Data Integration and Large-scale Analysis (DIA) 12 Distributed
























33 Slides6.77 MB
Data Integration and Large-scale Analysis (DIA) 12 Distributed Stream Processing Prof. Dr. Matthias Boehm Technische Universität Berlin Berlin Institute for the Foundations of Learning and Data Big Data Engineering (DAMS Lab) Last update: Jan 25, 2024
Announcements / Administrative Items #1 Video Recording Hybrid lectures: in-person H 0107, zoom live streaming, video recording https://tu-berlin.zoom.us/j/9529634787?pwd R1ZsN1M3SC9BOU1OcFdmem9zT202UT09 #2 Exam Registration Time slots: Feb 08, 4pm or Feb 15, 4pm (start 4.15pm, end 5.45pm, 48 seats per exam) Sign up for exam via ISIS (once you submitted the project/exercise), opens Jan 18 [If more capacity needed, additional slots Feb 08, 6pm and Feb 15, 6pm] #3 Exam Preparation Walk-through previous exam at end of last lecture Feb 01 Additional office hour: Feb 02, 4pm-5.30pm (in-person TEL 815, or virtually via zoom) 2 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing Feb 08: 33/48 Feb 15: 30/48
Announcements / Administrative Items, cont. #4 Elections 3 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Course Outline Part B: Large-Scale Data Management and Analysis 12 Distributed Stream Processing Compute/ Storage 13 Distributed Machine Learning Systems 11 Distributed Data-Parallel Computation 10 Distributed Data Storage 09 Cloud Resource Management and Scheduling Infra 08 Cloud Computing Fundamentals 4 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Agenda Data Stream Processing Distributed Stream Processing Data Stream Mining 5 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Data Stream Processing 6 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
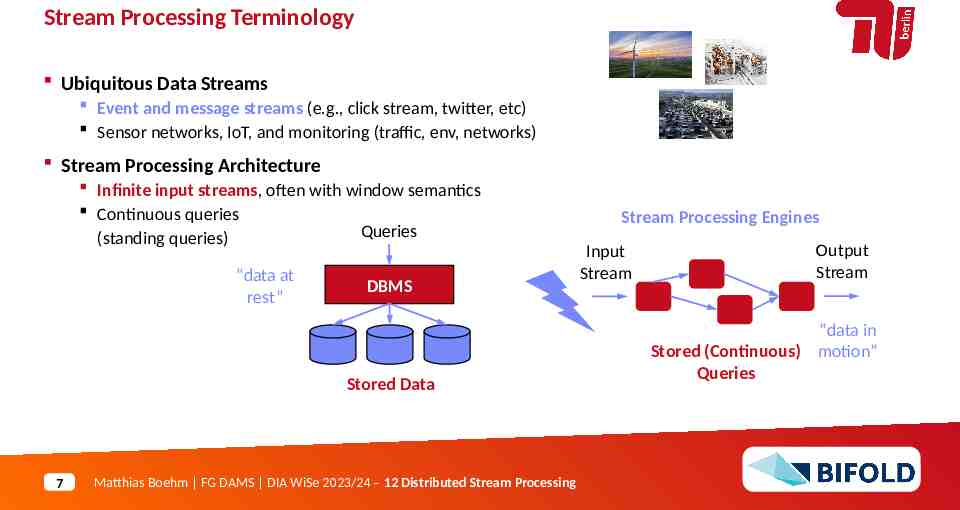
Stream Processing Terminology Ubiquitous Data Streams Event and message streams (e.g., click stream, twitter, etc) Sensor networks, IoT, and monitoring (traffic, env, networks) Stream Processing Architecture Infinite input streams, often with window semantics Continuous queries Queries (standing queries) “data at rest” DBMS Stored Data 7 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing Stream Processing Engines Input Stream Output Stream “data in Stored (Continuous) motion” Queries
