CrossFS: A Cross-layered DirectAccess File System Yujie Ren1, Changwoo










28 Slides4.65 MB
CrossFS: A Cross-layered DirectAccess File System Yujie Ren1, Changwoo Min2, and Sudarsun Kannan1 1 Rutgers University; 2 Virginia Tech
Outline Background Motivation Design Evaluation Conclusion 2
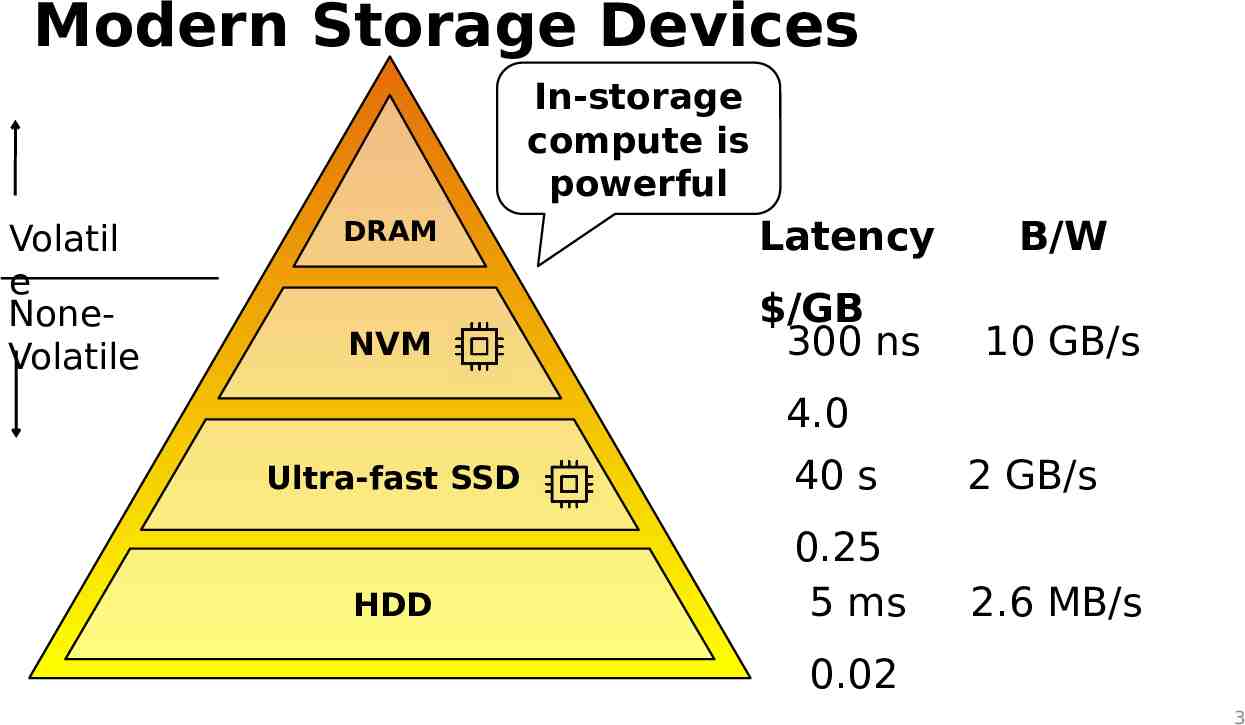
Modern Storage Devices In-storage compute is powerful Volatil e NoneVolatile DRAM Latency B/W NVM /GB 300 ns 10 GB/s 4.0 Ultra-fast SSD HDD 40 s 2 GB/s 0.25 5 ms 2.6 MB/s 0.02 3
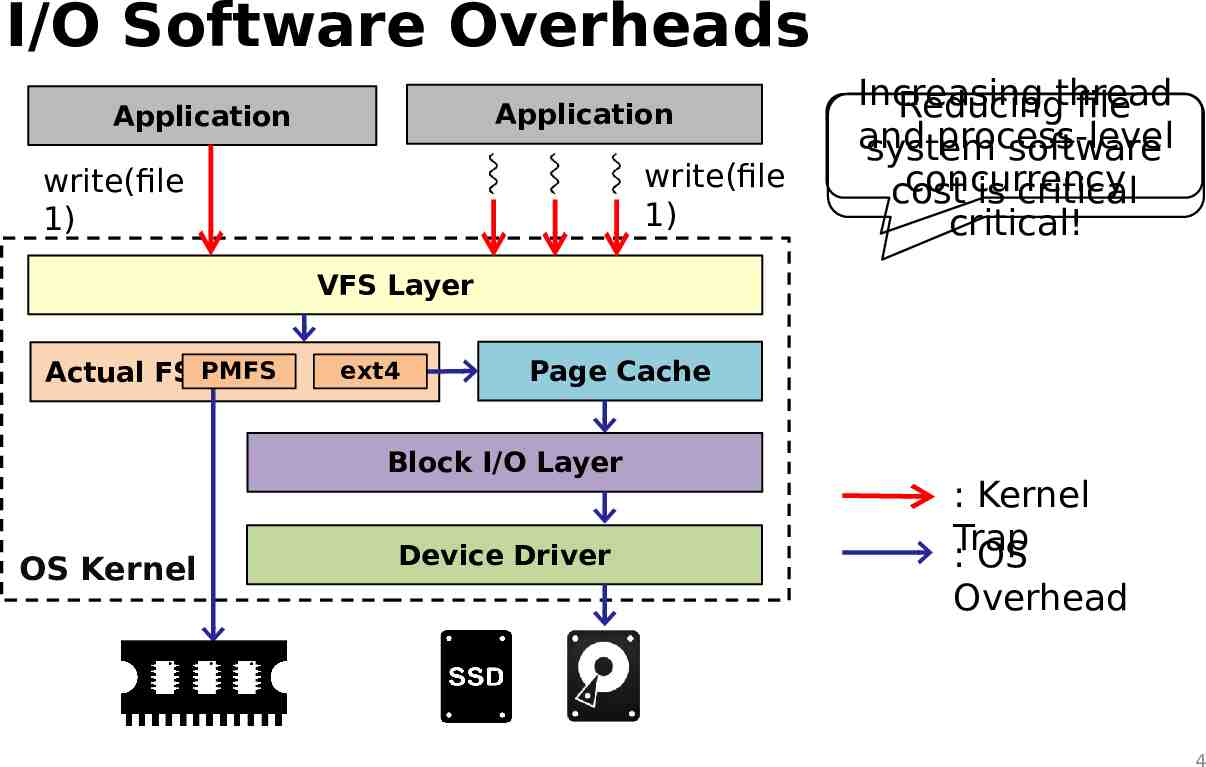
I/O Software Overheads Application Application write(file 1) write(file 1) Increasing Reducingthread file and process-level system software concurrency cost is critical critical! VFS Layer Actual FS PMFS ext4 Page Cache Block I/O Layer OS Kernel Device Driver : Kernel Trap : OS Overhead 4
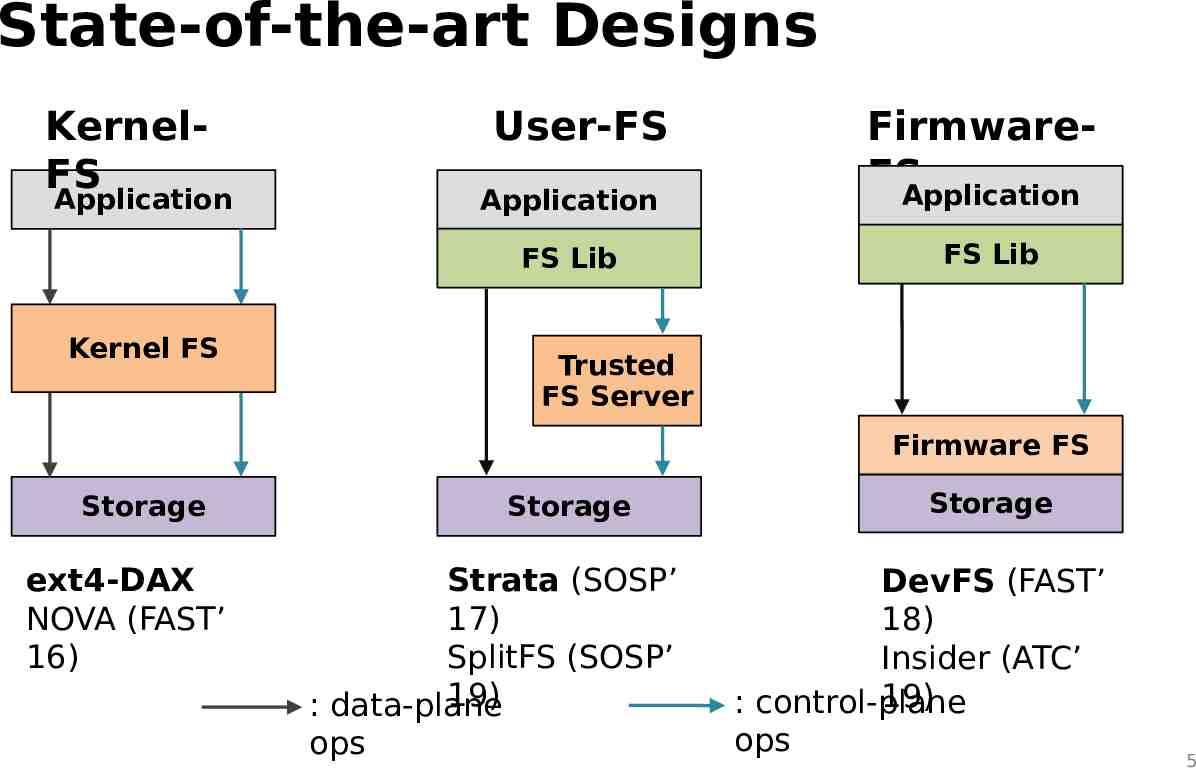
State-of-the-art Designs KernelFS Application User-FS Application FS Lib Kernel FS FirmwareFS Application FS Lib Trusted FS Server Firmware FS Storage ext4-DAX NOVA (FAST’ 16) Storage Strata (SOSP’ 17) SplitFS (SOSP’ 19) : data-plane ops Storage DevFS (FAST’ 18) Insider (ATC’ 19) : control-plane ops 5
