Chapter 10 Distributed Database Management Systems 1

















































55 Slides1.70 MB
Chapter 10 Distributed Database Management Systems 1
The Evolution of Distributed Database Management Systems Distributed database management system (DDBMS) Governs storage and processing of logically related data over interconnected computer systems in which both data and processing functions are distributed among several sites Distributed Databases 2
The Evolution of Distributed Database Management Systems (DDBMS) Centralized database required that corporate data be stored in a single central site Performance degradation as number of remote sites grew High cost to maintain large centralized DBs Reliability problems with one, central site Dynamic business environment and centralized database’s shortcomings spawned a demand for applications based on data access from different sources at multiple locations Business operations became more decentralized geographically Competition at global level Rapid technological change in computers Distributed Databases 3
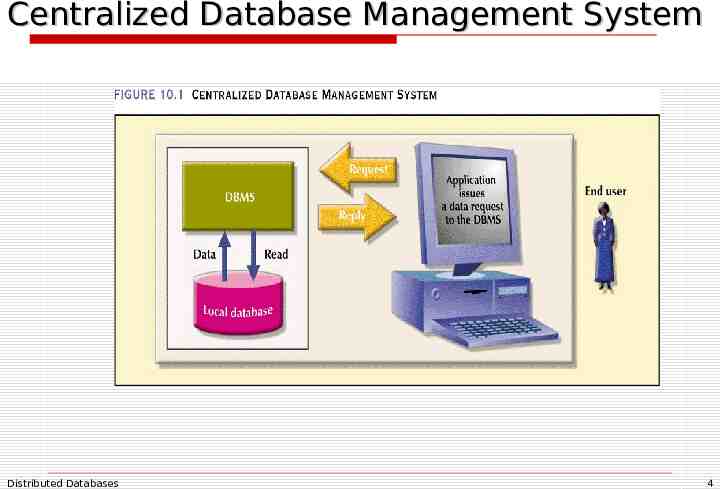
Centralized Database Management System Distributed Databases 4
DDBMS Advantages Data are located near “greatest demand” site Faster data access Faster data processing Growth facilitation Improved communications Reduced operating costs User-friendly interface Less danger of a single-point failure Processor independence Distributed Databases 5
DDBMS Disadvantages Complexity of management and control Security Lack of standards Increased storage requirements Greater difficulty in managing the data environment Increased training cost Distributed Databases 6
Distributed Processing vs Distributed Database Distributed processing – a database’s logical processing is shared among two or more physically independent sites that are connected through a network One computer performs I/O, data selection and validation while second computer creates reports Uses a single-site database but the processing chores are shared among several sites Distributed database – stores a logically related database over two or more physically independent sites. The sites are connected via a network Database is composed of database fragments which are located at different sites and may also be replicated among various sites Distributed Databases 7
Distributed Processing Environment Distributed Databases 8
Distributed Database Environment Distributed Databases 9
Characteristics of a DDBMS Application interface Validation Transformation Query optimization Mapping I/O interface Formatting Security Backup and recovery DB administration Concurrency control Transaction management Distributed Databases 10
Characteristics of Distributed Management Systems Must perform all the functions of a centralized DBMS Must handle all necessary functions imposed by the distribution of data and processing Must perform these additional functions transparently to the end user Distributed Databases 11
A Fully Distributed Database Management System Distributed Databases 12
DDBMS Components Must include (at least) the following components: Computer workstations Network hardware and software Communications media Carry the data from one workstation to another Transaction processor (application processor or transaction manager) Allows all sites to interact and exchange data Software component found in each computer that receives and processes the application’s requests data Data processor or data manager Software component residing on each computer that stores and retrieves data located at the site May even be a centralized DBMS Communications between the TPs and DPs is made possible through a set of protocols used by the DDBMS Distributed Databases 13
