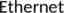CS239-Lecture 5 Spark + SparkSQL Madan Musuvathi Visiting































42 Slides2.15 MB
CS239-Lecture 5 Spark SparkSQL Madan Musuvathi Visiting Professor, UCLA Principal Researcher, Microsoft Research
Project Proposal Send a proposal (2-3 paragraphs) by April 13 Describe the problem Explain why it is interesting to solve Get my approval by April 11 (today)
Other announcements Quiz grades are in Added a topic on the discussion forum on - publicly available large datasets - access to AWS resources
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Zaharia et al. Presented by Manoj Reddy
Motivation MapReduce, Pregel and Dryad popular for large-scale data analytics Users write high-level operators Need not worry about parallelization and fault tolerance Issues: Do not leverage distributed memory Bottleneck: Data replication, disk I/O and serialization Support only specific computation patterns Inefficient for iterative ML and graph algorithms Keeping data in memory can improve performance by orders of magnitude Interactive data mining: Run multiple ad-hoc queries on the same subset of data
Resilient Distributed Datasets (RDDs) RDD is a read-only, partitioned collection of records Created through deterministic transformations on either: Data in stable storage Other RDDs Transformations include: map, filter & join RDDs do not need to be materialized at all times Lazy computation RDDs can be derived by computing the partitions through lineage Persistence: Users can specify a storage strategy for RDDs Partitioning: Useful for placement optimizations Join 2 RDDs that are co-partitioned Partitions RDD
Advantages of RDD Model In RDDs, writes are only possible through coarse-grained transformations More efficient fault tolerance
Disadvantages of RDD model RDDs best suited for batch applications Apply the same operation to all elements in a dataset Useful for efficiently recovering lost partitions using lineage graph Avoids logging large amounts of data Not suitable for asynchronous fine grained updates to shared state Storage system for web application Incremental web crawler Databases such as RAMCloud, Percolator and Piccolo more suitable Perform traditional update logging and data check-pointing
Example Stored in HDFS Stored in memory Pipeline filter and map and send a set of tasks to compute them on nodes containing partitions of errors Count and Collect are actions