Stream Processing Terminology, cont. Use Cases Monitoring and alerting (notifications on events / patterns) Real-time reporting (aggregate statistics for dashboards) Real-time ETL and event-driven data updates Real-time decision making (fraud detection) Data stream mining (summary statistics w/ limited memory) Data Stream Unbounded stream of data tuples S (s1, s2, ) with si (ti, di) See DM 10 NoSQL Systems (time series) Real-time Latency Requirements Real-time: guaranteed task completion by a given deadline (30 fps) Near Real-time: few milliseconds to seconds In practice, used with much weaker meaning 8 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing Continuously active
History of Stream Processing Systems 2000s Data stream management systems (DSMS, mostly academic prototypes): STREAM (Stanford’01), Aurora (Brown/MIT/Brandeis’02) Borealis (‘05), NiagaraCQ (Wisconsin), TelegraphCQ (Berkeley’03), and many others but mostly unsuccessful in industry/practice Message-oriented middleware and Enterprise Application Integration (EAI): IBM Message Broker, SAP eXchange Infra., MS Biztalk Server, TransConnect 2010s Distributed stream processing engines, and “unified” batch/stream processing Proprietary systems: Google Cloud Dataflow, MS StreamInsight / Azure Stream Analytics, IBM InfoSphere Streams / Streaming Analytics, AWS Kinesis Open-source systems: Apache Spark Streaming (Databricks), Apache Flink (Data Artisans), Apache Kafka (Confluent), Apache Storm 9 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
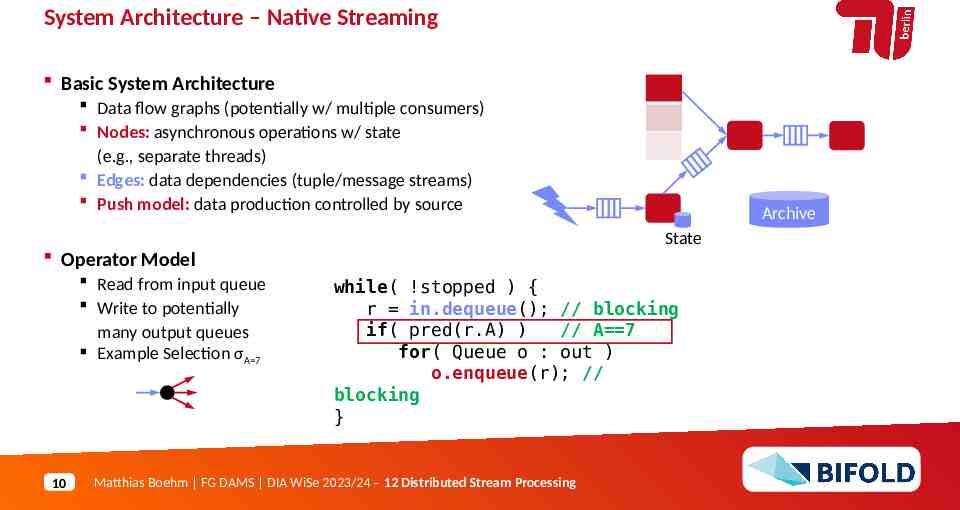
System Architecture – Native Streaming Basic System Architecture Data flow graphs (potentially w/ multiple consumers) Nodes: asynchronous operations w/ state (e.g., separate threads) Edges: data dependencies (tuple/message streams) Push model: data production controlled by source State Operator Model Read from input queue Write to potentially many output queues Example Selection σA 7 10 Archive while( !stopped ) { r in.dequeue(); // blocking if( pred(r.A) ) // A 7 for( Queue o : out ) o.enqueue(r); // blocking } Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
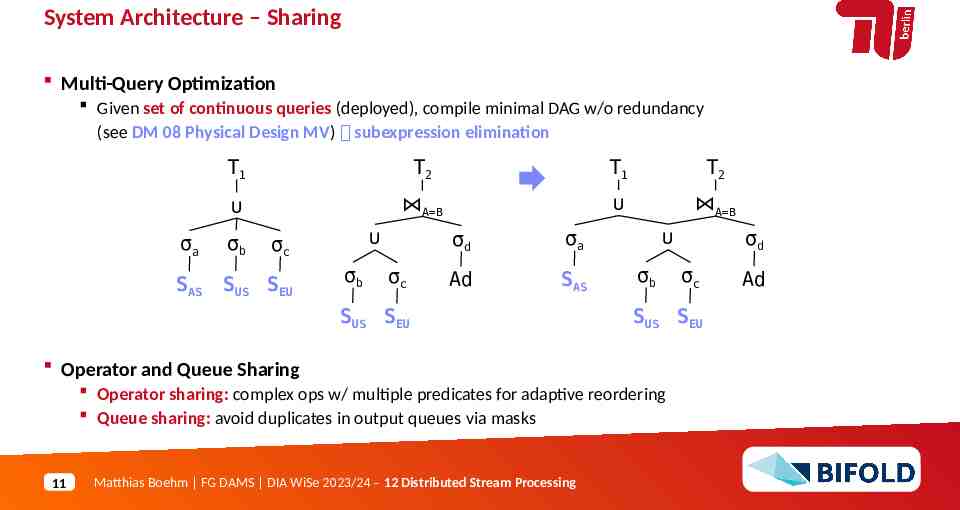
