CS136, Advanced Architecture Directory-Based Cache Coherence (more or







































55 Slides370.50 KB
CS136, Advanced Architecture Directory-Based Cache Coherence (more or less, with some inappropriate other topics)
Implementation Complications Write Races: – Cannot update cache until bus is obtained » Otherwise, another processor may get bus first, and then write the same cache block! – Two-step process: » Arbitrate for bus » Place miss on bus and complete operation – If miss occurs to block while waiting for bus, handle miss (invalidate may be needed) and then restart – Split-transaction bus: » Bus transaction is not atomic: can have multiple outstanding transactions for a block » Multiple misses can interleave, allowing two caches to grab block in the Exclusive state » Must track and prevent multiple misses for one block Must support interventions and invalidations CS136 2
Implementing Snooping Caches Multiple processors must be on bus, access to both addresses and data Add a few new commands to perform coherency, in addition to read and write Processors continuously snoop on address bus – If address matches tag, either invalidate or update Since every bus transaction checks cache tags, could interfere with CPU just to check: – Solution 1: duplicate set of tags for L1 caches just to allow checks in parallel with CPU – Solution 2: L2 cache already duplicate, provided L2 obeys inclusion with L1 cache » Block size, associativity of L2 affects L1 CS136 3
Limitations in Symmetric SMPs and Snooping Protocols Single memory accommodates all CPUs Multiple memory banks Bus-based multiprocessor – Bus must support both coherence & normal memory traffic Multiple buses or interconnection networks (crossbar or small point-to-point) Example: Opteron – Memory connected directly to each dual-core chip – Point-to-point connections for up to 4 chips – Remote memory and local memory latency are similar, allowing OS to treat Opteron as UMA computer CS136 4
Performance of Symmetric SharedMemory Multiprocessors Cache performance is combination of 1. Uniprocessor cache-miss traffic 2. Traffic caused by communication » Results in invalidations and subsequent cache misses 4th C: coherence miss – Joins Compulsory, Capacity, Conflict CS136 5
Coherence Misses 1. True-sharing misses arise from communication of data through cache-coherence mechanism – Invalidates due to 1st write to shared block – Reads by another CPU of modified block in different cache – Miss would still occur if block size were 1 word 2. False-sharing misses when a block is invalidated because some word in the block, other than the one being read, is written into – Invalidation does not cause a new value to be communicated, but only causes an extra cache miss – Block is shared, but no word in block is actually shared Miss would not occur if block size were 1 word CS136 6
Example: True v. False Sharing v. Hit Assume x1 and x2 in same cache block. P1 and P2 both read x1 and x2 before. Time P1 1 Write x1 2 3 CS136 True, False, Hit? Why? True miss; invalidate x1 in P2 Read x2 False miss; x1 irrelevant to P2 Write x1 4 5 P2 False miss; x1 irrelevant to P2 Write x2 False miss; x1 irrelevant to P2 Read x2 True miss; invalidate x2 in P1 7
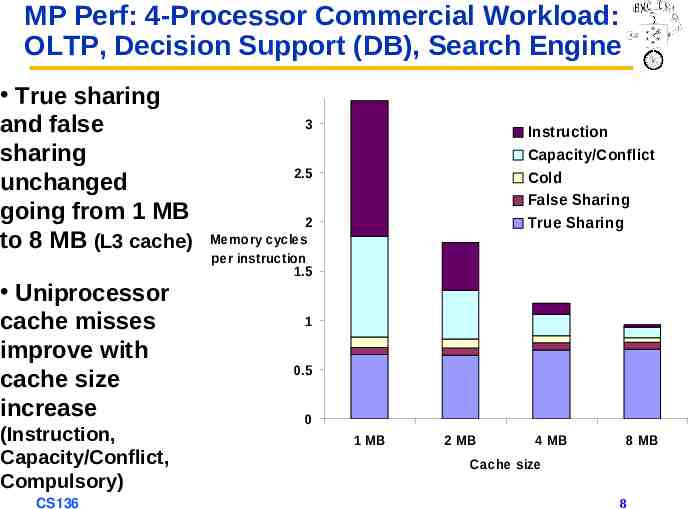
