Computer aided drug design Lecture 12 Structural Bioinformatics Dr.













27 Slides2.33 MB
Computer aided drug design Lecture 12 Structural Bioinformatics Dr. Avraham Samson 81-871 1
Perspective Principles of drug discovery (brief) Computer driven drug discovery Data driven drug discovery Modern target identification and selection Modern lead identification Overall strong structural bioinformatics emphasis
What is a drug? Defined composition with a pharmacological effect Regulated by the Food and Drug Administration (FDA) What is the process of Drug Discovery and Development?
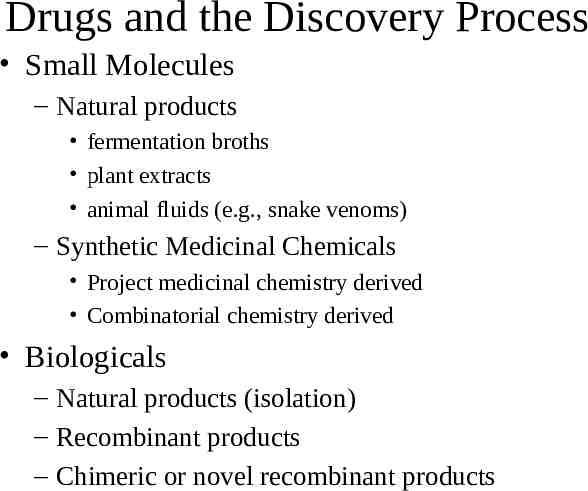
Drugs and the Discovery Process Small Molecules – Natural products fermentation broths plant extracts animal fluids (e.g., snake venoms) – Synthetic Medicinal Chemicals Project medicinal chemistry derived Combinatorial chemistry derived Biologicals – Natural products (isolation) – Recombinant products – Chimeric or novel recombinant products
Discovery vs. Development Discovery includes: Concept, mechanism, assay, screening, hit identification, lead demonstration, lead optimization Discovery also includes In Vivo proof of concept in animals and concomitant demonstration of a therapeutic index Development begins when the decision is made to put a molecule into phase I clinical trials
Discovery and Development The time from conception to approval of a new drug is typically 10-15 years The vast majority of molecules fail along the way The estimated cost to bring to market a successful drug is now 800 million!! (Dimasi, 2000)
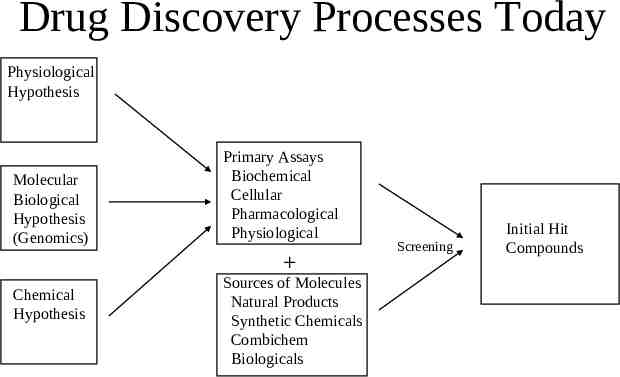
Drug Discovery Processes Today Physiological Hypothesis Molecular Biological Hypothesis (Genomics) Primary Assays Biochemical Cellular Pharmacological Physiological Chemical Hypothesis Sources of Molecules Natural Products Synthetic Chemicals Combichem Biologicals Screening Initial Hit Compounds
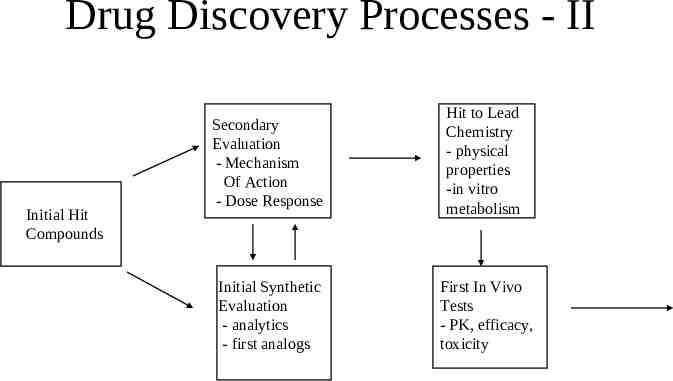
Drug Discovery Processes - II Initial Hit Compounds Secondary Evaluation - Mechanism Of Action - Dose Response Hit to Lead Chemistry - physical properties -in vitro metabolism Initial Synthetic Evaluation - analytics - first analogs First In Vivo Tests - PK, efficacy, toxicity
