Caching in Distributed File System Ke Wang CS614 – Advanced System Apr
















































56 Slides354.00 KB
Caching in Distributed File System Ke Wang CS614 – Advanced System Apr 24, 2001
Key requirements of distributed system Scalability from small to large networks Fast and transparent access to geographically Distributed File System(DFS) Information protection Ease of administration Wide support from variety of vendors
Background DFS -- a distributed implementation of a file system, where multiple users share files and storage resources. Overall storage space managed by a DFS is composed of different, remotely located, smaller storage spaces There is usually a correspondence between constituent storage spaces and sets of files
DFS Structure Service - a software entity providing a particular type of function to client Server - service software running on a single machine Client - process that can invoke a service using a set of operations that forms its client interface
Why caching? Retaining most recently accessed disk blocks. Repeated accesses to a block in cache can be handled without involving the disk. Advantages - Reduce delays - Reduce contention for disk arm
Caching in DFS Advantages Reduce network traffic Reduce server contention Problems Cache-consistency
Stuff to consider Cache location (disk vs. memory) Cache Placement (client vs. server) Cache structure (block vs. file) Stateful vs. Stateless server Cache update policies Consistency Client-driven vs. Server-driven protocols
Practical Distributed System NFS: Sun’s Network File System AFS: Andrew File System (CMU) Sprite FS: File System for the Sprite OS ( UC Berkeley)
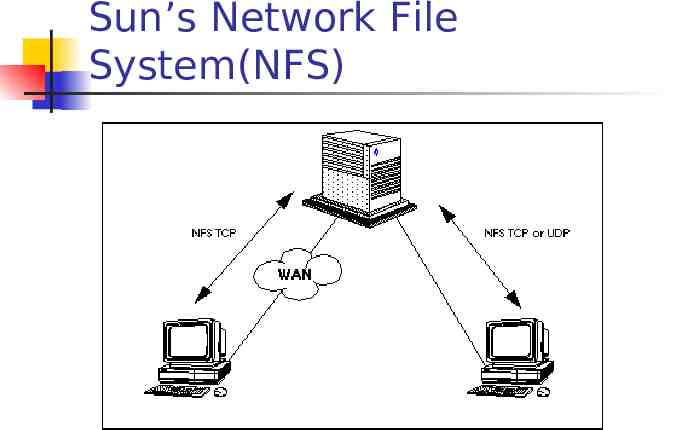
Sun’s Network File System(NFS)
Sun’s Network File System(NFS) Originally released in 1985 Build on top of an unreliable datagram protocol UDP (change to TCP now) Client-server model
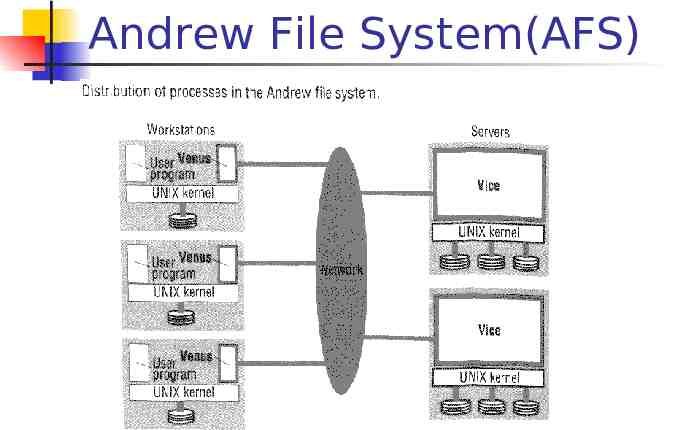
Andrew File System(AFS) Developed at CMU since 1983 Client-server model Key software: Vice and Venus Goal: high scalability (5,00010,000 nodes)
Andrew File System(AFS)
Andrew File System(AFS) VICE is a multi-threaded server process with each thread handling a single client request VENUS is the client process that runs on each workstation which forms the interface with VICE User-level processes
Prototype of AFS One process for one client Client cache file Verify timestamp every open - a lot of interaction with server - heavy network traffic
Improve AFS To improve prototype Reduce cache validity check Reduce server processes Reduce network traffic Higher scalability!
Sprite File System Designed for networked workstation with large physical memories (can be diskless) Expect memory of 100-500Mbytes Goal: high performance
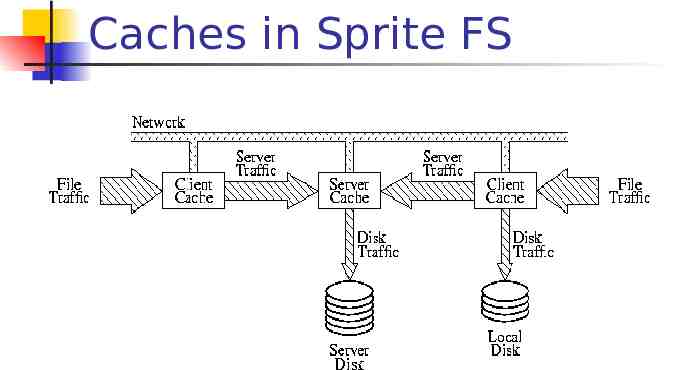
Caches in Sprite FS
Caches in Sprite FS(cont) When a process makes a file access, it is presented first to the cache(file traffic). If not satisfied, request is passed either to a local disk, if the file is stored locally(disk traffic), or to the server where the file is stored(server traffic). Servers also maintain caches to reduce disk traffic.