MP Perf: 4-Processor Commercial Workload: OLTP, Decision Support (DB), Search Engine True sharing and false sharing unchanged going from 1 MB to 8 MB (L3 cache) Uniprocessor cache misses improve with cache size increase (Instruction, Capacity/Conflict, Compulsory) CS136 3 Instruction Capacity/Conflict Cold False Sharing True Sharing 2.5 2 Memory cycles per instruction 1.5 1 0.5 0 1 MB 2 MB 4 MB 8 MB Cache size 8
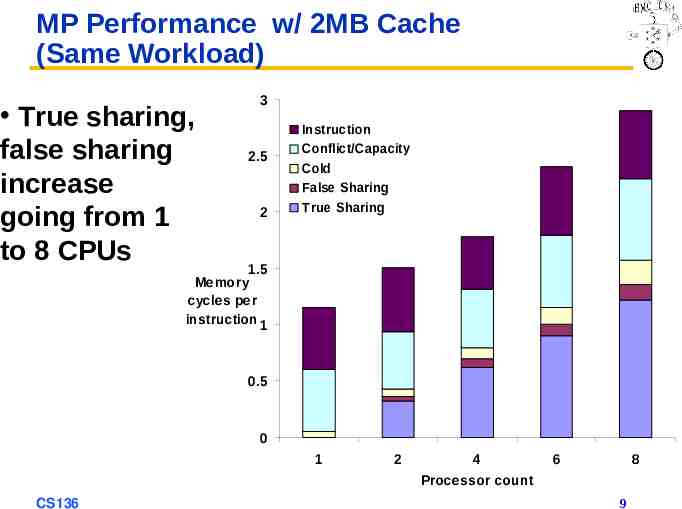
MP Performance w/ 2MB Cache (Same Workload) True sharing, false sharing increase going from 1 to 8 CPUs 3 2.5 2 Instruction Conflict/Capacity Cold False Sharing True Sharing 1.5 Memory cycles per instruction 1 0.5 0 1 CS136 2 4 Processor count 6 8 9
A Cache-Coherent System Must: Provide set of states, state transition diagram, and actions Manage coherence protocol – (0) Determine when to invoke coherence protocol – (a) Find info about state of block in other caches to determine action » Whether need to communicate with other cached copies – (b) Locate other copies – (c) Communicate with those copies (invalidate/update) (0) is done the same way on all systems – State of the line is maintained in the cache – Protocol is invoked if “access fault” occurs on the line Different approaches distinguished by (a) to (c) CS136 10
Bus-based Coherence All of (a), (b), (c) done through broadcast on bus – Faulting processor sends out a “search” – Others respond to the search probe and take necessary action Could do it in scalable network too – Broadcast to all processors, and let them respond Conceptually simple, but broadcast doesn’t scale with p (number of processors) – On bus, bus bandwidth doesn’t scale – On scalable (switched) network, every fault leads to at least p network transactions Scalable coherence: – Can have same cache states and transition diagram – Different mechanisms to manage protocol CS136 11
Scalable Approach: Directories Every memory block has associated directory information – Keeps track of copies of cached blocks and their states – On miss, find directory entry, look it up, and communicate only with the nodes that have copies, but only if necessary – In scalable networks, communication with directory and copies is through network transactions Many alternatives for organizing directory information CS136 12
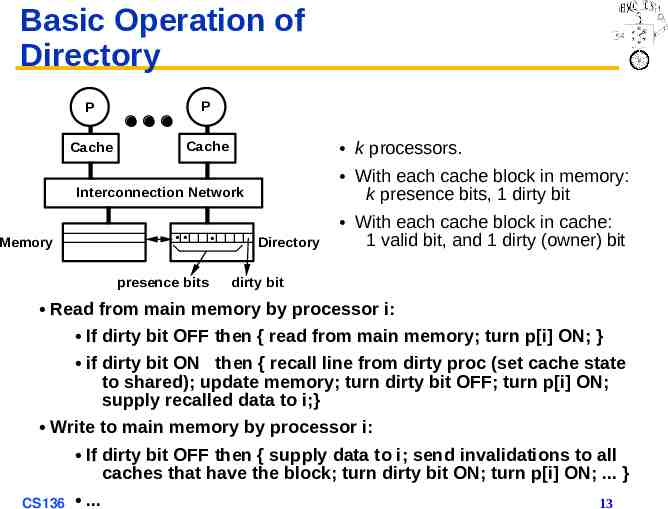
Basic Operation of Directory P P Cache Cache k processors. With each cache block in memory: k presence bits, 1 dirty bit Interconnection Network Memory presence bits Directory With each cache block in cache: 1 valid bit, and 1 dirty (owner) bit dirty bit Read from main memory by processor i: If dirty bit OFF then { read from main memory; turn p[i] ON; } if dirty bit ON then { recall line from dirty proc (set cache state to shared); update memory; turn dirty bit OFF; turn p[i] ON; supply recalled data to i;} Write to main memory by processor i: If dirty bit OFF then { supply data to i; send invalidations to all caches that have the block; turn dirty bit ON; turn p[i] ON; . } CS136 . 13
Directory Protocol Similar to Snoopy Protocol: Three states – Shared: 1 processors have data, memory up-to-date – Uncached (no processor has it; not valid in any cache) – Exclusive: 1 processor (owner) has data; memory out-of-date In addition to cache state, must track which processors have data when in the shared state (usually bit vector, 1 if processor has copy) Keep it simple(r): – Writes to non-exclusive data Write miss – Processor blocks until access completes – Assume messages received and acted upon in order sent CS136 14
