CS 388: Natural Language Processing: Statistical Parsing Raymond





































51 Slides1.06 MB
CS 388: Natural Language Processing: Statistical Parsing Raymond J. Mooney University of Texas at Austin 1
Statistical Parsing Statistical parsing uses a probabilistic model of syntax in order to assign probabilities to each parse tree. Provides principled approach to resolving syntactic ambiguity. Allows supervised learning of parsers from treebanks of parse trees provided by human linguists. Also allows unsupervised learning of parsers from unannotated text, but the accuracy of such parsers has been limited. 2
Probabilistic Context Free Grammar (PCFG) A PCFG is a probabilistic version of a CFG where each production has a probability. Probabilities of all productions rewriting a given non-terminal must add to 1, defining a distribution for each non-terminal. String generation is now probabilistic where production probabilities are used to nondeterministically select a production for rewriting a given non-terminal. 3
Simple PCFG for ATIS English Grammar S NP VP S Aux NP VP S VP NP Pronoun NP Proper-Noun NP Det Nominal Nominal Noun Nominal Nominal Noun Nominal Nominal PP VP Verb VP Verb NP VP VP PP PP Prep NP Prob 0.8 0.1 0.1 0.2 0.2 0.6 0.3 0.2 0.5 0.2 0.5 0.3 1.0 1.0 1.0 1.0 1.0 Lexicon Det the a that this 0.6 0.2 0.1 0.1 Noun book flight meal money 0.1 0.5 0.2 0.2 Verb book include prefer 0.5 0.2 0.3 Pronoun I he she me 0.5 0.1 0.1 0.3 Proper-Noun Houston NWA 0.8 0.2 Aux does 1.0 Prep from to on near through 0.25 0.25 0.1 0.2 0.2
Sentence Probability Assume productions for each node are chosen independently. Probability of derivation is the product of the probabilities of its productions. P(D1) 0.1 x 0.5 x 0.5 x 0.6 x 0.6 x S D1 0.1 0.5 x 0.3 x 1.0 x 0.2 x 0.2 x VP 0.5 0.5 x 0.8 Verb NP 0.6 0.5 0.0000216 book Det Nominal 0.5 0.6 the Nominal PP 1.0 0.3 NP 0.2 Noun Prep 0.2 0.5 flight through Proper-Noun 0.8 Houston 5