Distributed Database System Components Distributed Databases 14
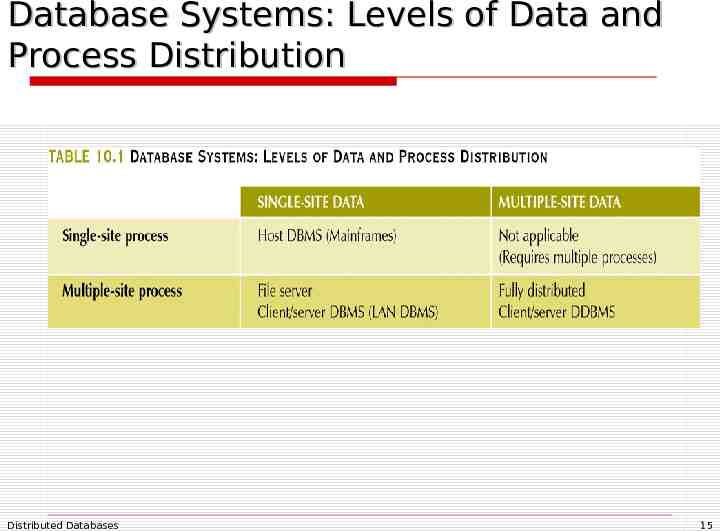
Database Systems: Levels of Data and Process Distribution Distributed Databases 15
Single-Site Processing, Single-Site Data (SPSD) All processing is done on single CPU or host computer (mainframe, midrange, or PC) All data are stored on host computer’s local disk Processing cannot be done on end user’s side of the system Typical of most mainframe and midrange computer DBMSs DBMS is located on the host computer, which is accessed by dumb terminals connected to it Also typical of the first generation of single-user microcomputer databases Distributed Databases 16
Single-Site Processing, Single-Site Data (Centralized) Distributed Databases 17
Multiple-Site Processing, Single-Site Data (MPSD) Multiple processes run on different computers sharing a single data repository MPSD scenario requires a network file server running conventional applications that are accessed through a LAN Many multi-user accounting applications, running under a personal computer network, fit such a description Distributed Databases 18
Multiple-Site Processing, Single-Site Data (MPSD) TP at each workstation acts only as a redirector to route all network data requests to the file server All record and file locking activity occurs at the enduser location All data selection, search and update functions takes place at the workstation. This requires entire files to travel through the network for processing at the workstation. This increases network traffic, slows response time and increases communication costs To perform SELECT that results in 50 rows, a 10,000 row table must travel over the network to the end-user Distributed Databases 19
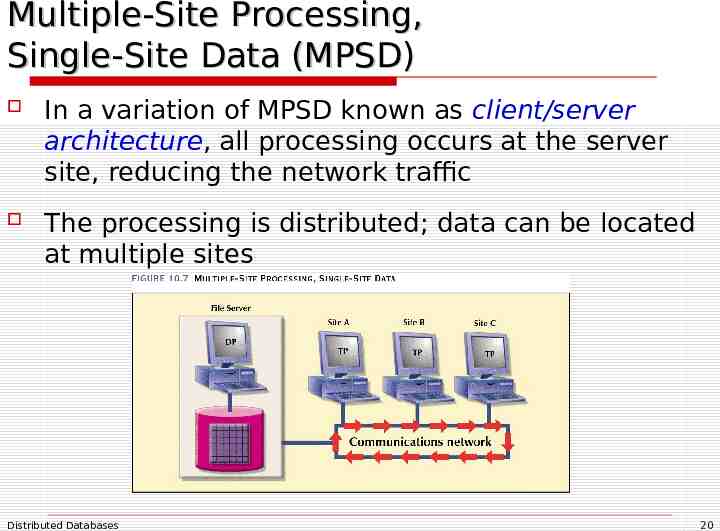
Multiple-Site Processing, Single-Site Data (MPSD) In a variation of MPSD known as client/server architecture, all processing occurs at the server site, reducing the network traffic The processing is distributed; data can be located at multiple sites Distributed Databases 20
Multiple-Site Processing, Multiple-Site Data (MPMD) Fully distributed database management system with support for multiple data processors and transaction processors at multiple sites Classified as either homogeneous or heterogeneous Homogeneous DDBMSs Integrate only one type of centralized DBMS over a network The same DBMS will be running on different mainframes, minicomputers and microcomputers Heterogeneous DDBMSs Fully heterogeneous DDBMS Integrate different types of centralized DBMSs over a network Support different DBMSs that may even support different data models (relational, hierarchical, or network) running under different computer systems, such as mainframes and microcomputers No DDBMS currently provides full support for heterogeneous or fully heterogeneous DDBMSs Distributed Databases 21
Heterogeneous Distributed Database Scenario Distributed Databases 22
Distributed Database Transparency Features Allow end user to feel like database’s only user. User feels like they are working with a centralized database Features include: Distribution transparency – user does not know where data is located and if replicated or partitioned Transaction transparency – transaction can update at several network sites to ensure data integrity Distributed Databases 23
Distributed Database Transparency Features Failure transparency – system continues to operate in the event of a node failure (other nodes pick up lost functionality) Performance transparency – allows system to perform as if it were a centralized DBMS. No performance degradation due to use of a network or platform differences Heterogeneity transparency – allows the integration of several different local DBMSs under a common schema Distributed Databases 24