Directory Protocol No bus and don’t want to broadcast: – Interconnect no longer single arbitration point – All messages have explicit responses Terms: typically 3 processors involved – Local node where a request originates – Home node where the memory location of an address resides – Remote node has copy of a cache block, whether exclusive or shared Example messages on next slide: P processor number, A address CS136 15
Directory Protocol Messages (Fig 4.22) Message type Source Destination Msg Content Read miss Local cache Home directory P, A – Processor P reads data at address A; make P a read sharer and request data Write miss Local cache Home directory P, A – Processor P has a write miss at address A; make P the exclusive owner and request data Invalidate Home directory Remote caches A – Invalidate a shared copy at address A Fetch Home directory Remote cache A – Fetch the block at address A and send it to its home directory; change the state of A in the remote cache to shared Fetch/Invalidate Home directory Remote cache A – Fetch the block at address A and send it to its home directory; invalidate the block in the cache Data value reply Home directory Local cache Data – Return a data value from the home memory (read miss response) Data write back Remote cache Home directory A, Data – Write back a data value for address A (invalidate response) CS136 16
State-Transition Diagram for One Block in Directory-Based System States identical to snoopy case; transactions very similar Transitions caused by read misses, write misses, invalidates, data fetch requests Generates read miss & write miss message to home directory Write misses that were broadcast on the bus for snooping explicit invalidate & data fetch requests Note: on a write, a cache block is bigger, so need to read the full cache block CS136 17
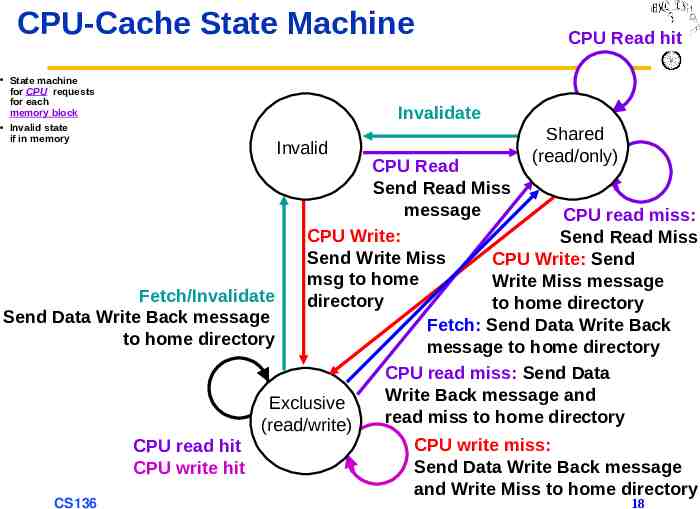
CPU-Cache State Machine State machine for CPU requests for each memory block Invalid state if in memory CPU Read hit Invalidate Invalid Shared (read/only) CPU Read Send Read Miss message CPU read miss: CPU Write: Send Read Miss Send Write Miss CPU Write: Send msg to home Write Miss message Fetch/Invalidate directory to home directory Send Data Write Back message Fetch: Send Data Write Back to home directory message to home directory CPU read miss: Send Data Write Back message and Exclusive read miss to home directory (read/write) CPU read hit CPU write hit CS136 CPU write miss: Send Data Write Back message and Write Miss to home directory 18
Transition Diagram for Directory Same states & structure as the transition diagram for an individual cache 2 actions 1. Update directory state 2. Send messages to satisfy requests Tracks all copies of memory block Also indicates an action that updates the sharing set, Sharers, as well as sending a message CS136 19
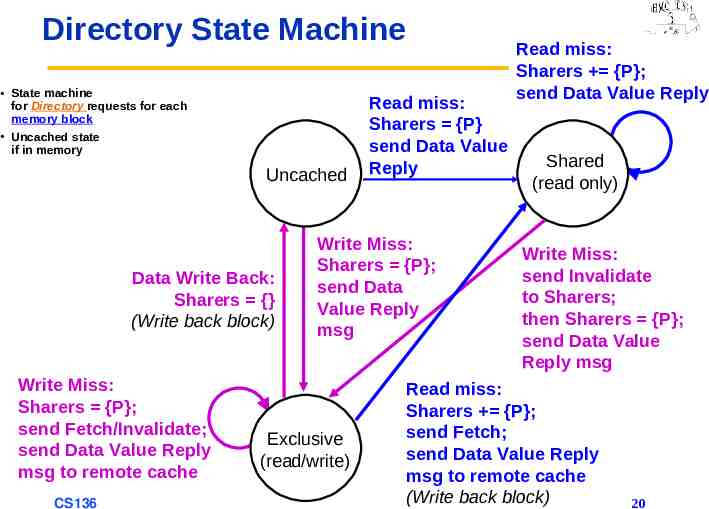
