A Novel Framework for DTCO: Fast and Automatic Routability












23 Slides2.43 MB
A Novel Framework for DTCO: Fast and Automatic Routability Assessment with Machine Learning for Sub-3nm Technology Options Chidi Chidambaram, Andrew B. Kahng, Minsoo Kim, Giri Nallapati, S.C. Song and Mingyu Woo University of California, San Diego Qualcomm Technologies, Inc. T15-5 2021 Symposia on VLSI Technology and Circuits
Outline Background PROBE2.0 framework Experimental Results with Sub-3nm Technology Conclusion T15-5 2021 Symposia on VLSI Technology and Circuits Slide 2
Outline Background PROBE2.0 framework Experimental Results with Sub-3nm Technology Conclusion T15-5 2021 Symposia on VLSI Technology and Circuits Slide 3
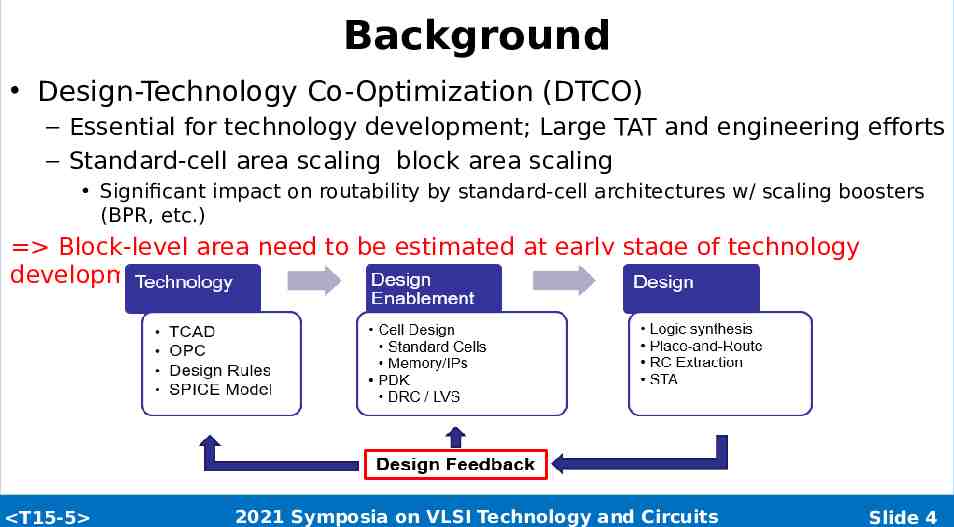
Background Design-Technology Co-Optimization (DTCO) – Essential for technology development; Large TAT and engineering efforts – Standard-cell area scaling block area scaling Significant impact on routability by standard-cell architectures w/ scaling boosters (BPR, etc.) Block-level area need to be estimated at early stage of technology development T15-5 2021 Symposia on VLSI Technology and Circuits Slide 4