Spark Scala OO Functional Programming Provides RDD abstraction in API similar to DryadLINQ RDD Operations in Spark
Logistic Regression & Page Rank Uses iterative algorithm called Gradient Descent Each document sends a contribution of r – its current rank n – number of neighbors Updates it’s rank as: 20x speedup over Hadoop
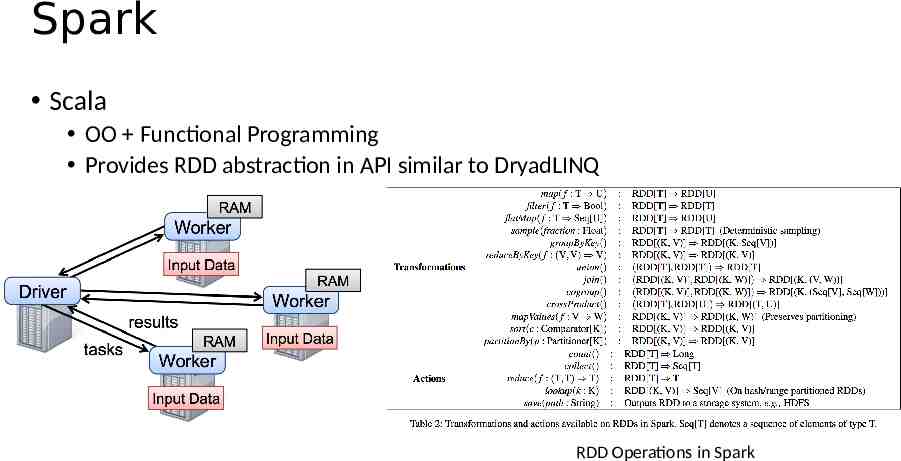
RDD Representation Relationship between RDDs Each partition of the parent RDD is used by at most one partition of the child RDD Multiple child partitions may depend on parent partition
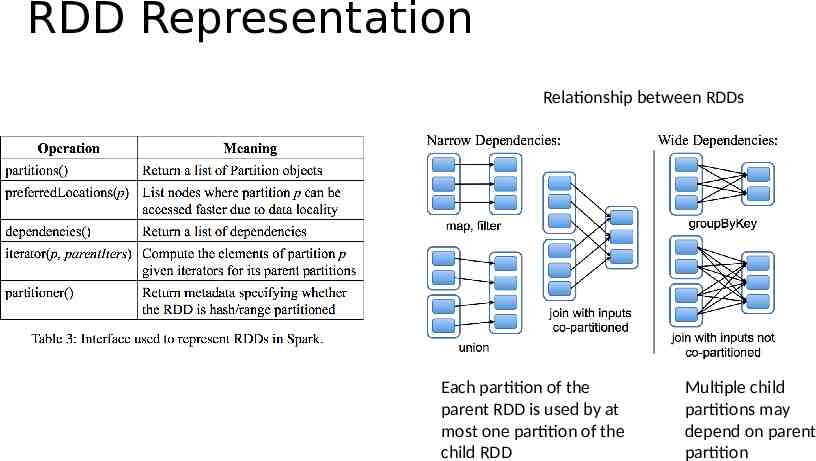
Implementation (I) Spark implemented using 14,000 lines of Scala Runs on top of Mesos cluster manager Job Scheduler: Similar to Dryad Takes in to account which partitions of persistent RDDs are in memory Builds a DAG of stages to execute using lineage graph Shuffle Stages contains pipelined transformations with narrow dependencies
Implementation (II) Job Scheduling If a node contains a partition in memory that needs to be processed then task is executed on that node If RDD provides preferred locations then the task is sent to the respective node Fault tolerance If a task fails, it is re-run on another node as long as its stage’s parents are still available If some stages become unavailable then, tasks are resubmitted to compute the missing partitions in parallel Scheduler failures can be tolerated by replicating the RDD lineage graph (About 10Kb)
Implementation (III) Interpreter integration Interactive shell similar to Ruby and Python. Extension to SQL Memory management 3 types: in-memory de-serialized java objects, in-memory serialized objects, on-disk Default is LRU policy but user can control via “persistence priority” Support for check pointing Useful for RDDs with long lineage graphs containing wide dependencies Users are in control (REPLICATE flag) For example, PageRank: a loss of partition on rank requires full recomputation Tradeoff: Not worthwhile for logistic regression Open problem: Determine which RDDs is worth checkpointing
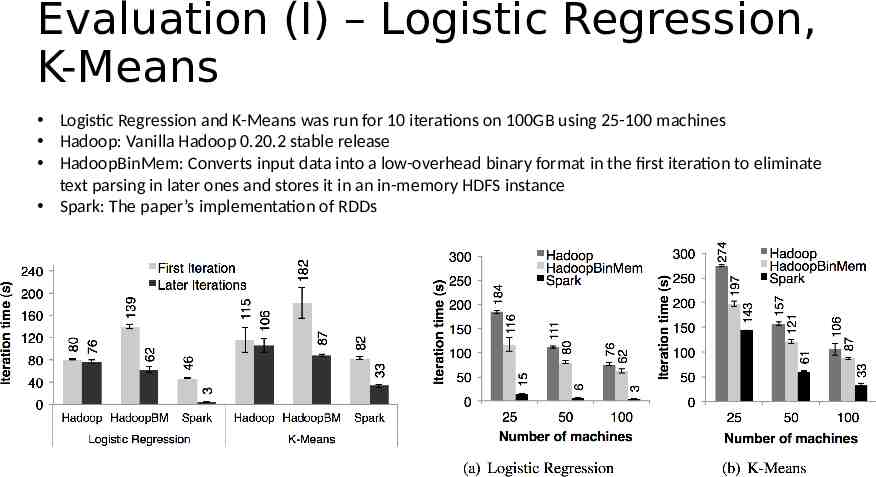
Evaluation (I) – Logistic Regression, K-Means Logistic Regression and K-Means was run for 10 iterations on 100GB using 25-100 machines Hadoop: Vanilla Hadoop 0.20.2 stable release HadoopBinMem: Converts input data into a low-overhead binary format in the first iteration to eliminate text parsing in later ones and stores it in an in-memory HDFS instance Spark: The paper’s implementation of RDDs