Distribution Transparency Allows management of a physically dispersed database as though it were a centralized database Supported by a distributed data dictionary (DDD) which contains the description of the entire database as seen by the DBA The DDD is itself distributed and replicated at the network nodes Three levels of distribution transparency are recognized: Fragmentation transparency – user does not need to know if a database is partitioned; fragment names and/or fragment locations are not needed Location transparency – fragment name, but not location, is required Local mapping transparency – user must specify fragment name and location Distributed Databases 25
A Summary of Transparency Features Distributed Databases 26
Distribution Transparency The EMPLOYEE table is divided among three locations (no replication) Suppose an employee wants to find all employees with a birthdate prior to jan 1, 1940 Fragmentation transparency SELECT * FROM EMPLOYEE WHERE EMP DOB ’01-JAN1940’; Location transparency SELECT * FROM E1 WHERE EMP DOB ’01-JAN-1940’ UNION SELECT * FROM E2 UNION SELECT * FROM E3 ; Local Mapping Transparency SELECT * FROM E1 NODE NY WHERE EMP DOB ’01JAN-1940’ UNION SELECT * FROM E2 NODE ATL UNION SELECT * FROM E3 NODE MIA ; Distributed Databases 27
Transaction Transparency Ensures database transactions will maintain distributed database’s integrity and consistency A DDBMS transaction can update data stored in many different computers connected in a network Transaction transparency ensures that the transaction will be completed only if all database sites involved in the transaction complete their part of the transaction Distributed Databases 28
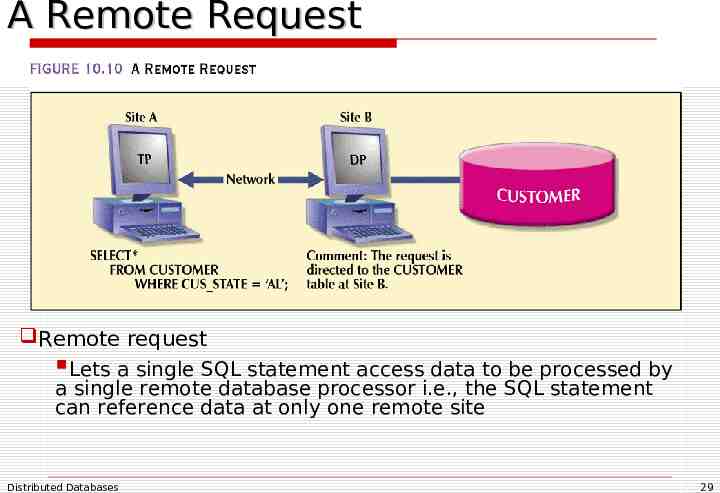
A Remote Request Remote request Lets a single SQL statement access data to be processed by a single remote database processor i.e., the SQL statement can reference data at only one remote site Distributed Databases 29
A Remote Transaction Remote transaction Accesses data at a single remote site This transaction updates two tables The remote transaction is sent to and executed at remote site B The transaction can reference only one remote DP Each SQL statement can reference only one remote DP at a time, and the entire transaction can reference and can be executed at only one remote DP Distributed Databases 30
A Distributed Transaction Distributed transaction Allows a transaction to reference several different (local or remote) DP sites Each request can access only one remote site at a time Distributed Databases Does not support access to a table fragmented across multiple remote sites in one request 31
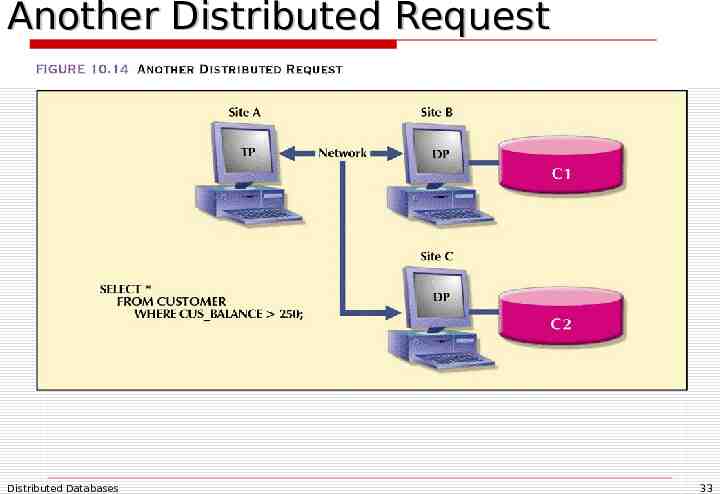
A Distributed Request Distributed request Lets a single SQL statement reference data located at several different local or remote DP sites The SELECT statement references two tables that are located at two different sites Similarly, a table fragmented across two sites can be transparently queried in one SELECT (next slide) Distributed Databases 32
Another Distributed Request Distributed Databases 33
Distributed Concurrency Control Multisite, multiple-process operations are much more likely to create data inconsistencies and deadlocked transactions than are single-site systems The TP component of a DDBMS must ensure that all parts of the transaction, at all sites, are completed before a final COMMIT is issued to record the transaction Distributed Databases 34