Syntactic Disambiguation Resolve ambiguity by picking most probable parse tree. S D2 P(D2) 0.1 x 0.3 x 0.5 x 0.6 x 0.5 x 0.1 VP 0.6 x 0.3 x 1.0 x 0.5 x 0.2 x 0.3 VP 0.5 0.2 x 0.8 Verb NP0.6 0.00001296 0.5 book PP Det Nominal 1.0 0.6 0.3 NP 0.2 the Noun 0.2Prep 0.5 flight through Proper-Noun 0.8 Houston 6
Sentence Probability Probability of a sentence is the sum of the probabilities of all of its derivations. P(“book the flight through Houston”) P(D1) P(D2) 0.0000216 0.00001296 0.00003456 7
Three Useful PCFG Tasks Observation likelihood: To classify and order sentences. Most likely derivation: To determine the most likely parse tree for a sentence. Maximum likelihood training: To train a PCFG to fit empirical training data. 8
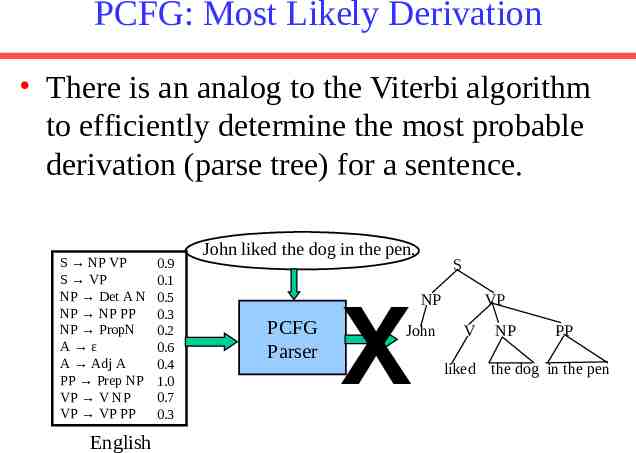
PCFG: Most Likely Derivation There is an analog to the Viterbi algorithm to efficiently determine the most probable derivation (parse tree) for a sentence. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 John liked the dog in the pen. PCFG Parser X S NP John VP V NP PP liked the dog in the pen
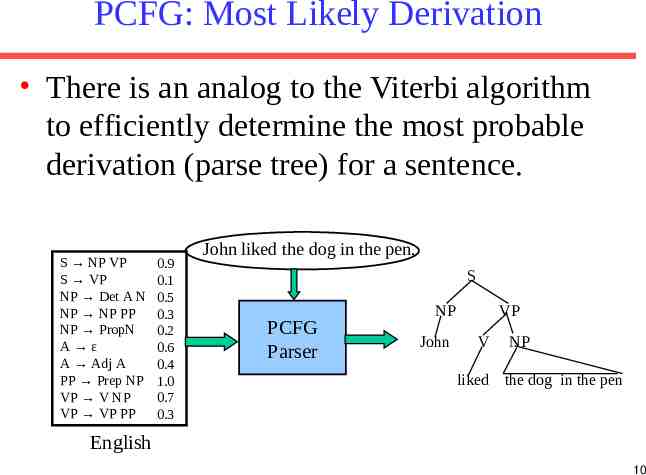
PCFG: Most Likely Derivation There is an analog to the Viterbi algorithm to efficiently determine the most probable derivation (parse tree) for a sentence. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 John liked the dog in the pen. S PCFG Parser NP John VP V NP liked the dog in the pen English 10
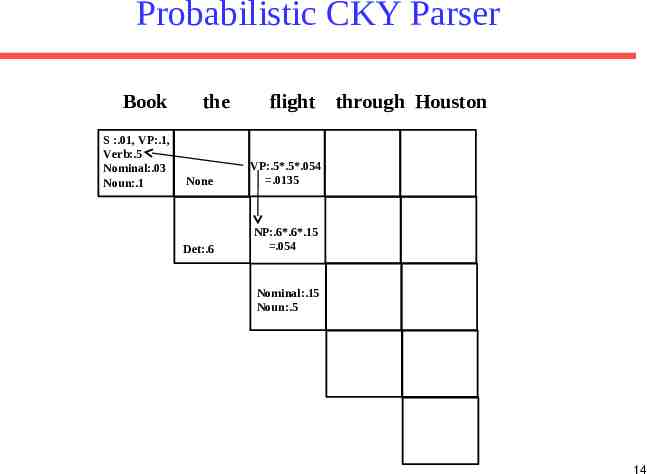
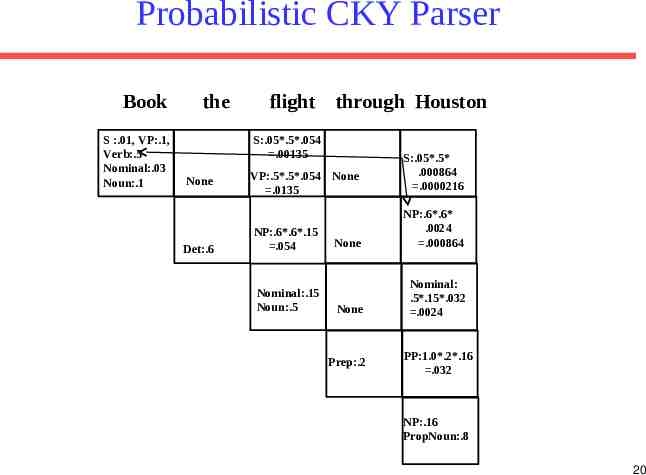
Probabilistic CKY CKY can be modified for PCFG parsing by including in each cell a probability for each non-terminal. Cell[i,j] must retain the most probable derivation of each constituent (nonterminal) covering words i 1 through j together with its associated probability. When transforming the grammar to CNF, must set production probabilities to preserve the probability of derivations.