System Architecture – Sharing Multi-Query Optimization Given set of continuous queries (deployed), compile minimal DAG w/o redundancy (see DM 08 Physical Design MV) subexpression elimination T1 T2 T1 T2 A B A B σa σb SAS SUS SEU σc σb σc σd σa Ad SAS SUS SEU σb Operator sharing: complex ops w/ multiple predicates for adaptive reordering Queue sharing: avoid duplicates in output queues via masks Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing σc SUS SEU Operator and Queue Sharing 11 σd Ad
System Architecture – Handling Overload #1 Back Pressure Graceful handling of overload w/o data loss Slow down sources E.g., blocking queues A B C 3ms 9ms 2ms Self-adjusting operator scheduling Pipeline runs at rate of slowest op #2 Load Shedding #1 Random-sampling-based load shedding #2 Relevance-based load shedding #3 Summary-based load shedding (synopses) Given SLA, select queries and shedding placement that minimize error and satisfy constraints #3 Distributed Stream Processing (see next part) Data flow partitioning (distribute the query) Key range partitioning (distribute the data stream) 12 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing [Nesime Tatbul et al: Load Shedding in a Data Stream Manager. VLDB 2003]
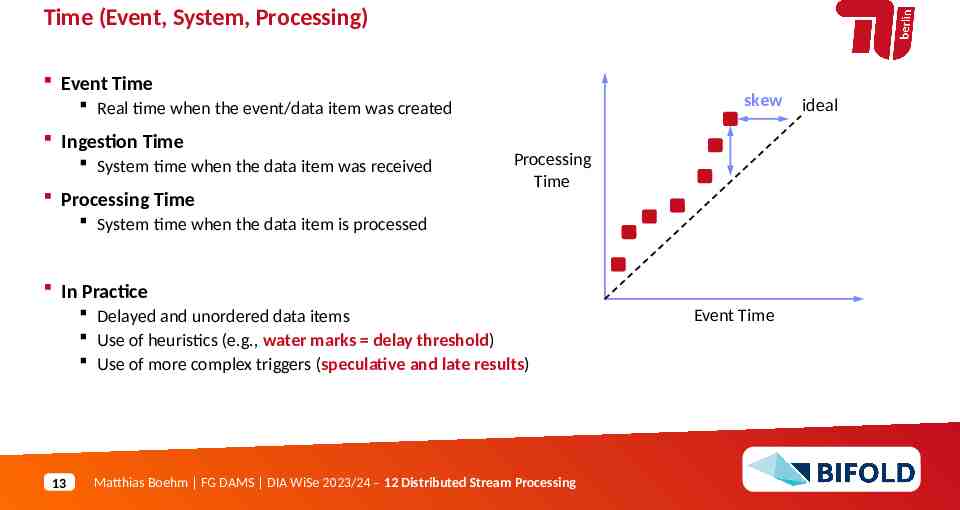
Time (Event, System, Processing) Event Time skew Real time when the event/data item was created Ingestion Time System time when the data item was received Processing Time Processing Time System time when the data item is processed In Practice Delayed and unordered data items Use of heuristics (e.g., water marks delay threshold) Use of more complex triggers (speculative and late results) 13 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing Event Time ideal
Durability and Delivery Guarantees #1 At Most Once “Send and forget”, ensure data is never counted twice Might cause data loss on failures 03 Message-oriented Middleware, EAI, and Replication #2 At Least Once “Store and forward” or acknowledgements from receiver, replay stream from a checkpoint on failures Might create incorrect state (processed multiple times) #3 Exactly Once “Store and forward” w/ guarantees regarding state updates and sent msgs Often via dedicated transaction mechanisms 14 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Window