Outline Background Motivation Design Evaluation Conclusion 6
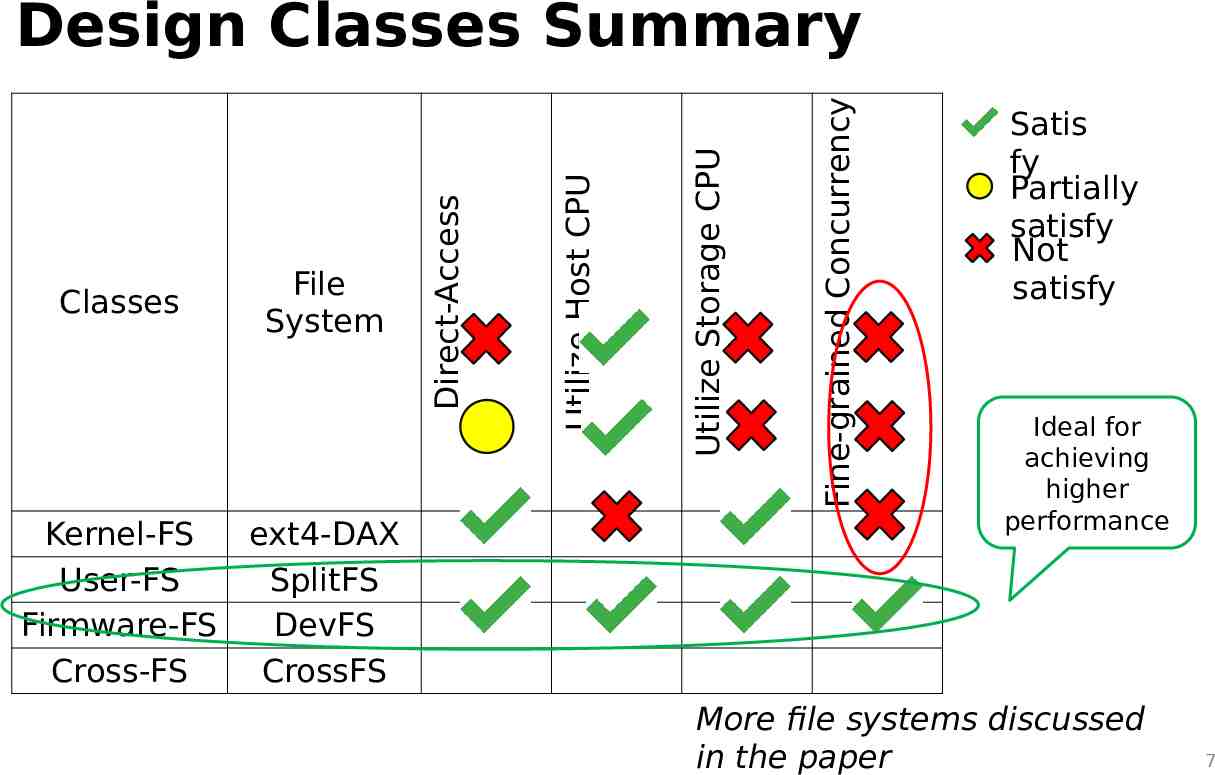
Kernel-FS ext4-DAX User-FS SplitFS Firmware-FS DevFS Cross-FS CrossFS Fine-grained Concurrency Utilize Storage CPU Utilize Host CPU Classes File System Direct-Access Design Classes Summary Satis fy Partially satisfy Not satisfy Ideal for achieving higher performance More file systems discussed in the paper 7
Need for Fine-grained Concurrency Several apps. share files across writers (producers) and readers (consumers) IOR 8
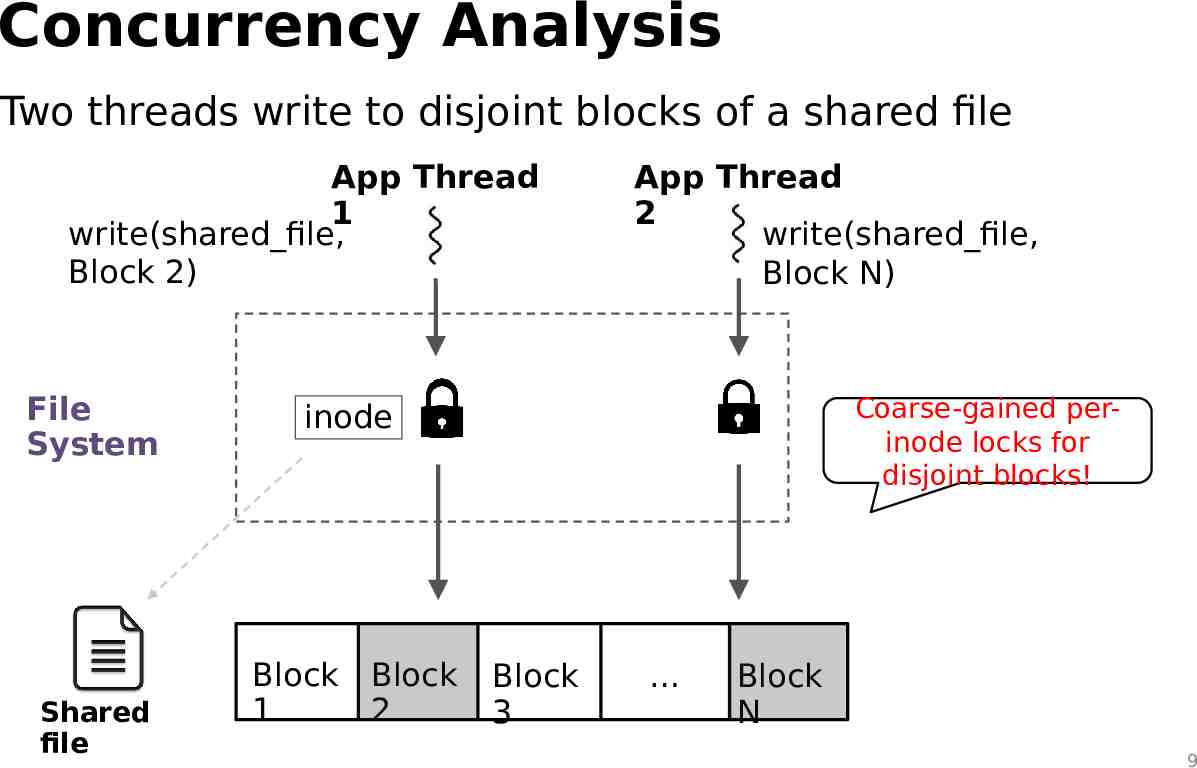
Concurrency Analysis Two threads write to disjoint blocks of a shared file App Thread 1 write(shared file, Block 2) File System Shared file App Thread 2 write(shared file, Block N) Coarse-gained perinode locks for disjoint blocks! inode Block Block 2 1 Block 3 Block N 9
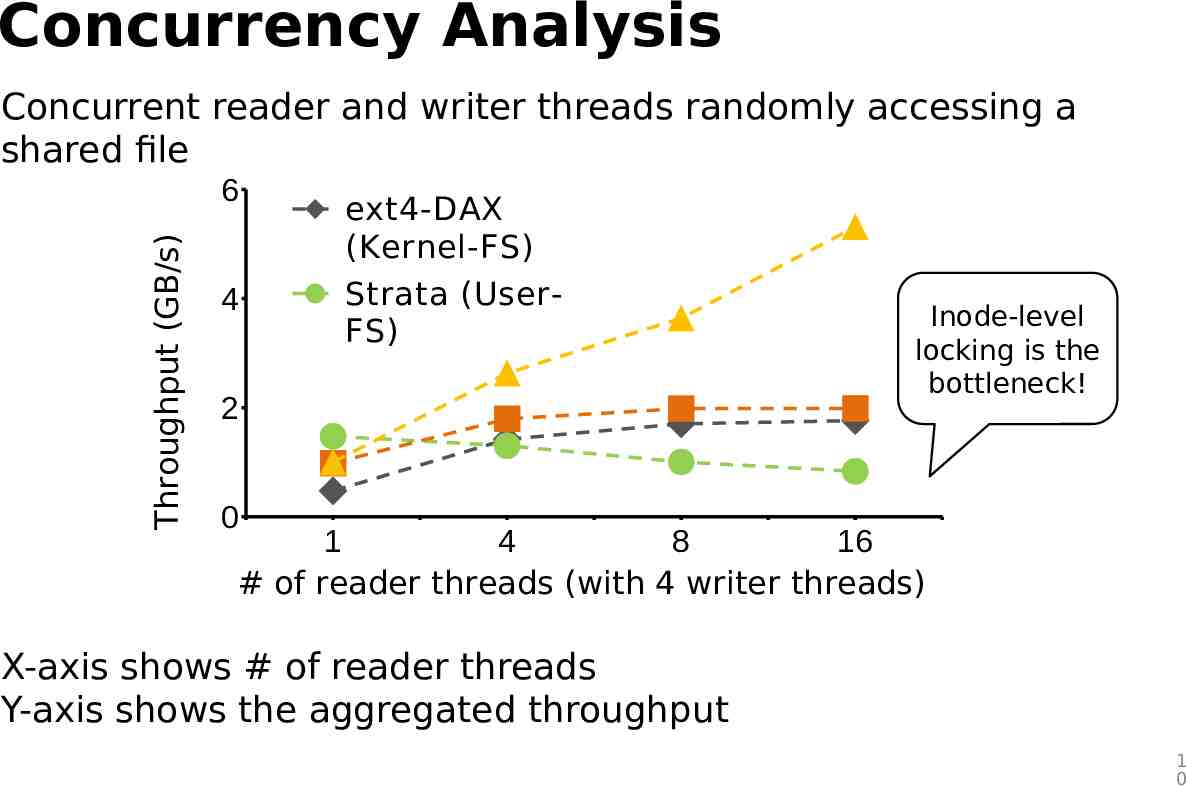
Concurrency Analysis Concurrent reader and writer threads randomly accessing a shared file Throughput (GB/s) 6 4 ext4-DAX (Kernel-FS) Strata (UserFS) 2 Inode-level locking is the bottleneck! 0 1 4 8 16 # of reader threads (with 4 writer threads) X-axis shows # of reader threads Y-axis shows the aggregated throughput 1 0