Directory State Machine State machine for Directory requests for each memory block Uncached state if in memory Uncached Data Write Back: Sharers {} (Write back block) Write Miss: Sharers {P}; send Fetch/Invalidate; send Data Value Reply msg to remote cache CS136 Read miss: Sharers {P} send Data Value Reply Write Miss: Sharers {P}; send Data Value Reply msg Exclusive (read/write) Read miss: Sharers {P}; send Data Value Reply Shared (read only) Write Miss: send Invalidate to Sharers; then Sharers {P}; send Data Value Reply msg Read miss: Sharers {P}; send Fetch; send Data Value Reply msg to remote cache (Write back block) 20
Example Directory Protocol Message sent to directory causes two actions: – Update directory – More messages to satisfy request If block Uncached: copy in memory is current value; only possible requests for that block are: – Read miss: requesting processor sent data from memory & requestor made only sharing node; state of block made Shared. – Write miss: requesting processor is sent value & becomes the Sharing node. Block made Exclusive to indicate only valid copy is cached. Sharers indicates identity of owner. Block is Shared memory value is up to date: – Read miss: requesting processor is sent data from memory & added to sharing set. – Write miss: requesting processor is sent value. All processors in Sharers are sent invalidate messages, & Sharers set to just requesting processor. State of block is made Exclusive. CS136 21
Example Directory Protocol Block is Exclusive: current value held in the cache of the processor identified by the set Sharers (the owner) three possible directory requests: – Read miss: owner sent data fetch message, changing state in owner’s cache to Shared and causing owner to send data to directory, where it is written to memory & sent back to requestor. Requestor added to Sharers, which still contains processor that was the owner. – Data write-back: owner is replacing block and hence must write it back, making memory copy up-to-date (home directory now becomes owner). Block is now Uncached and Sharers is empty. – Write miss: block has new owner. Message sent to old owner, causing cache to send value to directory and thence to requestor, which becomes new owner. Sharers set to new owner, and state becomes Exclusive. CS136 22
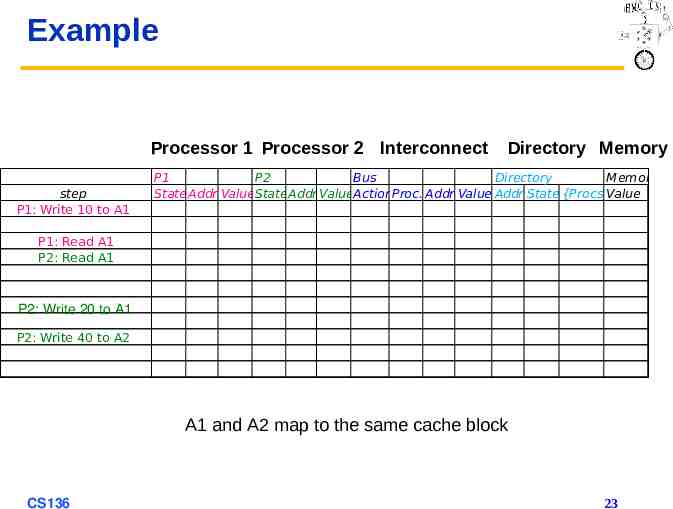
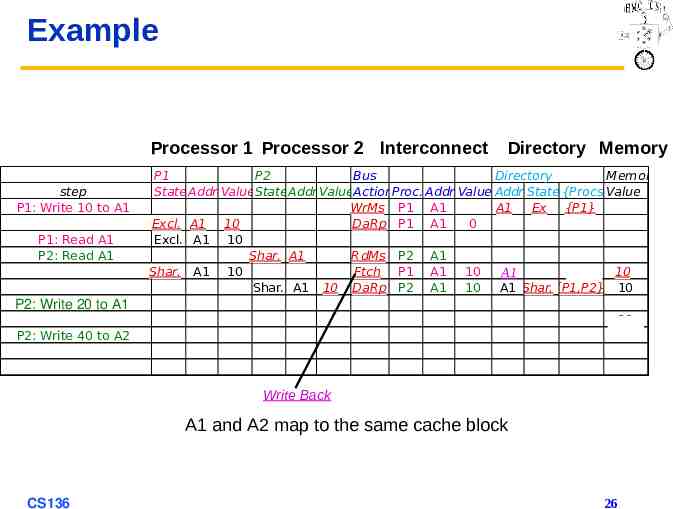
Example Processor 1 Processor 2 Interconnect step P1: Write 10 to A1 Directory Memory P1 P2 Bus Directory Memory State Addr ValueStateAddr ValueActionProc. Addr Value Addr State {Procs}Value P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 A1 and A2 map to the same cache block CS136 23
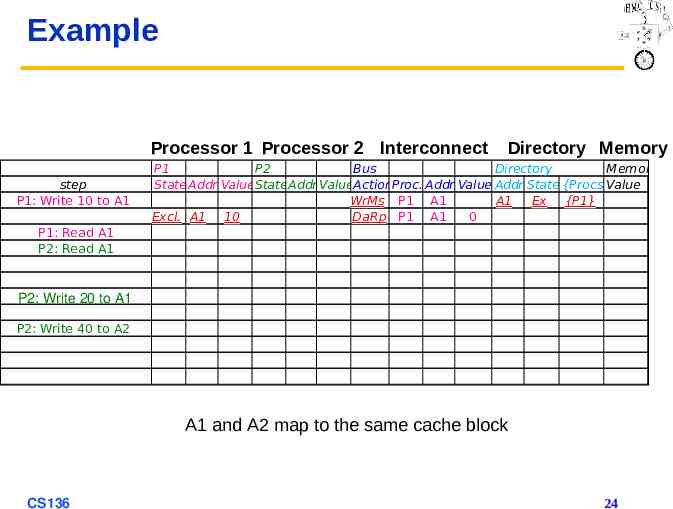
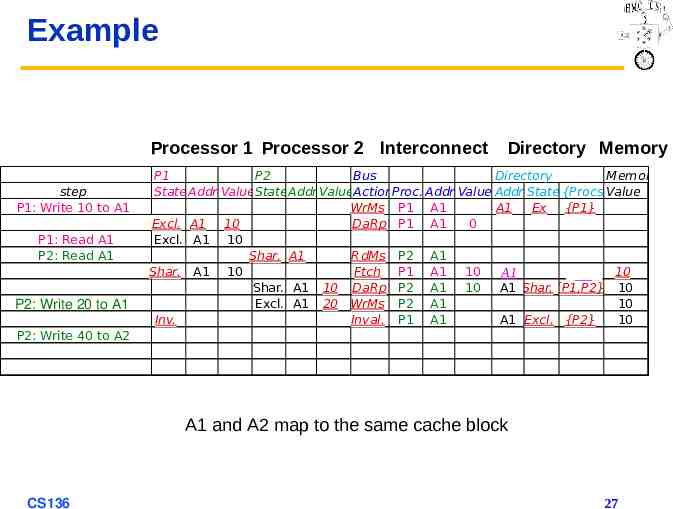
Example Processor 1 Processor 2 Interconnect step P1: Write 10 to A1 Directory Memory P1 P2 Bus Directory Memory State Addr ValueStateAddr ValueActionProc. Addr Value Addr State {Procs}Value WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 A1 and A2 map to the same cache block CS136 24
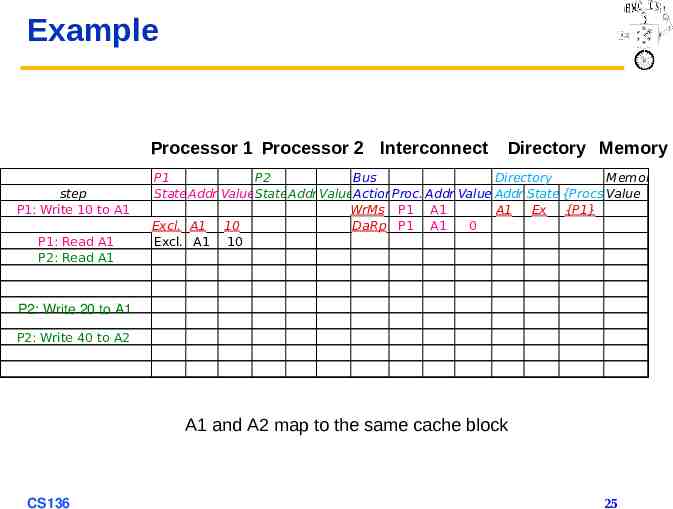
Example Processor 1 Processor 2 Interconnect step P1: Write 10 to A1 P1: Read A1 P2: Read A1 Directory Memory P1 P2 Bus Directory Memory State Addr ValueStateAddr ValueActionProc. Addr Value Addr State {Procs}Value WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 Excl. A1 10 P2: Write 20 to A1 P2: Write 40 to A2 A1 and A2 map to the same cache block CS136 25
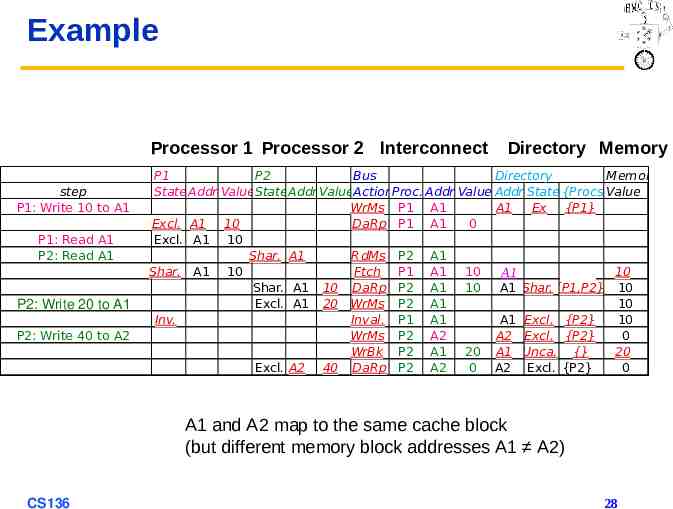