Semantics Windowing Approach Many operations like joins/aggregation undefined over unbounded streams Compute operations over windows of (a) time or (b) elements counts size 2min #1 Tumbling Window Every data item is only part of a single window Aka Jumping window 12:05 12:07 12:09 size 2min, step 1min #2 Sliding Window Time- or tuple-based sliding windows Insert new and expire old data items 12:05 15 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing 12:07 12:09
Stream Joins Basic Stream Join Tumbling window: use classic join methods Sliding window (symmetric for both R and S) Applies to arbitrary join pred See DM 08 Query Processing (NLJ) For each new r in R: 1. Scan window of stream S to find match tuples 2. Insert new r into window of stream R 3. Invalidate expired Excursus: How Soccer Players Would do Stream Joins tuples [Jens Teubner, René Müller: How players would Handshake-join w/ 2-phase forwarding in window ofsoccer stream R do stream joins. SIGMOD 2011] 16 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
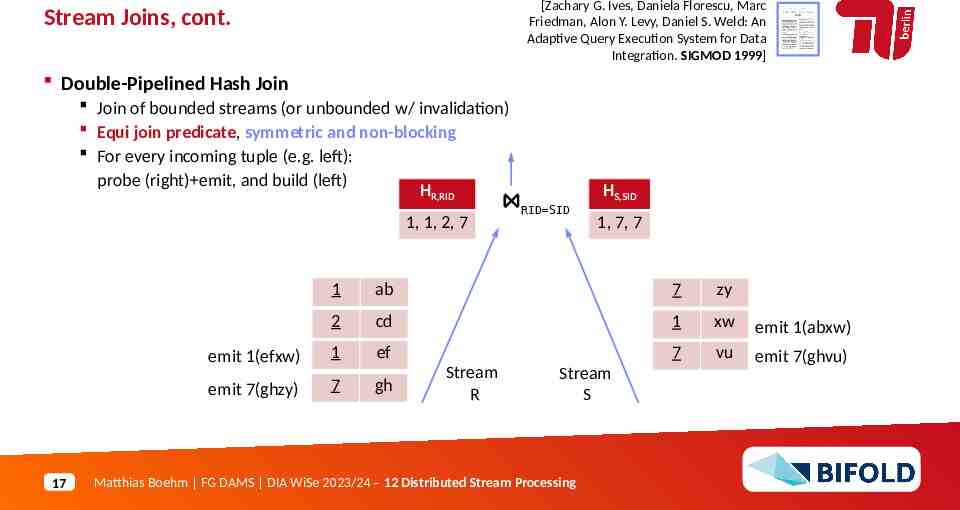
[Zachary G. Ives, Daniela Florescu, Marc Friedman, Alon Y. Levy, Daniel S. Weld: An Adaptive Query Execution System for Data Integration. SIGMOD 1999] Stream Joins, cont. Double-Pipelined Hash Join Join of bounded streams (or unbounded w/ invalidation) Equi join predicate, symmetric and non-blocking For every incoming tuple (e.g. left): probe (right) emit, and build (left) HHR,RID R,RID 1, 1,1,2, 1,272 17 HS,SID RID SID 1,1,77,77 1 ab 7 zy 2 cd 1 xw emit 1(abxw) emit 1(efxw) 1 ef 7 vu emit 7(ghvu) emit 7(ghzy) 7 gh Stream R Stream S Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Distributed Stream Processing 18 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Query-Aware Stream Partitioning [Theodore Johnson, S. Muthu Muthukrishnan, Vladislav Shkapenyuk, Oliver Spatscheck: Query-aware partitioning for monitoring massive network data streams. SIGMOD 2008] Example Use Case AT&T network monitoring with Gigascope (e.g., OC768 network) 2x40 Gbit/s traffic 112M packets/s 26 cycles/tuple on 3Ghz CPU Complex query sets (apps w/ 50 queries) and massive data rates Baseline Query Execution Plan Self join tb tb 1 High-level aggregation γ2 Low-level aggregation