Outline Background Motivation Design Evaluation Conclusion 1 1
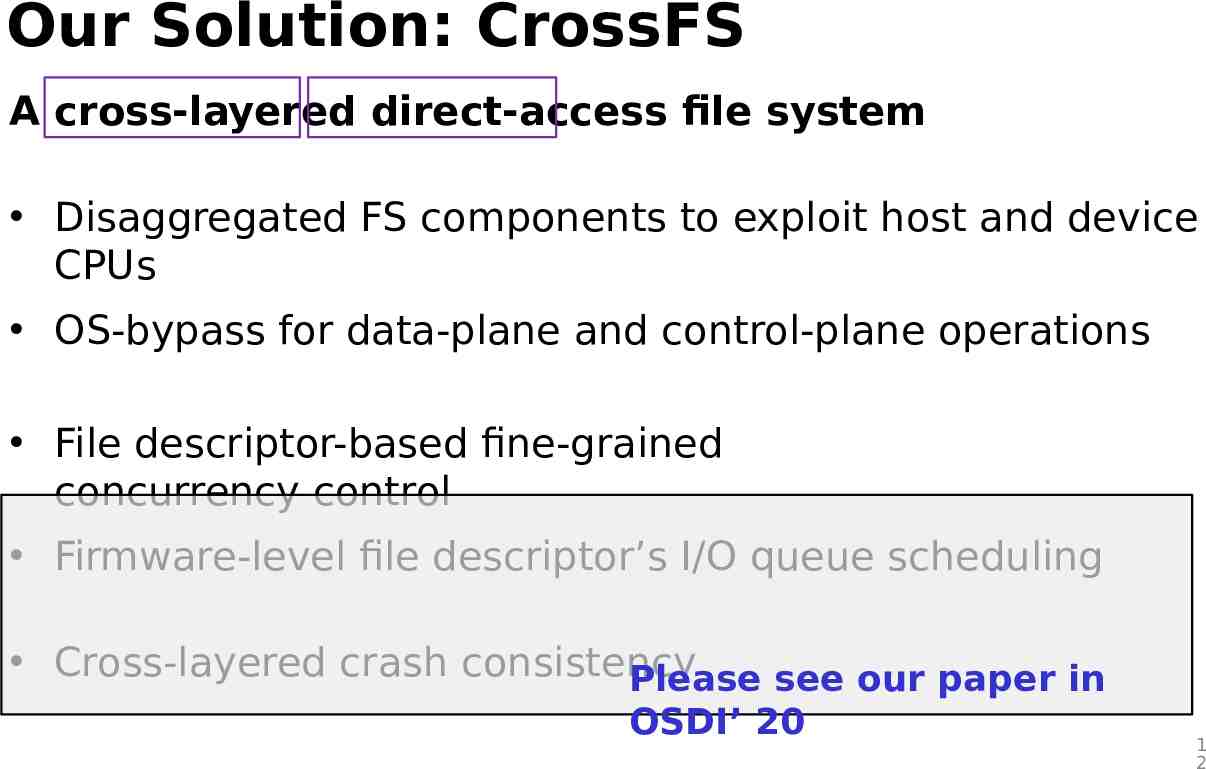
Our Solution: CrossFS A cross-layered direct-access file system Disaggregated FS components to exploit host and device CPUs OS-bypass for data-plane and control-plane operations File descriptor-based fine-grained concurrency control Firmware-level file descriptor’s I/O queue scheduling Cross-layered crash consistency Please see our paper in OSDI’ 20 1 2
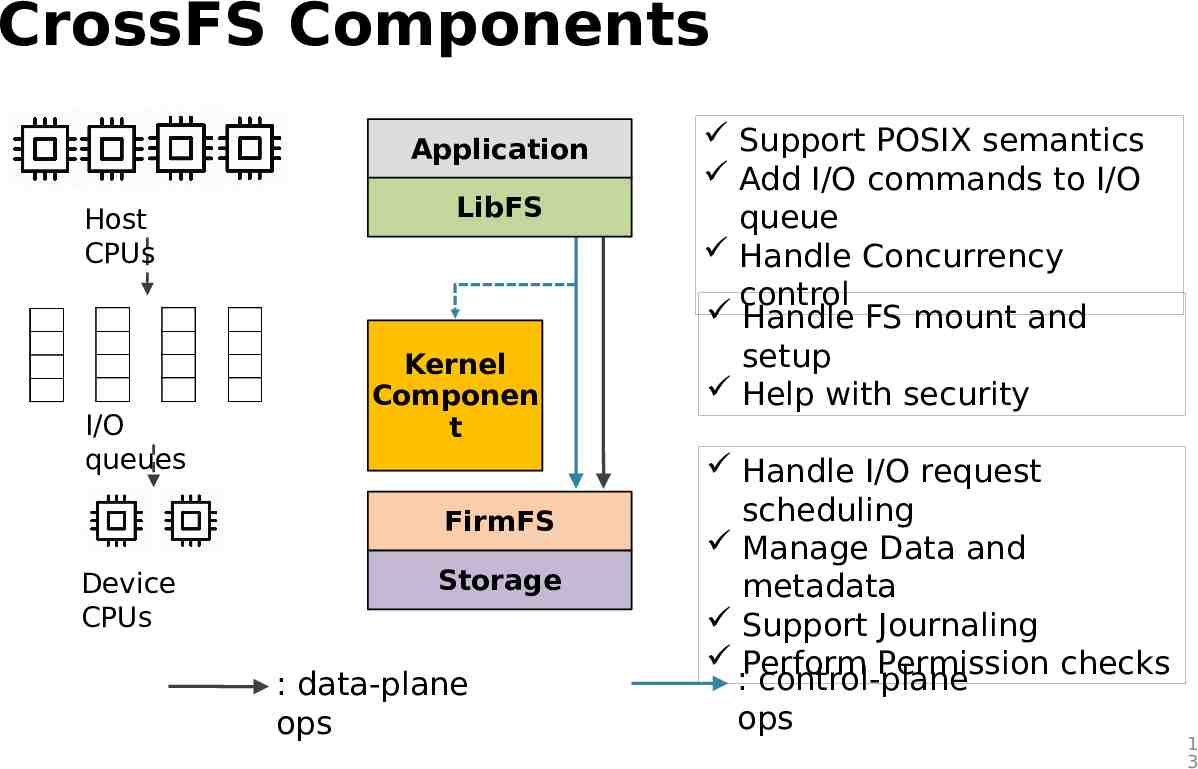
CrossFS Components Application Host CPUs I/O queues LibFS Kernel Componen t FirmFS Device CPUs Storage : data-plane ops Support POSIX semantics Add I/O commands to I/O queue Handle Concurrency control Handle FS mount and setup Help with security Handle I/O request scheduling Manage Data and metadata Support Journaling Perform Permission checks : control-plane ops 1 3
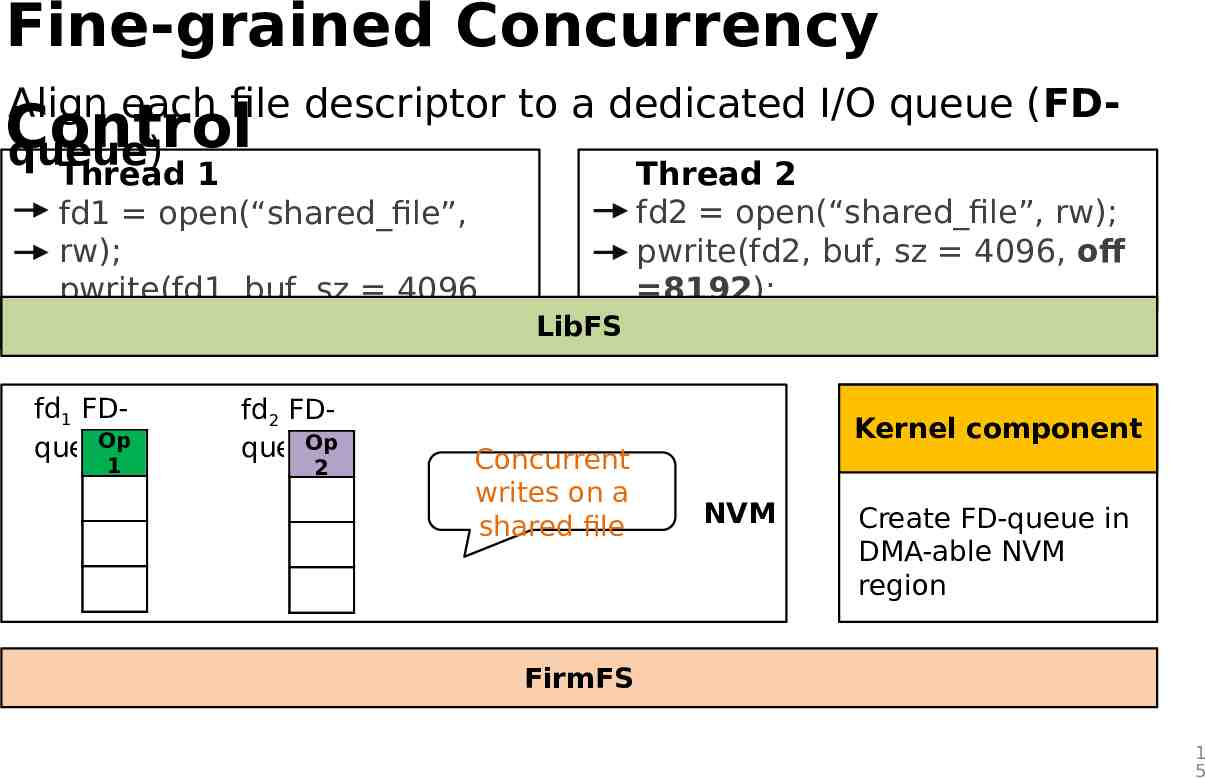