Outline Background PROBE2.0 framework Experimental Results with Sub-3nm Technology Conclusion T15-5 2021 Symposia on VLSI Technology and Circuits Slide 5
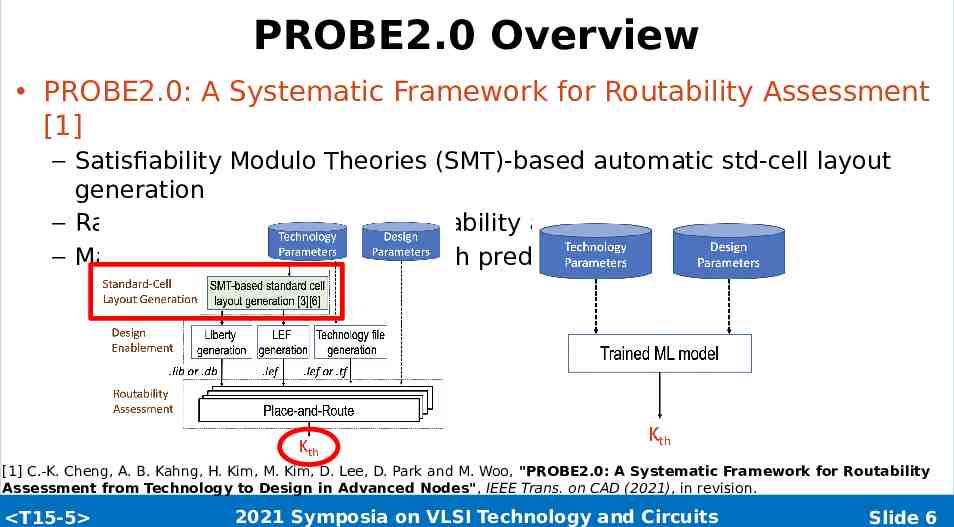
PROBE2.0 Overview PROBE2.0: A Systematic Framework for Routability Assessment [1] – Satisfiability Modulo Theories (SMT)-based automatic std-cell layout generation – Rank ordering (Kth)-based routability assessment – Machine learning (ML)-based Kth prediction [1] C.-K. Cheng, A. B. Kahng, H. Kim, M. Kim, D. Lee, D. Park and M. Woo, "PROBE2.0: A Systematic Framework for Routability Assessment from Technology to Design in Advanced Nodes", IEEE Trans. on CAD (2021), in revision. T15-5 2021 Symposia on VLSI Technology and Circuits Slide 6
Standard-Cell Layout SMT-based “automatic” standard-cell layout generation – Cell-level simultaneous placement and routing – Complete and optimal layout with grid-based conditional design rules – Open-sourced at GitHub https://github.com/ckchengucsd/SMT-based-STDCELL-Layout-Generator-for-PROB E2.0 – Generate signal and power/ground pins and convert into LEF format T15-5 2021 Symposia on VLSI Technology and Circuits Slide 7
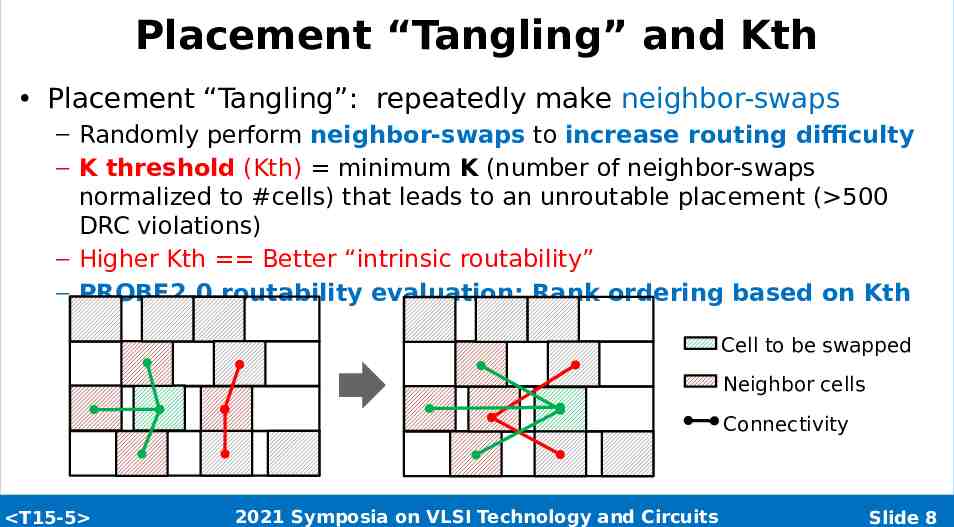
