Consistency and Replication By Deepa Jandhyala Deepak Chinavle



























38 Slides671.50 KB
Consistency and Replication By Deepa Jandhyala Deepak Chinavle
Introduction In Distributed Systems data is replicated to improve performance and enhance reliability. Replication leads to consistency problems between copies. How do we achieve consistency of replicated data while multiple processes are accessing the data? We will look at some consistency models followed by some replica management techniques.
Replication Reasons for Replication: 1) Increase Reliability Continue working after one replica crashes. Multiple copies provides better protection against corrupted data. – Safeguard against single failing write operation by considering the value that is returned by at least two copies as being the correct one. 2) Improve Performance Scaling in numbers. – When too many processes are accessing one server, performance can be improved by replicating the server and dividing the work. Scaling with respect to size of geographical area. – Placing a copy of data in the proximity of the process using it decreases access latency. *Price of Replication – Consistency problems
Consistency Issues Tight Consistency - all copies of replicated data needs to be consistent at all times – Updates performed as single atomic operation. – Leads to scalability problems across large networks Data needs to be synchronized. – Each copy needs to reach agreement on when to perform update locally. – Global Synchronization needed to keep all replicas consistent – Leads to high performance costs. Solution: Loosen consistency constraints – Avoid global synchronization and gain performance.
Consistency Models A contract between processes and the distributed data store (collection of shared data accessible to clients) concerning read and write operations to the data. – If processes obey certain rules then data store will work correctly. – A process that performs a read operation on a data item expects to see the last write operation on that data. – Each model effectively restricts the values that a read operation on a data item can return – Models with major restrictions are easier to use but don’t perform as well as models with minor restrictions.
Types of Consistency Models Data-Centric Consistency Models – Systemwide consistent view on a data store where concurrent processes can simultaneously update the data store. Continuous Sequential Causal Entry – The general organization of a logical data store, physically distributed and replicated across multiple processes.
Strict Consistency Strongest consistency model – Any read on a data item X returns a value corresponding to the result of the most recent write on X Need an absolute global time – “most recent” needs to be unambiguous – this behavior can be observed in uniprocessors – a 7; a 13; print(a); { *has* to print 13 as output} Suppose, 2 processors are a few meters apart – B has a copy of X, A sends request to read X at T1, B writes it at T2. If T2-T1 is greater than the time it takes to propagate the request, then due to the laws of Physics, it is not possible for A to get the updated value – Clearly, strict consistency is hard!
Continuous Consistency Can be measured along three dimensions based on how much inconsistency the applications can tolerate - deviation in numerical values - deviation in staleness - deviation with respect to the ordering of update operations To define inconsistencies we can define a conit : conit specifies the unit over which consistency is to be measured.
Continuous Consistency - Example of a Conit keeping track of consistency deviations
Choosing the appropriate granularity for a conit. Two updates lead to update propagation. No update propagation is needed (yet).
Linearizability and Sequential Consistency Strict consistency is the ideal model – but impossible to implement! Often times such strict consistency is not needed Sequential consistency – Lamport (1979) – slightly weaker than strict consistency – defined by Lamport for shared memory for multi-processors – Definition: The result of any execution is the same as if the (read and write) operations by all processes on the data store were executed in some sequential order and the operations of each individual process appear in this sequence in the order specified by its program – Definition means: when processes are running concurrently interleaving of read and write operations is acceptable, but all processes see the same interleaving of operations – Difference from strict consistency no reference to the most recent time absolute global time does not play a role
Sequential Consistency A sequentially consistent data store. (P3 and P4 see the same order) A data store that is not sequentially consistent. (P3 and P4 don’t see the same order of events) Note, it doesn’t matter, when the events actually took place It does matter if all processes see them in the same order
Linearizability and Sequential Consistency Process P1 Process P2 Process P3 x 1; print (y, z); y 1; print (x, z); z 1; print (x, y); Three concurrently executing processes. Three variables are stored in shared sequentially consistent data store Each variable is initialized to 0 Assignment corresponds to a write operation Various interleaved execution sequences are possible – How many? Are all of them sequentially valid?