Fine-grained Concurrency Inode-level rw-lock is the bottleneck Control - Even non-overlapping reads and writes are serialized Non-overlapping writes could be parallelized - Different threads could open different file descriptors for a shared file Thread 1 Thread 2 fd1 open(“shared file”, fd2 open(“shared file”, rw); rw); pwrite(fd2, buf, sz 4096, pwrite(fd1, buf, sz 4096, off 8192); File descriptor is a natural concurrency abstraction off 0); - Independent file descriptors for a shared file - Map each file descriptor to an independent hardware I/O queue 1 4
Fine-grained Concurrency Align each file descriptor to a dedicated I/O queue (FDControl queue) Thread 1 fd1 open(“shared file”, rw); pwrite(fd1, buf, sz 4096, off 0); fd1 FDOp queue 1 fd2 FDOp queue 2 Thread 2 fd2 open(“shared file”, rw); pwrite(fd2, buf, sz 4096, off 8192); LibFS Concurrent writes on a shared file Kernel component NVM Create FD-queue in DMA-able NVM region FirmFS 1 5
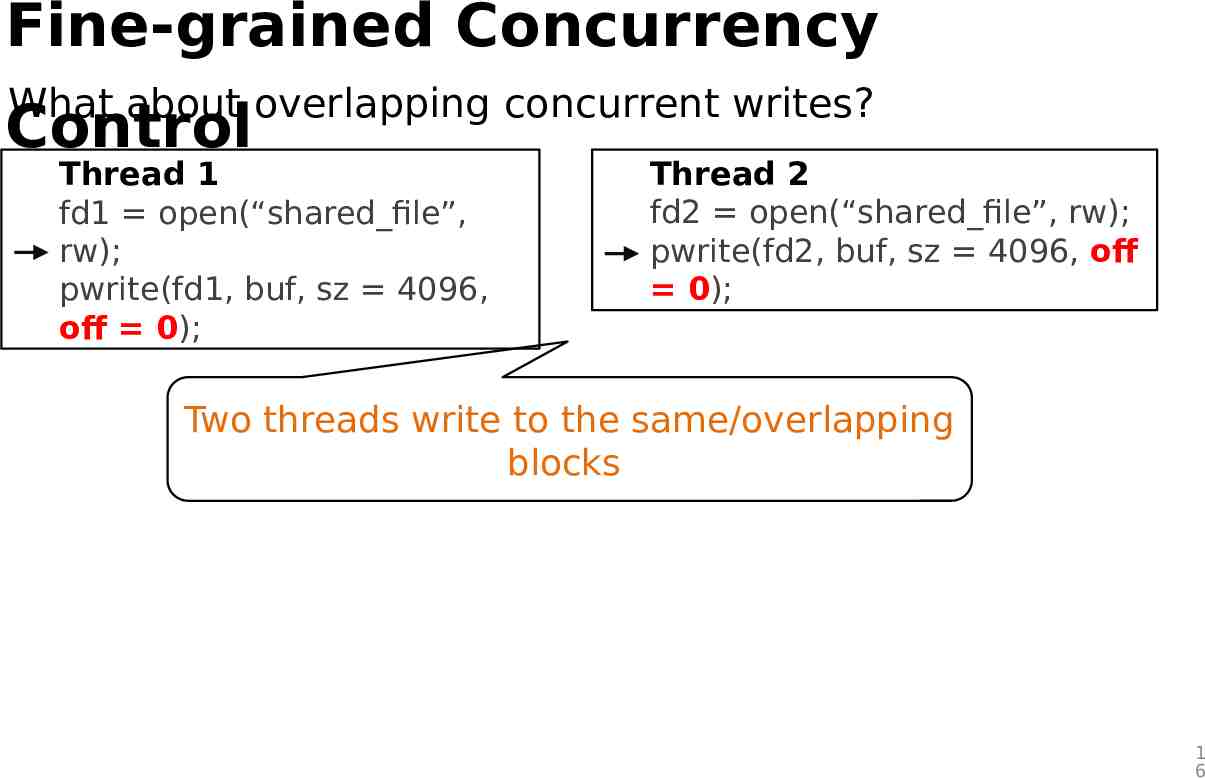
Fine-grained Concurrency What about overlapping concurrent writes? Control Thread 1 fd1 open(“shared file”, rw); pwrite(fd1, buf, sz 4096, off 0); Thread 2 fd2 open(“shared file”, rw); pwrite(fd2, buf, sz 4096, off 0); Two threads write to the same/overlapping blocks 1 6