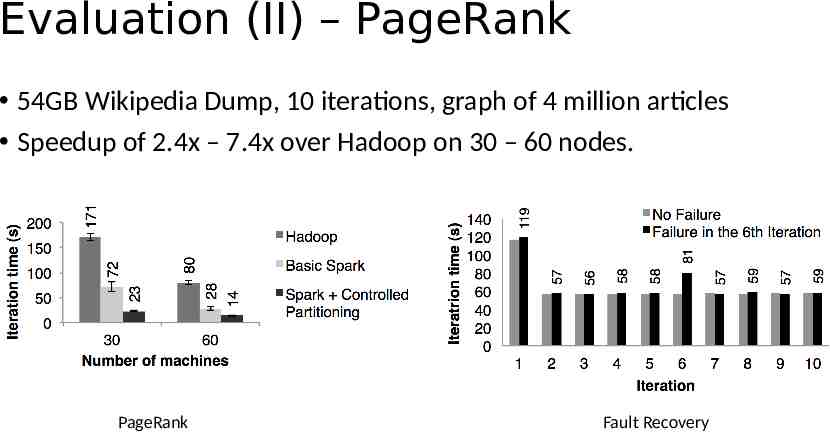
Evaluation (II) – PageRank 54GB Wikipedia Dump, 10 iterations, graph of 4 million articles Speedup of 2.4x – 7.4x over Hadoop on 30 – 60 nodes. PageRank Fault Recovery
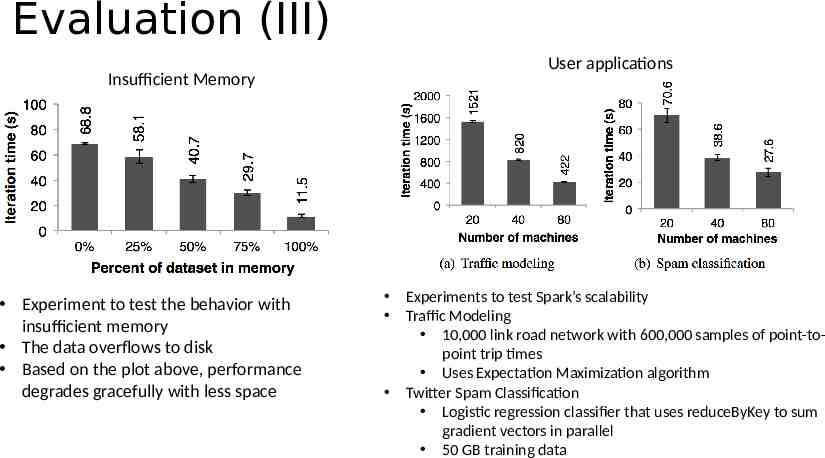
Evaluation (III) User applications Insufficient Memory Experiment to test the behavior with insufficient memory The data overflows to disk Based on the plot above, performance degrades gracefully with less space Experiments to test Spark’s scalability Traffic Modeling 10,000 link road network with 600,000 samples of point-topoint trip times Uses Expectation Maximization algorithm Twitter Spam Classification Logistic regression classifier that uses reduceByKey to sum gradient vectors in parallel 50 GB training data
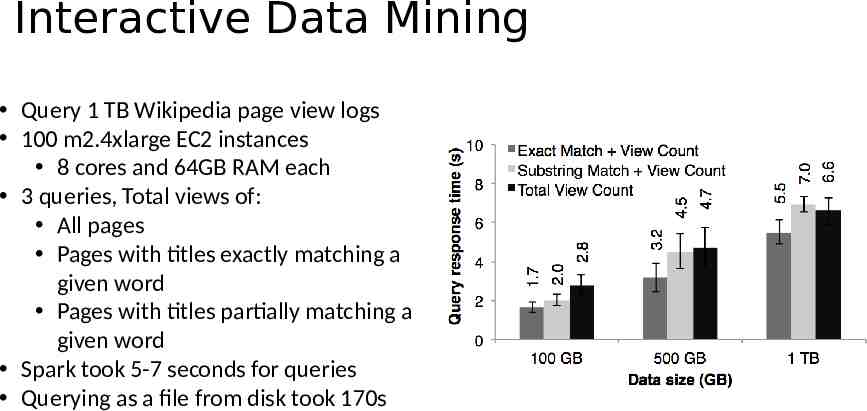
Interactive Data Mining Query 1 TB Wikipedia page view logs 100 m2.4xlarge EC2 instances 8 cores and 64GB RAM each 3 queries, Total views of: All pages Pages with titles exactly matching a given word Pages with titles partially matching a given word Spark took 5-7 seconds for queries Querying as a file from disk took 170s
Conclusion RDDs can express so far proposed cluster programming models MapReduce, DryadLINQ, Pregel using 200 line library on top of Spark Supports interactive data mining and batch stream processing Another benefit of RDD model is debugging using the lineage information Spark performs really well because previous frameworks did not provide data sharing abstractions Coarse-grained transformations allow Spark to recover data efficiently using lineage Spark is up to 20x faster than Hadoop for iterative applications, 40x for realworld data analytics report and can scan 1TB dataset with 5-7s latency
References Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauley, M., . & Stoica, I. (2012, April). Resilient distributed datasets: A faulttolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation (pp. 2-2). USENIX Association. Dean, J., & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1), 107113. G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing. In SIGMOD, 2010. Y. Bu, B. Howe, M. Balazinska, and M. D. Ernst. HaLoop: efficient iterative data processing on large clusters. Proc. VLDB Endow., 3:285– 296, September 2010. Yu, Y., Isard, M., Fetterly, D., Budiu, M., Erlingsson, Ú., Gunda, P. K., & Currey, J. (2008, December). DryadLINQ: A System for GeneralPurpose Distributed Data-Parallel Computing Using a High-Level Language. In OSDI(Vol. 8, pp. 1-14). Chambers, C., Raniwala, A., Perry, F., Adams, S., Henry, R. R., Bradshaw, R., & Weizenbaum, N. (2010, June). FlumeJava: easy, efficient data-parallel pipelines. In ACM Sigplan Notices (Vol. 45, No. 6, pp. 363-375). ACM.