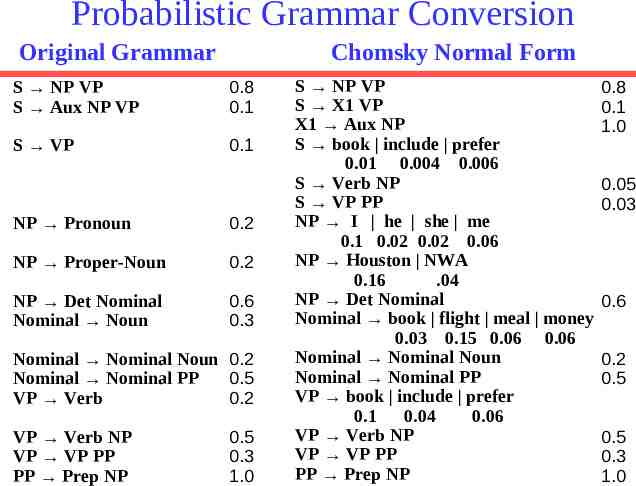
Probabilistic Grammar Conversion Original Grammar Chomsky Normal Form S NP VP S Aux NP VP 0.8 0.1 S VP 0.1 NP Pronoun 0.2 NP Proper-Noun 0.2 NP Det Nominal Nominal Noun 0.6 0.3 Nominal Nominal Noun 0.2 Nominal Nominal PP 0.5 VP Verb 0.2 VP Verb NP VP VP PP PP Prep NP 0.5 0.3 1.0 S NP VP S X1 VP X1 Aux NP S book include prefer 0.01 0.004 0.006 S Verb NP S VP PP NP I he she me 0.1 0.02 0.02 0.06 NP Houston NWA 0.16 .04 NP Det Nominal Nominal book flight meal money 0.03 0.15 0.06 0.06 Nominal Nominal Noun Nominal Nominal PP VP book include prefer 0.1 0.04 0.06 VP Verb NP VP VP PP PP Prep NP 0.8 0.1 1.0 0.05 0.03 0.6 0.2 0.5 0.5 0.3 1.0
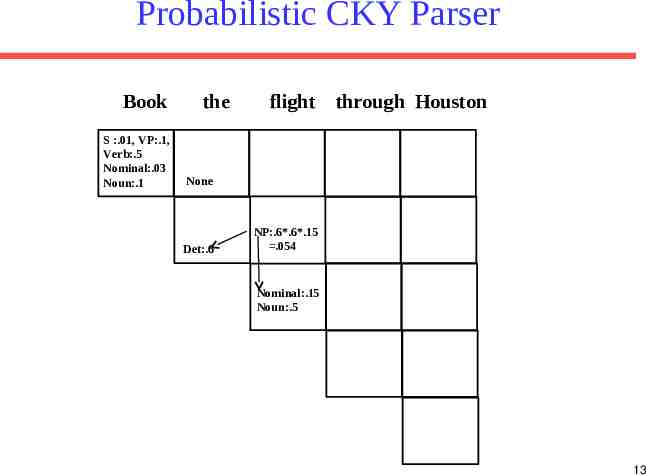
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston None Det:.6 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 13
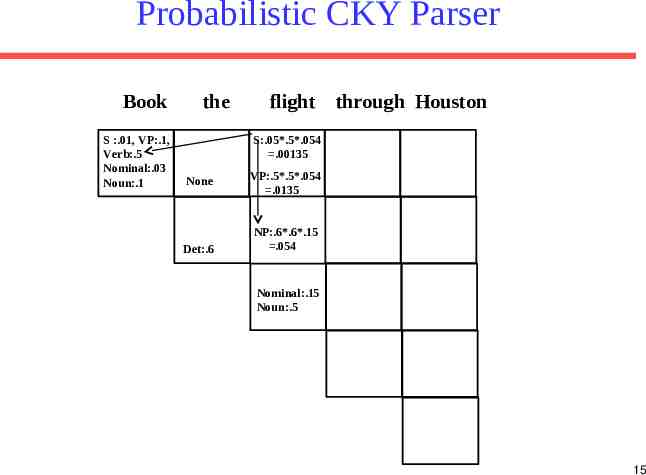
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight None VP:.5*.5*.054 .0135 Det:.6 NP:.6*.6*.15 .054 through Houston Nominal:.15 Noun:.5 14
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 15
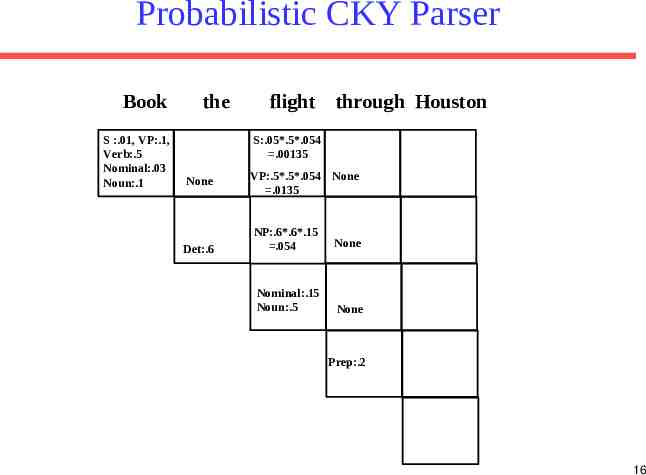
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 None Nominal:.15 Noun:.5 None Prep:.2 16
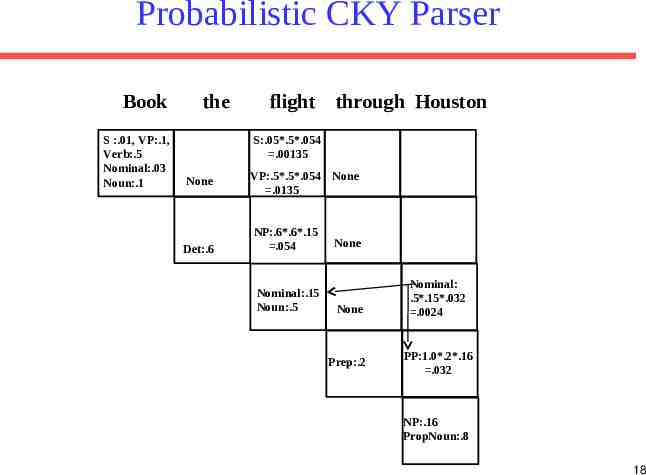
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 None Nominal:.15 Noun:.5 None Prep:.2 PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 17
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 None None Prep:.2 Nominal: .5*.15*.032 .0024 PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 18
