COMP4332/RMBI4310 Distributed Data Management Distributed





























35 Slides1.07 MB
COMP4332/RMBI4310 Distributed Data Management Distributed Data Management Prepared by Raymond Wong Presented by Raymond Wong raywong@cse 1
We know that in a single machine, if there are many very fast processors in a single CPU, our program could run more quickly If there are many very fast processors in a single CPU and many not-veryfast but fast processors in a single GPU, our program could run more quickly Distributed Data Management 2
This is called Distributed Data Management. Suppose that we have many machines/nodes/servers. They are connected via a fast network. Our program could run more quickly. Distributed Data Management 3
There are two new popular technologies for distributed data management. Hadoop Spark Distributed Data Management 4
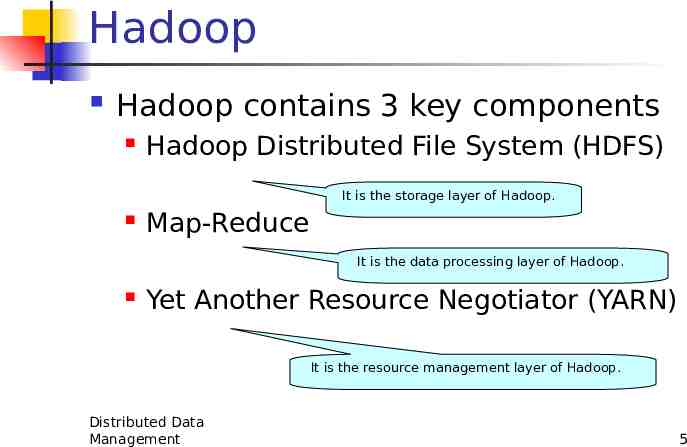
Hadoop Hadoop contains 3 key components Hadoop Distributed File System (HDFS) It is the storage layer of Hadoop. Map-Reduce It is the data processing layer of Hadoop. Yet Another Resource Negotiator (YARN) It is the resource management layer of Hadoop. Distributed Data Management 5
Hadoop Before we describe these 3 layers, let us describe the Hadoop system. It is a master-slave system Consider an application of “counting” the total number of occurrences for each word in all documents. E.g., There are 2 occurrences of word “Raymond” and 3 occurrences of word “Wong” in all documents Distributed Data Management 6
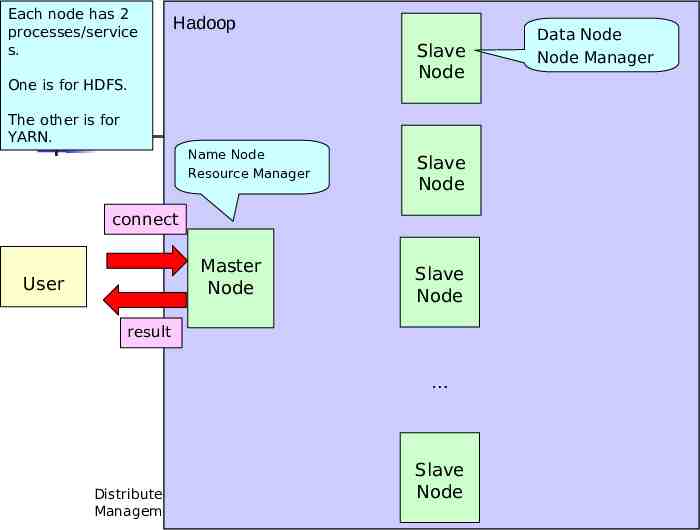
Hadoop There are many slave nodes (e.g., more than 1000). There is a single master node. Slave Node Slave Node Function: Perform actual operations/tasks Store the data connect Master Node User Slave Node e.g., “Raymond” and “Wong” result Function: Manage, maintain and monitor the slaves Store the meta-data (i.e., the data about Distributed Datadata). Management Slave Node 7
Each node has 2 processes/service s. Hadoop Slave Node One is for HDFS. Data Node Node Manager The other is for YARN. Name Node Resource Manager Slave Node connect Master Node User Slave Node result Distributed Data Management Slave Node 8
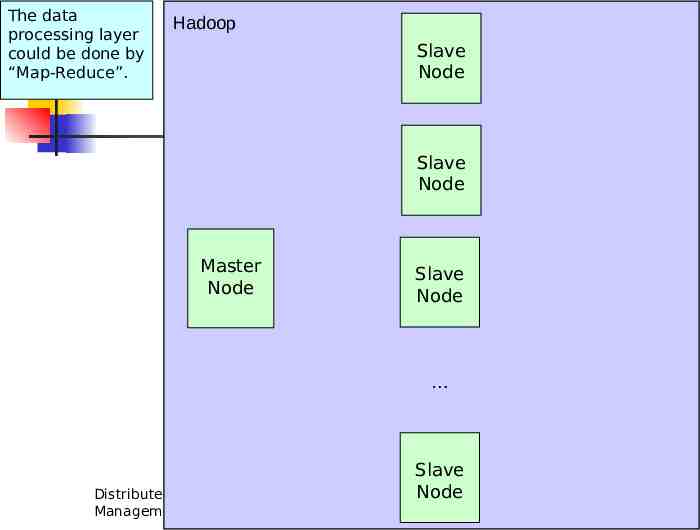
The data processing layer could be done by “Map-Reduce”. Hadoop Slave Node Slave Node Master Node Slave Node Distributed Data Management Slave Node 9
Hadoop Slave Node Slave Node Slave Node Distributed Data Management Slave Node 10
Hadoop Slave Node Slave Node Slave Node Distributed Data Management Slave Node 11
