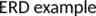290: Data Mining, InformationExtraction, and (Business)Analytics in






















26 Slides1.21 MB
290: Data Mining, InformationExtraction, and (Business)Analytics in Knowledge Services Ram Akella University of California Berkeley & Silicon Valley Center Lecture 1 January 19, 2011
Class Outline Knowledge Services, Data Mining, and Business Analytics Internet marketing and online ads, financial services, health services, service centers Data Mining and Statistics Focus of course Prediction and Classification Data and pre-processing: TSK Ch 2 Review of class Look ahead for next class
Who? Who Should Take This Course? Graduate Students Engineers and Managers who wish to Gain depth and/or perspective Move into this area (Potential) Entrepreneurs who wish to Brainstorm new ideas Create process for startup
What? What will you learn in this course? Techniques, software, and perspectives in: Statistics, Data Mining, and Business Analytics Online marketing, computational advertising, healthcare services, financial services, service/call centers and text mining
Knowledge Services Examples Online Marketing (Ranking Ads) User Ad Creatives Target Page Targeting Engine . Ads . Landing Pages . .
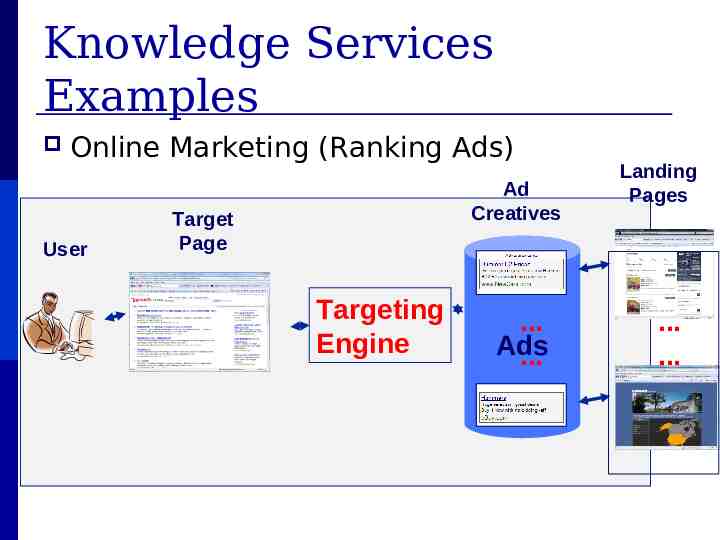
Knowledge Services Examples Opinion Mining (Blog Trend)
Knowledge Services Examples Social Networks
Knowledge Services and Data Mining What are Knowledge Services? What is Data Mining? Business Analytics? What is the connection between all three?
Services What is a service? http://en.wikipedia.org/wiki/ Service (economics) A service is the non-material equivalent of a good. A service provision is an economic activity that does not result in ownership Service professions http://www.bls.gov/oco/oco1006.htm Management and Business Professionals http://www.bls.gov/oco/oco1001.htm
Knowledge Services Marketing Internet and other marketing campaigns Online (computational) advertising Financial Services How should you invest? What are stock and industry trends? Fraud detection
Knowledge Services (Continued) Health Services Body fat profile and weight prediction Cancer identification Social networks for diabetes knowledge sharing Facebook! Service Centers Call center management Network prognostics and diagnostics Anomaly detection
Data Mining and Business Analytics Data Mining and Business Analytics Techniques to model and solve Knowledge Services problems This course Decision Theory is an aspect of business analytics Techniques to solve business management decision making Later courses E.g. How many experts and technicians of each type in a service center
Data Mining and Text Mining Knowledge Services Data Mining Data Mining Business Analytics Decision analytics Text Mining plus Image/Video Mining
Statistics and Data Mining 1 How are statistics and data mining related? Or are they not?
Data Mining: Definitions Data mining is the nontrivial process of identifying, novel, potentially useful, and ultimately understandable patterns in data. - Fayyad. Data mining is the process of extracting previously unknown, comprehensible, and actionable information from large databases and using it to make crucial business decisions. - Zekulin. Data Mining is a set of methods used in the knowledge discovery process to distinguish previously unknown relationships and patterns within data. - Ferruzza. Data mining is the process of discovering advantageous patterns in data. - John
Statistics Hypothesis testing Experimental design Response surface modeling ANOVA, MANOVA, etc. Linear regression Discriminant analysis Logistic regression GLM Canonical correlation Principal components Factor analysis
Data Mining Decision tree induction (C4.5, CART, CHAID) Rule induction (AQ, CN2, Recon, etc.) Nearest neighbors (case based reasoning) Clustering methods (data segmentation) Association rules (market basket analysis) Feature extraction Visualization In addition, some include: Neural networks Bayesian belief networks (graphical models) Genetic algorithms Self-organizing maps
Course Focus In this course, we transition from one to the other Good statistical basis enables more powerful data mining techniques! Every class Motivated by practical examples in Knowledge Services Solid grounding in techniques, software, data, for statistics and data mining (machine learning)
Statistics to Data Mining Transition DM packages implement well known procedures from machine learning, pattern recognition, neural networks and data visualization. Statistics concentrate on probabilistic inference in information science while DM also finds patterns in the data. Dimensionality reduction with statistical assumptions can be applied in DM (PCA). Assessing data quality.
Class Administration Office hours 1-2?, 5-6 pm?, Wed, by appt. Ignore rst for now Assignments and Projects: Postponement by 1 day – lose 10 points; 2 days, 20 points; then, 0 credit Project grading will be identical; lose 10 points for one day delay, 20 for 2 days, and 0 credit subsequently Quizzes and midterms: No postponement unless serious health or extraordinary work situation; see TA and then instructor Review website every day; you are responsible for monitoring and responding to changes Readings will be posted ahead of time; lecture PPTs just a bit before or after class You are expected to read and be prepared! Homework will be posted by Wednesday (latest Friday) for you to work over weekend and consult TA on Monday Labs: has computers; similarly Labs, with course software
Prediction and Classification Classification Prediction Classification is the task of assigning objects to one of several predefined categories. A prediction is a statement or claim that a particular event or value will occur in the future in more certain terms than a forecast. In DM, typically these tasks are performed based on a set of attributes which describe the object to classify or the variable to predict.
Data and Pre-processing Lecture 1b
Review and Summary of Lecture 1 Introduction to the course: Problems in Knowledge Services and Analytics. Data Mining definitions and differences between DM and Statistics. Data types and issues: Types of attributes in data: Nominal, Ordinal, Interval and Ratio. Types of data sets: Record, Graph, Ordered. Data quality issues: Noise and outliers, missing values, duplicate data.
Review and Summary of Lecture 1 Data preprocessing: Aggregation: data reduction, change of scale, combination of features. Sampling: random, with/without replacement, stratified. Dimensionality reduction: PCA, SVD. Feature subset selection: brute-force, embedded, filter, wrapper. Feature creation: extraction (domain specific), mapping to new space, combination of features.
Look-Ahead for Lecture 2 (and Boot camp 1) Covariance Matrix. Notions of Linear Algebra Singular Value Decomposition Principal Component Analysis in detail Please take a look at chapter 4 of the textbook.
Guest Speaker Jeff Kreuelen Senior Manager, IBM Almaden Text Mining, Service Centers Service Analytics, Data Mining, Text Mining, CRM, Marketing, Call Centers, Financial Services