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 None NP:.6*.6* .0024 .000864 None Nominal: .5*.15*.032 .0024 Prep:.2 PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 19
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 S:.05*.5* .000864 .0000216 None NP:.6*.6* .0024 .000864 None Nominal: .5*.15*.032 .0024 Prep:.2 PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 20
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 S:.03*.0135* .032 .00001296 S:.0000216 None NP:.6*.6* .0024 .000864 None Nominal: .5*.15*.032 .0024 Prep:.2 PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 21
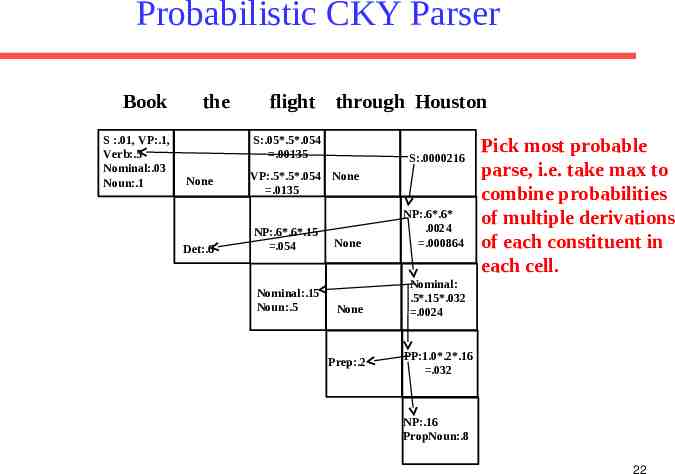
Probabilistic CKY Parser Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 S:.0000216 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 None NP:.6*.6* .0024 .000864 None Nominal: .5*.15*.032 .0024 Prep:.2 Pick most probable parse, i.e. take max to combine probabilities of multiple derivations of each constituent in each cell. PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 22
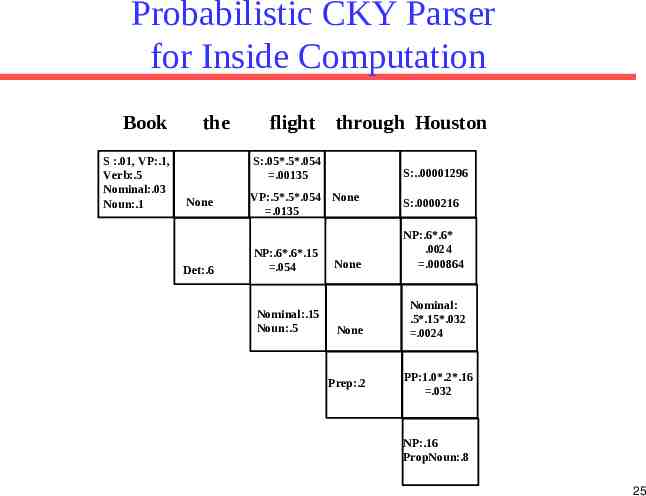
PCFG: Observation Likelihood There is an analog to Forward algorithm for HMMs called the Inside algorithm for efficiently determining how likely a string is to be produced by a PCFG. Can use a PCFG as a language model to choose between alternative sentences for speech recognition or machine translation. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 O1 ? The dog big barked. ? The big dog barked O2 P(O2 English) P(O1 English) ? 23