Example Processor 1 Processor 2 Interconnect step P1: Write 10 to A1 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Directory Memory P1 P2 Bus Directory Memory State Addr ValueStateAddr ValueActionProc. Addr Value Addr State {Procs}Value WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 Excl. A1 10 Shar. A1 RdMs P2 A1 Shar. A1 10 Ftch P1 A1 10 10 A1 A1 Shar. A1 10 DaRp P2 A1 10 A1 Shar.{P1,P2} 10 10 10 10 Write WriteBack Back A1 and A2 map to the same cache block CS136 26
Example Processor 1 Processor 2 Interconnect step P1: Write 10 to A1 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Directory Memory P1 P2 Bus Directory Memory State Addr ValueStateAddr ValueActionProc. Addr Value Addr State {Procs}Value WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 Excl. A1 10 Shar. A1 RdMs P2 A1 Shar. A1 10 Ftch P1 A1 10 10 A1 A1 Shar. A1 10 DaRp P2 A1 10 A1 Shar.{P1,P2} 10 Excl. A1 20 WrMs P2 A1 10 Inv. Inval. P1 A1 A1 Excl. {P2} 10 10 A1 and A2 map to the same cache block CS136 27
Example Processor 1 Processor 2 Interconnect step P1: Write 10 to A1 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Directory Memory P1 P2 Bus Directory Memory State Addr ValueStateAddr ValueActionProc. Addr Value Addr State {Procs}Value WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 Excl. A1 10 Shar. A1 RdMs P2 A1 Shar. A1 10 Ftch P1 A1 10 10 A1 A1 Shar. A1 10 DaRp P2 A1 10 A1 Shar.{P1,P2} 10 Excl. A1 20 WrMs P2 A1 10 Inv. Inval. P1 A1 A1 Excl. {P2} 10 WrMs P2 A2 A2 Excl. {P2} 0 WrBk P2 A1 20 A1 Unca. {} 20 Excl. A2 40 DaRp P2 A2 0 A2 Excl. {P2} 0 A1 and A2 map to the same cache block (but different memory block addresses A1 A2) CS136 28
Implementing a Directory We assume operations atomic – Not really true – Reality is much harder – Must avoid deadlock when run out of buffers in network (see Appendix E) Optimization: – Read or write miss in Exclusive: » Send data directly to requestor from owner vs. first to memory and then from memory to requestor CS136 29
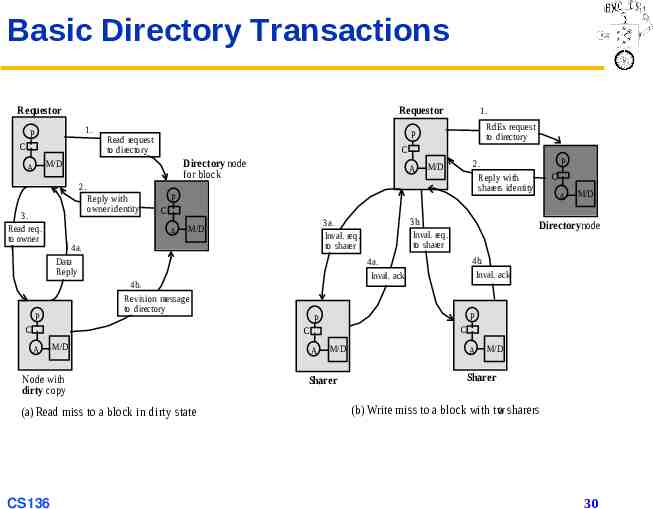
Basic Directory Transactions Requestor Requestor 1. P C RdEx request to directory P Read request to directory C Directory node for block M/D A 1. A 2. 3. Read req. to owner Reply with owner identity P 4a. Data Reply M/D Node with dirty copy (a) Read miss to a block in dirty state 4b. Inval. ack P P C C CS136 A Directorynode 4a. Inval. ack 4b. Revision message to directory M/D 3b. Inval. req. to sharer 3a. Inval. req. to sharer M/D C A C C A P P 2. Reply with sharers identity M/D A M/D Sharer A M/D Sharer (b) Write miss to a block with tw o sharers 30
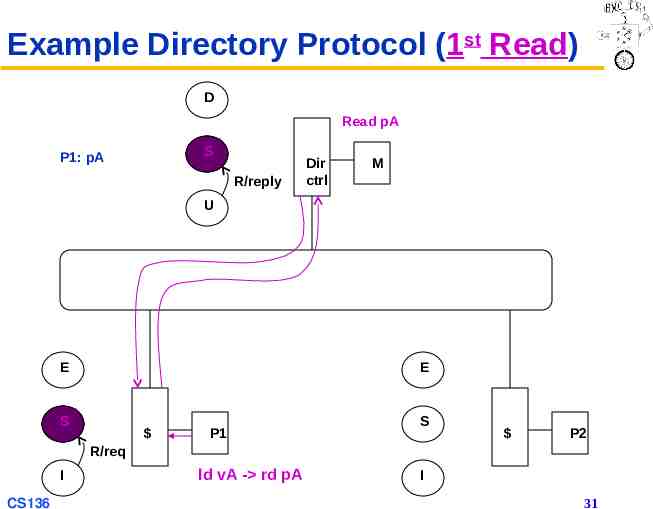
Example Directory Protocol (1st Read) D Read pA S P1: pA R/reply Dir ctrl M U E E S P1 S P2 R/req I CS136 ld vA - rd pA I 31
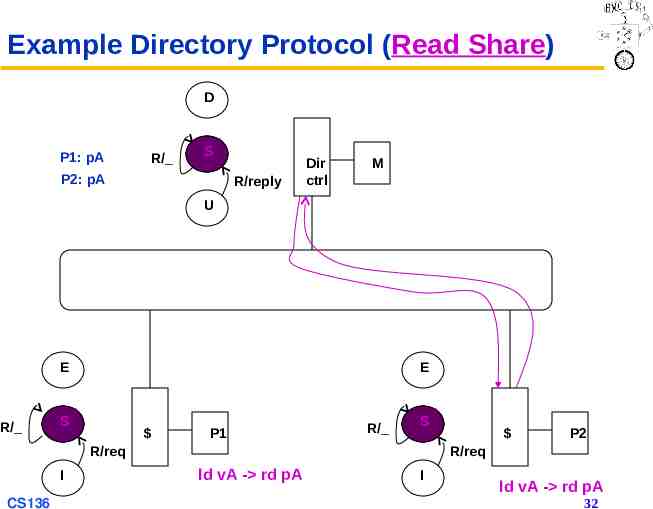
Example Directory Protocol (Read Share) D P1: pA R/ S P2: pA R/reply Dir ctrl M U E R/ E S P1 R/ S R/req I CS136 P2 R/req ld vA - rd pA I ld vA - rd pA 32
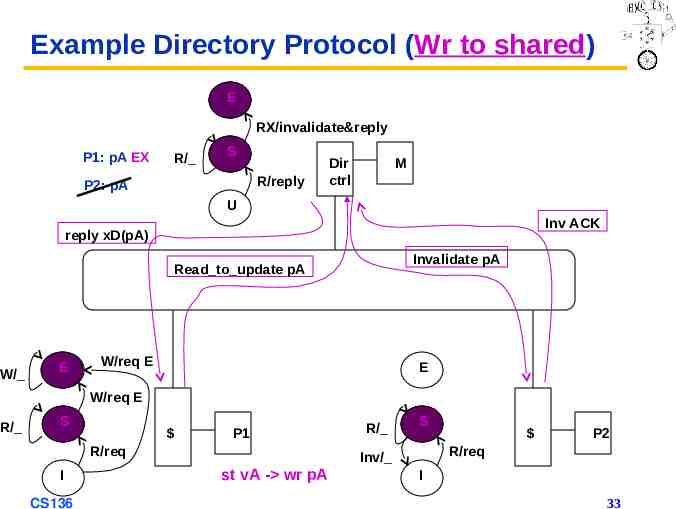
Example Directory Protocol (Wr to shared) D E RX/invalidate&reply P1: pA EX R/ S R/reply P2: pA Dir ctrl M U Inv ACK reply xD(pA) Invalidate pA Read to update pA W/ E W/req E E W/req E R/ S P1 R/req I CS136 R/ S P2 R/req Inv/ st vA - wr pA I 33
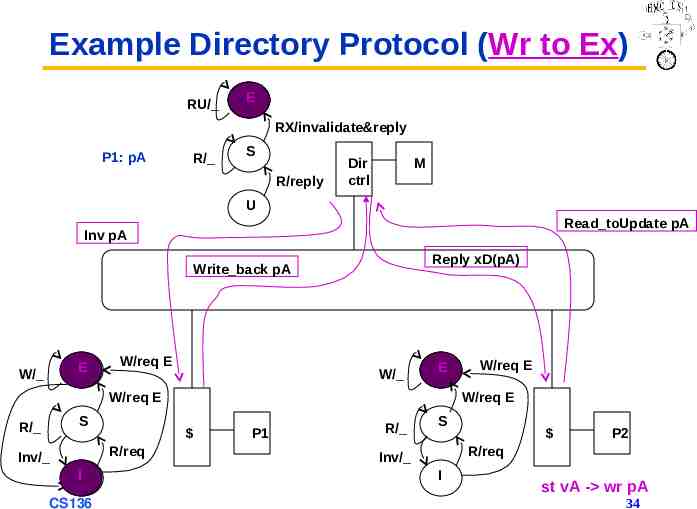
Example Directory Protocol (Wr to Ex) RU/ D E RX/invalidate&reply P1: pA R/ S R/reply Dir ctrl M U Read toUpdate pA Inv pA Reply xD(pA) Write back pA E W/ W/req E W/ E W/req E S R/ I CS136 W/req E R/req Inv/ W/req E P1 R/ S P2 R/req Inv/ I st vA - wr pA 34