Placement “Tangling” and Kth Placement “Tangling”: repeatedly make neighbor-swaps – Randomly perform neighbor-swaps to increase routing difficulty – K threshold (Kth) minimum K (number of neighbor-swaps normalized to #cells) that leads to an unroutable placement ( 500 DRC violations) – Higher Kth Better “intrinsic routability” – PROBE2.0 routability evaluation: Rank ordering based on Kth Cell to be swapped Neighbor cells Connectivity T15-5 2021 Symposia on VLSI Technology and Circuits Slide 8
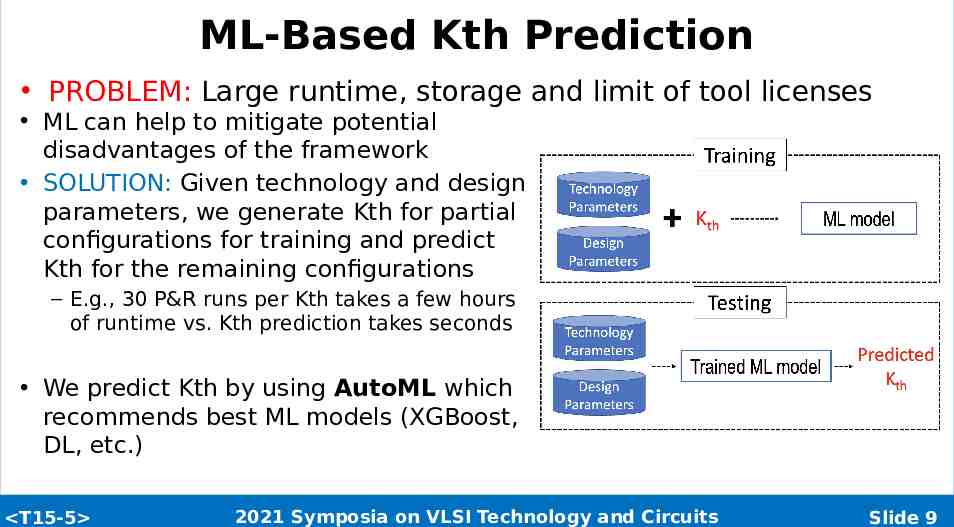
ML-Based Kth Prediction PROBLEM: Large runtime, storage and limit of tool licenses ML can help to mitigate potential disadvantages of the framework SOLUTION: Given technology and design parameters, we generate Kth for partial configurations for training and predict Kth for the remaining configurations – E.g., 30 P&R runs per Kth takes a few hours of runtime vs. Kth prediction takes seconds We predict Kth by using AutoML which recommends best ML models (XGBoost, DL, etc.) T15-5 2021 Symposia on VLSI Technology and Circuits Slide 9
Outline Background PROBE2.0 framework Experimental Results with Sub-3nm Technology Conclusion T15-5 2021 Symposia on VLSI Technology and Circuits Slide 10