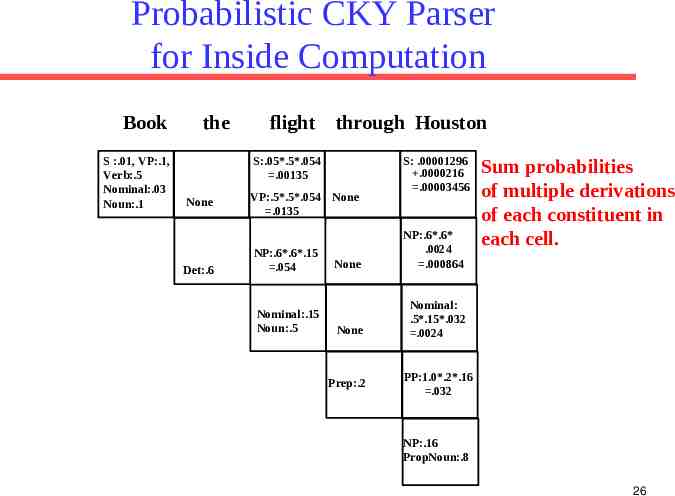
Inside Algorithm Use CKY probabilistic parsing algorithm but combine probabilities of multiple derivations of any constituent using addition instead of max. 24
Probabilistic CKY Parser for Inside Computation Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the None Det:.6 flight through Houston S:.05*.5*.054 .00135 S:.00001296 VP:.5*.5*.054 None .0135 S:.0000216 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 None NP:.6*.6* .0024 .000864 None Nominal: .5*.15*.032 .0024 Prep:.2 PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 25
Probabilistic CKY Parser for Inside Computation Book S :.01, VP:.1, Verb:.5 Nominal:.03 Noun:.1 the flight through Houston S:.05*.5*.054 .00135 None Det:.6 VP:.5*.5*.054 None .0135 NP:.6*.6*.15 .054 Nominal:.15 Noun:.5 S: .00001296 .0000216 .00003456 None NP:.6*.6* .0024 .000864 None Nominal: .5*.15*.032 .0024 Prep:.2 Sum probabilities of multiple derivations of each constituent in each cell. PP:1.0*.2*.16 .032 NP:.16 PropNoun:.8 26
PCFG: Supervised Training If parse trees are provided for training sentences, a grammar and its parameters can be can all be estimated directly from counts accumulated from the tree-bank (with appropriate smoothing). Tree Bank S NP VP John V put NP PP the dog in the pen S NP John VP V put NP PP the dog in the pen . . . Supervised PCFG Training S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 English 27