γ1 Low-level filtering σ TCP 19 Query flow pairs: SELECT S1.tb, S1.srcIP, S1.max, S2.max FROM heavy flows S1, heavy flows S2 WHERE S1.srcIP S2.srcIP and S1.tb S2.tb 1 Query heavy flows: SELECT tb,srcIP,max(cnt) as max cnt FROM flows GROUP BY tb, srcIP Query flows: SELECT tb, srcIP, destIP, COUNT(*) AS cnt FROM TCP WHERE . GROUP BY time/60 AS tb,srcIP,destIP Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
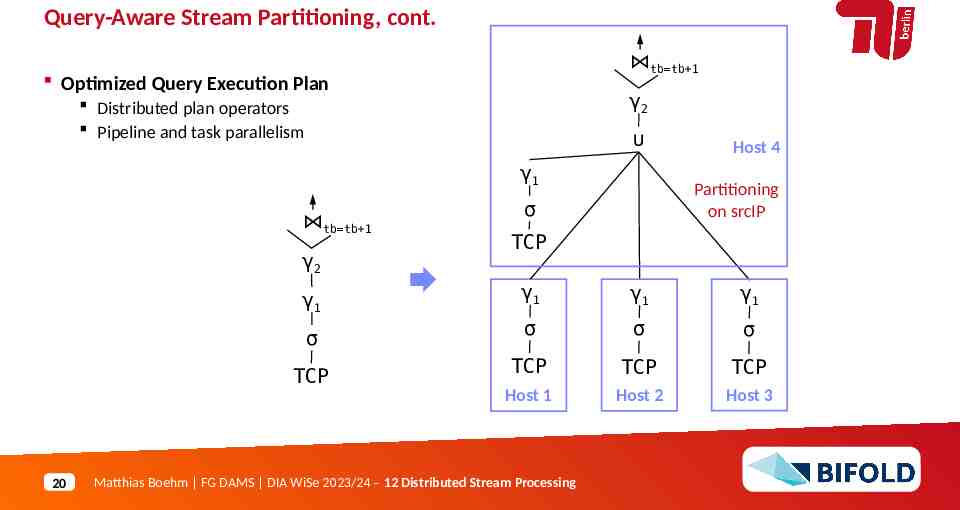
Query-Aware Stream Partitioning, cont. tb tb 1 Optimized Query Execution Plan γ2 Distributed plan operators Pipeline and task parallelism γ1 tb tb 1 γ2 γ1 σ TCP 20 Host 4 Partitioning on srcIP σ TCP γ1 γ1 γ1 σ σ σ TCP TCP TCP Host 1 Host 2 Host 3 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Stream Group Partitioning 11 Distributed, Data-Parallel Computation Large-Scale Stream Processing Limited pipeline parallelism and task parallelism (independent subqueries) Combine with data-parallelism over stream groups #1 Shuffle Grouping Tuples are randomly distributed across consumer tasks Good load balance #2 Fields Grouping Tuples partitioned by grouping attributes Guarantees order within keys, but load imbalance if skew #3 Partial Key Grouping Apply “power of two choices” to streaming Key splitting: select among 2 candidates per key (associative agg) #4 Others: Global, None, Direct, Local 21 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing [Md Anis Uddin Nasir et al: The power of both choices: Practical load balancing for distributed stream processing engines. ICDE 2015]
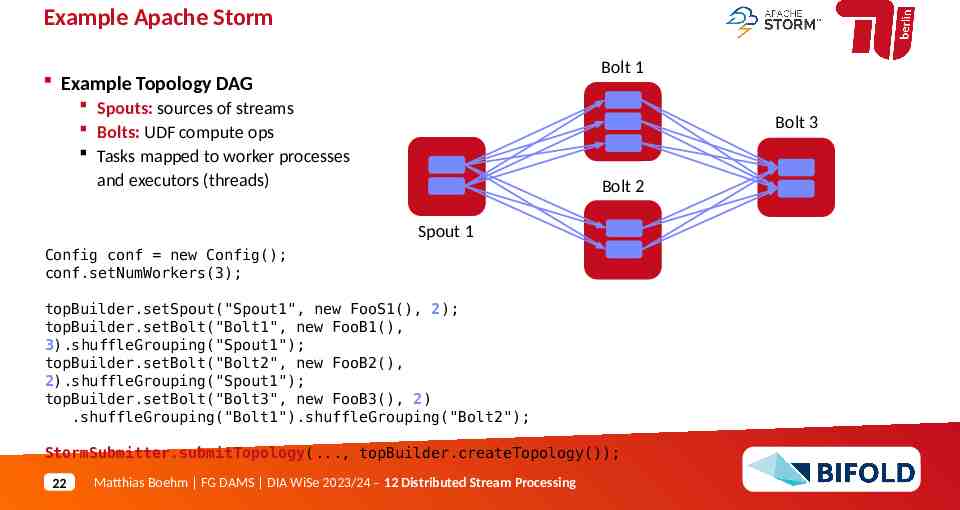
Example Apache Storm Bolt 1 Example Topology DAG Spouts: sources of streams Bolts: UDF compute ops Tasks mapped to worker processes and executors (threads) Bolt 3 Bolt 2 Spout 1 Config conf new Config(); conf.setNumWorkers(3); topBuilder.setSpout("Spout1", new FooS1(), 2); topBuilder.setBolt("Bolt1", new FooB1(), 3).shuffleGrouping("Spout1"); topBuilder.setBolt("Bolt2", new FooB2(), 2).shuffleGrouping("Spout1"); topBuilder.setBolt("Bolt3", new FooB3(), 2) .shuffleGrouping("Bolt1").shuffleGrouping("Bolt2"); StormSubmitter.submitTopology(., topBuilder.createTopology()); 22 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Example Twitter Heron Motivation Heavy