Our Study In this work, we perform an early-stage routability assessment with sub-3nm configurations Reminder: The PROBE2.0 framework is used for routability assessment and we can assess routability with extended configurations Technology and design parameters for sub-3nm technology – – – – Cell height (CH): 80 150nm Contacted poly pitch (CPP): 39 57nm Metal pitch (MP): 16 30nm PDN strategy (power/ground pin & rails) : Includes buried power rails (BPR) T15-5 2021 Symposia on VLSI Technology and Circuits Slide 11
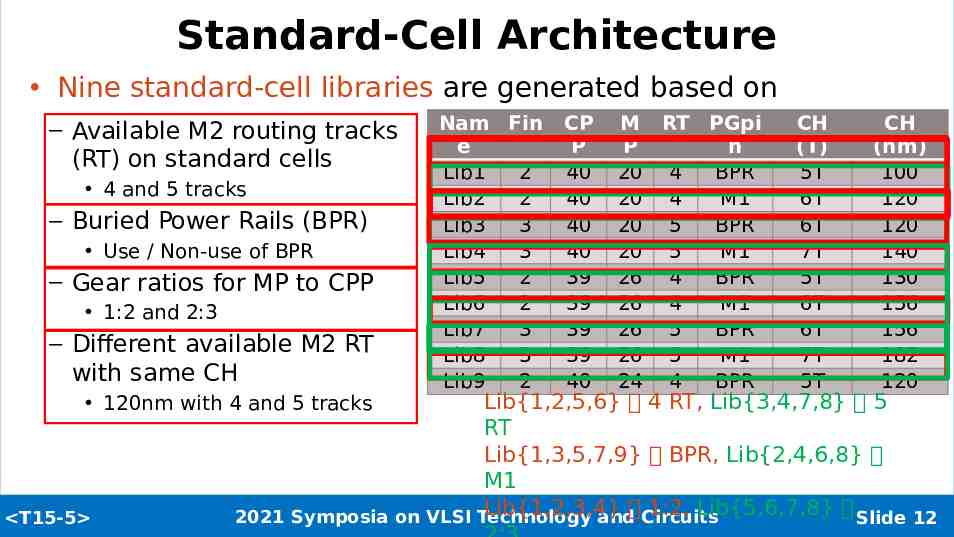
Standard-Cell Architecture Nine standard-cell libraries are generated based on – Available M2 routing tracks (RT) on standard cells 4 and 5 tracks – Buried Power Rails (BPR) Use / Non-use of BPR – Gear ratios for MP to CPP 1:2 and 2:3 – Different available M2 RT with same CH CP P 40 40 40 40 39 39 39 39 40 M RT PGpi P n 20 4 BPR 20 4 M1 20 5 BPR 20 5 M1 26 4 BPR 26 4 M1 26 5 BPR 26 5 M1 24 4 BPR CH (T) 5T 6T 6T 7T 5T 6T 6T 7T 5T CH (nm) 100 120 120 140 130 156 156 182 120 Lib{1,2,5,6} 4 RT, Lib{3,4,7,8} 5 RT Lib{1,3,5,7,9} BPR, Lib{2,4,6,8} M1 Lib{1,2,3,4} 1:2, Lib{5,6,7,8} Slide 12 2021 Symposia on VLSI Technology and Circuits 120nm with 4 and 5 tracks T15-5 Nam Fin e Lib1 2 Lib2 2 Lib3 3 Lib4 3 Lib5 2 Lib6 2 Lib7 3 Lib8 3 Lib9 2