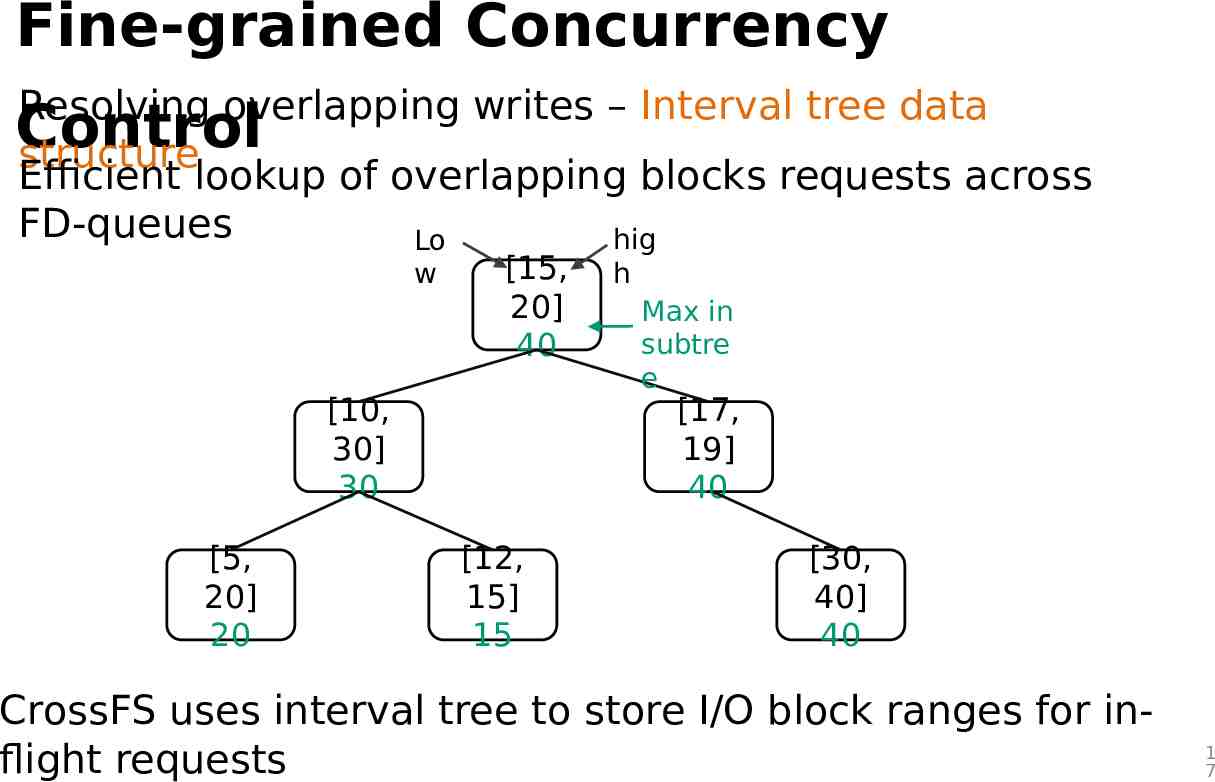
Fine-grained Concurrency Resolving overlapping writes – Interval tree data Control structure Efficient lookup of overlapping blocks requests across FD-queues hig Lo w [15, 20] 40 [10, 30] 30 [5, 20] 20 h Max in subtre e [17, 19] 40 [12, 15] 15 [30, 40] 40 CrossFS uses interval tree to store I/O block ranges for inflight requests 1 7
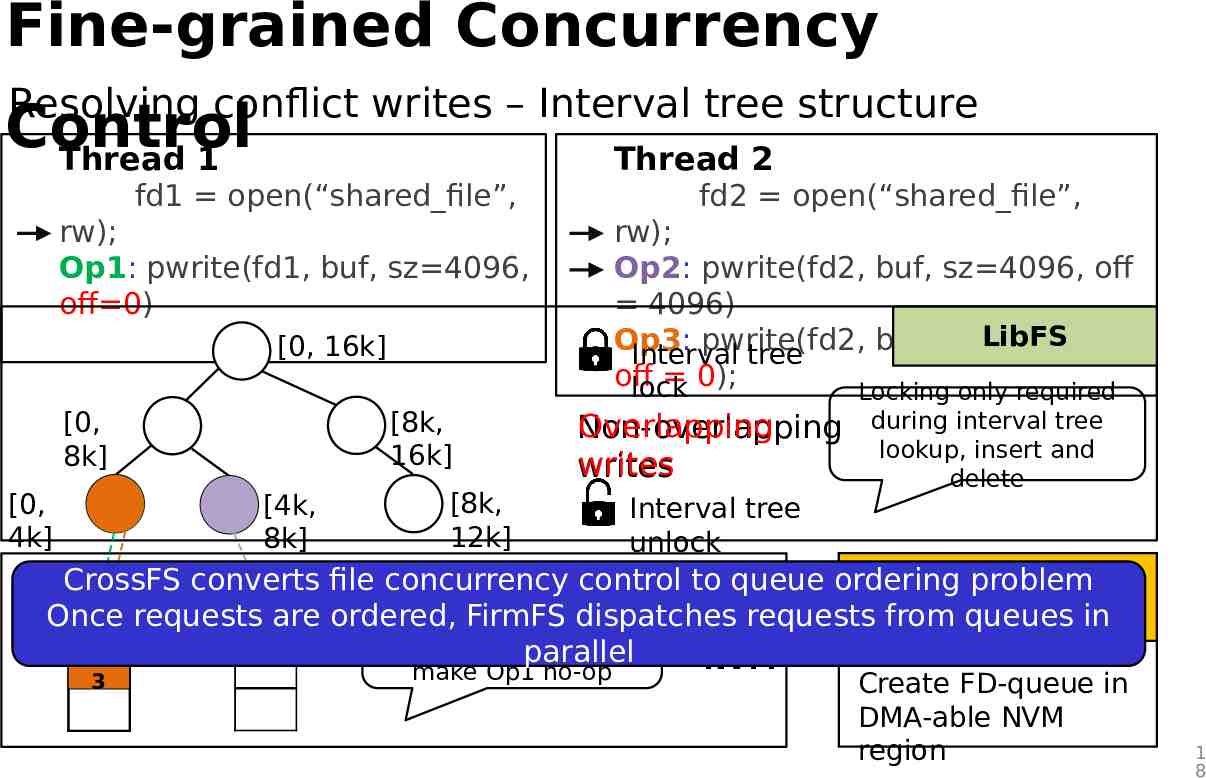
Fine-grained Concurrency Resolving conflict writes – Interval tree structure Control Thread 1 Thread 2 fd1 open(“shared file”, rw); Op1: pwrite(fd1, buf, sz 4096, off 0) [0, 16k] [8k, 16k] [0, 8k] fd2 open(“shared file”, rw); Op2: pwrite(fd2, buf, sz 4096, off 4096) LibFS Op3: pwrite(fd2, buf, sz 4096, Interval tree off 0); lock Locking only required Overlapping Non-overlapping writes during interval tree lookup, insert and delete [8k, [0, [4k, Interval tree 12k] 4k] 8k] unlock fd1 FDfd2 FDCrossFS converts file concurrency control to queue ordering problem Kernel component Opare ordered, Op requests Order Op3 in thedispatches same queue queue Once FirmFS requests from queues in 1 Op 3 2 queue as Op1 and parallel make Op1 no-op NVM Create FD-queue in DMA-able NVM region 1 8