The Effect of a Premature COMMIT If one of the DPs did not commit and had to rollback while the other sites committed, the database would not be in a consistent state Distributed Databases 35
Two-Phase Commit Protocol Distributed databases make it possible for a transaction to access data at several sites Final COMMIT must not be issued until all sites have committed their parts of the transaction Two-phase commit protocol requires each individual DP’s transaction log entry be written before the database fragment is actually updated Distributed Databases 36
Two-Phase Commit Protocol DO-UNDO-REDO protocol is used by the DP to roll back and/or roll forward transactions with the help of the system’s transaction log entries DO performs the operation and records the “before” and “after” values in the transaction log UNDO reverses an operation, using the log entries written by the DO portion of the sequence REDO redoes an operation, using the log entries written by the DO portion of the sequence To ensure that the DO,UNDO and REDO operations can survive a system crash while they are being executed, a write-ahead protocol is used This forces the log entry to be written to permanent storage before the actual operation takes place Distributed Databases 37
Two-Phase Commit Protocol The two-phase commit protocol defines the operations between two types of nodes – the coordinator and one or more subordinates Phase I: Preparation The coordinator sends a PREPARE TO COMMIT message to its subordinates The subordinates receive the message, write the transaction log using the write-ahead protocol, and send an acknowledgement (YES/PREPARED TO COMMIT or NO/NOT PREPARED) message to the coordinator The coordinator makes sure that all nodes are ready to commit or it aborts the action Distributed Databases 38
Two-Phase Commit Protocol Phase II: The Final COMMIT The coordinator broadcasts a COMMIT message to all subordinates and waits for replies Each subordinate receives the COMMIT message, then updates the database using the DO protocol The subordinates reply with a COMMITTED or NOT COMMITTED message to the coordinator If one or more subordinates did not commit, the coordinator sends an ABORT message, forcing them to UNDO all changes The information necessary to recover the database is in the transaction log and the database can be recovered with the DO-UNDO-REDO protocol Distributed Databases 39
Distributed Database Design Data fragmentation: Data replication: How to partition the database into fragments Which fragments to replicate Data allocation: Where to locate those fragments and replicas Distributed Databases 40
Data Fragmentation Breaks single object into two or more segments or fragments Each fragment can be stored at any site over a computer network Information about data fragmentation is stored in the distributed data catalog (DDC), from which it is accessed by the TP to process user requests Distributed Databases 41
Data Fragmentation Strategies Horizontal fragmentation: Vertical fragmentation: Division of a relation into subsets (fragments) of tuples (rows) Division of a relation into attribute (column) subsets Mixed fragmentation: Combination of horizontal and vertical strategies Distributed Databases 42
A Sample CUSTOMER Table Distributed Databases 43
Horizontal Fragmentation of the CUSTOMER Table by State Distributed Databases 44
Vertically Fragmented Table Contents Two separate areas in the company use different fields of the table in the daily activities – the SERVICE dept and the COLLECTIONS dept Distributed Databases 45
Mixed Fragmentation of the CUSTOMER Table The table is divided horizontally by the three states and within each state there is a vertical fragmentation by department Distributed Databases 46