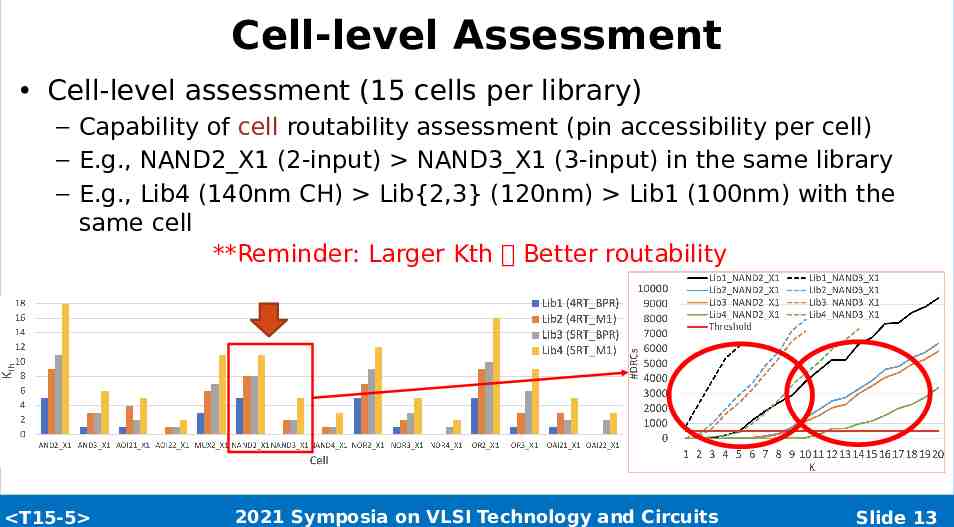
Cell-level Assessment Cell-level assessment (15 cells per library) – Capability of cell routability assessment (pin accessibility per cell) – E.g., NAND2 X1 (2-input) NAND3 X1 (3-input) in the same library – E.g., Lib4 (140nm CH) Lib{2,3} (120nm) Lib1 (100nm) with the same cell **Reminder: Larger Kth Better routability T15-5 2021 Symposia on VLSI Technology and Circuits Slide 13
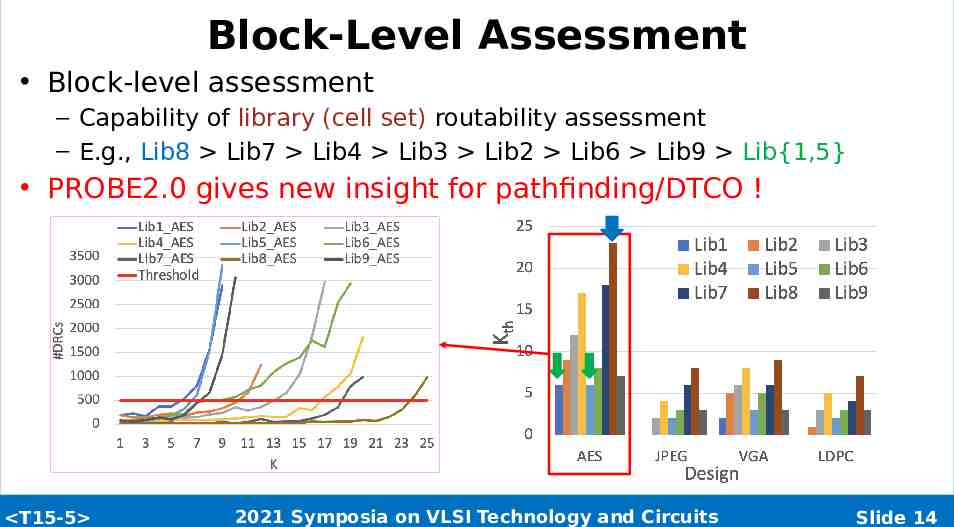
Block-Level Assessment Block-level assessment – Capability of library (cell set) routability assessment – E.g., Lib8 Lib7 Lib4 Lib3 Lib2 Lib6 Lib9 Lib{1,5} PROBE2.0 gives new insight for pathfinding/DTCO ! T15-5 2021 Symposia on VLSI Technology and Circuits Slide 14
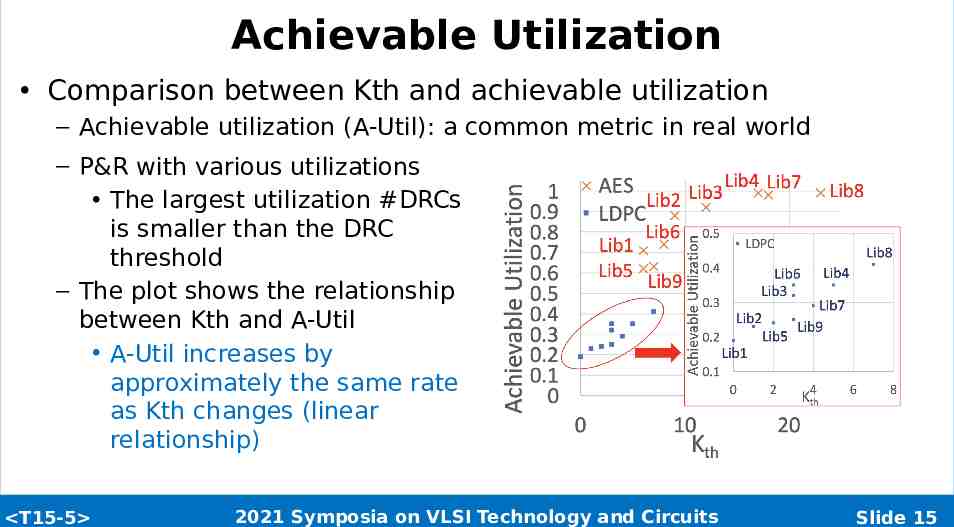
Achievable Utilization Comparison between Kth and achievable utilization – Achievable utilization (A-Util): a common metric in real world – P&R with various utilizations The largest utilization #DRCs is smaller than the DRC threshold – The plot shows the relationship between Kth and A-Util A-Util increases by approximately the same rate as Kth changes (linear relationship) T15-5 2021 Symposia on VLSI Technology and Circuits Slide 15