Outline Background Motivation Design Evaluation Conclusion 1 9
Experimental Setup Hardware platform - Dual-socket 64-core Xeon Scalable CPU @ 2.6GHz - 512GB Intel Optane DC NVM Emulate firmware-level FS (no programmable storage H/W) - Reserve dedicated device threads for handling I/O requests - Add PCIe latency for all I/O operations State-of-the-art file systems - Reduce CPU frequency for device CPUs - ext4-DAX, NOVA [FAST’ 16] (Kernel-level file system) - Strata [SOSP ‘17], SplitFS [SOSP’ 19] (User-level file system) - DevFS [FAST’ 18] (Firmware-level file system) 2 0
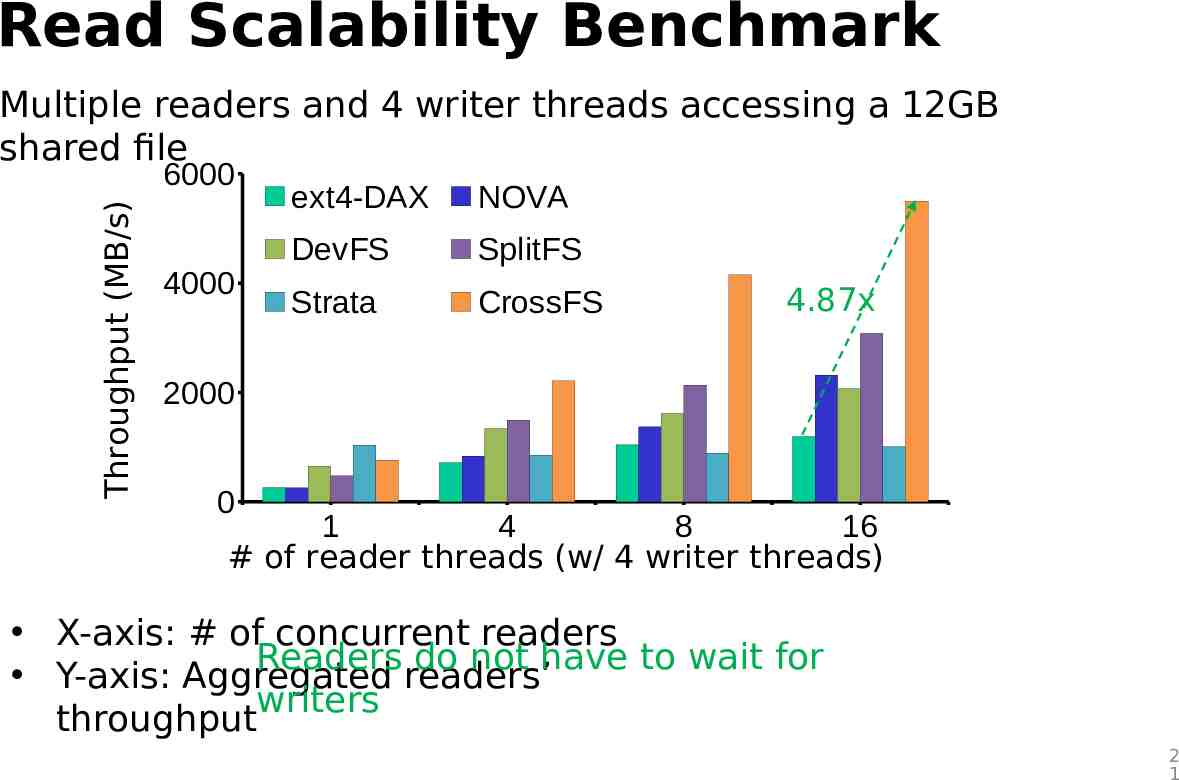
Read Scalability Benchmark Multiple readers and 4 writer threads accessing a 12GB shared file Throughput (MB/s) 6000 4000 ext4-DAX NOVA DevFS SplitFS Strata CrossFS 4.87x 2000 0 1 4 8 16 # of reader threads (w/ 4 writer threads) X-axis: # of concurrent readers Readers do not have to wait for Y-axis: Aggregated readers’ writers throughput 2 1
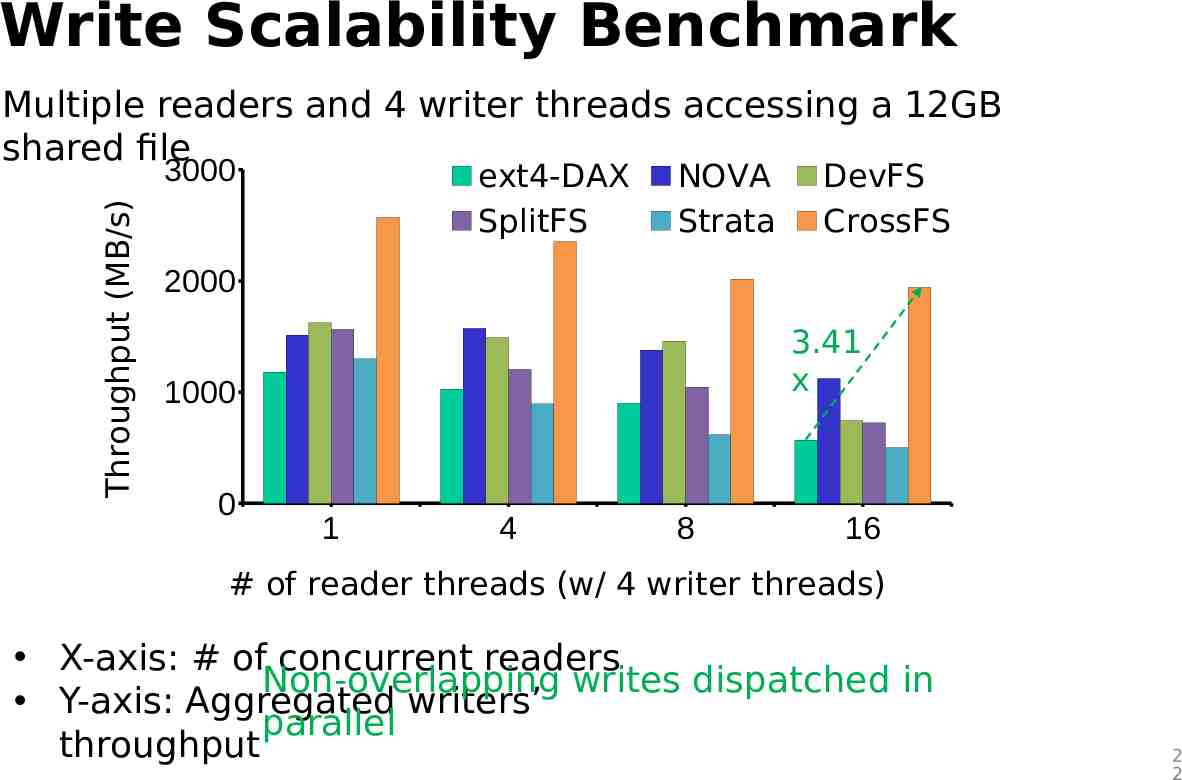
