Faloutsos. Sampling from large graphs. ACM SIGKDD 2006: 631-636. D. Liben-Nowell and J.Kleinberg. The link prediction problem for social networks. In CIKM'03: Proceedings of the 14th ACM international conference on Information and Knowledge Management, pp 556-559. ACM Press, 2003. Hugo Liu and Pattie Maes. InterestMap: Harvesting Social Network Profiles for Recommendations. Workshop: Beyond Personalization, IUI'05, 2005. 12/02/06 IEEE ICDM 2006 86
References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. Lonier, T. & Matthews, C., 2004. "Measuring the Impact of Social Networks on Entrepreneurial Success: The Master Mind Principle." Presented at the 2004 Babson Kauffman Entrepreneurship Research Conference, Glasgow, Scotland, June. M. Makrehchi and M.S. Kamel. Building social networks from web documents: A text mining approach. In the 2nd LORNET Scientific Conference, 2005. B. Malin. Unsupervised name disambiguation via social network similarity. In Proc. SIAM Wksp on Link Analysis, Counterterrorism, and Security, pages 93–102, Newport Beach, CA, 2005. P. Marsden 1990. “Network Data and Measurement.” Annual Review of Sociology, Volume 16 (1990), pp. 435-463. McDonald, D. W. 2003. Recommending collaboration with social networks: a comparative evaluation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Ft. Lauderdale, Florida, USA, April 05 - 10, 2003). CHI '03. Peter Mika. Flink: Using Semantic Web Technology for the Presentation and Analysis of Online Social Networks. Journal of Web Semantics 3(2), Elsevier, 2005. S. Milgram, The small world problem,'' Psychology Today 1, 61 (1967). Martina Morris. Network Epidemiology: A Handbook for Survey Design and Data Collection (2004). London: Oxford University Press. M. E. J. Newman. Who is the best connected scientist? A study of scientific coauthorship networks. Phys.Rev. E64 (2001) 016131. M. E. J. Newman. The structure and function of complex networks. SIAM Review, 45(2):167-- 256, 2003. M.E.J.Newman. Fast algorithm for detecting community structure in networks. Phys. Rev. E 69, 066133, 2004. 12/02/06 IEEE ICDM 2006 87
References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. M.E.J.Newman. Modularity and community structure in networks. Proc. of Natl Acad. of Sci. USA 103, 8577-8582, 2006. J. Palau, M. Montaner, and B. Lopez. Collaboration analysis in recommender systems using social networks. In Eighth Intl. Workshop on Cooperative Info. Agents (CIA'04), 2004. Paolillo, J.C. and Wright, E. Social Network Analysis on the Semantic Web: Techniques and challenges for Visualizing FOAF. Visualizing the Semantic Web (Draft Chapter), in press., Jialun Qin, Jennifer J. Xu, Daning Hu, Marc Sageman and Hsinchun Chen: Analyzing Terrorist Networks: A Case Study of the Global Salafi Jihad Network. Intelligence and Security Informatics, 2005. Matthew Richardson and Pedro Domingos. 2002. Mining knowledge-sharing sites for viral marketing. In Proceedings of the Eighth ACM SIGKDD international Conference on Knowledge Discovery and Data Mining (Edmonton, Alberta, Canada, July 23 - 26, 2002). KDD '02. ACM Press, New York, NY, 61-70. P. Sarkar and A. Moore. Dynamic social network analysis using latent space models. ACM SIGKDD Explorations Newsletter, 7(2), pp 31-40, 2005. Schelling, T (1978). Micromotives and macrobehavior. New York: W. W. Norton. Shetty, J., & Adibi, J. The Enron email dataset database schema and brief statistical report (Technical Report). Information Sciences Institute, 2004. J.Shetty and J.Adibi. Discovering important nodes through graph entropy the case of Enron email database. In Proceedings of 3rd international Workshop on Link Discovery in ACM SIGKDD'05, pp 74-81, 2005. E. Spertus, Mehran Sahami, Orkut Buyukkokten: Evaluating similarity measures: a large-scale study in the orkut social network. KDD 2005: 678-684 12/02/06 IEEE ICDM 2006 88
References 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. M. Steyvers, P. Smyth, M. Rosen-Zvi, T. Griffiths. Probabilistic author-topic models for information discovery. In proceedings of 10th ACM SIGKDD, pp 306-315, Seattle, WA, USA, 2004. J. Travers and S. Milgram, An experimental study of the small world problem,'' Sociometry 32, 425 (1969). J.Tyler, D. Wilkinson and B. Huberman. Email as spectroscopy: automated discovery of community structure within organizations. Communities and technologies, pp 81-69, 2003. S. Wasserman, & K. Faust, Social Network Analysis: Methods and Applications. New York and Cambridge, ENG: Cambridge University Press (1994). D. J. Watts, S. H. Strogatz, "Collective Dynamics of Small-World Networks." Nature 393, 440-442, 1998. D. Watts, Network dynamics and the small world phenomenon. Americal Journal of Sociology 105 (2), 493-527. 1999 D. Watts. Small Worlds: The Dynamics of Networks between Order and Randomness, 2003. A.Y.Wu, M.Garland and J.Han. Mining scale free networks using geodesic clustering. ACM SIGKDD'04, pp 719-724, New York, NY, USA, 2004, ACM Press. Xu, J. and Chen, H. 2005. Criminal network analysis and visualization. Commun. ACM 48, 6 (Jun. 2005), 100-107. Wan-Shiou Yang; Jia-Ben Dia; Hung-Chi Cheng; Hsing-Tzu Lin, "Mining Social Networks for Targeted Advertising," System Sciences, 2006. HICSS '06. Proceedings of the 39th Annual Hawaii International Conference on , vol.6, no.pp. 137a- 137a, 04-07 Jan. 2006. H Peyton Young, 2000. "The Diffusion of Innovations in Social Networks," Economics Working Paper Archive 437, The Johns Hopkins University,Department of Economics. 12/02/06 IEEE ICDM 2006 89
References 1. 2. 3. 4. 5. 6. 7. 8. B. Yu and M. P. Singh. Searching social networks. In Proceedings of the 2nd International Joint Conference on Autonomous Agents and MultiAgent Systems (AAMAS). ACM Press, July 2003. Zhang, J. and Van Alstyne, M. 2004. SWIM: fostering social network based information search. In CHI '04 Extended Abstracts on Human Factors in Computing Systems (Vienna, Austria, April 24 - 29, 2004). CHI '04. ACM Press, New York, NY, 1568-1568. D. Zhou, E.Manavoglu, J.Li, C.L.Giles and H.Zha. Probabilistic models for discovering e-communities. In WWW'06: Proceedings of 15th international conference on World Wide Web, pp 173-182, New York, NY, USA, 2006, ACM Press. N. Contractor. Multi-theoretical multilevel MTML models to study the emergence of networks, NetSci conference, 2006. Linton C. Freeman. See you in the Funny Papers: Cartoons and Social Networks. CONNECTIONS, 23(1): 32-42, 2000. Y.Matsao, J.Mori, M. Hamasaki, K. Ishida, T.Nishimura, H.Takeda, K.Hasida and M. Ishizuka. Polyphnet: an advanced social network extraction system from the web. In WWW'06: Proceedings of 15th international conference on World Wide Web, pp 397406, New York, NY, USA, 2006, ACM Press. N. Matsumura, D.E.Goldberg and X.Llor. Mining directed social network from message board. In WWW'05: Proceedings of 14th international conference on World Wide Web, pp 1092-1093, New York, NY, USA, 2005, ACM Press. Liebowitz, 2004 12/02/06 IEEE ICDM 2006 90