Spark SQL: Relational Data Processing in Spark Lana Ramjit
Overview
Two Paradigms MapReduce parallelism abstractions make it easy to run distributed computation flexible, complete programming language -programmer responsible for optimizations -difficult/inefficient for many queries (join) SQL Easy for certain operations like filter, join Optimizations built-in Simple, declarative query statements -must perform ETL on data -doesn't scale well -hard to perform iteration, row-by-row
What is Spark SQL? Tries to allow users to have the advantages of both without the disadvantages of either Make it easier to construct a “pipeline” or mix of SQL queries fed into procedural constructs, similar to FlumeJava or DryadLINQ Transforms SQL operations into RDD operations Data can be loaded from HDFS Stores data in memory Supports both relational and Spark-style queries Provides a configurable optimization engine
Shark: Spark SQL predecessor Extended Hive to run on top of Spark Implemented optimizations that are common in RDBMS - only worked with external data stored in HDFS, not on native RDDs -optimizations were limited to those for MapReduce -only usable through forming SQL queries
Features and Constructs
DataFrame API The DataFrame is the main abstraction provided Conceptually, similar to a table in a relational database Can be constructed from RDDs, Hive tables, or most structured data files (CSVs, JSON) (top image) Can run SQL style queries on them (bottom image)
DataFrames cont'd The most compelling features (in my opinion!) can embed relational style queries inside of a non-declarative language Allows use of things like loop constructs and conditionals surrounding SQL-style queries Can access, name, and use intermediate results of those queries Spark-style lazy-eval allows optimization (more on this later) Immediate error detection and response despite lazy-evaluation
Catalyst Optimizer “At its core, Catalyst contains a general library for representing trees and applying rules to manipulate them.” Trees consist of nodes, which have a type and 0 children. Rules are functions that transform a tree from one state to another, usually using pattern matching native to functional languages.