Hadoop “Raymond” “Wong” “Peter” “Kelvin” (“Raymond”, 1) Mapper Mapper “Chan” They are written in the disk in this node. (“Wong”, 1) (“Peter”, 1) (“Kelvin”, 1) We map each record to a (key, value) pair like the dictionary entry in Python. (“Chan”, 1) “Mary” (“Mary”, 1) Mapper “Wong” Note that these mapper processors run “concurrently”. (“Wong”, 1) “Raymond” “Wong” Mapper Distributed Data Management (“Raymond”, 1) (“Wong”, 1) 12
Hadoop (“Raymond”, 1) (“Wong”, 1) (“Peter”, 1) (“Kelvin”, 1) (“Chan”, 1) (“Mary”, 1) (“Wong”, 1) (“Raymond”, 1) Distributed Data Management (“Wong”, 1) 13
Hadoop (“Raymond”, 1) (“Wong”, 1) (“Peter”, 1) (“Kelvin”, 1) (“Chan”, 1) (“Mary”, 1) (“Wong”, 1) (“Raymond”, 1) Data (“Wong”, Distributed 1) Management 14
Hadoop (“Raymond”, 1) (“Wong”, 1) One of the existing slave nodes (“Peter”, 1) (“Kelvin”, 1) (“Chan”, 1) (“Mary”, 1) (“Wong”, 1) Slave Node (“Raymond”, 1) Data (“Wong”, Distributed 1) Management 15
Hadoop (“Raymond”, 1) (“Wong”, 1) Shuffle: to transfer the output of the mapper to the input of the reducer (“Peter”, 1) (“Kelvin”, 1) (“Chan”, 1) (“Raymond”, [1, 1]) (“Raymond”, 2) (“Wong”, [1, 1, 1]) (“Wong”, 3) (“Peter”, 1) (“Peter”, [1]) (“Mary”, 1) (“Wong”, 1) Shuffle & Sort (“Kelvin”, [1]) (“Chan”, [1]) Reduc er (“Mary”, [1]) (“Kelvin”, 1) (“Chan”, 1) (“Mary”, 1) (“Raymond”, 1) Data (“Wong”, Distributed 1) Management Sort: to merge the output of the mapper They are written in the disk in this node. This “reducer” could be done in multiple slave nodes. 16
We could see that there are many “concurrent” processes. Thus, there is a speedup. Distributed Data Management 17
Limitation The “intermediate” result must be stored in the disk only (not main memory) There are only a limited number of operations (e.g., Map, Reduce, Shuffle and Sort) The Hadoop could execute in a batch mode only Distributed Data Management 18
There are two new popular technologies for distributed data management. Hadoop Spark Distributed Data Management 19
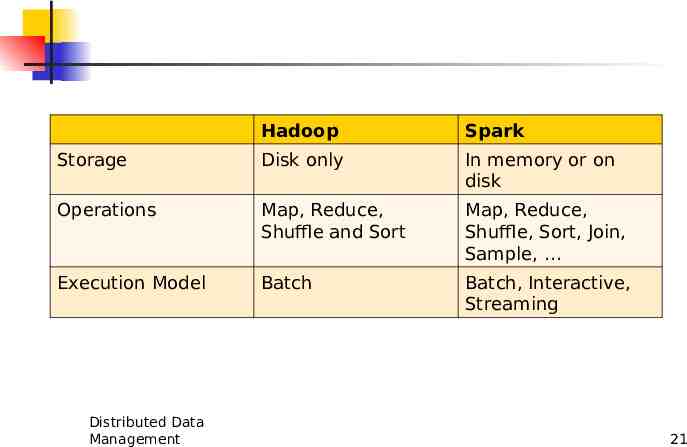
Spark Spark is a platform for “Distributed Data Management” It has more advantages compared with Hadoop. Distributed Data Management 20
Hadoop Spark Storage Disk only In memory or on disk Operations Map, Reduce, Shuffle and Sort Map, Reduce, Shuffle, Sort, Join, Sample, Execution Model Batch Batch, Interactive, Streaming Distributed Data Management 21
In Spark, there is an important data structure called “Resilient Distributed Dataset (RDD)” Distributed Data Management 22
