A Case for Redundant Arrays of Inexpensive Disks (RAID) David














17 Slides558.36 KB
A Case for Redundant Arrays of Inexpensive Disks (RAID) David A Patterson, Garth Gibson, and Randy H Katz Presented by Connor Bolton
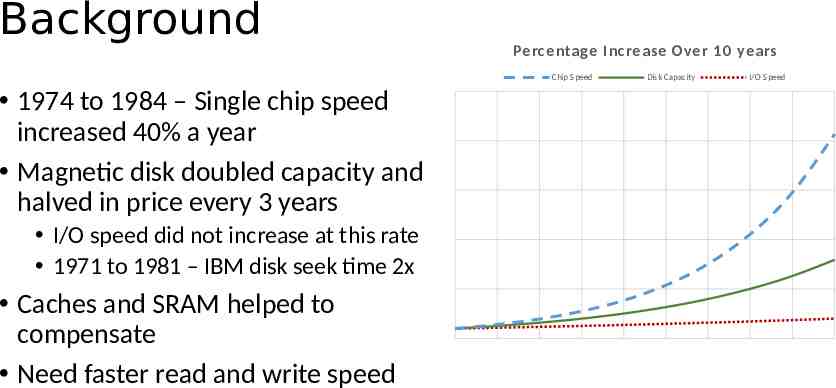
Background Percentage Increase Over 10 years Chip Speed 1974 to 1984 – Single chip speed increased 40% a year Magnetic disk doubled capacity and halved in price every 3 years I/O speed did not increase at this rate 1971 to 1981 – IBM disk seek time 2x Caches and SRAM helped to compensate Need faster read and write speed Disk Capacity I/O Speed
Motivation for RAID Characteristics IBM 3380 Fujitsu M2361A Conners CP3100 Conners CP3100 (75x) Formatted Data Capacity (MB) 7500 600 100 7500 Price/MB 18- 10 20- 17 10- 7 10- 7 I/O Bandwidth 120 24 20 1500 MTTF Rated (hours) 30000 20000 30000 400 Power/box (W) 6600 640 10 1000
RAID 1 – Mirrored Disks G 1 C 1 G data disks in group C check disks per group
RAID 2 – Hamming Code for ECC Bit level striping Requires discs to be in sync Hamming Code parity to correct single error Variable number of check disks per group Reads of less than group size require reading the whole group C 3 G 4 G data disks in group C check disks per group
RAID 2 – Hamming Code for ECC
RAID 3 – Single Check Disk Per Group Byte level striping Requires discs to be in sync Parity to detect single error Use disk controllers to detect which disk failed Single check disk per group G 3 C 1 G data disks in group C check disks per group
RAID 3 – Single Check Disk Per Group
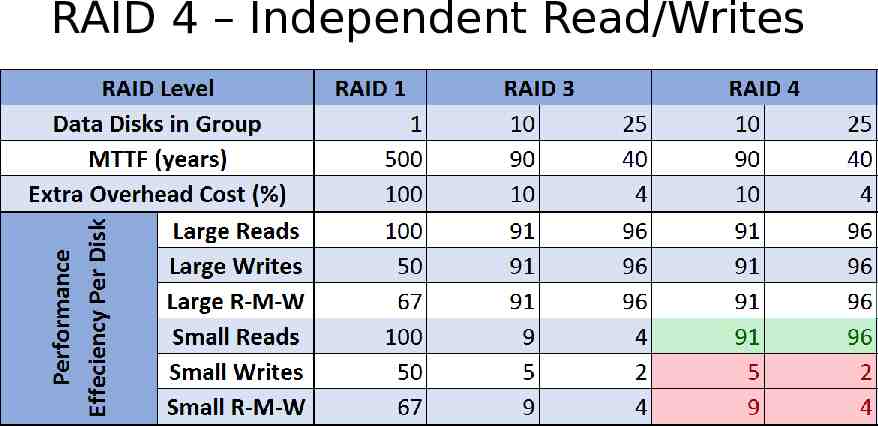
RAID 4 – Independent Read/Writes Block level striping Can read in parallel Cannot write in parallel In write parity can be calculated with just 2 disks Single check disk per group G 3 C 1
RAID 4 – Independent Read/Writes
RAID 5 – No Single Check Disk Block level striping Distribute data and check info across all disks Can read and write in parallel Single “check disk” per group G 3 C 1
RAID 5 – No Single Check Disk
RAID Level Comparison
RAID 5 vs SLED
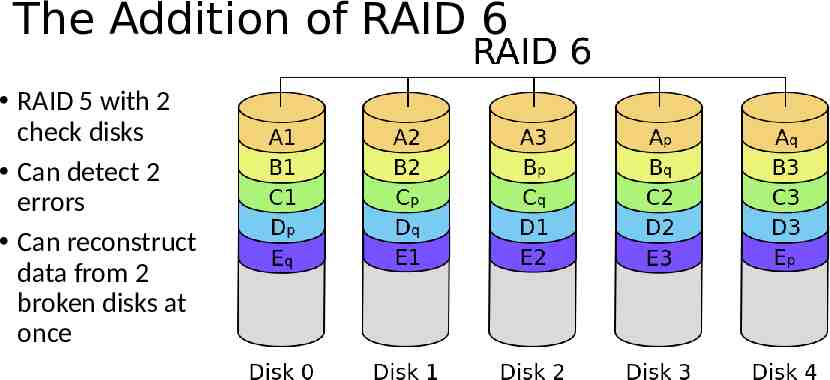
The Addition of RAID 6 RAID 5 with 2 check disks Can detect 2 errors Can reconstruct data from 2 broken disks at once
Current Day Issues: Excessive bit errors due to bad sectors on large discs RAID 6 with 2TB drives in 1000 disk system there is a 5% chance of annual data loss 8TB drives with 40% loss Rebuild times are being elongated as drive sizes increase
Discussion Topics: How do you modify RAID to mitigate large bit error and long rebuild times? What are the advantages and disadvantages of using RAID with SSDs?