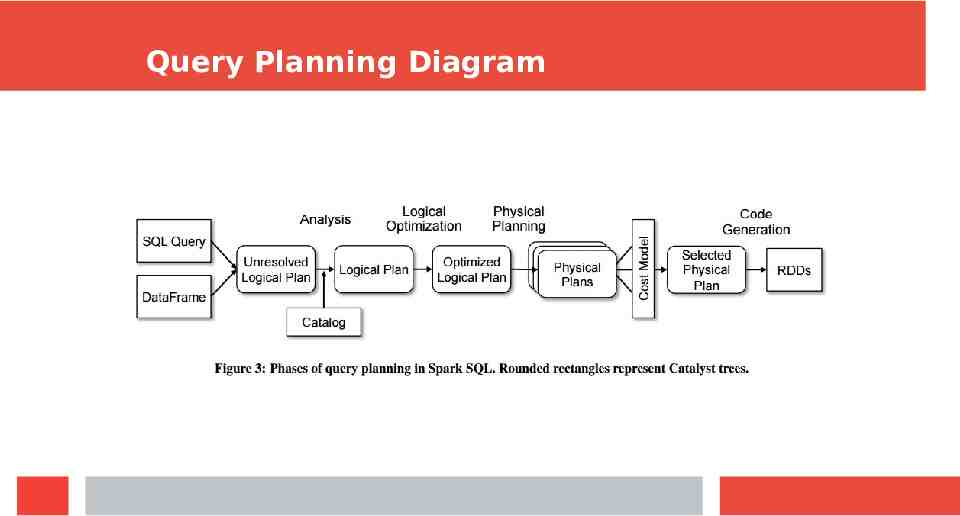
Four Stages 1) Analysis Takes a query, finds the matching relation from the Catalog, performs type matching, and resolves aliases 2) Logical optimization Performs basic rule-based optimization to transform the tree (for example, simplifying a boolean expression) 3) Physical planning generates plans based on the physical layout of the data and the costs of those plans 4) Code Generation uses quasiquotes to generate Java bytecode
Query Planning Diagram
Analytics Features Can infer a schema from semi-structured data (neat!) Passes over data, finds the most specific but sufficient Spark SQL data-type that covers all instances of a field Find all instances of field, find largest matching data type, and set that as the “type” of that column MLLib added a DataFrame API for ML Created a user-defined type to represent vectors (not sure why this wasn't an original type) Had the incidental effect of introducing cross-compatibility across all Spark languages
Performance and Evaluation
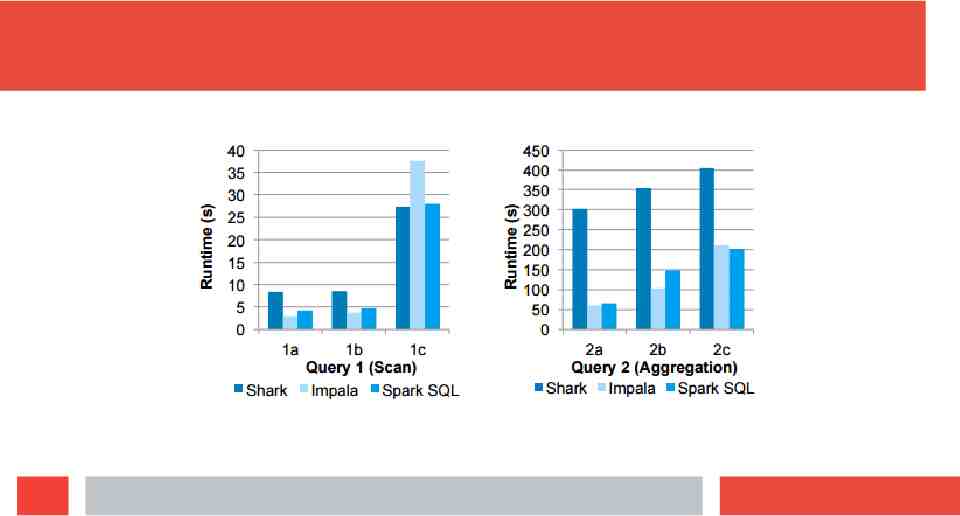
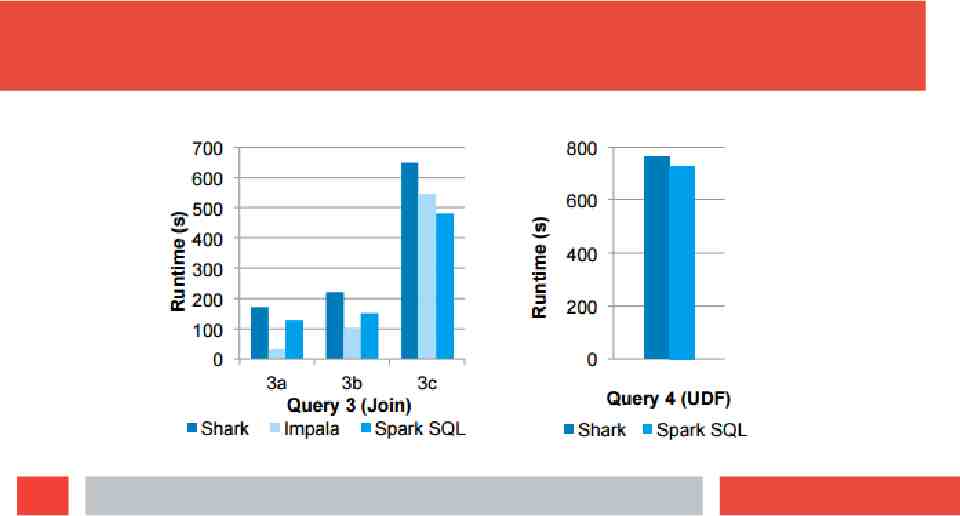
Performance: SQL Queries SQL Query Performance Use AMPLab big data benchmark Four queries which perform scans, aggregation, joins and a MapReduce job that uses a UDF First three queries have multiple parameters that increase selectivity such that query 1b is more selective than 1a and 1c is more selective than 1b Compared against Impala and Shark Competitive performance, overall