Estimating Production Probabilities Set of production rules can be taken directly from the set of rewrites in the treebank. Parameters can be directly estimated from frequency counts in the treebank. count( ) count( ) P ( ) count( ) count( ) 28
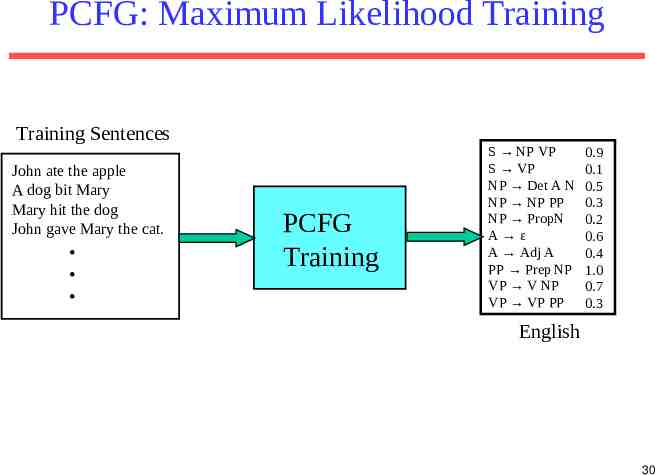
PCFG: Maximum Likelihood Training Given a set of sentences, induce a grammar that maximizes the probability that this data was generated from this grammar. Assume the number of non-terminals in the grammar is specified. Only need to have an unannotated set of sequences generated from the model. Does not need correct parse trees for these sentences. In this sense, it is unsupervised. 29
PCFG: Maximum Likelihood Training Training Sentences John ate the apple A dog bit Mary Mary hit the dog John gave Mary the cat. . . . PCFG Training S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 English 30
Inside-Outside The Inside-Outside algorithm is a version of EM for unsupervised learning of a PCFG. – Analogous to Baum-Welch (forward-backward) for HMMs Given the number of non-terminals, construct all possible CNF productions with these non-terminals and observed terminal symbols. Use EM to iteratively train the probabilities of these productions to locally maximize the likelihood of the data. – See Manning and Schütze text for details Experimental results are not impressive, but recent work imposes additional constraints to improve unsupervised grammar learning.