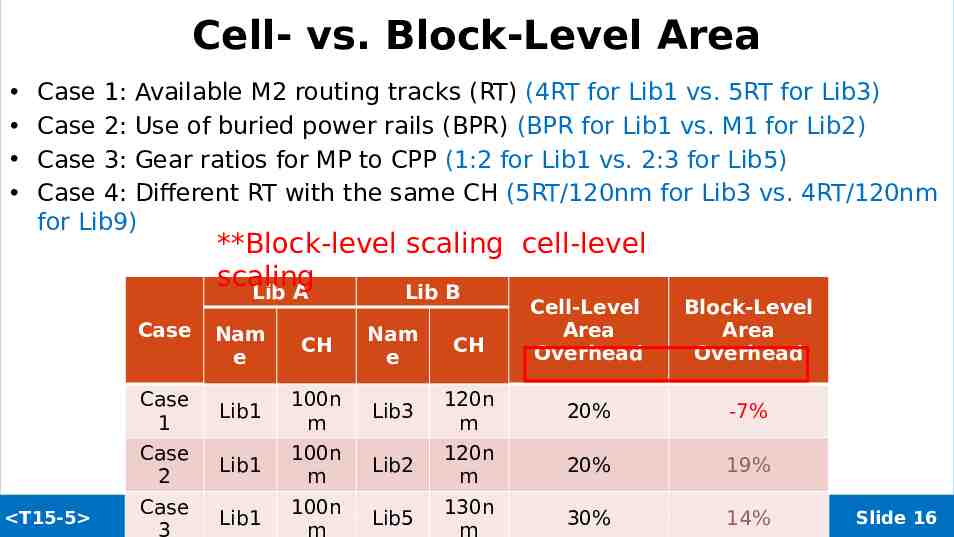
Cell- vs. Block-Level Area Case 1: Available M2 routing tracks (RT) (4RT for Lib1 vs. 5RT for Lib3) Case 2: Use of buried power rails (BPR) (BPR for Lib1 vs. M1 for Lib2) Case 3: Gear ratios for MP to CPP (1:2 for Lib1 vs. 2:3 for Lib5) Case 4: Different RT with the same CH (5RT/120nm for Lib3 vs. 4RT/120nm for Lib9) **Block-level scaling cell-level scaling Lib A Lib B Case T15-5 Cell-Level Area Overhead Block-Level Area Overhead Nam e CH Nam e CH Case 1 Lib1 100n m Lib3 120n m 20% -7% Case 2 Lib1 100n m Lib2 120n m 20% 19% Case 3 100n 130n 2021 Symposia on VLSI Technology and Circuits 14% Lib1 Lib5 30% m m Slide 16
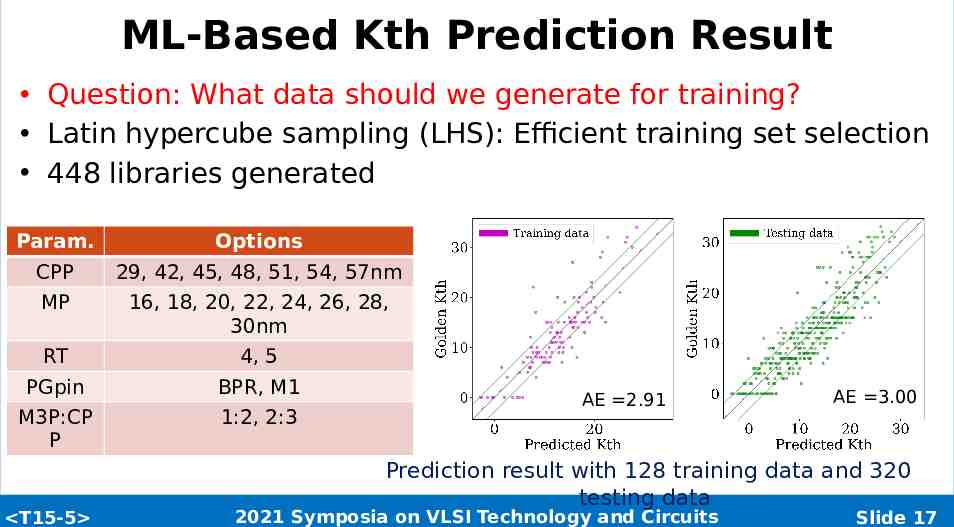
ML-Based Kth Prediction Result Question: What data should we generate for training? Latin hypercube sampling (LHS): Efficient training set selection 448 libraries generated Param. Options CPP 29, 42, 45, 48, 51, 54, 57nm MP 16, 18, 20, 22, 24, 26, 28, 30nm RT 4, 5 PGpin BPR, M1 M3P:CP P 1:2, 2:3 T15-5 AE 2.91 AE 3.00 Prediction result with 128 training data and 320 testing data 2021 Symposia on VLSI Technology and Circuits Slide 17