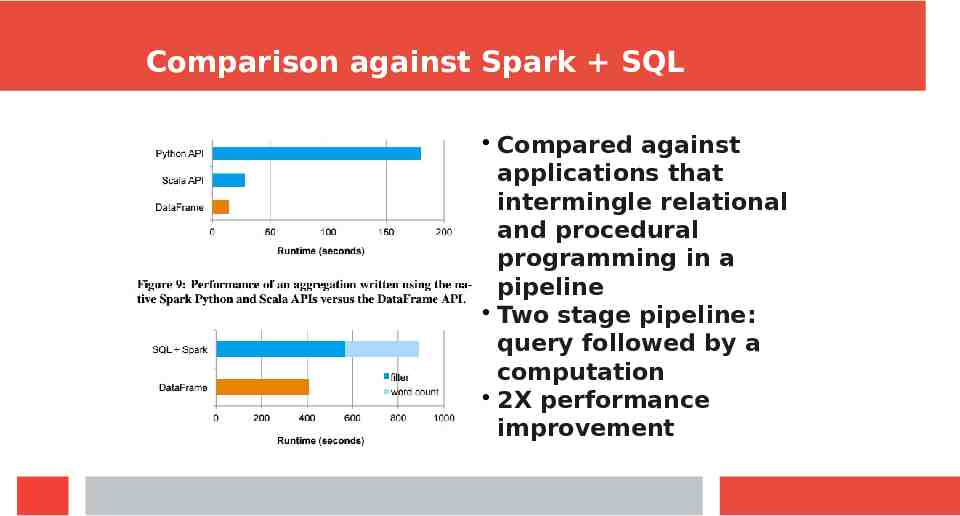
Comparison against Spark SQL Compared against applications that intermingle relational and procedural programming in a pipeline Two stage pipeline: query followed by a computation 2X performance improvement
Issues? Improvements? Extensible optimization Cool in theory! But having written a compiler using a functional language.doesn't seem useful for the average programmer. I didn't find Catalyst's method of adding rules intuitive and still find it a bit confusing Evaluation Found the spark sql evaluation method lacking—wanted a better comparison against larger pipelines Choosing two separate engines felt like a straw-man Would also be interested in a “softer” usability report
Comparison to Dryad-LINQ, FlumeJava If pipeline optimization and languageintegrated relational queries sound familiar, that's because it is Comparison of performance? Does SparkSQL do anything new? The DataFrame abstraction is novel—DryadLINQ works on C# objects. Iteration via Spark Offers immediate feedback on type and compilation errors Other?
Spark SQL DataFrames API - relational interface associate schemas with RDDs lazy evaluation (unlike R & Python) columnar format Catalyst optimizer - use Scala’s pattern matching feature to write tree transformation rules