Linearizability and Sequential Consistency Four valid execution sequences for the processes of the previous slide. The vertical axis is time. x 1; print ((y, z); y 1; print (x, z); z 1; print (x, y); x 1; y 1; print (x,z); print(y, z); z 1; print (x, y); y 1; z 1; print (x, y); print (x, z); x 1; print (y, z); y 1; x 1; z 1; print (x, z); print (y, z); print (x, y); Prints: 001011 Prints: 101011 Prints: 010111 Prints: 111111 Signature: 001011 (a) Signature: 101011 (b) Signature: 110101 (c) Signature: 111111 (d) – Signature: output from P1, P2 and P3 as a string: – Not all 64 ( 26) patterns are allowed 000000 (print statements ran before assignments!) 001001 is also not possible (why?)
Causal Consistency Necessary condition: Writes that are potentially causally related must be seen by all processes in the same order. Concurrent writes may be seen in a different order on different machines. Weaker than sequential consistency If event B is caused or influence by an earlier event A, causality requires that everyone first see A and then B Concurrent: operations that are not causally related
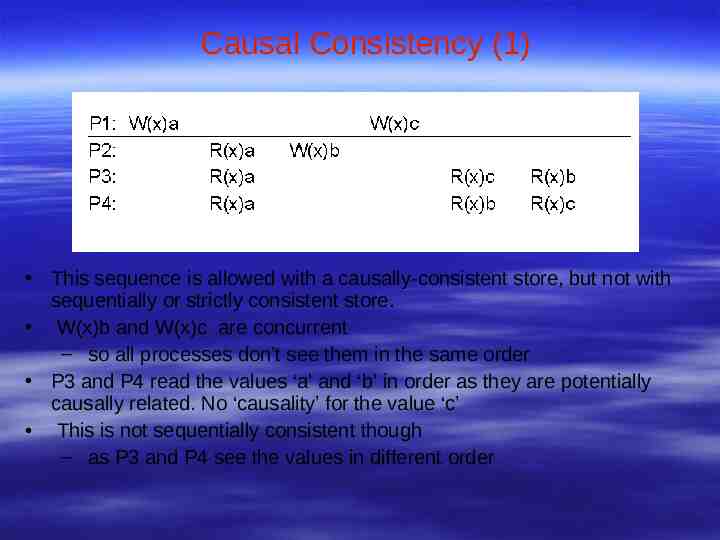
Causal Consistency (1) This sequence is allowed with a causally-consistent store, but not with sequentially or strictly consistent store. W(x)b and W(x)c are concurrent – so all processes don’t see them in the same order P3 and P4 read the values ‘a’ and ‘b’ in order as they are potentially causally related. No ‘causality’ for the value ‘c’ This is not sequentially consistent though – as P3 and P4 see the values in different order
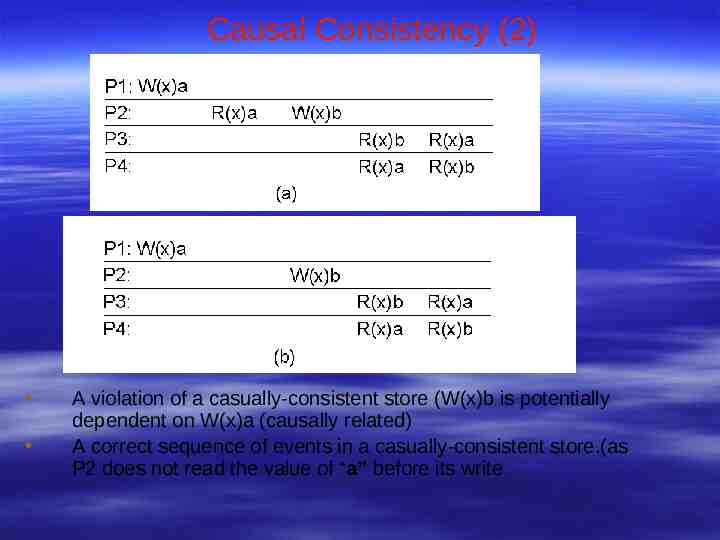
Causal Consistency (2) A violation of a casually-consistent store (W(x)b is potentially dependent on W(x)a (causally related) A correct sequence of events in a casually-consistent store.(as P2 does not read the value of “a” before its write
Entry Consistency Conditions: - An acquire access of a synchronization variable is not allowed to perform with respect to a process until all updates to the guarded shared data have been performed with respect to that process. - Before an exclusive mode access to a synchronization variable by a process is allowed to perform with respect to that process, no other process may hold the synchronization variable, not even in nonexclusive mode. - After an exclusive mode access to a synchronization variable has been performed, any other process's next nonexclusive mode access to that synchronization variable may not be performed until it has performed with respect to that variable's owner.