use of Apache Storm at Twitter Issues: debugging, performance, shared cluster resources, back pressure mechanism [Credit: Karthik Ramasamy] Data per day Cluster Size Twitter Heron API-compatible distributed streaming engine De-facto streaming engine at Twitter since 2014 Dhalion (Heron Extension) Automatically reconfigure Heron topologies to meet throughput SLO Now back pressure implemented in Apache Storm 2.0 (May 2019) 23 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing # of Msgs # of Topologies per day [Sanjeev Kulkarni et al: Twitter Heron: Stream Processing at Scale. SIGMOD 2015] [Avrilia Floratou et al: Dhalion: SelfRegulating Stream Processing in Heron. PVLDB 2017]
Discretized Stream (Batch) Computation Motivation Fault tolerance (low overhead, fast recovery) Combination w/ distributed batch analytics [Matei Zaharia et al: Discretized streams: fault-tolerant streaming computation at scale. SOSP 2013] Discretized Streams (DStream) Batching of input tuples (100ms – 1s) based on ingest time Periodically run distributed jobs of stateless, deterministic tasks DStreams State of all tasks materialized as RDDs, recovery via lineage Batch Computation Sequence of immutable, partitioned datasets (RDDs) Criticism: High latency, required for batching 24 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Unified Batch/Streaming Engines Apache Spark Streaming (Databricks) Micro-batch computation with exactly-once guarantee Back-pressure and water mark mechanisms Structured streaming via SQL (2.0), continuous streaming (2.3) Apache Flink (Data Artisans, now Alibaba) Tuple-at-a-time with exactly-once guarantee Back-pressure and water mark mechanisms Batch processing viewed as special case of streaming Google Cloud Dataflow Tuple-at-a-time with exactly-once guarantee MR FlumeJava MillWheel Dataflow (managed batch/stream service) Apache Beam (API SDK from Dataflow) Abstraction for Spark, Flink, Dataflow w/ common API, etc Individual runners for the different runtime frameworks 25 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing [https://flink.apache.org/news/ 2019/02/13/unified-batch-strea mingblink.html] [T. Akidau et al.: The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. PVLDB 2015]