Caching in Sprite FS Two unusual aspects Guarantee complete consistent view Concurrent write sharing Sequential write sharing Cache size varies dynamically
Cache Location Disk vs. Main Memory Advantages of disk caches More Reliable Cached data are still there during recovery and don’t need to be fetched again
Cache Location Disk vs. Main Memory(cont) Advantages of main-memory caches: Permit workstations to be diskless More quick access Server caches(used to speed up disk I/O) are always in main memory; using main-memory caches on the clients permits a single caching mechanism for servers and users
Cache Placement Client vs. Server Client cache reduce network traffic Server cache reduce server load Read-only operations on unchanged files do not need go over the network Cache is amortized across all clients ( but needs to be bigger to be effective) In practice, need BOTH!
Cache structure Block basis Simple Sprite FS, NFS File basis Reduce interaction with servers AFS Cannot access files larger than cache
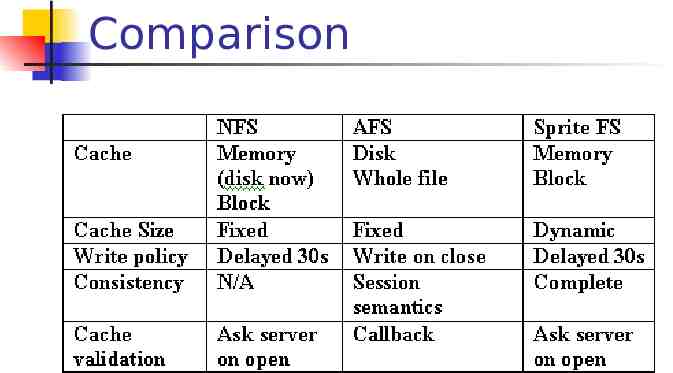
Compare NFS: client memory(disk), block basis AFS: client disk, file basis Sprint FS: client memory, server memory, block basis
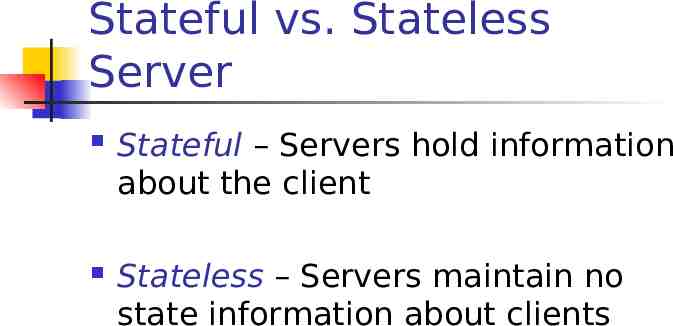
Stateful vs. Stateless Server Stateful – Servers hold information about the client Stateless – Servers maintain no state information about clients
Stateful Servers Mechanism Client opens a file Server fetches information about the file from its disk, store in memory, gives client a unique connection id and open file id is used for subsequent accesses until the session ends
Stateful Servers(cont) Advantages: Fewer disk access Read-ahead possible RPCs are small, contains only an id File may be cached entirely on client, invalidated by the server if there is a conflicting write
Stateful Servers(cont) Disadvantage: Server loses all its volatile state in crash Restore state by dialog with clients, or abort operations that underway when crash occurred Server needs to be aware of client failures
Stateless Server Each request must be selfcontained Each request identifies the file and position in the file No need to establish and terminate a connection by open and close operations
Stateless Server(cont) Advantage A file server crash does not affect clients Simple Disadvantage Impossible to enforce consistency RPC needs to contain all state, longer
Stateful vs. Stateless AFS and Sprite FS are stateful Sprite FS servers keep track of which clients have which files open AFS servers keep track of the contents of client’s caches NFS is stateless
Cache Update Policy Write-through Delayed-write Write-on-close (variation of delayed-write)
Cache Update Policy(cont) Write-through – all writes be propagated to stable storage immediately Reliable, but poor performance
Cache Update Policy(cont) Delayed-write – modification written to cache and then written through to server later Write-on-close – modification written back to server when file close Reduces intermediate read and write traffic while file is open
Cache Update Policy(cont) Pros for delayed-write/write-on-close Lots of files have lifetimes of less than 30s Redundant writes are absorbed Lots of small writes can be batched into larger writes Disadvantage: Poor reliability; unwritten data may be lost when client crash
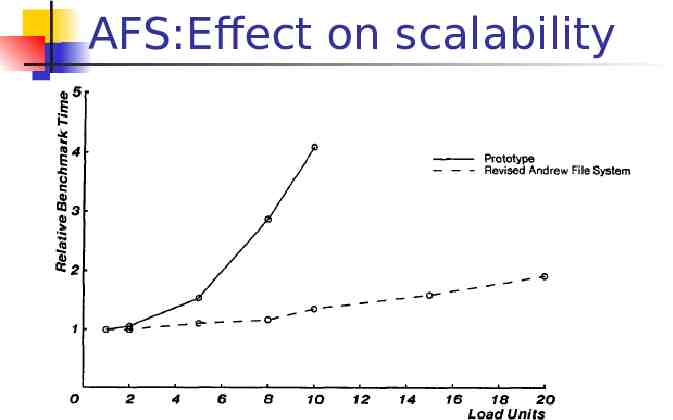
Caching in AFS Key to Andrew’s scalability Client cache entire file in disk Write-on-close Server load and network traffic reduced Contacts server only on open and close Retain across reboots Require local disk, large enough
Cache update policy NFS and Sprite delayed-write Delay 30 seconds AFS write-on-close Reduce traffic to server dramatically Good scalability of AFS
Consistency Is locally cached copy of data consistent with the master copy? Is there danger of “stale” data? Permit concurrent write sharing?