Vanilla PCFG Limitations Since probabilities of productions do not rely on specific words or concepts, only general structural disambiguation is possible (e.g. prefer to attach PPs to Nominals). Consequently, vanilla PCFGs cannot resolve syntactic ambiguities that require semantics to resolve, e.g. ate with fork vs. meatballs. In order to work well, PCFGs must be lexicalized, i.e. productions must be specialized to specific words by including their head-word in their LHS non-terminals (e.g. VP-ate). 32
Example of Importance of Lexicalization A general preference for attaching PPs to NPs rather than VPs can be learned by a vanilla PCFG. But the desired preference can depend on specific words. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 John put the dog in the pen. S NP PCFG Parser John VP V NP PP put the dog in the pen 33
Example of Importance of Lexicalization A general preference for attaching PPs to NPs rather than VPs can be learned by a vanilla PCFG. But the desired preference can depend on specific words. S NP VP S VP NP Det A N NP NP PP NP PropN A ε A Adj A PP Prep NP VP V NP VP VP PP English 0.9 0.1 0.5 0.3 0.2 0.6 0.4 1.0 0.7 0.3 John put the dog in the pen. PCFG Parser X S NP John VP V NP put the dog in the pen 34
Head Words Syntactic phrases usually have a word in them that is most “central” to the phrase. Linguists have defined the concept of a lexical head of a phrase. Simple rules can identify the head of any phrase by percolating head words up the parse tree. – – – – Head of a VP is the main verb Head of an NP is the main noun Head of a PP is the preposition Head of a sentence is the head of its VP
Lexicalized Productions Specialized productions can be generated by including the head word and its POS of each nonterminal as part of that non-terminal’s symbol. Sliked-VBD NPJohn-NNP NNP John VP liked-VBD VBD liked NPdog-NN DT Nominaldog-NN Nominaldog-NN PPin-IN Nominal dog-NN PPin-IN the Nominal dog-NN NN IN dog in NPpen-NN DT the Nominalpen-NN NN pen
Lexicalized Productions Sput-VBD NPJohn-NNP VP put-VBD VPput-VBD VPput-VBD PPin-IN VPput-VBD NNP John VBD put PP in-IN NPdog-NN DT the Nominal IN dog-NN NN dog in NPpen-NN DT the Nominalpen-NN NN pen
Parameterizing Lexicalized Productions Accurately estimating parameters on such a large number of very specialized productions could require enormous amounts of treebank data. Need some way of estimating parameters for lexicalized productions that makes reasonable independence assumptions so that accurate probabilities for very specific rules can be learned. Collins (1999) introduced one approach to learning effective parameters for a lexicalized grammar.
Treebanks English Penn Treebank: Standard corpus for testing syntactic parsing consists of 1.2 M words of text from the Wall Street Journal (WSJ). Typical to train on about 40,000 parsed sentences and test on an additional standard disjoint test set of 2,416 sentences. Chinese Penn Treebank: 100K words from the Xinhua news service. Other corpora existing in many languages, see the Wikipedia article “Treebank” 39
First WSJ Sentence ( (S (NP-SBJ (NP (NNP Pierre) (NNP Vinken) ) (, ,) (ADJP (NP (CD 61) (NNS years) ) (JJ old) ) (, ,) ) (VP (MD will) (VP (VB join) (NP (DT the) (NN board) ) (PP-CLR (IN as) (NP (DT a) (JJ nonexecutive) (NN director) )) (NP-TMP (NNP Nov.) (CD 29) ))) (. .) )) 40
Parsing Evaluation Metrics PARSEVAL metrics measure the fraction of the constituents that match between the computed and human parse trees. If P is the system’s parse tree and T is the human parse tree (the “gold standard”): – Recall (# correct constituents in P) / (# constituents in T) – Precision (# correct constituents in P) / (# constituents in P) Labeled Precision and labeled recall require getting the non-terminal label on the constituent node correct to count as correct. F1 is the harmonic mean of precision and recall. 41