Types of Consistency Models – Client-Centric Consistency Models Consistency for a single client with no guarantees concerning concurrent accesses by different clients – Monotonic-Reads – Monotonic-Writes – Read-Your-Writes – Write-Follow-Reads – Examples: DNS – Single naming authority per zone – “lazy” propagation of updates WWW – No write-write conflicts – Usually acceptable to serve slightly out-of-date pages from a cache
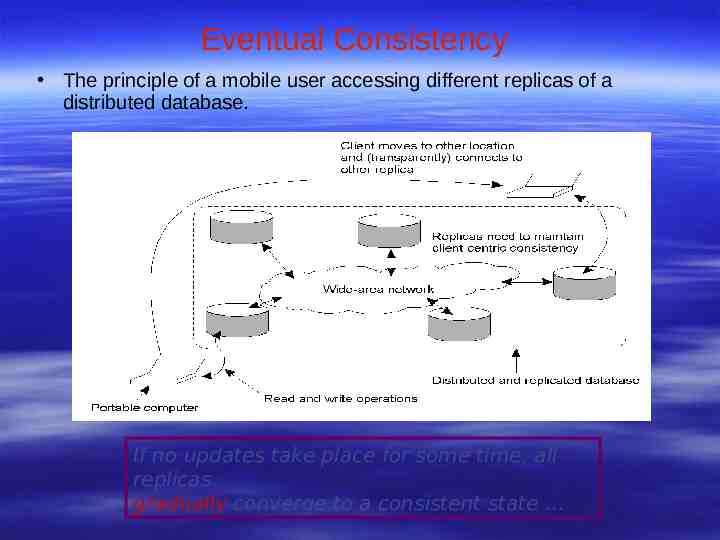
Eventual Consistency The principle of a mobile user accessing different replicas of a distributed database. If no updates take place for some time, all replicas gradually converge to a consistent state
Notations for client-centric models xi[t]: version of object x at local copy Li at time t – result of updates to a series of writes since system initialization at Li – WS(xi[t]): series of writes – WS(xi[t2]; xj[t2]): series of writes that have also been performed at copy Lj at a later time Assume an “owner” for each data item – avoid write-write conflicts Monotonic reads Monotonic writes Read-your-values Writes-follow-reads
Monotonic Reads WS(x1) is part of WS(x2) If a process has seen a value of x at time t, it will never see an older value at a later time. Example: -replicated mailboxes with on-demand propagation of updates The read operations performed by a single process P at two different local copies of the same data store. a) A monotonic-read consistent data store (a) b) A data store that does not provide monotonic reads (b)
Monotonic Writes If an update is made to a copy, all preceding updates must have been completed first. A write may affect only part of the state of a data item FIFO propagation of updates by each process No guarantee that x at L2 has the same value as x at L1 at the time W(x1) completed a) b) Example: - s/w library The write operations performed by a single process P at two different local copies of the same data store A monotonic-write consistent data store. A data store that does not provide monotonic-write consistency.
Read Your Writes A write is completed before a successive read, no matter where the read takes place Negative examples: - updates of Web pages - changes of passwords The effects of the previous write at L1 have not yet been propagated ! a) b) A data store that provides read-your-writes consistency. A data store that does not.
Writes Follow Reads Any successive write will be performed on a copy that is up-to-date with the value most recently read by the process. Example: - updates of a newsgroup: Responses are visible only after the original posting has been received a) b) A writes-follow-reads consistent data store A data store that does not provide writesfollow-reads consistency
Replica Placement (I) The logical organization of different kinds of copies of a data store into three concentric rings.