Sprite:Complete Consistency Concurrent Write Share A file open on multiple clients At least one client write Server detects Require write back to server Invalidate open cache
Sprite:Complete Consistency Sequential Write Sharing Out-of-date blocks A file modified, closed, opened by others Compare version number with server Current data in other’s cache Keep track of last writer
AFS: session semantics Session semantics in AFS Writes to an open file invisible to others Once file closed, changes visible to new opens anywhere Other file operations visible immediately Only guarantee sequential consistency
Consistency Sprite guarantees complete consistency AFS uses session semantics NFS not guarantee consistency NFS is stateless. All operations involve contacting the server; if server is unreachable, read & write cannot work
Client-driven vs. Serverdriven Client-driven approach Client initiates validity check Server check whether the local data are consistent with master copy Server-driven approach Server records files client caches When server detect inconsistency, it must react
AFS: server-driven Callback (key to scalability) Cache valid if have callback on Server notify before modification When reboot, all suspect reduces cache validation requests to server
Client-driven vs. Serverdriven AFS is server-driven (callback) Contributes to AFS’s scalability Whole file caching and session semantics also help NFS and Sprite are client-driven Increased load on network and server
AFS:Effect on scalability
Sprite:Dynamic cache size Make client cache as large as possible Virtual memory and file system negotiate Compare age of oldest page Two problems Double caching Multiblock pages
Why not callback in Sprite?
Why not callback in Sprite? Estimated improvement is small Reason Andrew is user-level process Sprite is kernel-level implementation
Comparison
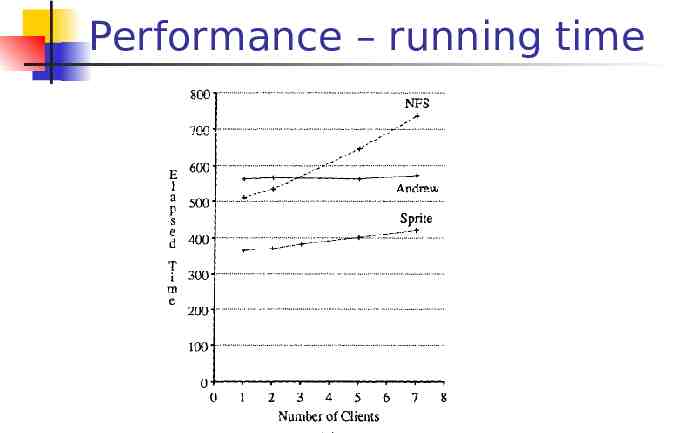
Performance – running time
Performance – running time Use Andrew benchmark Sprite system is fastest Kernel-to-kernel PRC Delayed write Kernel implementation (AFS is userlevel)
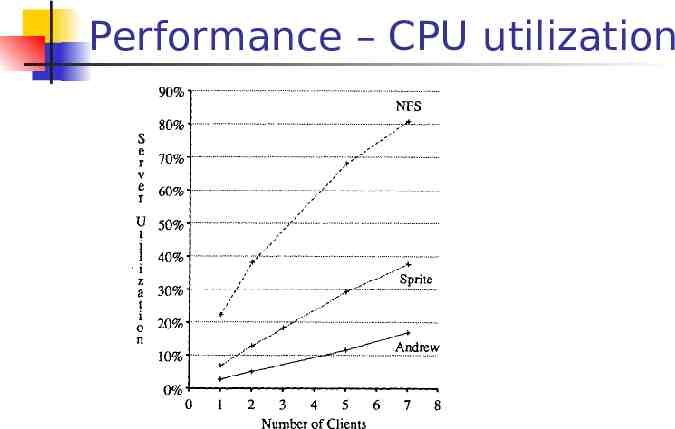
Performance – CPU utilization
Performance – CPU utilization Use Andrew benchmark Andrew system showed greatest scalability File-based cache Server-driven Use of callback
Nomadic Caching New issues If client become disconnected? Weakly connected(by modem)? Violate key property: transparency!
Nomadic Caching Cache misses may impede progress Local update invisible remotely Update conflict Update vulnerable to loss, damage Coda file system