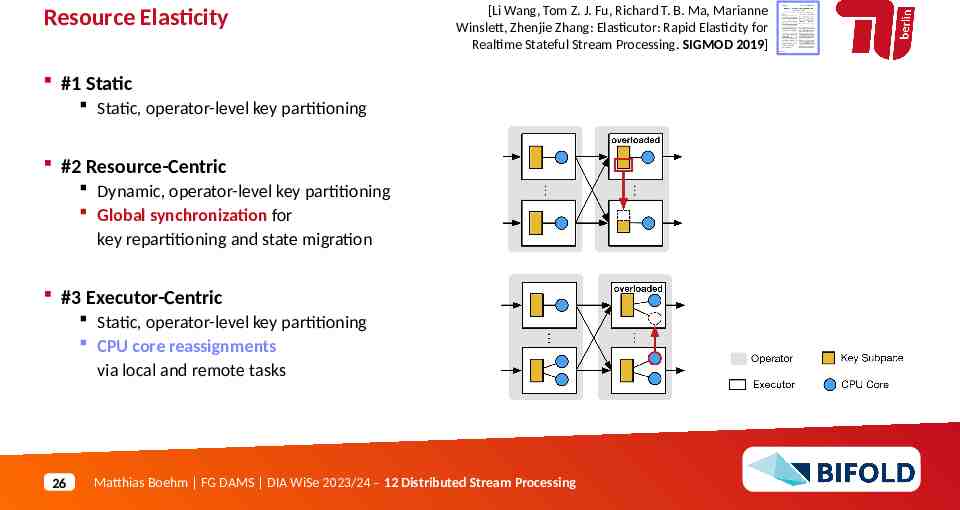
Resource Elasticity [Li Wang, Tom Z. J. Fu, Richard T. B. Ma, Marianne Winslett, Zhenjie Zhang: Elasticutor: Rapid Elasticity for Realtime Stateful Stream Processing. SIGMOD 2019] #1 Static Static, operator-level key partitioning #2 Resource-Centric Dynamic, operator-level key partitioning Global synchronization for key repartitioning and state migration #3 Executor-Centric Static, operator-level key partitioning CPU core reassignments via local and remote tasks 26 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Data Stream Mining Selected Example Algorithms 27 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Overview Stream Mining Streaming Analysis Model Independent of actual storage model and processing system Unbounded stream of data item S (s1, s2, ) Evaluate function f(S) as aggregate over stream or window of stream Standing vs ad-hoc queries Recap: Classification of Aggregates Additive aggregation functions (SUM, COUNT) Semi-additive aggregation functions (MIN, MAX) Additively computable aggregation functions (AVG, STDDEV, VAR) Aggregation functions (MEDIAN, QUANTILES) approximations Selected Algorithms Higher-Order Statistics (e.g., STDDEV) Approximate # Distinct Items (e.g., KMV, HyperLogLog) Approximate Heavy Hitters (e.g. CountMin-Sketch) 28 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing 02 Data Warehousing, ETL, and SQL/OLAP
Higher-Order Statistics Overview Order Statistics Many order statistics computable via pth central moment Examples: Variance , skewness, kurtosis 𝑛 𝑚𝑝 2 𝜎 Incremental Computation of Variance #1 Default 2-pass algorithm (mean, and squared diffs) #2 Textbook 1-pass algorithm (incrementally maintainable) numerically instable #3 Incremental update rules for mp with Kahan addition (variance since 1979) [Yuanyuan Tian, Shirish Tatikonda, Berthold Reinwald: Scalable and Numerically Stable Descriptive Statistics in SystemML. ICDE 2012] 29 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing 1 𝑝 𝑥 𝑥 ( ) 𝑖 𝑛 𝑖 1 𝑛 𝑛 𝑚 𝑛 1 2 1 1 2 𝑥 𝑛 𝑖 1 𝑖 𝑛2 2 𝑛 ( ) 𝑖 1 𝑥𝑖 11 Distributed, Data-Parallel Computation