Replica Placement (II) Permanent copies – Basis of distributed data store Example from the Web: – Anycasting & round-robin clusters – Mirror sites Server-initiated – Push caches Dynamic replication to handle bursts Read-only – Content Distribution Network (CDN) Client-initiated – Improve access time to data Danger of “stale” data – Private vs Shared caches
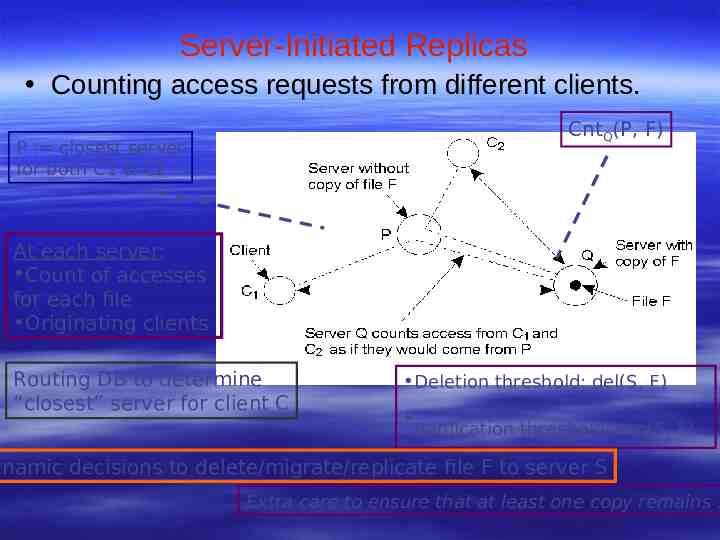
Server-Initiated Replicas Counting access requests from different clients. CntQ(P, F) P : closest server for both C1 & C2 At each server: Count of accesses for each file Originating clients Routing DB to determine “closest” server for client C Deletion threshold: del(S, F) Replication threshold: rep(S, F) ynamic decisions to delete/migrate/replicate file F to server S Extra care to ensure that at least one copy remains !
Update propagation State vs Operations – Notification of an update Invalidation protocols Best for low read/write ratio (%) – Transfer data from one copy to another Transfer of actual data or log of changes Batching Best for relatively high read/write % – Propagate the update to other copies Active replication Pull vs Push – Push replicas maintain a high degree of consistency Updates are expected to be of use to multiple readers – Pull best for low read/write % – Hybrid scheme based on lease model Unicast vs Multicast – Push multicast group – Pull single server or client requests an update
Pull versus Push Protocols Stateful server: keeps track of all caches Issue Push-based Pull-based State of server List of client replicas and caches None Messages sent Update (and possibly fetch update later) Poll and update Response time at client Immediate (or fetch-update time) Fetch-update time Comparison between push-based & pull-based protocols in the case of multiple client, single server systems.
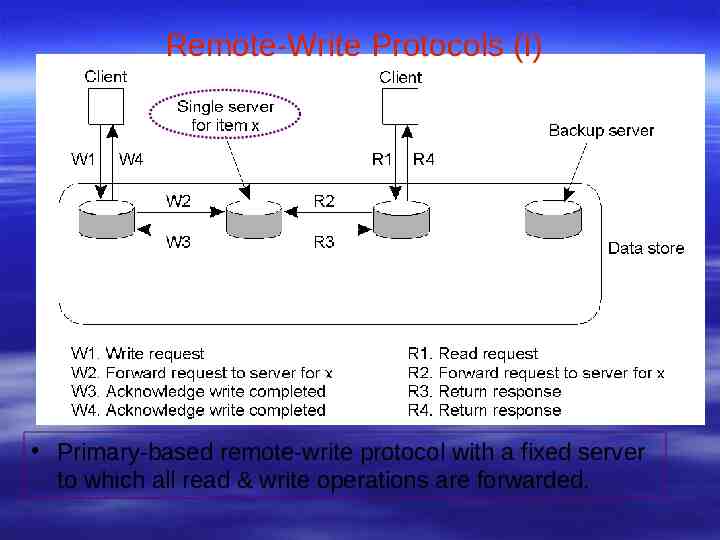
Remote-Write Protocols (I) Primary-based remote-write protocol with a fixed server to which all read & write operations are forwarded.