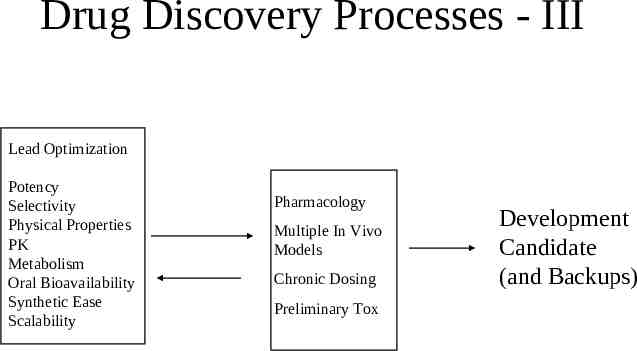
Drug Discovery Processes - III Lead Optimization Potency Selectivity Physical Properties PK Metabolism Oral Bioavailability Synthetic Ease Scalability Pharmacology Multiple In Vivo Models Chronic Dosing Preliminary Tox Development Candidate (and Backups)
Drug Discovery Disciplines Medicine Physiology/pathology Pharmacology Molecular/cellular biology Automation/robotics Medicinal, analytical,and combinatorial chemistry Structural and computational chemistries Bioinformatics
Drug Discovery Program Rationales Unmet Medical Need Me Too! - Market - ( s) Drugs in search of indications – Side-effects often lead to new indications Indications in search of drugs – Mechanism based, hypothesis driven, reductionism
Serendipity and Drug Discovery Often molecules are discovered/synthesized for one indication and then turn out to be useful for others – – – – Tamoxifen (birth control and cancer) Viagra (hypertension and erectile dysfunction) Salvarsan (Sleeping sickness and syphilis) Interferon- (hairy cell leukemia and Hepatitis C)
Issues in Drug Discovery Hits and Leads - Is it a “Druggable” target? Resistance Pharmacodynamics Delivery - oral and otherwise Metabolism Solubility, toxicity Patentability
A Little History of Computer Aided Drug Design 1960’s - Viz - review the target - drug interaction 1980’s- Automation - high trhoughput target/drug selection 1980’s- Databases (information technology) - combinatorial libraries 1980’s- Fast computers - docking 1990’s- Fast computers - genome assembly - genomic based target selection 2000’s- Vast information handling - pharmacogenomics
Chembank database http://chembank.broadinstitute.org/welcome.htm
Patchdock http://bioinfo3d.cs.tau.ac.il/PatchDock/index.html
From the Computer Perspective
Progress About the computer industry “If the automobile industry had made as much progress in the past fifty years, a car today would cost a hundredth of a cent and go faster than the speed of light.” – Ray Kurzweil, The Age of Spiritual Machines