Number of Distinct Items [Kevin S. Beyer, Peter J. Haas, Berthold Reinwald, Yannis Sismanis, Rainer Gemulla: On synopses for distinct-value estimation under multiset operations. SIGMOD 2007] Problem Estimate # distinct items in a dataset / data stream w/ limited memory Support for set operations (union, intersect, difference) Duplicates yield same hash! K-Minimum Values (KMV) Hash values to Domain to avoid collisions space Store k minimum hash values (e.g., via priority queue) in normalized form Basic estimator: Unbiased estimator: 30 0 U(k 4) 0.24 1 𝐵𝐸 𝐷𝑘 𝑘 / 𝑈 ( 𝑘) Example: 16.67 vs 12.5 𝑈𝐵 𝐷𝑘 (𝑘 1)/ 𝑈 ( 𝑘) Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Number of Distinct Items, cont. 11 Distributed, Data-Parallel Computation KMV Set Operations Union and intersection directly on partition synopses Difference via Augmented KMV (AKMV) that include counters of multiplicities of k-minimum values HyperLogLog Hash values and maintain maximum # of leading zeros p Stochastic averaging over m sub-streams (p maintain in registers M) HyperLogLog 31 0 1 [P. Flajolet, Éric Fusy, O. Gandouet, and F. Meunier: Hyperloglog: The analysis of a near-optimal cardinality estimation algorithm. AOFA 2007] [Stefan Heule, Marc Nunkesser, Alexander Hall: HyperLogLog in practice: algorithmic engineering of a state of the art cardinality estimation algorithm. EDBT 2013] Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing
Stream Summarization [Graham Cormode, S. Muthukrishnan: An Improved Data Stream Summary: The Count-Min Sketch and Its Applications. LATIN 2004] Problem Summarize stream in sketch/synopsis w/ limited memory Finding quantiles, frequent items (heavy hitters), etc Unlikely similar hash collisions Count-Min (CM) Sketch Two-dimensional count array of width w and depth d d hash functions map {1 n} {1 w} Update (si,ci): compute d hashes for si and increase counts of all locations Point query (si): compute d hashes for si and estimate frequency as min(count[j,hj(si)]) 32 6 h1 h2 1 3 h3 3 4 1 1 1 5 h4 1 2 1 hd 7 1 1 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing 2 5
Summary and Q&A Data Stream Processing Distributed Stream Processing Data Stream Mining Next Lectures (Large-scale Data Management and Analysis) 13 Distributed Machine Learning Systems [Feb 01, 4pm] 14 Exam Preparation [Feb 01, 6pm] 33 Matthias Boehm FG DAMS DIA WiSe 2023/24 – 12 Distributed Stream Processing