Computing Evaluation Metrics Correct Tree T Computed Tree P S S VP Verb book VP NP Det VP Nominal the Nominal Noun Verb PP Prep book NP flight through Proper-Noun NP Det Nominal Noun the flight PP Prep through Proper-Noun Houston # Constituents: 12 NP Houston # Constituents: 12 # Correct Constituents: 10 Recall 10/12 83.3% Precision 10/12 83.3% F1 83.3%
Treebank Results Results of current state-of-the-art systems on the English Penn WSJ treebank are 91-92% labeled F1. 43
Human Parsing Computational parsers can be used to predict human reading time as measured by tracking the time taken to read each word in a sentence. Psycholinguistic studies show that words that are more probable given the preceding lexical and syntactic context are read faster. – John put the dog in the pen with a lock. – John put the dog in the pen with a bone in the car. – John liked the dog in the pen with a bone. Modeling these effects requires an incremental statistical parser that incorporates one word at a time into a continuously growing parse tree. 44
Garden Path Sentences People are confused by sentences that seem to have a particular syntactic structure but then suddenly violate this structure, so the listener is “lead down the garden path”. – The horse raced past the barn fell. vs. The horse raced past the barn broke his leg. – The complex houses married students. – The old man the sea. – While Anna dressed the baby spit up on the bed. Incremental computational parsers can try to predict and explain the problems encountered parsing such sentences. 45
Center Embedding Nested expressions are hard for humans to process beyond 1 or 2 levels of nesting. – The rat the cat chased died. – The rat the cat the dog bit chased died. – The rat the cat the dog the boy owned bit chased died. Requires remembering and popping incomplete constituents from a stack and strains human short-term memory. Equivalent “tail embedded” (tail recursive) versions are easier to understand since no stack is required. – The boy owned a dog that bit a cat that chased a rat that died. 46
Dependency Grammars An alternative to phrase-structure grammar is to define a parse as a directed graph between the words of a sentence representing dependencies between the words. liked nsubj John Typed dependency parse liked dog the John in pen dobj det dog the in pen the det the 47
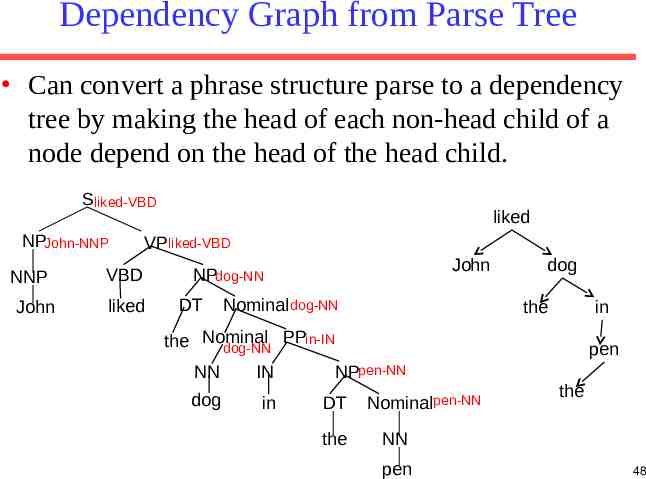
Dependency Graph from Parse Tree Can convert a phrase structure parse to a dependency tree by making the head of each non-head child of a node depend on the head of the head child. Sliked-VBD NPJohn-NNP NNP John liked VP liked-VBD VBD liked John NPdog-NN DT Nominal dog-NN dog the in PPin-IN the Nominal dog-NN NN IN dog in pen NPpen-NN DT the Nominalpen-NN the NN pen 48
Unification Grammars In order to handle agreement issues more effectively, each constituent has a list of features such as number, person, gender, etc. which may or not be specified for a given constituent. In order for two constituents to combine to form a larger constituent, their features must unify, i.e. consistently combine into a merged set of features. Expressive grammars and parsers (e.g. HPSG) have been developed using this approach and have been partially integrated with modern statistical models of disambiguation. 49
Mildly Context-Sensitive Grammars Some grammatical formalisms provide a degree of context-sensitivity that helps capture aspects of NL syntax that are not easily handled by CFGs. Tree Adjoining Grammar (TAG) is based on combining tree fragments rather than individual phrases. Combinatory Categorial Grammar (CCG) consists of: – Categorial Lexicon that associates a syntactic and semantic category with each word. – Combinatory Rules that define how categories combine to form other categories. 50
Statistical Parsing Conclusions Statistical models such as PCFGs allow for probabilistic resolution of ambiguities. PCFGs can be easily learned from treebanks. Lexicalization and non-terminal splitting are required to effectively resolve many ambiguities. Current statistical parsers are quite accurate but not yet at the level of human-expert agreement. 51






