Customizable Soft Vector Processors Peter Yiannacouras, PhD Candidate




8 Slides718.00 KB
Customizable Soft Vector Processors Peter Yiannacouras, PhD Candidate Connections 2009
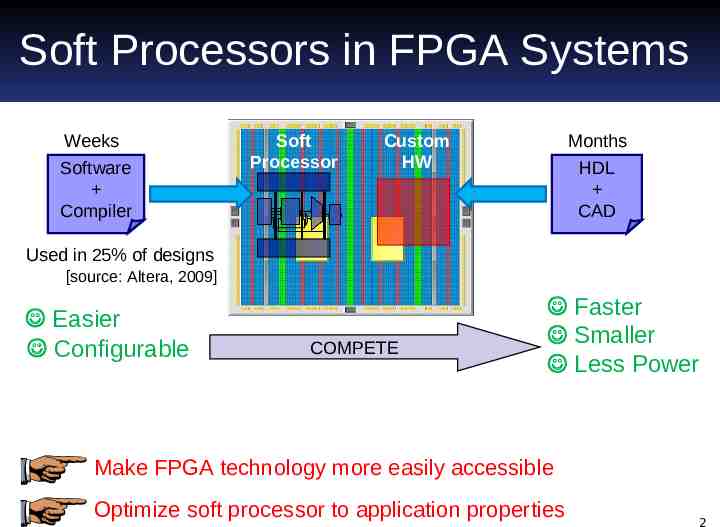
Soft Processors in FPGA Systems Weeks Software Compiler Soft Processor Custom HW Months HDL CAD Used in 25% of designs [source: Altera, 2009] Easier Configurable COMPETE Faster Smaller Less Power Make FPGA technology more easily accessible Optimize soft processor to application properties 2
Data Level Parallelism Same operation // C code for(i 0;i 16; i ) c[i] a[i] b[i] //Processor instructions load r0,a[1] load r1,b[1] add r2,r0,r1 store r2,c[1] c[15] a[15] b[15] c[14] a[14] b[14] c[13] a[13] b[13] c[12] a[12] b[12] c[11] a[11] b[11] c[10] a[10] b[10] c[9] a[9] b[9] c[8] a[8] b[8] c[7] a[7] b[7] c[6] a[6] b[6] c[5] a[5] b[5] c[4] a[4] b[4] c[3] a[3] b[3] c[2] a[2] b[2] c[1] a[1] b[1] c[0] a[0] b[0] Independent data Data Level Parallelism Commonly found in embedded systems Exploit using a Vector Processor c a b 3
Vector Processing Primer // C code for(i 0;i 16; i ) c[i] a[i] b[i] // Vectorized code set vl,16 vload vr0,a vload vr1,b vadd vr2,vr0,vr1 vstore vr2,c Each vector instruction holds many units of independent operations vadd vr2[15] vr0[15] vr1[15] vr2[14] vr0[14] vr1[14] vr2[13] vr0[13] vr1[13] vr2[12] vr0[12] vr1[12] vr2[11] vr0[11] vr1[11] vr2[10] vr0[10] vr1[10] vr2[9] vr0[9] vr1[9] vr2[8] vr0[8] vr1[8] vr2[7] vr0[7] vr1[7] vr2[6] vr0[6] vr1[6] vr2[5] vr0[5] vr1[5] vr2[4] vr0[4] vr1[4] vr2[3] vr0[3] vr1[3] vr2[2] vr0[2] vr1[2] vr2[1] vr0[1] vr1[1] vr2[0] vr0[0] vr1[0] 1 Vector Lane 4