Outline Background PROBE2.0 framework Experimental Results with Sub-3nm Technology Conclusion T15-5 2021 Symposia on VLSI Technology and Circuits Slide 18
Conclusion We report, for the first time, that block-level scaling can be reversed from cell-level scaling in cell height 150nm regime PROBE2.0 framework is useful for pathfinding/DTCO problems Machine learning (ML) assists our routability evaluation 400 unique standard-cell architectures studied – 80 150nm cell height; 39 57nm contacted poly pitch (CPP); 16 30nm metal pitch; Use/non-use of buried power rails (BPR) Future work – We are adding power and performance aspects into the framework T15-5 2021 Symposia on VLSI Technology and Circuits Slide 19
Thank You ! T15-5 2021 Symposia on VLSI Technology and Circuits Slide 20
BACKUP SLIDES T15-5 2021 Symposia on VLSI Technology and Circuits Slide 21
Standard-Cell Layout T15-5 2021 Symposia on VLSI Technology and Circuits Slide 22
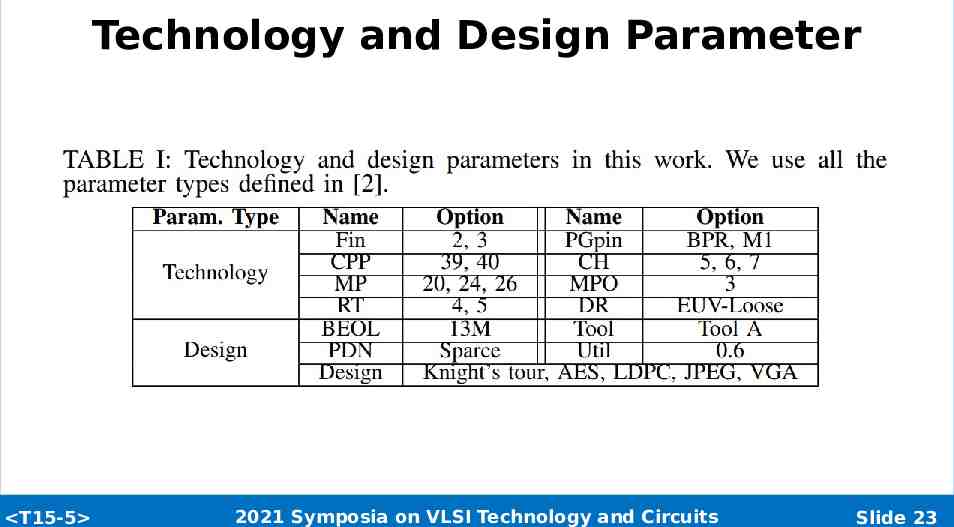
Technology and Design Parameter T15-5 2021 Symposia on VLSI Technology and Circuits Slide 23