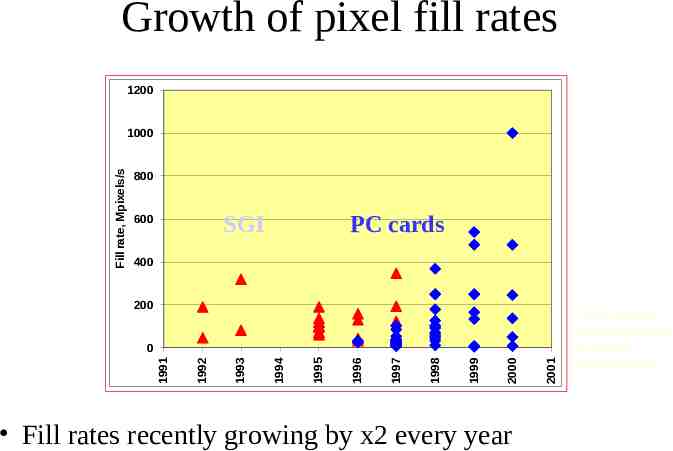
Growth of pixel fill rates 1200 Fill rate, Mpixels/s 1000 800 SGI 600 PC cards 400 200 2001 2000 1999 1998 1997 1996 1995 1994 1993 1992 1991 0 * Not counting custom hardware or special configurations Fill rates recently growing by x2 every year Data source: Product literature
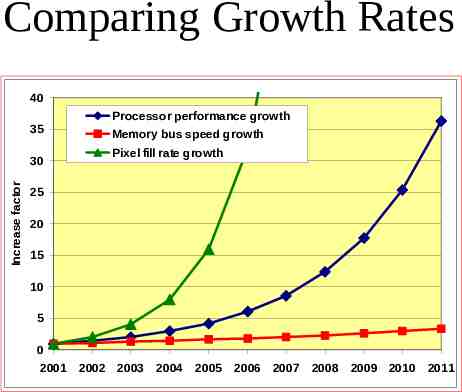
Comparing Growth Rates 40 35 Increase factor 30 Processor performance growth Memory bus speed growth Pixel fill rate growth 25 20 15 10 5 0 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011
From the Target Perspective
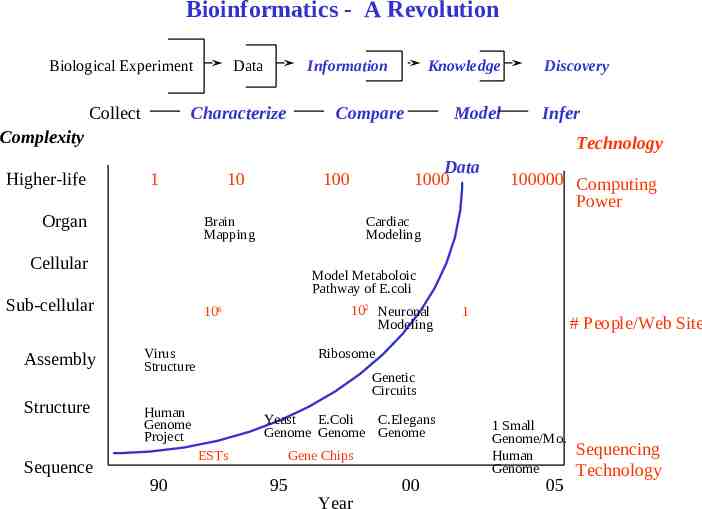
Bioinformatics - A Revolution Biological Experiment Collect Data Information Characterize Knowledge Compare Model Discovery Infer Complexity Higher-life Technology 1 Organ 10 Brain Mapping Model Metaboloic Pathway of E.coli Sub-cellular Structure Sequence 100000 Computing Power Cardiac Modeling Cellular Assembly Data 1000 100 102 Neuronal Modeling 106 Virus Structure Ribosome Human Genome Project Yeast E.Coli C.Elegans Genome Genome Genome # People/Web Site Genetic Circuits ESTs 90 1 Gene Chips 95 Year 00 1 Small Genome/Mo. Human Genome 05 Sequencing Technology
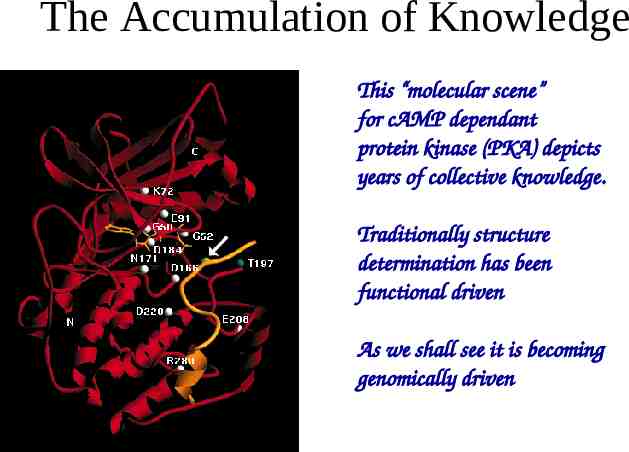
The Accumulation of Knowledge This “molecular scene” for cAMP dependant protein kinase (PKA) depicts years of collective knowledge. Traditionally structure determination has been functional driven As we shall see it is becoming genomically driven
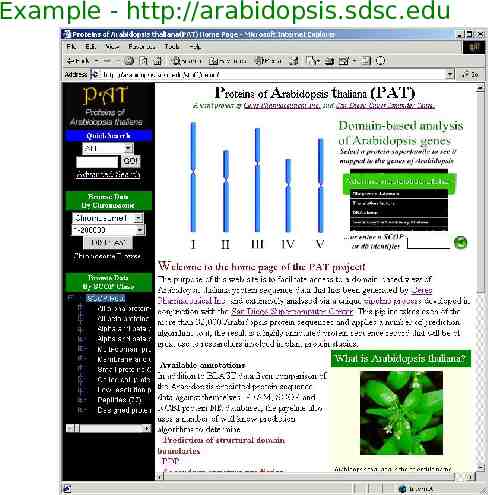
Example - http://arabidopsis.sdsc.edu
Combinatorial Libraries Thousands of variations to a fixed template Good libraries span large areas of chemical and conformational space - molecular diversity Diversity in - steric, electrostatic, hydrophobic interactions. Desire to be as broad as “Merck” compounds from random screening Computer aided library design is in its infancy Blaney and Martin - Curr. Op. In Chem. Biol. (1997) 1:54-59
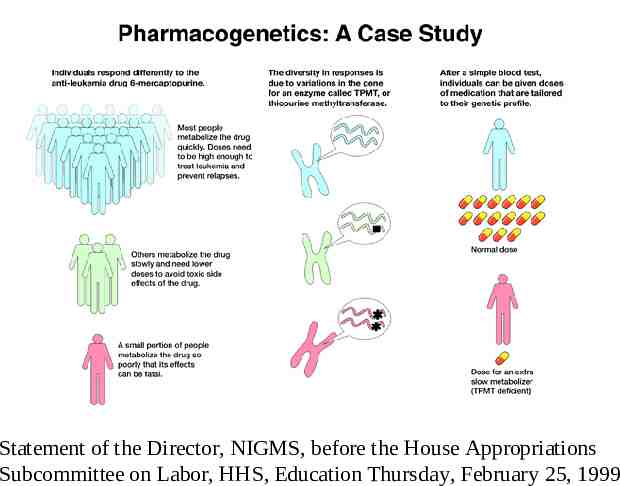
Statement of the Director, NIGMS, before the House Appropriations Subcommittee on Labor, HHS, Education Thursday, February 25, 1999