A Popular Middle Ground Two-level “hierarchy” Individual nodes are multiprocessors, connected non-hierarchically – E.g. mesh of SMP, or multicore chips Coherence across nodes is directory-based – Directory keeps track of nodes, not individual processors Coherence within nodes is snooping or directory – Orthogonal, but needs a good interface SMP on a chip: directory snoop? CS136 35
New Topic: Synchronization Why synchronize? – Need to know when it is safe for different processes to use shared data Issues for Synchronization: – Uninterruptible instruction to fetch and update memory (atomic operation) – User-level synchronization operation using this primitive – For large-scale MPs, synchronization can be a bottleneck; need techniques to reduce contention and latency of synchronization CS136 36
Uninterruptible Instructions to Fetch and Update Memory Atomic exchange: interchange value in register with one in memory – – – – 0 Synchronization variable is free 1 Synchronization variable is locked and unavailable Set register to 1 & swap New value in register determines success in getting lock » 0 if you succeeded in setting lock (you were first) » 1 if another processor claimed access first – Key: exchange operation is indivisible Test and set: tests value and sets it if it passes test Fetch and increment: returns value of memory location and atomically increments it – 0 synchronization variable is free CS136 37
Uninterruptible Instruction to Fetch and Update Memory Hard to read & write in 1 instruction, so use 2 Load linked (or load locked) store conditional – Load linked returns initial value – Store conditional returns 1 if succeeds (no other store to same memory location since preceding load) and 0 otherwise Example of atomic swap with LL & SC: try: mov R3,R4 R2,0(R1) ; get sc R3,0(R1) beqz R3,try mov R4,R2 ; mov exchange value- R3ll old value ; store new value ; loop if store fails ; put old value in R4 Example of fetch & increment with LL & SC: try: ll R2,0(R1) ; get old value addi R2,R2,#1 ; increment it sc ; store new value beqz R2,try ; loop if store fails CS136 R2,0(R1) 38
User-Level Synchronization Using LL/SC Spin locks: processor continuously tries to acquire lock, spinning around loop trying to get it lockit: locked li exch bnez R2,#1 R2,0(R1) R2,lockit ; atomic exchange ; loop while What about MP with cache coherency? – Want to spin on cached copy to avoid full memory latency – Likely to get cache hits for such variables Problem: exchange includes write – Invalidates all other copies – Generates considerable bus traffic CS136 39
User-Level Synchronization Using LL/SC (cont’d) Solution to bus traffic: don’t try exchange when you know it will fail – Keep reading cached copy – Lock release will invalidate try: li lockit: spin exchange failure CS136 R2,#1 lw R3,0(R1) ;load old bnez R3,lockit ; 0 exch R2,0(R1) ;atomic bnez R2,try ;spin on 40
Another MP Issue: Memory Consistency Models What is consistency? When must processor see new value? E.g., seems that in P1: A 0; P2: B 0; . . A 1; B 1; L1: if (B 0) . L2: if (A 0) . it’s impossible for both ifs L1 & L2 to be true – But what if write invalidate is delayed & processor continues? Memory consistency models: what are rules for such cases? Sequential consistency: result of any execution is same as if each processor’s accesses were kept in order, and accesses among different processors were interleaved (like assignments before ifs above) – SC: delay all memory accesses until all invalidates done CS136 41