RDD is an immutable set of objects which could be computed on different nodes. Each RDD is "logically" partitioned across different nodes so that different components of this RDD could be computed on different nodes. Distributed Data Management 23
Two types of RDD operations Transformation Action Distributed Data Management 24
Transformation is an operation that takes an RDD as the input and produce one or many RDDs as the output. There are two types of transformation Narrow transformation Wide transformation Distributed Data Management 25
A narrow transformation is an operation which takes the RDD data from a single node and outputs the processed data in the same node. Node 1 Narrow transformation Data 1 Node 1 Processed Data 1 From Data 1 only Node 2 Narrow transformation Data 2 These 2 nodes could be done concurrently. Distributed Data Management Node 2 Processed Data 2 From Data 2 only 26
Example Map FlatMap MapPartition Filter Sample Union Distributed Data Management 27
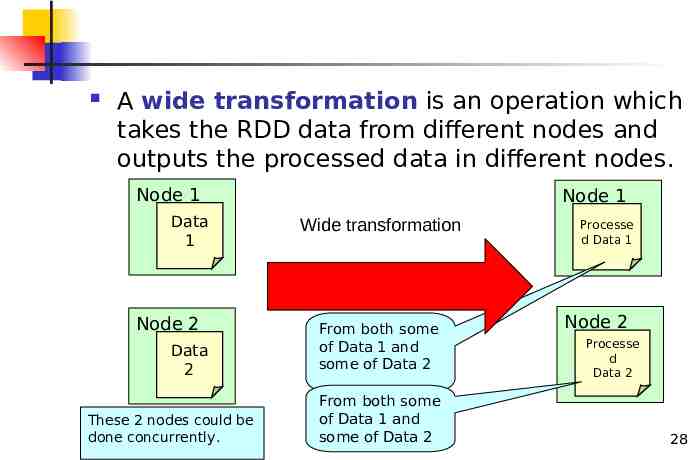
A wide transformation is an operation which takes the RDD data from different nodes and outputs the processed data in different nodes. Node 1 Data 1 Node 2 Data 2 These 2 nodes could be Distributed Data done concurrently. Management Node 1 Wide transformation From both some of Data 1 and some of Data 2 From both some of Data 1 and some of Data 2 Processe d Data 1 Node 2 Processe d Data 2 28
Example Intersection Distinct ReduceByKey GroupByKey Join Cartesian Repartition Coalesce Distributed Data Management 29
Two types of RDD operations Transformation Action Distributed Data Management 30
Action is an operation which returns the final result of all RDD computations Distributed Data Management 31
We could see that there are many “concurrent” processes. Thus, there is a speedup. Distributed Data Management 32
There are some components in The core of Spark Spark Spark version of SQL Spark Core Spark handling streaming data Spark SQL Spark Streaming Spark version of Machine Learning libraries Spark component handling graphs (e.g., Spark MLib social networks) Spark GraphX Spark version of R SparkR Distributed Data Management 33
There is a tool called “Databricks” (from University of California, Berkeley) using Spark. It could support what we have learnt Python Keras (built on TensorFlow) We could still do what we have learnt on Databricks (using Spark) Distributed Data Management 34
Our tutorial on 8 May covers how to use Databricks. Distributed Data Management 35