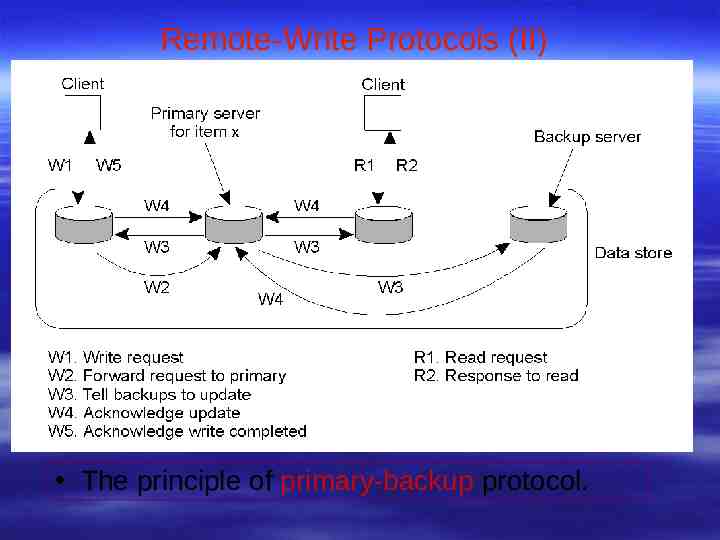
Remote-Write Protocols (II) The principle of primary-backup protocol.
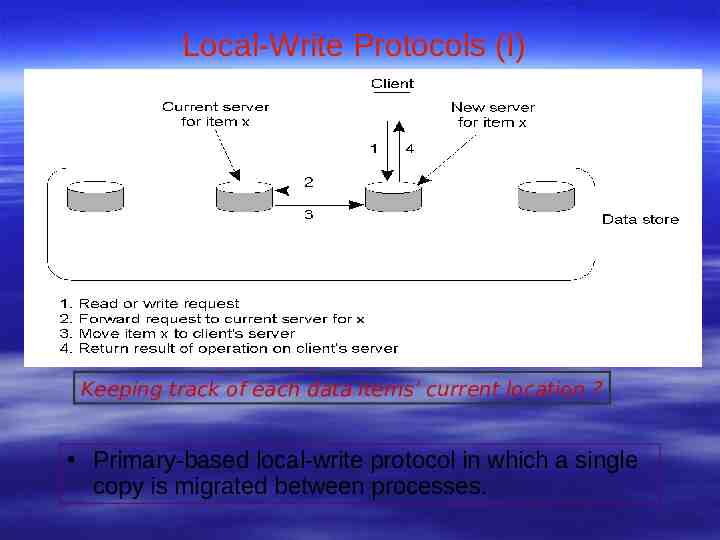
Local-Write Protocols (I) Keeping track of each data items’ current location ? Primary-based local-write protocol in which a single copy is migrated between processes.
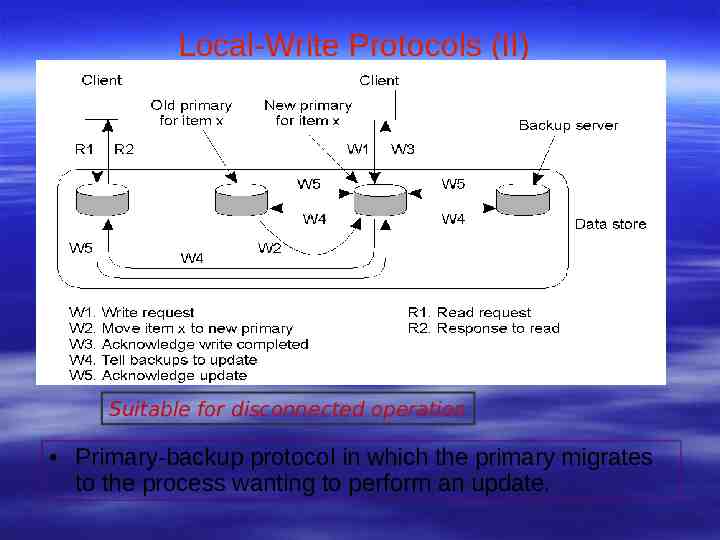
Local-Write Protocols (II) Suitable for disconnected operation Primary-backup protocol in which the primary migrates to the process wanting to perform an update.