Memory Consistency Model Sequential consistency can slow execution SC not issue for most programs; they are synchronized – Defined as all access to shared data being ordered by synchronization operations, e.g. write (x) . release (s) // unlock . acquire (s) // lock . read(x) Only nondeterministic programs aren’t synchronized – Data race: program outcome is f(processor speed) CS136 42
Memory Consistency Models Most programs synchronized (risk-averse programmers) Several relaxed models for memory consistency Characterized by attitude towards: – – – – RAR WAR RAW WAW to different addresses CS136 43
Relaxed Consistency Models: The Basics Key ideas: – Allow reads and writes to complete out of order – But use synchronization operations to enforce ordering – Thus, synchronized program behaves as if processor were sequentially consistent – By relaxing orderings, can obtain performance advantages – Also specifies legal compiler optimizations on shared data » Unless synchronization points clearly defined and programs synchronized, compiler couldn’t swap read and write of two shared data items because might affect program semantics 3 major types of relaxed orderings CS136 44
Relaxed Consistency Orderings W R (writes don’t have to finish before next read) – Retains ordering among writes – Thus, many programs that work under sequential consistency operate under this model without additional synchronization – Called processor consistency W W (writes can be reordered) R W and R R – Variety of models depending on ordering restrictions and how synchronization operations enforce ordering CS136 45
Complexities in Relaxed Consistency Defining precisely what “completing a write” means Deciding when a processor can see values that it has written CS136 46
Mark Hill’s Observation Use speculation to hide latency caused by strict consistency model – If processor receives invalidation for memory reference before it is committed, use speculation recovery to back out computation and restart with invalidated memory reference – Very closely related to Virtual Time 1. Aggressive implementation of sequential consistency or processor consistency gains most of advantage of more relaxed models 2. Implementation adds little to implementation cost of speculative processor 3. Allows programmer to reason using simpler programming models – Some load/store synchronization algorithms require this CS136 47
Crosscutting Issues: Performance Measurement of Parallel Processors Performance: how well scale as increase # proc Speedup fixed as well as scaleup of problem – Assume benchmark of size n on p processors makes sense: how scale benchmark to run on m * p processors? – Memory-constrained scaling: keeping amount of memory used constant per processor – Time-constrained scaling: keeping total execution time, assuming perfect speedup, constant Example: 1 hour on 10 P, time O(n3), 100 P? – Memory-constrained scaling: 10n size 103/10 100X or 100 hours! 10X processors for 100X longer? – Time-constrained scaling: 1 hour 101/3n 2.15n scale up Must know app. well if want to scale accurately – # iterations – Error tolerance CS136 48