Write Scalability Benchmark Multiple readers and 4 writer threads accessing a 12GB shared file Throughput (MB/s) 3000 ext4-DAX SplitFS NOVA Strata DevFS CrossFS 2000 3.41 x 1000 0 1 4 8 16 # of reader threads (w/ 4 writer threads) X-axis: # of concurrent readers Non-overlapping writes dispatched in Y-axis: Aggregated writers’ parallel throughput 2 2
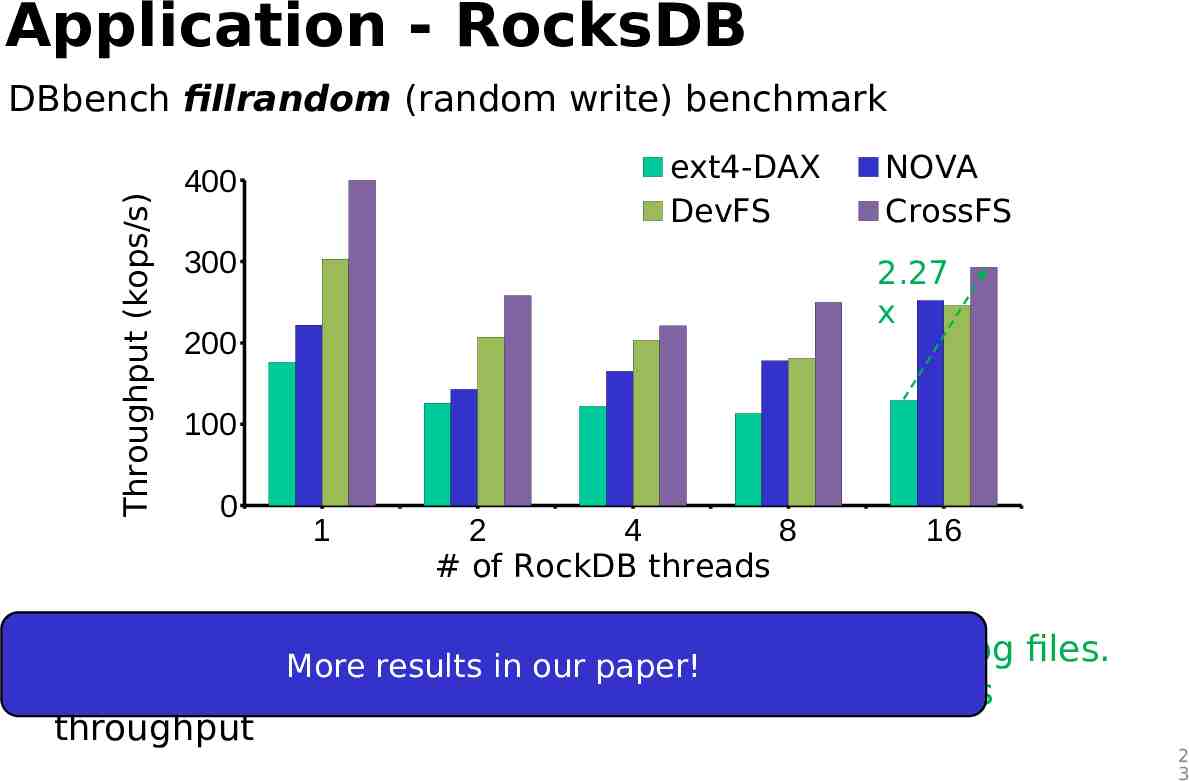
Application - RocksDB Throughput (kops/s) DBbench fillrandom (random write) benchmark ext4-DAX DevFS 400 300 NOVA CrossFS 2.27 x 200 100 0 1 2 4 8 # of RockDB threads 16 X-axis: # of DBbench threads - RocksDB threads append kv-pairs to shared log files. More results in our paper! Y-axis: fillrandom benchmark - CrossFS eliminates inode-level lock overheads throughput 2 3
Conclusion Storage hardware (with compute capability) has reached the microsecond era Providing direct I/O and utilizing host and storage-level compute is critical Our approach: Cross-layered storage file system design Fine grained concurrency control is important for I/O scalability - Our approach: File-descriptor concurrency control Future work: - H/W integration, support for sophisticated scheduling policies, other file system operations (e.g., mmap()) Thanks! https://github.com/RutgersCSSystems/ CrossFS [email protected] 2 4