Vector Processing Primer // C code for(i 0;i 16; i ) c[i] a[i] b[i] // Vectorized code set vl,16 vload vr0,a vload vr1,b vadd vr2,vr0,vr1 vstore vr2,c vadd vr2[15] vr0[15] vr1[15] vr2[14] vr0[14] vr1[14] vr2[13] vr0[13] vr1[13] vr2[12] vr0[12] vr1[12] vr2[11] vr0[11] vr1[11] vr2[10] vr0[10] vr1[10] vr2[9] vr0[9] vr1[9] vr2[8] vr0[8] vr1[8] vr2[7] vr0[7] vr1[7] vr2[6] vr0[6] vr1[6] vr2[5] vr0[5] vr1[5] vr2[4] vr0[4] vr1[4] vr2[3] vr0[3] vr1[3] vr2[2] vr0[2] vr1[2] vr2[1] vr0[1] vr1[1] vr2[0] vr0[0] vr1[0] 16 Vector Lanes 16x speedup Implemented on an FPGA (Soft Vector Processor) Each vector instruction holds many units of independent operations Is it scalable? 5
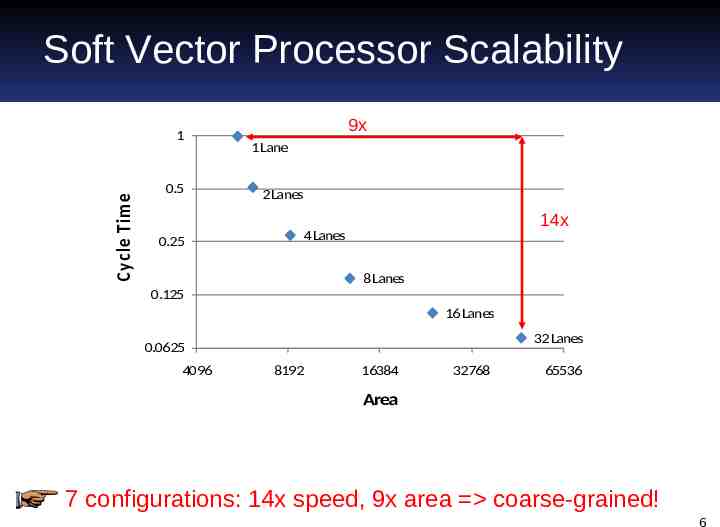
Soft Vector Processor Scalability Cycle Tim e 1 0.5 9x 1 Lane 2 Lanes 14x 0.25 4 Lanes 8 Lanes 0.125 16 Lanes 32 Lanes 0.0625 4096 8192 16384 32768 65536 Area 7 configurations: 14x speed, 9x area coarse-grained! 6
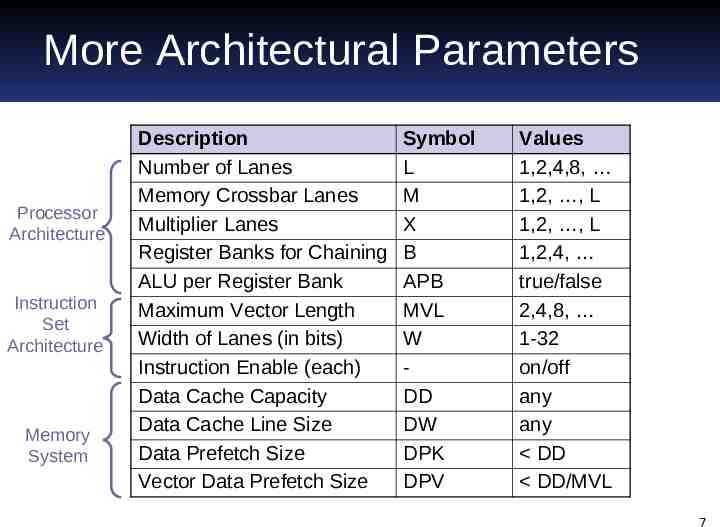
More Architectural Parameters Processor Architecture Instruction Set Architecture Memory System Description Number of Lanes Memory Crossbar Lanes Multiplier Lanes Register Banks for Chaining ALU per Register Bank Maximum Vector Length Width of Lanes (in bits) Instruction Enable (each) Data Cache Capacity Data Cache Line Size Data Prefetch Size Vector Data Prefetch Size Symbol L M X B APB MVL W DD DW DPK DPV Values 1,2,4,8, 1,2, , L 1,2, , L 1,2,4, true/false 2,4,8, 1-32 on/off any any DD DD/MVL 7
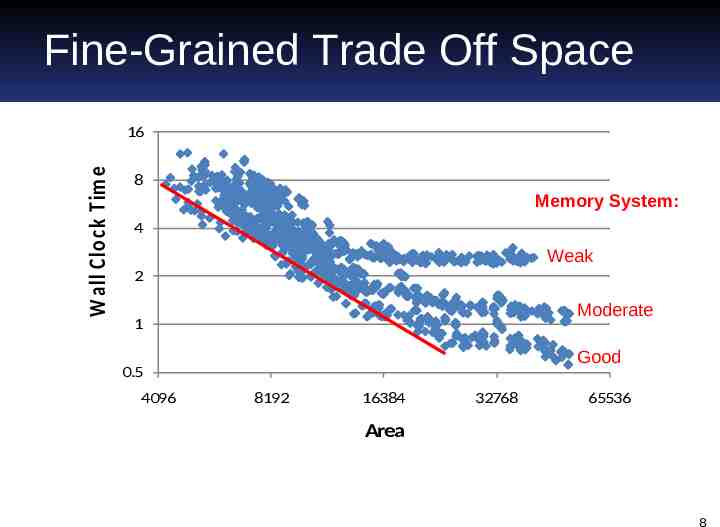
Fine-Grained Trade Off Space W all Clo ck Tim e 16 8 Memory System: 4 Weak 2 Moderate 1 Good 0.5 4096 8192 16384 32768 65536 Area 8