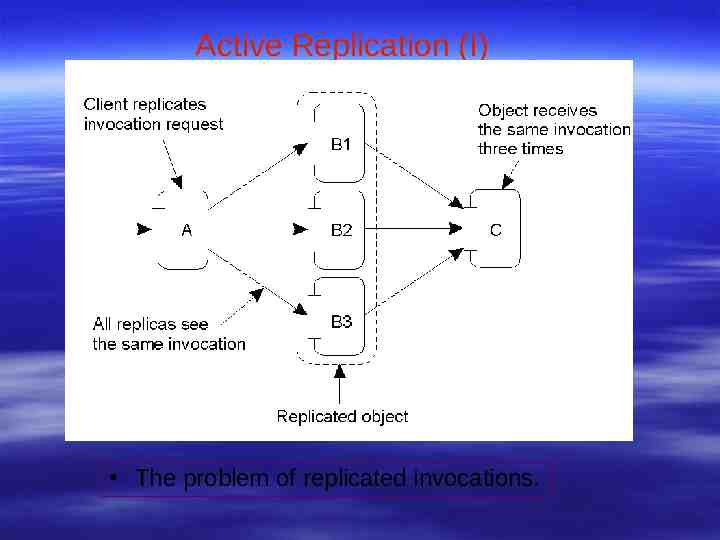
Active Replication (I) The problem of replicated invocations.
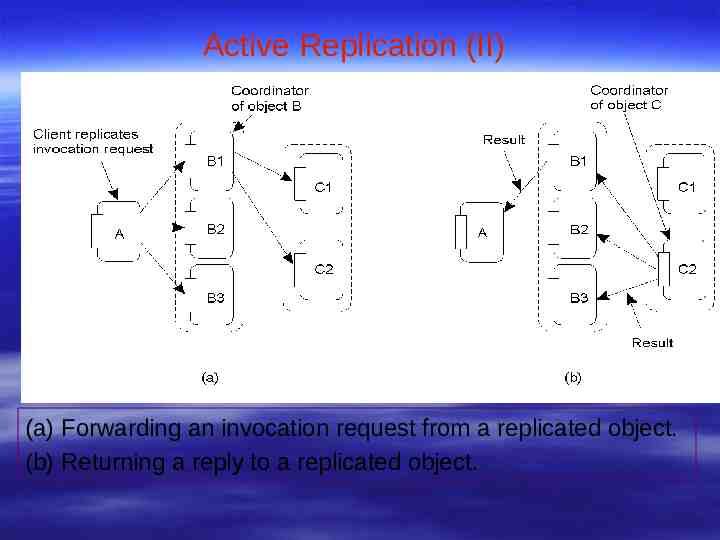
Active Replication (II) (a) Forwarding an invocation request from a replicated object. (b) Returning a reply to a replicated object.
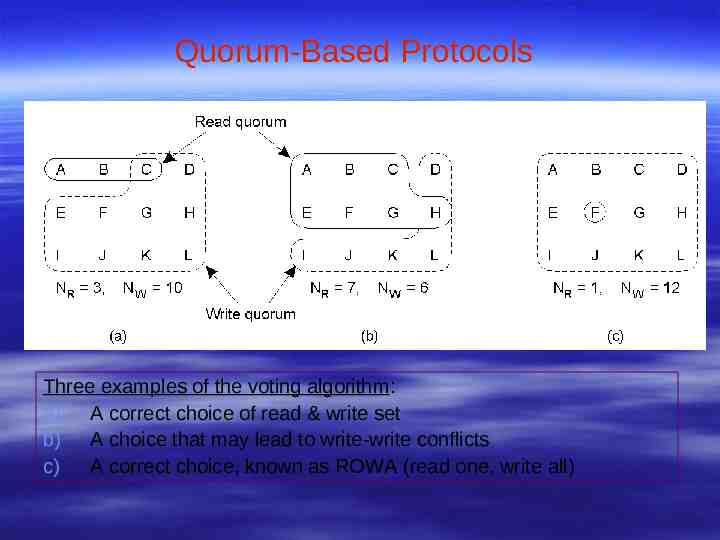
Quorum-Based Protocols Three examples of the voting algorithm: a) A correct choice of read & write set b) A choice that may lead to write-write conflicts c) A correct choice, known as ROWA (read one, write all)
References Distributed Systems, Principles and paradigms – Andrew S. Tenebaum, Maarten Van Steen Data Consistency in Intermittently Connected Distributed Systems – Evaggelia Pitoura, Bharat Bhargava, Ouri Wolfson Maintaining Consistency of Data in Mobile Distributed Environments Evaggelia Pitoura, Bharat Bhargava