Table Contents After the Mixed Fragmentation Process Distributed Databases 47
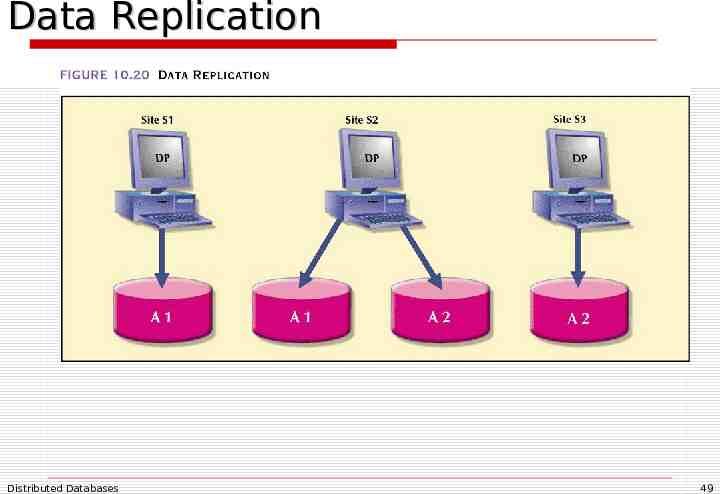
Data Replication Storage of data copies at multiple sites served by a computer network Fragment copies can be stored at several sites to serve specific information requirements Can enhance data availability and response time Can help to reduce communication and total query costs Imposes additional processing overhead Which copy do you read when submitting a query All copies must be updated when a write occurs Distributed Databases 48
Data Replication Distributed Databases 49
Replication Scenarios Fully replicated database: Partially replicated database: Stores multiple copies of each database fragment at multiple sites Can be impractical due to amount of overhead Stores multiple copies of some database fragments at multiple sites Most DDBMSs are able to handle the partially replicated database well Unreplicated database: Stores each database fragment at a single site No duplicate database fragments Database size, usage frequency and costs (performance, overhead, management) influence the decision to replicate Distributed Databases 50
Data Allocation Deciding where to locate data Allocation strategies: Centralized data allocation Partitioned data allocation Database is divided into several disjointed parts (fragments) and stored at several sites Replicated data allocation Entire database is stored at one site Copies of one or more database fragments are stored at several sites Data distribution over a computer network is achieved through data partition, data replication, or a combination of both Distributed Databases 51
Client/Server vs. DDBMS Way in which computers interact to form a system Features a user of resources, or a client, and a provider of resources, or a server Can be used to implement a DBMS in which the client is the TP and the server is the DP The client interacts with the end user and sends a request to the server. The server receives, schedules and executes the request, selecting only those records that are needed by the client. The server sends the data to the client only when the client requests the data. Distributed Databases 52
Client/Server Advantages Less expensive than alternate minicomputer or mainframe solutions Allow end user to use microcomputer’s GUI, thereby improving functionality and simplicity More people with PC skills than with mainframe skills in the job market PC is well established in the workplace Numerous data analysis and query tools exist to facilitate interaction with DBMSs available in the PC market Considerable cost advantage to offloading applications development from the mainframe to powerful PCs Distributed Databases 53
Client/Server Disadvantages Creates a more complex environment, in which different platforms (LANs, operating systems, and so on) are often difficult to manage An increase in the number of users and processing sites often paves the way for security problems Possible to spread data access to a much wider circle of users increases demand for people with broad knowledge of computers and software increases burden of training and cost of maintaining the environment Distributed Databases 54
C. J. Date’s Twelve Commandments for Distributed Databases 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. Local site independence Central site independence Failure independence Location transparency Fragmentation transparency Replication transparency Distributed query processing Distributed transaction processing Hardware independence Operating system independence Network independence Database independence Distributed Databases 55