Backup 2 5
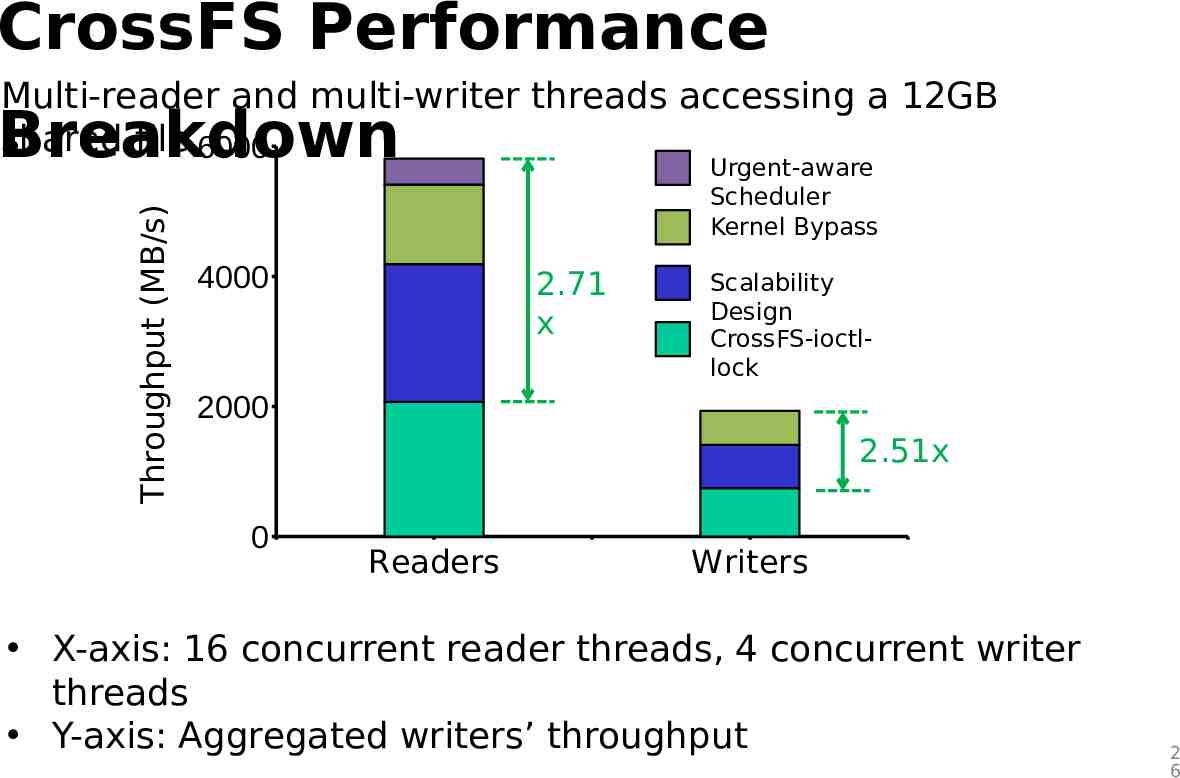
CrossFS Performance Multi-reader and multi-writer threads accessing a 12GB shared file 6000 Throughput (MB/s) Breakdown 4000 Urgent-aware Scheduler Kernel Bypass 2.71 x Scalability Design CrossFS-ioctllock 2000 2.51x 0 Readers Writers X-axis: 16 concurrent reader threads, 4 concurrent writer threads Y-axis: Aggregated writers’ throughput 2 6
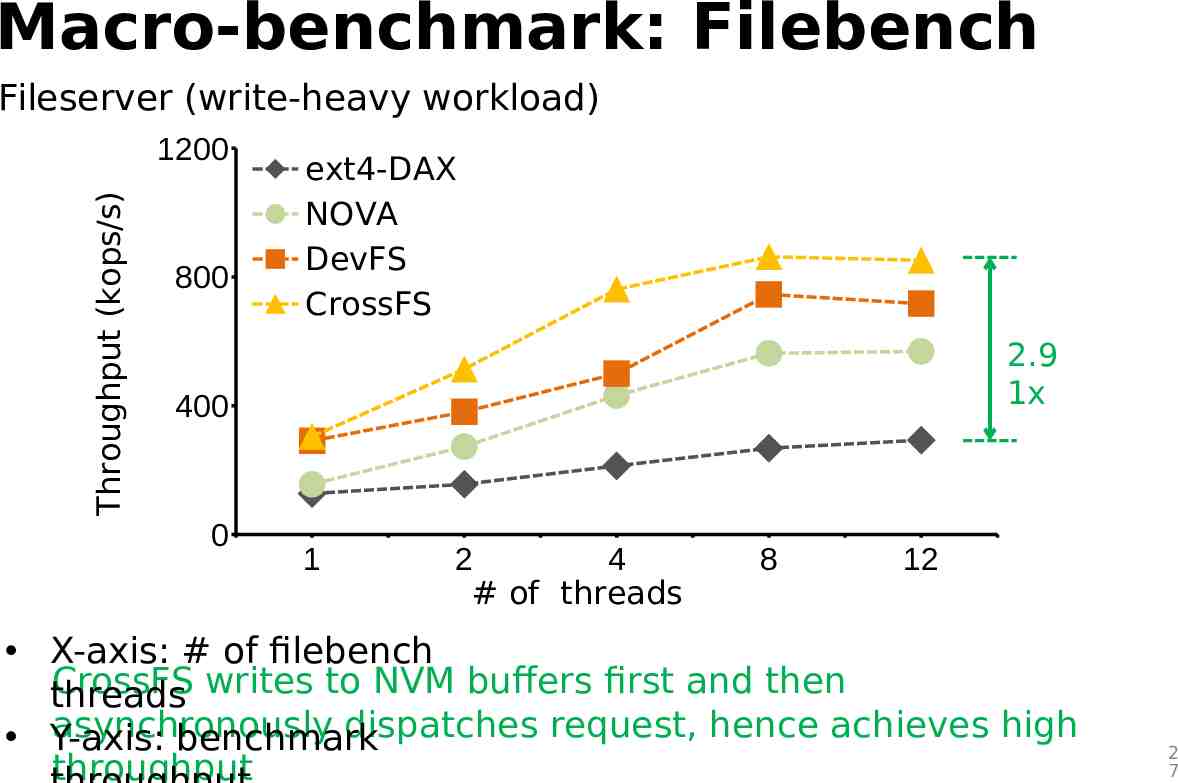
Macro-benchmark: Filebench Fileserver (write-heavy workload) Throughput (kops/s) 1200 800 ext4-DAX NOVA DevFS CrossFS 2.9 1x 400 0 1 2 4 # of threads 8 12 X-axis: # of filebench CrossFS writes to NVM buffers first and then threads asynchronously dispatches request, hence achieves high Y-axis: benchmark throughput 2 7
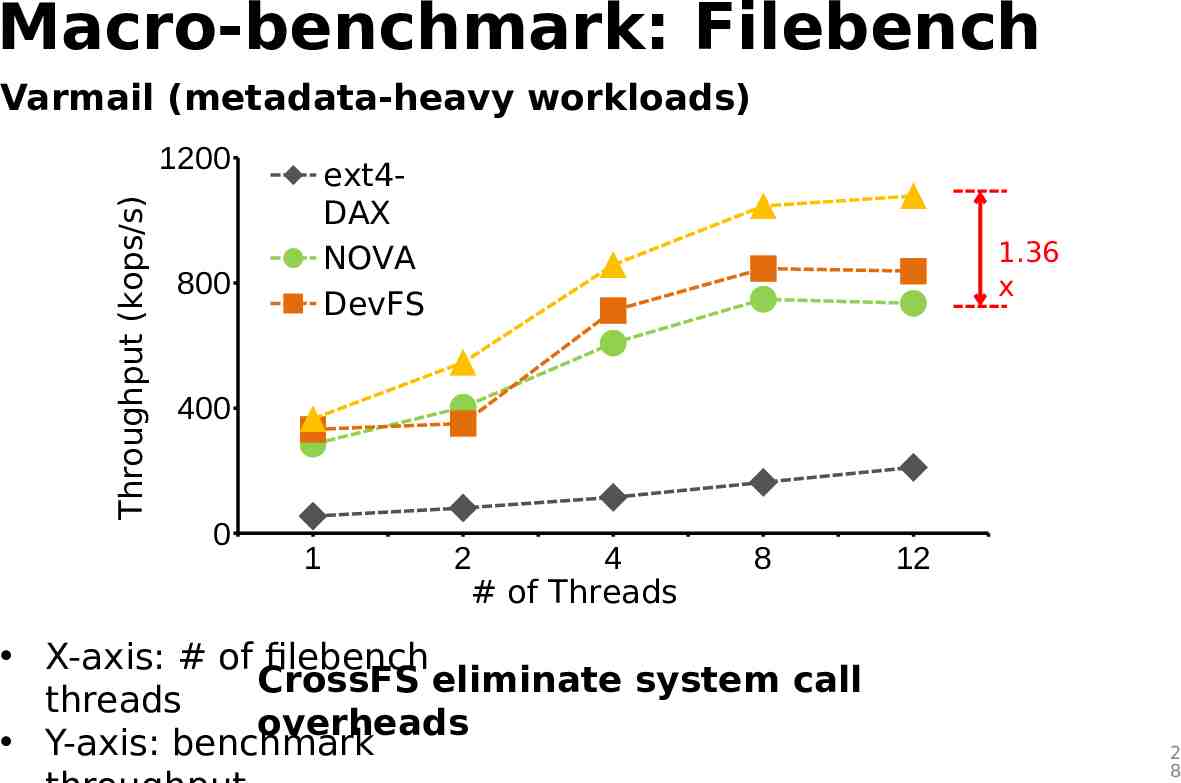
Macro-benchmark: Filebench Varmail (metadata-heavy workloads) Throughput (kops/s) 1200 ext4DAX NOVA DevFS 800 1.36 x 400 0 1 2 4 # of Threads 8 X-axis: # of filebench CrossFS eliminate system call threads overheads Y-axis: benchmark 12 2 8