Fallacy: Amdahl’s Law Doesn’t Apply to Parallel Computers Since some part linear, can’t go 100X? 1987 claim to break it, since 1000X speedup – Researchers scaled benchmark to have 1000X data set – Then compared uniprocessor and parallel execution times – Sequential portion of program was constant, independent of size of input, and rest was fully parallel » Hence, linear speedup with 1000 processors – Usually, sequential part scales with data CS136 49
Fallacy: Linear Speedups Needed to Make Multiprocessors Cost-Effective David Wood & Mark Hill 1995 study Compare costs of SGI uniprocessor and MP Uniprocessor 38,400 100 * MB MP 81,600 20,000 * P 100 * MB 1 GB, uni 138k v. MP 181k 20k * P What speedup for better MP cost/performance? 8 proc 341k; 341k/138k 2.5X 16 proc need only 3.6X, or 25% of linear speedup Even if need more memory for MP, linear not needed CS136 50
Fallacy: Scalability is Almost Free “Build scalability into a multiprocessor and then simply offer it at any point from a small to a large number of processors” Cray T3E scales to 2048 CPUs vs. 4 CPU Alpha – At 128 CPUs, T3E delivers peak bisection BW of 38.4 GB/s, or 300 MB/s per CPU (uses Alpha microprocessor) – Compaq Alphaserver ES40 has up to 4 CPUs and 5.6 GB/s of interconnect BW, or 1400 MB/s per CPU Building apps that scale requires significantly more attention to: – – – – Load balance Locality Potential contention Serial (or partly parallel) portions of program 10X is very hard CS136 51
Pitfall: Not Developing SW With Multiprocessor in Mind SGI OS protects page-table data structure with single lock – Assumption is that page allocation is infrequent Many programs initialize lots of pages at startup If parallelized, multiple processes/ors allocate pages Single kernel lock then serializes initialization CS136 52
Answers to 1995 Questions About Parallelism In 1995 edition of the text, H&P concluded chapter with discussion of two then-current controversial issues: 1. What architecture would very-large-scale microprocessorbased multiprocessors use? 2. What was role for multiprocessing in future of microprocessor architecture? Answers: 1. Large scale MPs did not become major and growing market » Clusters of single microprocessors or moderate SMPs 2. For at least next 5 years, MPU performance will come from TLP via multicore processors, not more ILP CS136 53
Cautionary Tale Key to success of ILP in ‘80s and ‘90s was software, i.e. optimizing compilers that could exploit it Similarly, successful exploitation of TLP will depend as much on development of software systems as on contributions of computer architects – I.e., take Compilers! Given slow progress on parallel software in past 30 years, exploiting TLP effectively will almost certainly remain huge challenge for many years CS136 54
And in Conclusion Snooping and directory protocols similar – Bus makes snooping easier because of broadcast Directory has extra data structure to track state of all cache blocks Distributing directory Scalable shared-address multiprocessor Cache-coherent, Non-Uniform Memory Access MPs highly effective for multiprogrammed workloads MPs proved effective for intensive commercial workloads – OLTP (assuming enough I/O to be CPU-limited) – DSS applications (query optimization is critical) – Large-scale web searching applications CS136 55





